python面试项目案例
Posted yk 坤帝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python面试项目案例相关的知识,希望对你有一定的参考价值。
个人公众号 yk 坤帝
后台回复 面试项目整理 获取整理资源
1.python第三方模块下载
2.scrapy框架爬虫
3.python使用matplotlib模块绘制折线图相关参数
4.numpy读取本地数据
5.lambda函数用法
6. list,sort,lambda模块区别联系
7.爬虫requests模块解析
8.爬虫bs4,BeautifulSoup解析
9.模拟器打开开发者模式
10. d.get()用法解析
d[i] = d.get(i,0)+1
11.jieba模块用法
12.strip(),split()函数用法
13.chr()函数用法
14.python 从其他文件夹下调用函数
15.统计文件中的词频,并排序
16.输出文件主要内容并统一格式(strip(),split(),sort(),format()
17.提纯文件内容,统一修改格式
18.星座不同格式转换
19.《三国演义》词云统计
20.文件关键词输出排序
1.python第三方模块下载
Windows:
windows系统
进入命令行窗口 win+r
1.pip install 模块 国外镜像源 下载速度慢
2.pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 模块 国内清华镜像源 下载速度快
3.http://pypi.douban.com/simple/ 模块 国内豆瓣镜像源 下载速度快
4.https://pypi.mirrors.ustc.edu.cn/simple/ 模块 阿里云
5.https://pypi.tuna.tsinghua.edu.cn/simple/ 中科大
如果你那儿的网络总是不给力,又不想每次手动添加,可以加在配置文件里一劳永逸。
2.scrapy框架爬虫
1.定位到相应文件夹 Windows: windows系统 进入命令行窗口 win+r
2.scrapy startproject 项目
3.scrapy genspider 名称 www.xxx.com
基于CrawlSpider爬虫父类的创建
scrapy genspider -t crawl 名称 www.xxx.com
分布式爬虫:
执行工程 scrapy runspider xxx.py
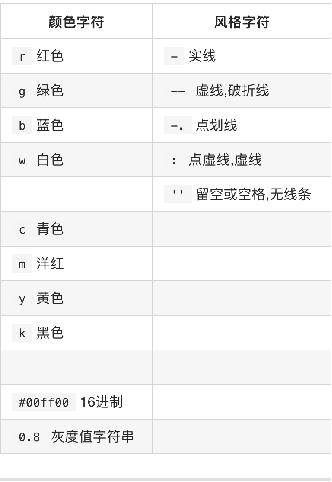
3.python使用matplotlib模块绘制折线图相关参数

4.numpy读取本地数据
np.loadtxt(fname,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)

5.lambda函数用法
个人公众号 yk 坤帝
学习更多硬核知识。
f = open('命运1.txt','r')
txt = f.read()
d = {}
for i in txt:
if i not in ',。?!—《》:‘’“”()□':
d[i] = d.get(i,0) + 1
ls = list(d.items())
ls.sort(key=lambda x:x[1],reverse = True)
print("{}:{}".format(ls[0][0],ls[0][1]))
f.close()
命运1.txt文件在我的资源中下载
6. list,sort,lambda模块区别联系
list.sort(key=lambda x:x[1],reverse = True)
首先说一下 sort函数
sort函数是一个专门对列表进行排序的一个函数,下面是官方的解释
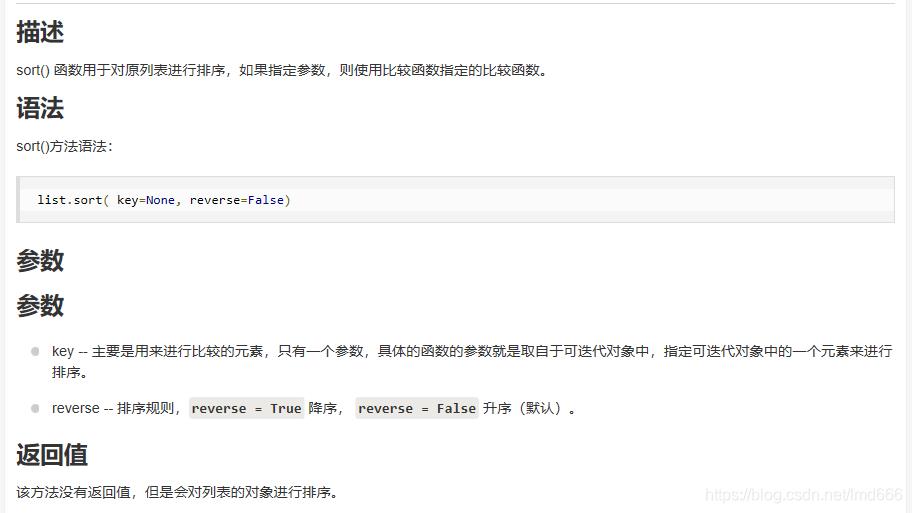
我的理解是,按照列表维度(指数组中第0,1,2个元素)进行排序,默认为从小到大,'reverse=True’则意味着从大到小。
关于维度,形象地理解如下:
list = [('i','he',5), ('q', 'I', 3), ('p', 'they', 1)]中,
x:x[0]中,
x表示列表中的元素,
x[0]表示列表中的元素的索引为0的元素
key=lambda x:x[0]
相当于对’i’, ‘q’, 'p’进行排序,
其中x可以换成其他变量。x:x[1]***
那这个key=lambda x: x[1] 是什么意思呢? 其实可以把lambda看作一个隐函数,在这里可以不用管它,记得有这个就可以,
