Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
Posted 邻家大男孩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合相关的知识,希望对你有一定的参考价值。
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~
首先介绍一下这个标题吧~
1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待当前URL抓取完毕之后在进行下一个URL的抓取,抓取效率可以提高很多。
2. Scrapy-redis:虽然Scrapy框架是异步加多线程的,但是我们只能在一台主机上运行,爬取效率还是有限的,Scrapy-redis库为我们提供了Scrapy分布式的队列,调度器,去重等等功能,有了它,我们就可以将多台主机组合起来,共同完成一个爬取任务,抓取的效率又提高了。
3. Scrapyd:分布式爬虫完成之后,接下来就是代码部署,如果我们有很多主机,那就要逐个登录服务器进行部署,万一代码有所改动..........可以想象,这个过程是多么繁琐。Scrapyd是专门用来进行分布式部署的工具,它提供HTTP接口来帮助我们部署,启动,停止,删除爬虫程序,利用它我们可以很方便的完成Scrapy爬虫项目的部署。
4. Gerapy:是一个基于Scrapyd,Scrapyd API,Django,Vue.js搭建的分布式爬虫管理框架。简单点说,就是用上述的Scrapyd工具是在命令行进行操作,而Gerapy将命令行和图形界面进行了对接,我们只需要点击按钮就可完成部署,启动,停止,删除的操作。
1. 创建Scrapy项目:(之前的博客有提到过)
项目的结构如下:(这个项目里包含了多个spider,接下来,就以我圈出来的为例讲解)

因为我这个需要用到固定的代理,在这个讲一下代理如何使用:
代理在middlewares.py这个模块中的process_request方法中进行配置(如果想知道为什么在这里配置,可以去google一下scrapy框架爬虫的整体结构流程),如下:
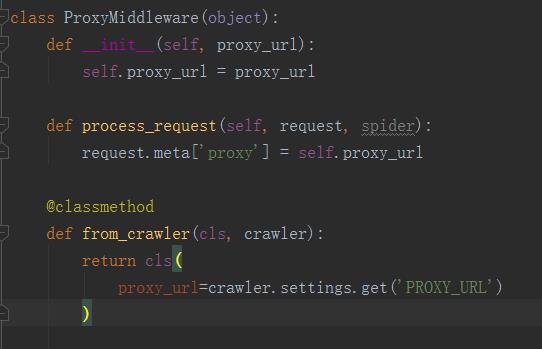
然后在settings.py中指定具体的代理是什么:如 PROXY_URL=\'http://10.10.10.10:8080\'
如果要设置动态代理,参考这里:https://github.com/Damon-zln/ProxyPool
2. Scrapy-redis分布式配置:
