爬虫学习笔记—— scrapy-redis
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫学习笔记—— scrapy-redis相关的知识,希望对你有一定的参考价值。
一、分布式概念和作用
分布式:一个业务分拆多个子业务,部署在不同的服务器上;是一种将任务分布在不同地方的工作方式。
作用:提高安全性和效率
分布式爬虫:
- 默认情况下,我们使用scrapy框架进行爬虫时使用的是单机爬虫,就是说它只能在一台电脑上运行,因为爬虫调度器当中的队列queue去重和set集合都只能在本机上创建的,其他电脑无法访问另外一台电脑上的内存和内容。
- 分布式爬虫实现了多台电脑使用一个共同的爬虫程序,它可以同时将爬虫任务部署到多台电脑上运行,这样可以提高爬虫速度,实现分布式爬虫。
二、Scrapy-redis
2.1、redis的安装与使用
1、redis 下载地址
https://github.com/MicrosoftArchive/redis/releases
2、修改redis.windows.conf
bind 127.0.0.1 -> bind 0.0.0.0
3、启动服务与数据库
启动服务器:redis-server
启动数据库:redis-cli
4、使用:
redis基本使用可看我博客:学习笔记(十七)——redis(CRUD)
python连接redis可看我博客:学习笔记(十九)——Python与数据库交互(mysql、redis)
2.2、Redis Desktop Manager下载
这是一个redis的桌面工具,可以图形化界面操作redis数据库
安装教程:https://www.cnblogs.com/ttlx/p/11611086.html
2.3、特点和架构
scrapy_redis是一个基于Redis的Scrapy组件,用于scrapy项目的分布式部署和开发。
特点:分布式爬取
可以启动多个spider对象,互相之间共享有一个redis的request队列。最适合多个域名的广泛内容的爬取。
分布式数据处理:
爬取到的item数据被推送到redis中,这意味着你可以启动尽可能多的item处理程序。
2.4、安装和使用
- 一般通过pip安装Scrapy-redis:
pip install scrapy-redis
- scrapy-redis依赖:
Python 2.7, 3.4 or 3.5以上
Redis >= 2.8
Scrapy >= 1.1
- scrapy-redis的使用非常简单,几乎可以并不改变原本scrapy项目的代码,只用做少量设置
2.5、redis中存储的数据
-
spidername:items
list类型,保存爬虫获取到的数据item内容是json字符串。
-
spidername:dupefilter
set类型,用于爬虫访问的URL去重内容,是40个字符的url的hash字符串
-
spidername:start_urls
list类型,用于接收redis spider启动时的第一个url
-
spidername:requests
zset类型,用于存放requests等待调度。内容是requests对象的序列化字符串
2.6、项目配置及项目代码
spider文件
代码作了简单改动
- 导出RedisSpider
- 类继承 RedisSpider (原来是继承scrapy.Spider)
- 注销strat_urls 设置
redis_key = "db:start_urls"开启爬虫钥匙
注意:使用时,记得提前在redis中添加。例如:lpush db:start_urls https://movie.douban.com/top250
settings文件
需要配置:
- 公共的调度器 SCHEDULER
- 公共的过滤器 DUPEFILTER_CLASS
- 公共存储区域 redis
常用设置:
# 1.启用调度将请求存储进redis 必须
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 2.确保所有spider通过redis共享相同的重复过滤。 必须
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#公共管道
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline':300,
# 'db250.pipelines.Db250Pipeline': 200,
}
# 3.指定连接到Redis时要使用的主机和端口。 必须
REDIS_HOST = 'localhost'
REDIS_PORT = 6379
# 不清理redis队列,允许暂停/恢复抓取。
# 可选 允许暂定,redis数据不丢失
SCHEDULER_PERSIST = True
三、小案例:爬取豆瓣250电影信息
(这里就用我博客:Scrapy框架(二)的案例来进行修改演示,以下仅列举需要稍微修改的地方)
注意:这里有一点要提示下,爬取的数据量要设置大些,不然可能效果不明显。这里仅仅只是伪分布式
3.1、spider文件
from scrapy_redis.spiders import RedisSpider #导入RedisSpider
#原本是继承scrapy.Spider 现在改为RedisSpider
class DbSpider(RedisSpider):
name = 'db'
# allowed_domains = ['movie.douban.com']
# start_urls = ['https://movie.douban.com/top250'] #这个要注释掉
redis_key = 'db:start_urls' # 开启爬虫钥匙
page = 0
def parse(self, response):
all_mes = response.xpath('//div[@class="info"]')
for mes in all_mes:
film_name = mes.xpath('./div/a/span[1]/text()')[0].extract()
score = mes.xpath('./div/div/span[2]/text()')[0].extract()
director = mes.xpath('./div/p/text()')[0].extract().strip()
item = Db250Item()
item['film_name'] = film_name
item['score'] = score
item['director'] = director
# yield item
detail_url = mes.xpath('./div/a/@href').extract()[0]
yield scrapy.Request(detail_url,callback=self.get_detail,meta={'info':item})
if response.meta.get('num'): #这个meta很关键 可以避免相互干扰
self.page = response.meta["num"]
self.page += 1
if self.page == 6:
return
page_url = 'https://movie.douban.com/top250?start={}&filter='.format(self.page * 25)