后面的x: x[1] 为对前面的对象中的第二维数据(即value)的值进行排序。
7.爬虫requests模块解析
# 调用requests模块
个人公众号 yk 坤帝
后台回复 面试项目整理 获取整理资源
import requests
# 获取网页源代码,得到的res是response对象。
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
# 检测请求是否正确响应
print(res.status_code)
res.encoding=res.apparent_encoding
# 正确响应,进行读写操作
# 新建一个名为book的html文档,你看到这里的文件没加路径,它会被保存在程序运行的当前目录下。
# 字符串需要以w读写。你在学习open()函数时接触过它。
if res.status_code == 200:
file = open('book1.html','wb')
# res.text是字符串格式,把它写入文件内。
file.write(res.content)
# 关闭文件
file.close()
8.爬虫bs4,BeautifulSoup解析
from bs4 import BeautifulSoup
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spder-men0.0.html')
print(res.status_code)
soup = BeautifulSoup(res.content,'html.parser')
#soup输出的内容于text一样,但格式不一样
#(soup)
item = soup.find('div')
#print(type(item))
#print(item)
items = soup.find_all('div')
#print(items)
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
soup = BeautifulSoup(res.text,'html.parser')
items = soup.find_all('div',class_='books')
#print(items)
#print(type(items))
for item in items:
#print('想找的数据都包含在这里了:\\n',item)
#print(type(item))
kind = item.find('h2')
title = item.find(class_='title')
bref = item.find(class_='info')
print(kind.text,'\\n',title.text,'\\n',title['href'],'\\n',bref.text)
print(type(kind),type(title),type(bref))
9.模拟器打开开发者模式
模拟器打开开发者模式
appium连接模拟器进行自动化测试时,需要使用adb来连接模拟器,具体操作步骤:
打开模拟器
在cmd中输入:adb devices
此时出现的列表中找不到对应的安卓设备
在cmd中输入:adb connect 127.0.0.1:5555(5555为模拟器对应的端口号,此处为雷电模拟器)
再次输入:adb devices,列表中找到对应模拟器表面连接成功
下面是其他几款流行的模拟器单位端口:
adb 命令连接模拟器
天天模拟器端口 6555
adb connect 127.0.0.1:6555
海马模拟器
adb connect 127.0.0.1:26944
mumu模拟器 6.0
adb connect 127.0.0.1:7555
逍遥游模拟器
adb connect 127.0.0.1:21503
夜神模拟器
adb connect 127.0.0.1:62001
10. d.get()用法解析
d[i] = d.get(i,0)+1
f = open('命运.txt','r')
txt = f.read()
d = {}
for i in txt:
if i not in '\\n':
d[i] = d.get(i,0)+1
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True) # 此行可以按照词频由高到低排序
for k in range(10):
print(ls[k][0],end = '')
f.close()
d[i] = d.get(i,0)+1
d[i]代表字典d中符号i对应的键值