1. 首先,确认Scrapy-redis库已经安装~
未安装,可以 pip install scrapy-redis 进行安装。
2. 搭建Redis服务器,如果未安装redis数据库的,请自行google~
Redis安装完成后,就可以远程连接了,如果不能,可能是服务器上没有开放端口(redis默认端口6379)
记录服务器的IP,端口(默认是6379),密码为foobared,供后面分布式爬虫使用。
3. 配置Scrapy-redis(只需要修改settings.py文件即可)
将调度器的类和去重的类替换为Scrapy-redis提供的类,在settings.py中配置如下:
SCHEDULER = \'scrapy_redis.scheduler.Scheduler\'
DUPEFILTER_CLASS = \'scrapy_redis.dupefilter.RFPDupeFilter\'
Redis连接配置:
REDIS_URL = \'redis://[:password]@host:port/db\'
其他的都使用默认配置(如:调度对列,持久化,重爬,管道)
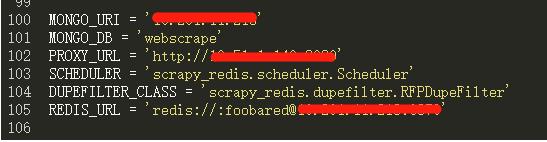
5. 配置存储目标:
搭建一个MongoDB服务,将多台主机的数据都存在同一个MongoDB数据库中
