老友(研发岗)被裁后,想加盟小吃店,我用Python采集了一点数据,多少是个心意
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了老友(研发岗)被裁后,想加盟小吃店,我用Python采集了一点数据,多少是个心意相关的知识,希望对你有一定的参考价值。
朋友公司不景气,被裁员了,为了安慰他,我让擦哥爬取了一些小吃加盟项目。
阅读本篇博客你将收获
- Python 技术的提升;
- requests 库和 lxml 库的熟悉度增加;
- 小吃加盟数据,没准用得上。
3158 网加盟小吃数据抓取
目标数据源分析
本次的目标数据源为 3158 加盟网,没写文章前,橡皮擦就没想到还真有专门宣传加盟的网站!
目标数据源地址如下:
https://www.3158.cn/xiangmu/canyin/
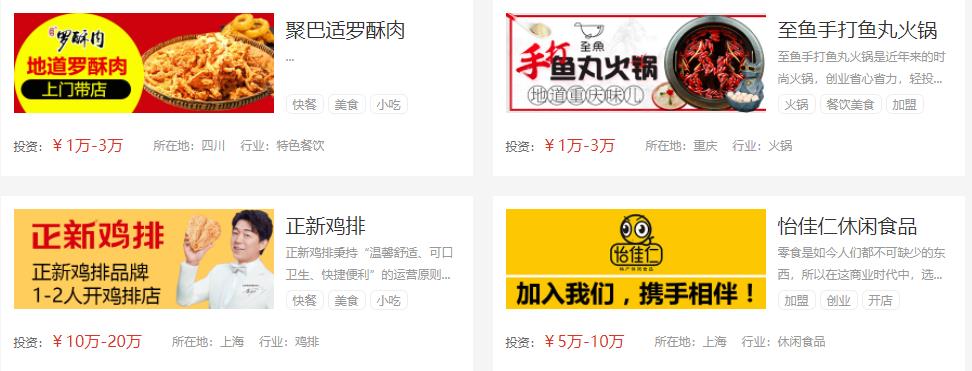
本篇博客将要涉及的知识点
- requests 抓取网页数据;
- xpath 熟悉度练习,lxml 格式化提取
- csv 文件存储,3 行代码版
数据来源分析
目标数据分页格式如下,简单的规则,并且总页数可直接在网页看到,省去了判断数据是否爬取完毕的逻辑。
https://www.3158.cn/xiangmu/canyin/?pt=all&page=1
https://www.3158.cn/xiangmu/canyin/?pt=all&page=2
https://www.3158.cn/xiangmu/canyin/?pt=all&page=3
https://www.3158.cn/xiangmu/canyin/?pt=all&page=n
静态网页直接使用 requests 抓取即可,本案例的重点依旧在 lxml 提取,为了防止爬取过程中断,可以先将网页数据批量存储到本地。
抓取代码如下
import requests
from lxml import etree
import time
import re
import random
USER_AGENTS = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"其它 UserAgent 自己选择"
]
def run(url, index):
try:
headers = {"User-Agent": random.choice(USER_AGENTS)}
res = requests.get(url=url, headers=headers)
res.encoding = "utf-8"
html = res.text
with open(f"./html/{index}.html", "w+", encoding="utf-8") as f:
f.write(html)
except Exception as e:
print(e)
if __name__ == '__main__':
for i in range(1, 130):
print(f"正在爬取第{i}页数据")
run(f"https://www.3158.cn/xiangmu/canyin/?pt=all&page={i}", i)
print("全部爬取完毕")
运行上述代码前,需要在代码目录创建 html 文件夹,用于存储静态网页,最终该文件夹下形成下图内容,表示页面抓取完毕。

数据提取时间
本次提取依旧使用 lxml 库,更多内容可在官方站点持续学习,地址为 https://lxml.de/tutorial.html 。
在上一步骤中,已经将网页保存到本地,后续围绕这 129 个HTML文件处理即可。
打开上图中任意 HTML 页面,出现如下效果,对数据对比之后发现,页面布局存在下图所示的差异。
数据提取完毕,才发现,其实可以忽略这个差异。
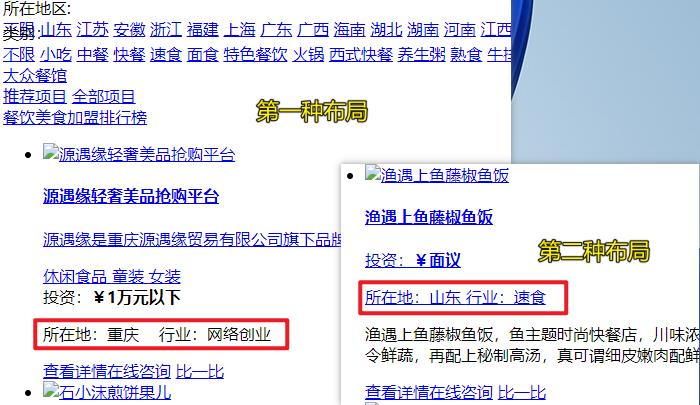
基于上图对数据规则进行设置,目标数据包含:
- 加盟店名称
- 投资金额
- 所在地
- 行业
- 标签(如数据存在)
- 详情页地址
为了后续爬取方面,将详情页地址也进行提取,以上内容就是目标数据最终的格式。
在数据源存在差异的情况下,直接检查 HTML 源代码,寻找页面出现差异性的原因。
li标签存在差异化,对其进行特殊处理即可。
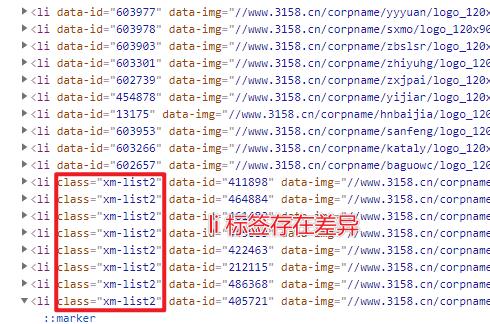
提取代码如下所示,相关说明已经添加在注释
import requests
from lxml import etree
import time
import re
import random
# 列表转换为字符串
def list_str(my_list):
return ",".join(my_list)
def get_data():
for i in range(1, 130):
with open(f"./html/{i}.html", "r", encoding="utf-8") as f:
html = f.read()
element = etree.HTML(html)