yield scrapy.Request(page_url,meta={'num':self.page})
def get_detail(self,response):
items = Db250Item()
info = response.meta["info"]
items.update(info)
detail= response.xpath('//div[@class="indent"]//span[@property="v:summary"]/text()').extract()[0].strip()
items['detail'] = detail
yield items
3.2、settings文件
添加
# 1.启用调度将请求存储进redis 必须
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 2.确保所有spider通过redis共享相同的重复过滤。 必须
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#公共管道
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline':300, #为了写的redis
'db250.pipelines.Db250Pipeline': 200, #写到txt文本方便我们查看
}
# 3.指定连接到Redis时要使用的主机和端口。 必须
REDIS_HOST = 'localhost'
REDIS_PORT = 6379
# 不清理redis队列,允许暂停/恢复抓取。
# 可选 允许暂定,redis数据不丢失
SCHEDULER_PERSIST = True
3.3、pipelines文件
import json
import pandas as pd
from itemadapter import ItemAdapter
class Db250Pipeline:
def open_spider(self,spider):
self.f = open('film_mes1.txt','w',encoding='utf-8')
def process_item(self, item, spider):
data = json.dumps(dict(item),ensure_ascii=False)+'\\n'
self.f.write(data)
return item
def close_spider(self,spider):
self.f.close()
结果执行步骤:
1、准备(这两文件代码完全一模一样):

2、在终端分布运行这两个文件(由于我还没在redis设置钥匙,所以这两文件都处于等待状态)
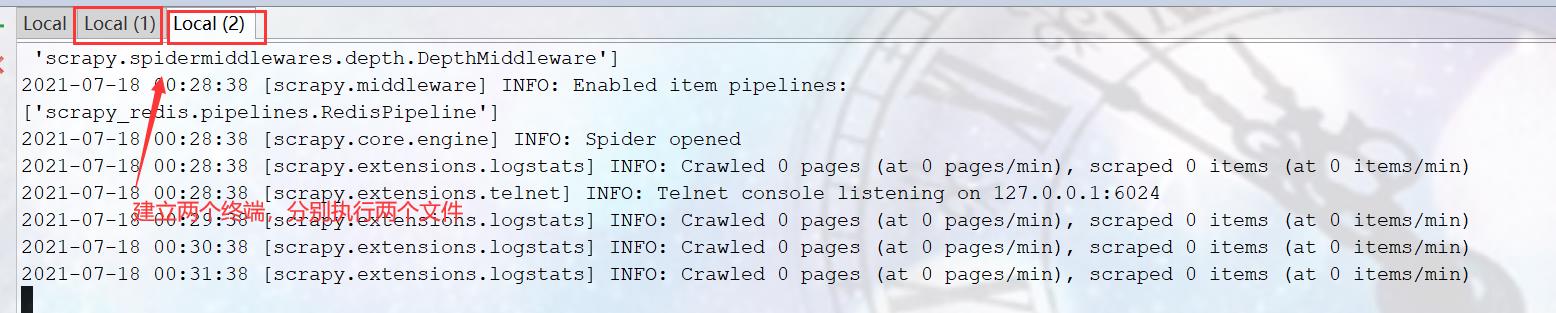
3、再开启一个终端(在redis写入钥匙)

最后让我们来看看结果是什么样的(这里我爬取了6页数据也就是150条):
① 首先我们先看看redis数据库的内容,这里我们打开RDM:
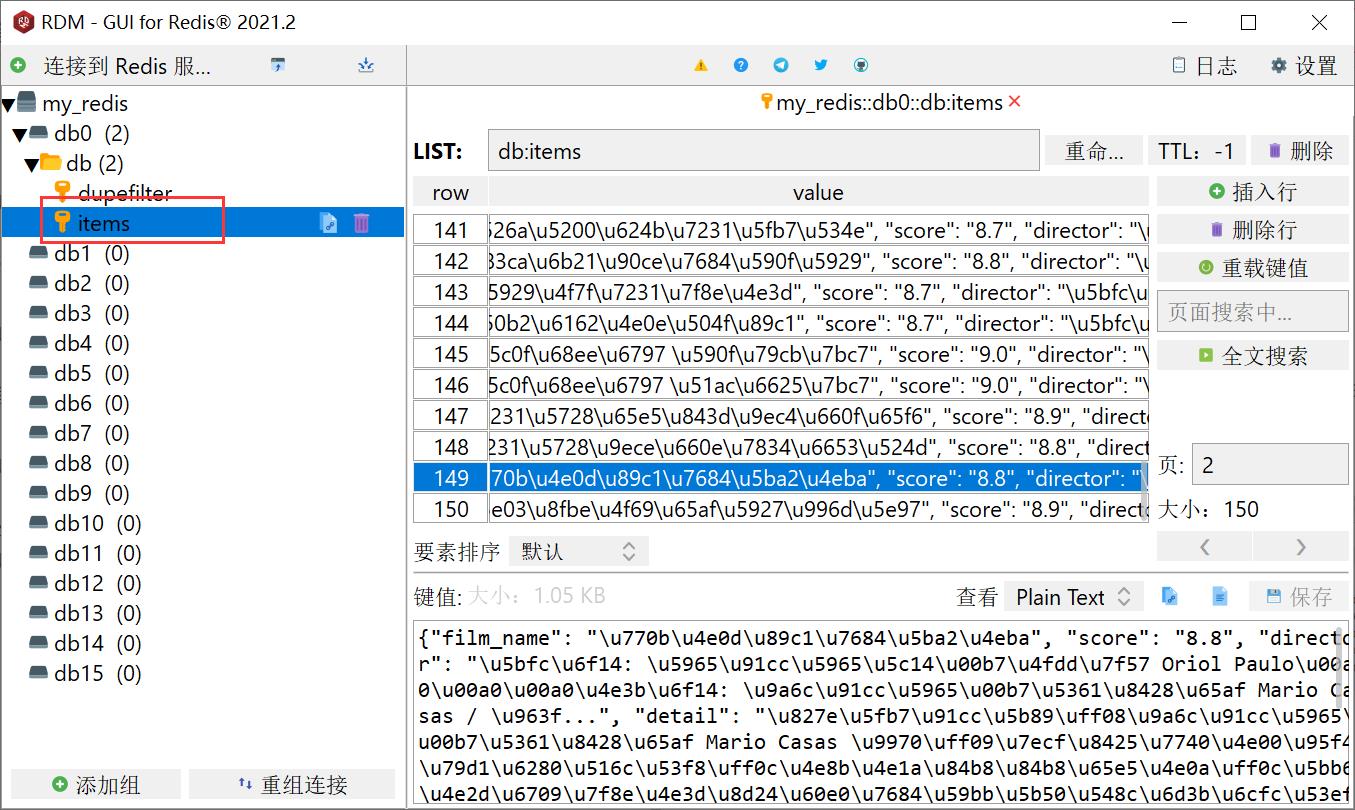
这里我们看到了数据库的内容是一堆字符,但是我们可以从网上找JSON解析工具来进行解析(这里我随便找了一个JSON在线解析)
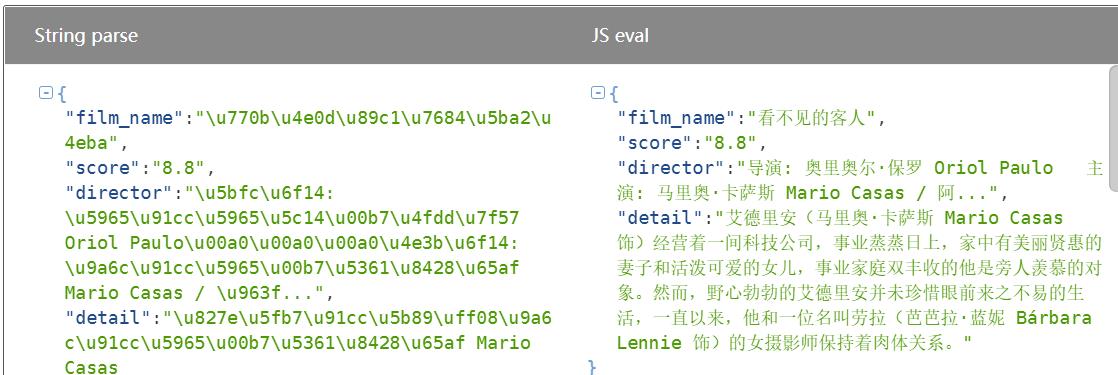
②接下来,我们来看看txt文件的写入情况
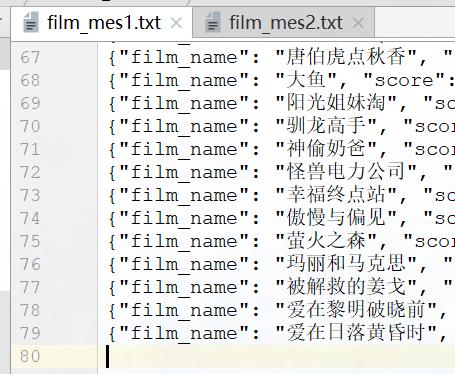 |  |
两个文件加起来刚好150条,说明我们的伪分布式是成功的
以上是关于爬虫学习笔记—— scrapy-redis的主要内容,如果未能解决你的问题,请参考以下文章
爬虫学习 17.基于scrapy-redis两种形式的分布式爬虫