配置如下:
MONGO_URI = \'host\'
MONGO_DB = \'webscrape\'
所有配置截图如下:
3. Scrapyd的安装:
1. 安装:pip install scrapyd
2. 配置:安装完毕后,需要新建一个配置文件/etc/scrapyd/scrapyd.conf,scrapyd在运行时会读取此配置文件。
在Scrapyd1.2版本后,不会自动创建该文件,需要我们自行添加。
首先,执行如下命令新建文件:
sudo mkdir /etc/scrapyd
sudo vi /etc/scrapyd/scrapyd.conf
接着写入如下内容:
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 10
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root
[services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
daemonstatus.json = scrapyd.webservice.DaemonStatus
配置文件内容参见官方文档:https://scrapyd.readthedocs.io/en/stable/config.html#example-configuration-file
这里的配置文件有所修改:max_proc_per_cpu官方默认是4,即一台主机每个CPU最多运行4个Scrapy任务,在此提高为10,另外,bind_address,默认为本地127.0.0.1,在此修改为0.0.0.0,这样外网可以访问。
3. 后台运行scrapyd:
scrapyd > /dev/null &
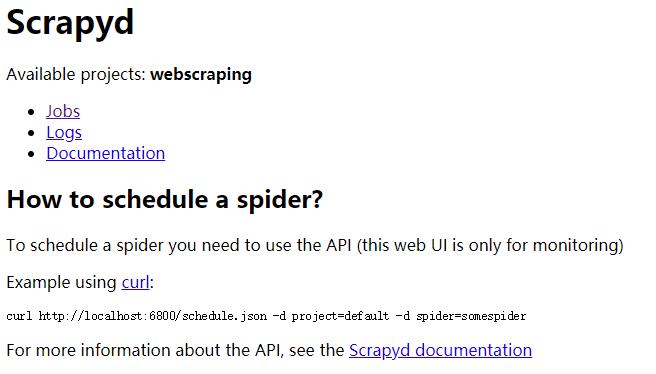
运行之后,便可在浏览器的6800端口访问WEB UI了,如下:
4. Gerapy分布式管理:
1. 安装:pip install gerapy
2. 使用说明:
利用gerapy命令创建一个项目:
gerapy init
在当前目录下生成一个gerapy文件夹,进入gerapy文件夹,会发现一个空的projects文件夹,后面后用到。
初始化:
gerapy migrate
这样会生成一个SQLite数据库,用于保存各个主机的配置信息等。
启动Gerapy服务:
gerapy runserver host:port (默认是端口8000)
这样,我们就可以通过http://host:8000进入Gerapy管理页面。