# contains 函数 获取包含 xxx 的元素,类似的还有 starts-with,ends-with,last
origin_li = element.xpath("//ul[contains(@class,'xm-list')]/li")
# 循环抓取 li 内部数据
for item in origin_li:
# 提取加盟名称
# title = item.xpath(".//div[@class='r']/h4/text()")[0]
title = item.xpath("./div[@class='top']/a/@title")[0]
# 提取超链接
detail_link = "http://" + item.xpath("./div[@class='top']/a/@href")[0]
# 提取特殊标签
special_tag = list_str(item.xpath("./@class"))
# 当包含特殊标签 xm-list2 时,使用不同的提取规则
if special_tag != "xm-list2":
# 提取标签
tags = list_str(item.xpath(".//div[@class='bot']/span[@class='label']/text()"))
# 提取投资价格
price = list_str(item.xpath(".//div[@class='bot']/span[@class='money']/b/text()"))
# 地址和行业
city_industry = list_str(item.xpath("./div[@class='bot']/p/span/text()"))
long_str = f"{title},{detail_link}, {tags}, {price}, {city_industry}"
save(long_str)
else:
# 地址和行业
city_industry = list_str(item.xpath(
"./div[@class='top']/a/div/p[2]/span/text()"))
long_str = f"{title},{detail_link}, {0}, {0}, {city_industry}"
save(long_str)
def save(long_str):
try:
with open(f"./jiameng.csv", "a+", encoding="utf-8") as f:
f.write("\\n"+long_str)
except Exception as e:
print(e)
if __name__ == '__main__':
# for i in range(1, 130):
# print(f"正在爬取第{i}页数据")
# run(f"https://www.3158.cn/xiangmu/canyin/?pt=all&page={i}", i)
get_data()
print("全部提取完毕")
上述代码首先通过 element.xpath("//ul[contains(@class,'xm-list')]/li") 提取 HTML 中的 li 标签,然后遍历提取的 li 数据,进行内部提取。
提取过程中,发现 title 与 detail_link,即标题与详情页的提取代码一致,其它数据通过判断 li 标签的 class 否含有 xm-list2 进行判断,整体代码如上所示。
在使用 lxml 的过程中,最常用的为路径表达式,即 // 从根目录提取, .// 从当前节点的根目录提取,./ 从当前节点提取。
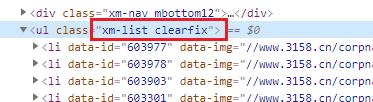
代码中还用到了 contains 函数,在本案例中该函数用于判断属性值中是否包含某个字符串,例如上文代码中提取 ul 标签,正是此函数的应用,在提取所有 li的过程中,需要提前匹配 ul,该标签在 HTML 中属性如下所示,使用 contains 可以进行部分匹配。
在代码后半部分,存在一个 XPath 匹配规则 city_industry = list_str(item.xpath("./div[@class='top']/a/div/p[2]/span/text()")) ,注意其中出现的 p[2] ,该代码表示选取第二个 p 标签。
今天的抓取结果展示,2021-7-16
本次抓取的数据,已经上传到 CSDN 下载频道,源码分享在代码频道。
完整代码下载地址:https://codechina.csdn.net/hihell/python120,NO14。
以下是爬取过程中产生的加盟店数据,数据量不大,你可以进行二次扩展。
爬取资源仅供学习使用,侵权删。
评论时间
来都来了,评论区不发了评论吗?
今天是持续写作的第 184 / 200 天。
可以关注我,点赞我、评论我、收藏我啦。
更多精彩
以上是关于老友(研发岗)被裁后,想加盟小吃店,我用Python采集了一点数据,多少是个心意的主要内容,如果未能解决你的问题,请参考以下文章