d.get()有两个参数时,理解为当i对应键值不存在时返回第二个参数作为键值,在本例中代表当i键值不存在时,返回0为i的键值,加1代表每次遍历到i键值加一,第二次遍历到i时,d.get(i,0)返回1,以此类推。
第三次遍历到i时,d.get(i,0)返回2,对应字典中i的键值
11.jieba模块用法
import jieba
s = input("请输入一个字符串")
n = len(s)
m = len(jieba.lcut(s))
print("中文字符数为{},中文词语数为{}。".format(n, m))
12.strip(),split()函数用法
ls = line.strip(’\\n’).split(’,’)
strip() 方法用于移除字符串头尾指定的字符(默认为空格)。
line.strip(’\\n’) 移除换行符并返回列表。
split()通过指定分隔符对字符串进行切片。
line.strip(’\\n’).split(’,’) 通过逗号进行切片。
f = open('sensor.txt','r',encoding = 'utf-8')
fo = open('earpa001.txt','w')
lines = f.readlines()
for line in lines:
ls = line.strip('\\n').split(',')
if ls[1] == ' earpa001':
fo.write('{},{},{},{}\\n'.format(ls[0],ls[1],ls[2],ls[3]))
f.close()
fo.close()
13.chr()函数用法
键盘输入一个9800到9811之间的正整数n,作为Unicode编码,把n-1、n和n+1三个Unicode编码对应字符按照如下格式要求输出到屏幕:宽度为11个字符,加号字符+填充,居中。
例如:键盘输入:9802
屏幕输出:++++???++++
n = eval(input("请输入一个数字:"))
print("{:+^11}".format(chr(n-1)+chr(n)+chr(n+1)))
14.python 从其他文件夹下调用函数
import sys
import os
o_path = os.getcwd()
sys.path.append(o_path)
from 代理池 import ip代理池
两个文件夹在同一根文件夹下
- o_path = os.getcwd() 获得根文件夹的路径
- sys.path.append(o_path) 添加路径
- from 代理池 import ip代理池
15.统计文件中的词频,并排序
1.对“命运. txt”文件进行字符频次统计,输出频次最高的中文字符(不包含标点符号)及其频次,字符与频次之间采用英文冒号”:”分隔,示例格式如下:
理:224.
2.对“命运. txt”文件进行字符频次统计,按照频次由高到低,屏幕输出前10个频次最高的字符,不包含回车符,字符之间无间隔,连续输出,示例格式如下:
理斯卫… (后略,共10个字符)
3.对“命运. txt”文件进行字符频次统计,将所有字符按照频次从高到低排序,字符包括中文、标点、英文等符号,但不包含空格和回车。将排序后的字符及频次输出到考生文件夹下,文件名为“命运-频次排序. txt”。字符与频次之间采用英文冒号”:”分隔,各字符之间采用英文逗号”,”分隔,参考CSV格式,最后无逗号,文件内部示例格式如下:
理:224,斯:120,卫:100
个人公众号 yk 坤帝
后台回复 面试项目整理 获取整理资源
f = open('命运.txt','r')
txt = f.read()
d = {}
for i in txt:
if i not in ",。?!《》【】“”‘’":
d[i] = d.get(i,0)+1
ls = list(d.items())
ls.sort(key=lambda x:x[1],reverse = True)
print("{}:{}".format(ls[0][0],ls[0][1]))
f.close()
个人公众号 yk 坤帝
后台回复 面试项目整理 获取整理资源
f = open('命运.txt','r')
txt = f.read()
d = {}
for i in txt:
if i not in '\\n':
d[i] = d.get(i,0)+1
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True) # 此行可以按照词频由高到低排序
for k in range(10):
print(ls[k][0],end='')
f.close()
个人公众号 yk 坤帝
后台回复 面试项目整理 获取整理资源
