为什么我们需要“分布式数据湖”
Posted 迂704
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么我们需要“分布式数据湖”相关的知识,希望对你有一定的参考价值。
我们的随时都受到来自各方的威胁,数据泄露、数据丢失这些问题一直困扰着我们,我们却无能为力。在这个信息裸奔的年代,我们别无选择,随着技术的进步与成熟我们逐渐找到了对抗的武器,今天就来谈一谈“分布式数据湖”这个概念。
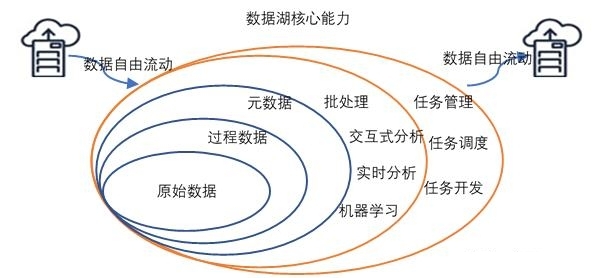
数据湖的概念,来自大数据和机器学习业务。我们日常一定听过数据库,数据库的形式可大可小,是非常独立的数据存储单位,每个数据存储位置都是一个数据库,当数据库之间被打通,形成一个大数据交互结构,就可以理解为数据湖的形象。数据湖是一个安全的集中式辅助存储库,它以数据原始形式和可用于分析的形式存储所有数据。
利用数据湖,可以分解数据孤岛并组合不同类型进行分析,获得分析结果指导更好的业务决策。数据湖的关键问题在于如何解决加密和数据访问授权问题,这和我们现在所说的去中心化数据结构不谋而合。
去中心化数据结构的出现和产生让我们看到了另一种数据存储的可能。

以微信为例,假设微信是一个去中心化的数据存储结构那么我们将不再会看到一些垃圾广告,再也不会看到某个公众号写的“xx个朋友也关注了”。用户之所以深受这些数据的毒害,根本原因在于数据的授权不完全在用户的手上,平台可以随意拿走用户的数据已经见怪不怪了。
大部分分布式系统项目的终极目标都是将数据集中起来放到分布式存储的系统中,但是仅仅是这样远远不够,哪怕我们将数据的支配权归还给用户,也只能能让用户更好的享受平台带来的服务,但是无法产生任何价值。数据依然没有体现任何的价值。那么这个时候就有人提出让数据流动起来,让数据成为数字资产的一种形式。但是摆在我们面前的两大难题分别是如何存储这些数据和如何计算这些数据。
我们所看到的NFT或者DeFi都没能解决这两个问题,因为它们并不需要和现实世界有过多复杂的连通,一旦涉及到现实世界的交互,这一问题的难度就会成几何倍数的攀升。
分布式存储的难点不仅在于存储,更在于如何计算这些数据,数据的流动带来了庞大的计算量,于是XFS系统想出了一个解决办法,我们在不完全抛弃传统中心化存储的前提下融合分布式记账技术的优势,让数据无缝衔接,在一个系统中自由的流动,同时这个系统具备完全独立的两套计算系统,这一设计解决了数据计算的需求。
计算的问题解决了,那么XFS系统如何解决存储的问题,或者说不仅是单纯的存储。分片协议的使用让存储变的更加简单,首先是存储容量的激增,保证了XFS系统能存储比其他分布式系统更多的数据信息,其次,灵活的数据分发与调用让数据流动了起来。使用FIX这一激励机制或许是XFS系统最为正确的选择之一**。

抛弃传统的POW与POS证明转而采用时空证明和复制证明确保统一节点能在长时间内被验证和授权,从而解决了数据的授权问题。**
XFS系统可以简单的看做一个个人的数据库,每个参与到其中的人都是一份子,我们每个人对个人的数据库享有绝对的支配权,我们不再是待宰的羔羊,我们可以拒绝那些我们不认可的授权。
以上是关于为什么我们需要“分布式数据湖”的主要内容,如果未能解决你的问题,请参考以下文章