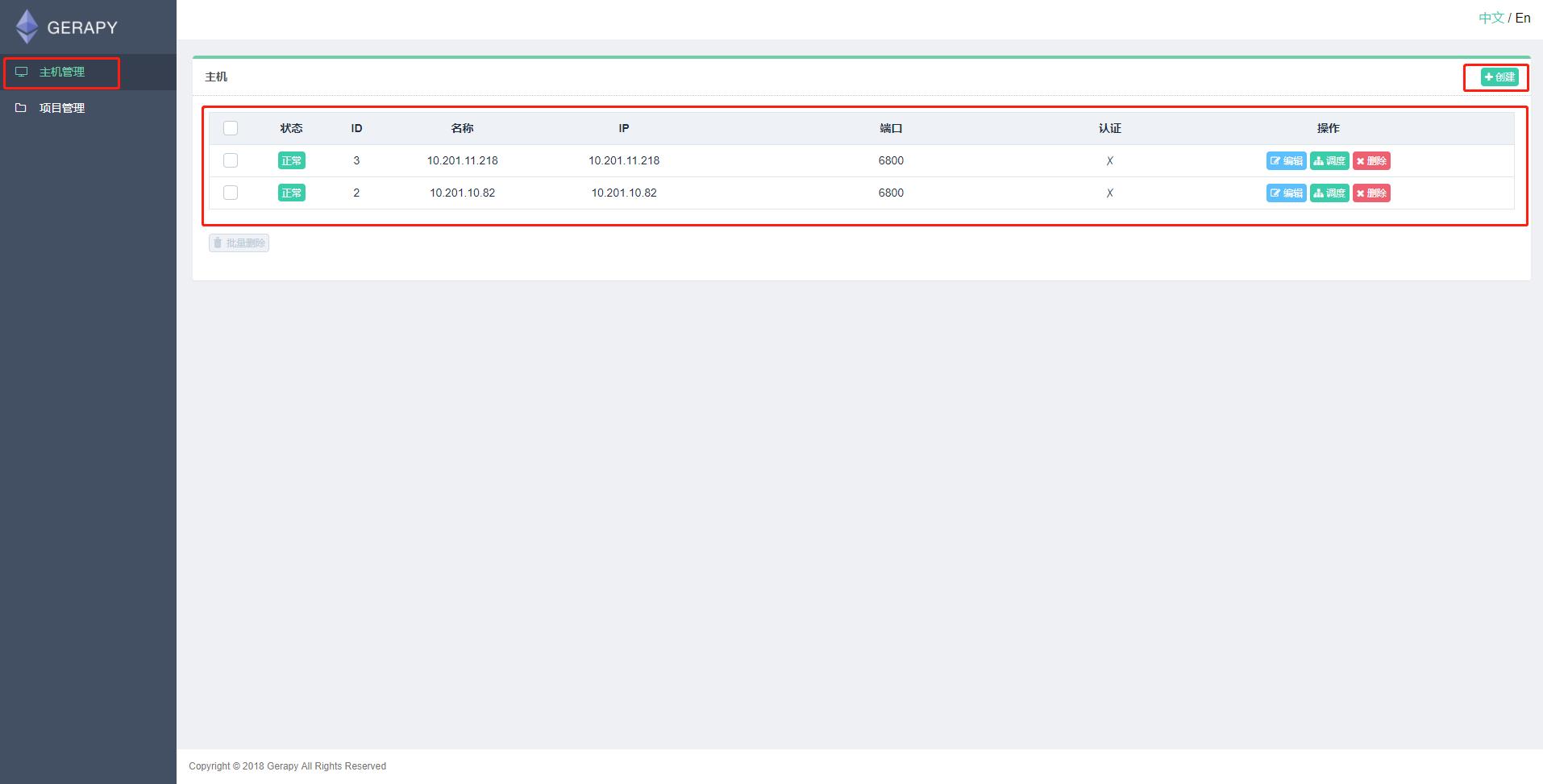
在主机管理中添加scrapyd运行的地址和端口,如下:
在projects文件夹中,放入你的Scrapy项目:
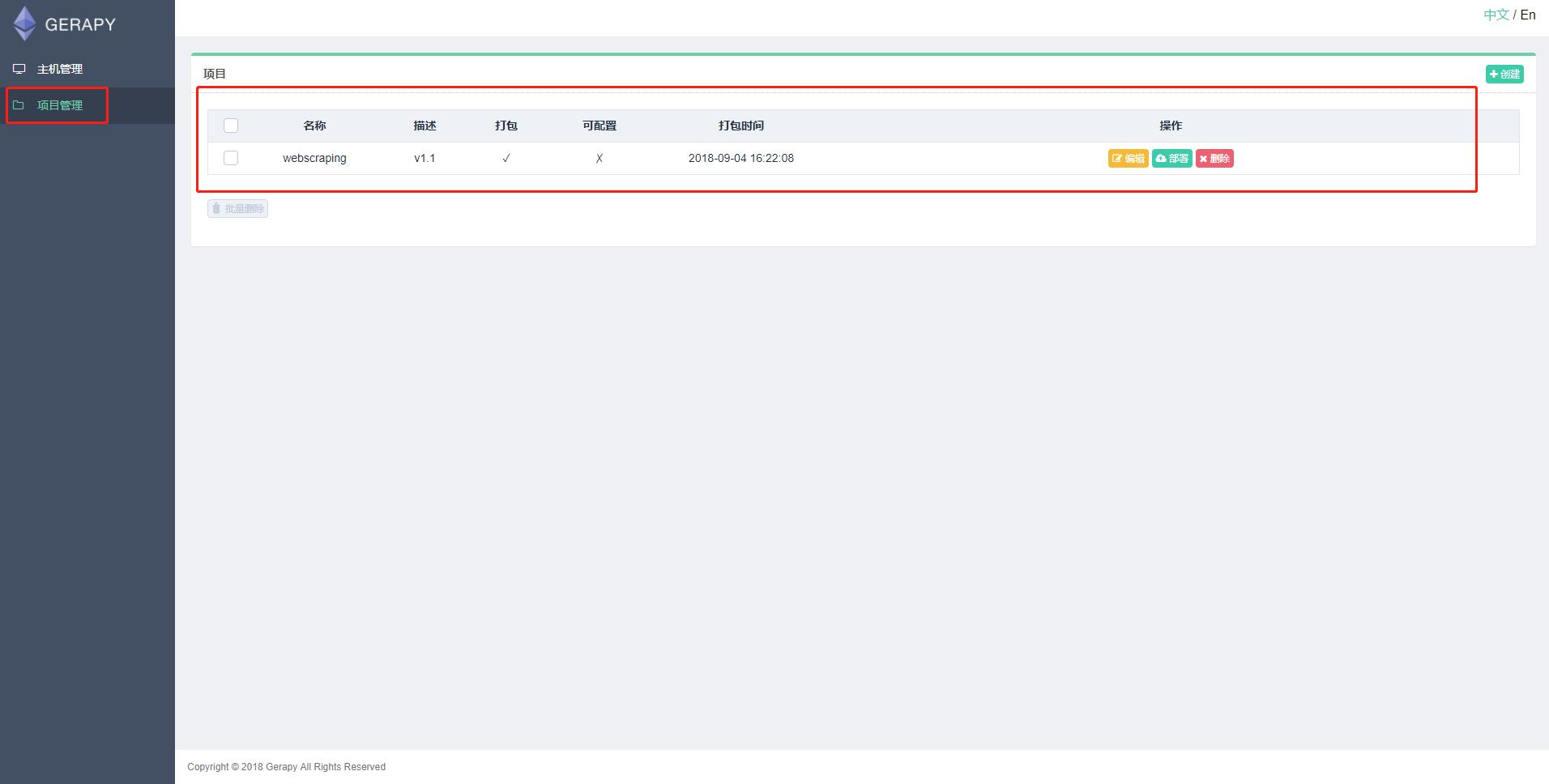
可以点击上图中的编辑,在线编辑项目,如果项目没有问题,可以点击部署进行打包和部署,在部署之前要打包项目(打包成一个egg文件),可以部署到多台主机。
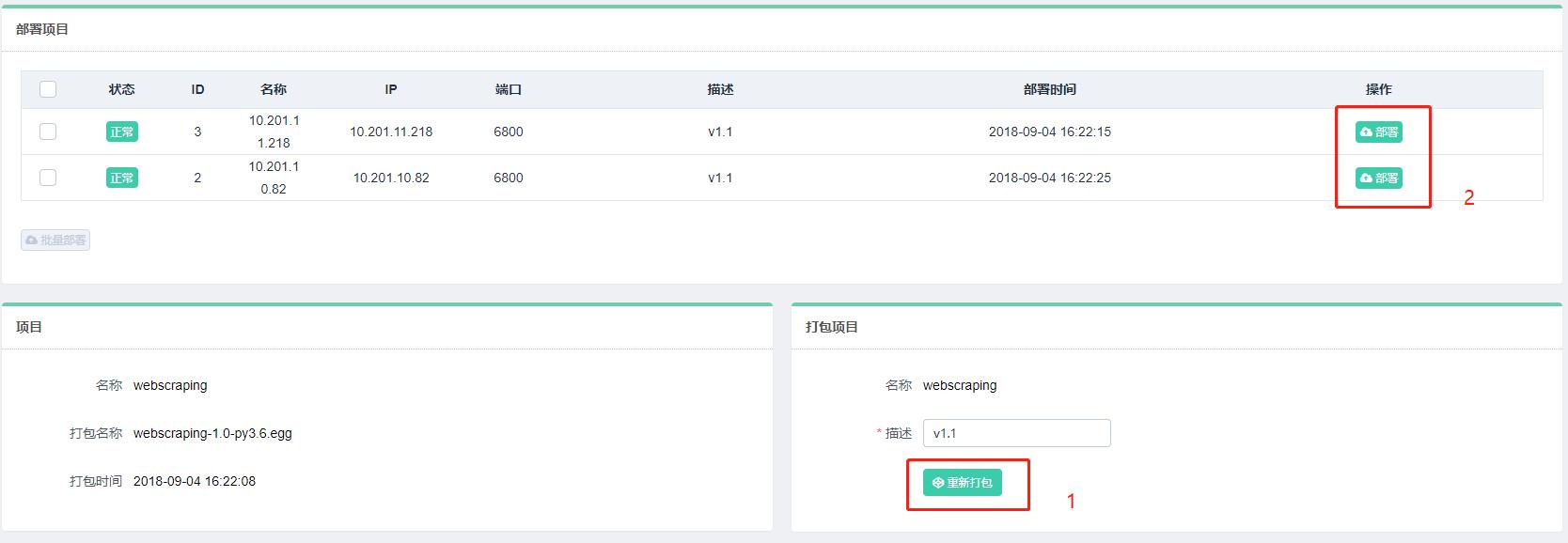
部署完毕后,可以回到主机管理页面进行任务调度。点击调度即可进入任务管理页面,可以查看当前主机所有任务的运行状态:
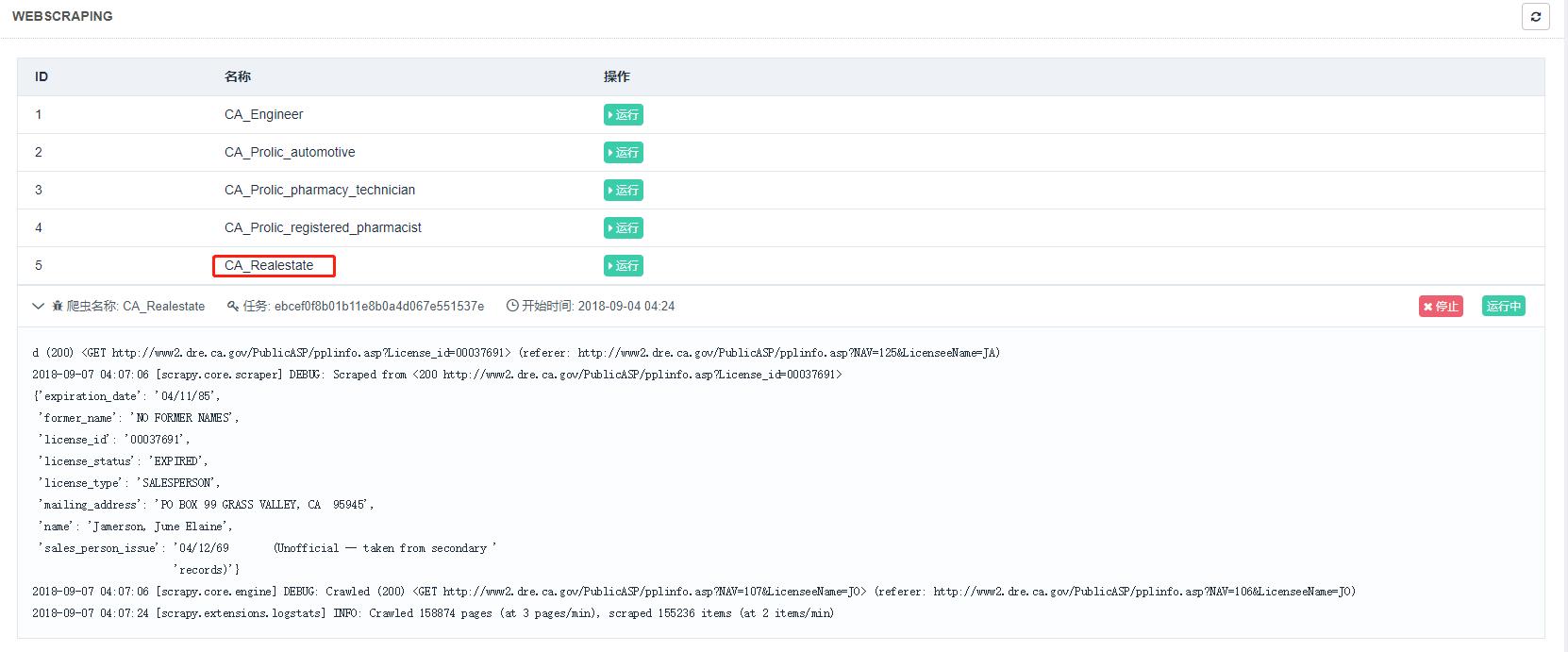
通过点击运行,停止按钮来实现任务的启动和停止,同时可以展开任务条目查看日志详情。
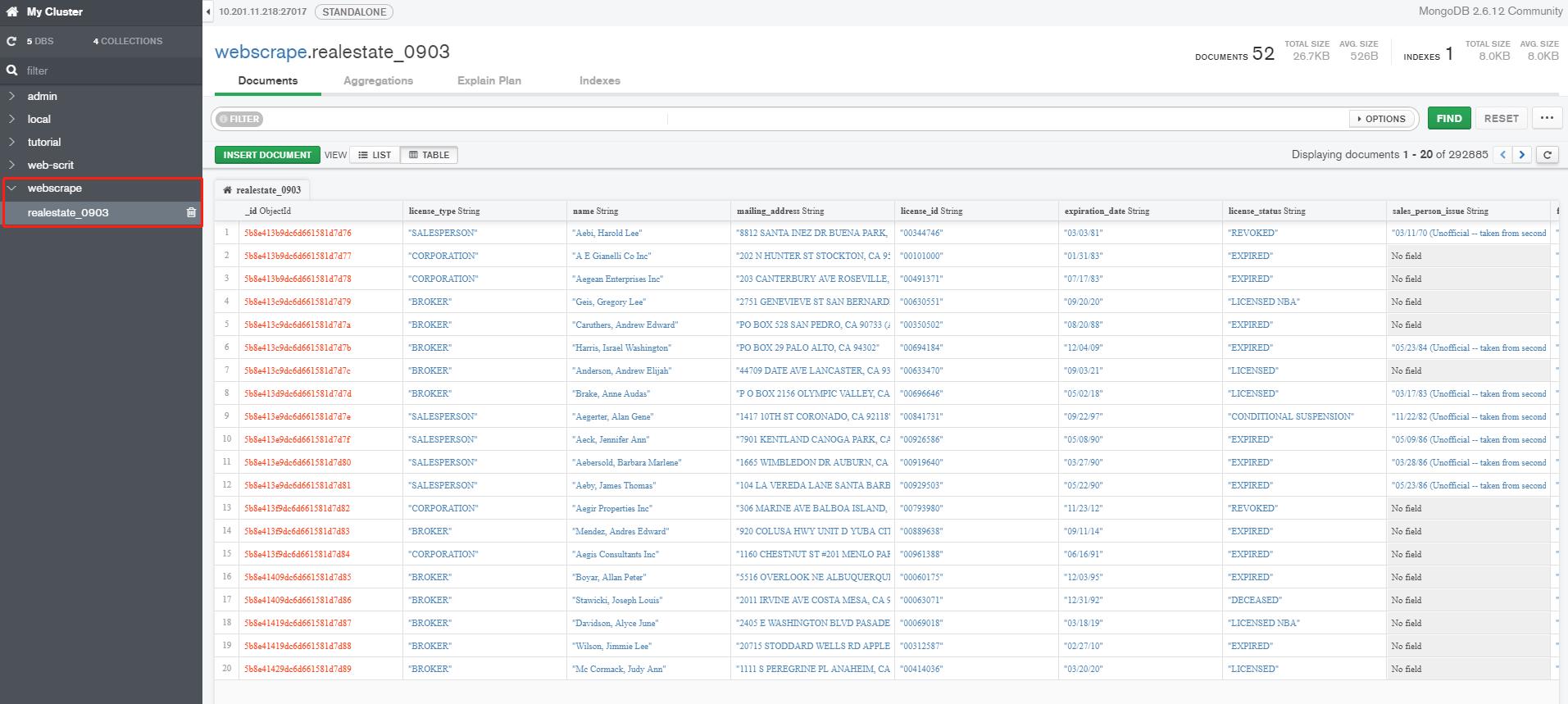
下面是抓取的数据存入MongoDB数据库:
至此,分布式爬虫就完成了,可能说的有点简略,如有不理解的,自行google~
以上是关于Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合的主要内容,如果未能解决你的问题,请参考以下文章