f = open('命运.txt','r')
fi = open('命运-频次排序.txt','w')
txt = f.read()
d = {}
for i in txt:
if i not in '\\n':
d[i] = d.get(i,0)+1
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True) # 此行可以按照词频由高到低排序
s=""
for k in ls:
s+="{}:{}".format(k[0],k[1])+','
fi.write(s[:-1])
f.close()
fi.close()
16.输出文件主要内容并统一格式(strip(),split(),sort(),format()
下面所示为一套由公司职员随身佩戴的位置传感器采集的数据,文件名称为“sensor.txt”,其内容示例如下:
2016/5/31 0:05, vawelon001, 1, 1
2016/5/31 0:20, earpa001, 1,1
2016/5/31 2:26, earpa001,1, 6
… (略)
第一列是传感器获取数据的时间,第二列是传感器的编号,第三列是传感器所在的楼层,第四列是传感器所在的位置区域编号。
1-1,5
1-4, 3
… (略)
含义如下:
第1行“1-1,5”中1-1表示1楼1号区域,5表示出现5次;
第2行“1-4,3”中1-4表示1楼4号区域,3表示出现3次;
1.读入sensor. txt文件中的数据,提取出传感器编号为earpa00的所有数据,将结果输出保存到“earpa001. txt”文件。输出文件格式要求:原数据文件中的每行记录写入新文件中,行尾无空格,无空行。参考格式如下:
2016/5/31 7:11, earpa001,2, 4
2016/5/31 8:02, earpa001,3, 4
2016/5/31 9:22, earpa001,3,4
… (略)
f = open('sensor.txt','r',encoding='utf-8')
fo = open('earpa001.txt','w')
ls = f.readlines()
for line in ls:
lt = line.strip('\\n').split(',')
if lt[1] == ' earpa001':
fo.write('{},{},{},{}\\n'.format(lt[0],lt[1],lt[2],lt[3]))
f.close()
fo.close()
2.读入“earpa001. txt” 文件中的数据,统计earpa001对应的职员在各楼层和区域出现的次数,保存到“earpa001 _count. txt” 文件,每条记录一 -行,位置信息和出现的次数之间用英文半角逗号隔开,行尾无空格,无空行。参考格式如下。
f = open('earpa001.txt','r',encoding = 'utf-8')
fo = open('earpa001_count.txt','w')
ls = f.readlines()
d = {}
for line in ls:
lt = line.strip('\\n').split(',')
key = lt[2]+'-'+lt[3]
d[key] = d.get(key,0)+1
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True) # 该语句用于排序
for k in ls:
fo.write('{},{}\\n'.format(k[0],k[1]))
f.close()
fo.close()
17.提纯文件内容,统一修改格式
《论语》是儒家学派的经典著作之一,主要记录了孔子及其弟子言行。这里给出了一个网络版本的《论语》,文件名称为“论语.txt”,其内容采用逐句“原文”与逐句“注释”相结合的形式组织,通过【原文】标记《论语》原文内容,通过【注释】标记《论语》注释内容,具体文件格式框架请参考“论语.txt”文件。
1.提取“论语.txt”文件中的原文内容,输出保存到考生文件夹下,文件名为“论语-原文.txt”。具体要求:仅保留“论语.txt”文件中所有【原文】标签下面的内容,不保留标签,并去掉每行行首空格及行尾空格,无空行。原文小括号及内部数字是源文件中注释项的标记,请保留。示例输出文件格式请参考“论语-原文-输出示例.txt”文件。注意:示例输出文件帮助考生了解输出格式,不作它用。
fi = open("论语.txt", 'r')
fo = open("论语-原文.txt", 'w')
flag = False
for line in fi:
if '【原文】' in line:
flag = True
continue
if '【注释】' in line:
flag = False
line = line.strip(" \\n")
if flag == True:
if line:
fo.write(line+'\\n')
fi.close()
fo.close()
2.对“论语-原文.txt”或“论语.txt”文件进一步提纯,去掉每行文字中所有小括号及内部数字,保存为“论文-提纯原文.txt”文件。示例输出文件格式请参考“论语-提纯原文-输出示例.txt”文件。注意:示例输出文件帮助考生了解输出格式,不作它用。
```python
fi = open("论语-原文.txt", 'r')
fo = open("论语-提纯原文.txt", 'w')
for line in fi:
for i in range(23):
line=line.replace('('+str(i)+')','')
fo.write(line)
fi.close()
fo.close()
18.星座不同格式转换
二千多年前希腊的天文学家希巴克斯命名十二星座,它们是水瓶座、双鱼座、白羊座、金牛座、双子座、巨蟹座、狮子座、处女座、天秤座、天蝎座、射手座、摩羯座。给出一个CSV文件(PY301-SunSign.csv),内容示例如下:
序号,星座,开始月日,结束月日,Unicode
1,水瓶座,120,218,9810
2,双色座,219,320,9811
3,白羊座,321,419,9800
4,金牛座,420,520,9801
5,双子座,521,621,9802
…(略)
以第1行为例,120表示1月20日,218表示2月18日,9810是Unicode码。
1.读入CSV文件中数据,获得用户输入。根据用户输入的星座名称,输出此星座的出生日期范围。
参考输入和输出示例格式如下:
请输入星座中文名称(例如,双子座):双子座
双子座的生日位于521-621之间
个人公众号 yk 坤帝
学习更多硬核知识。
f = open('PY301-SunSign.csv','r')
ls = []
s = input('请输入星座中文名称(例如,双子座):')
for line in f.readlines():
ls = line.strip('\\n').split(',')
if ls[1] == s:
print("{}的生日位于{}-{}之间".format(ls[1],ls[2],ls[3]))
f.close()
2.读入CSV文件中数据,获得用户输入。用户键盘输入一组范围是1-12的整数作为序号,序号间采用空格分隔,以回车结束。屏幕输出这些序号对应的星座的名称、字符编码以及出生日期范围,每个星座的信息一行。本次屏幕显示完成后,重新回到输入序号的状态。
参考输入和输出示例格式如下:
请输入星座序号(例如,5):5 10
双子座(9802)的生日是5月21日至6月21日之间
天蝎座(9807)的生日是10月24日至11月22日之间
请输入星座序号(例如,5):
个人公众号 yk 坤帝
学习更多硬核知识。
f = open('PY301-SunSign.csv','r')
ls = []
ls = f.readlines()
while True:
s = input('请输入星座序号(例如,5):')
for i in s.split():
for line in ls:
lt = line.strip('\\n').split(',')
if i == lt[0]:
print("{}({})的生日是{}月{}日至{}月{}日之间".format(lt[1],lt[4],lt[2][:-2],lt[2][-2:],lt[3][:-2],lt[3][-2:]))
f.close()
3.在PY301-3.py文件中修改代码,对键盘输入的每个序号做合法性处理。如果输入的数字不合法,请输出“输入星座编号有误!”,継纹输出后续信息,然后重新回到输入序号的状态。
参考输入和输出示例格式如下:
请输入星座序号(例如,5):5 14 11
双子座(9802)的生日是5月21日至6月21日之间
输入星座序号有误!
射手座(9808)的生日是11月23日至12月21日之间
请输入星座序号(例如,5):
个人公众号 yk 坤帝
学习更多硬核知识。
f = 以上是关于python面试项目案例的主要内容,如果未能解决你的问题,请参考以下文章
Express实战 - 应用案例- realworld-API - 路由设计 - mongoose - 数据验证 - 密码加密 - 登录接口 - 身份认证 - token - 增删改查API(代码片段