吊炸天的 Kafka 图形化工具 Eagle,必须推荐给你!
Posted JAVA炭烧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吊炸天的 Kafka 图形化工具 Eagle,必须推荐给你!相关的知识,希望对你有一定的参考价值。
摘要
Kafka是当下非常流行的消息中间件,据官网透露,已有成千上万的公司在使用它。最近实践了一波Kafka,确实很好很强大。今天我们来从三个方面学习下Kafka:Kafaka在Linux下的安装,Kafka的可视化工具,Kafka和SpringBoot结合使用。希望大家看完后能快速入门Kafka,掌握这个流行的消息中间件!
Kafka简介
Kafka是由LinkedIn公司开发的一款开源分布式消息流平台,由Scala和Java编写。主要作用是为处理实时数据提供一个统一、高吞吐、低延迟的平台,其本质是基于发布订阅模式的消息引擎系统。
Kafka具有以下特性:
- 高吞吐、低延迟:Kafka收发消息非常快,使用集群处理消息延迟可低至2ms。
- 高扩展性:Kafka可以弹性地扩展和收缩,可以扩展到上千个broker,数十万个partition,每天处理数万亿条消息。
- 永久存储:Kafka可以将数据安全地存储在分布式的,持久的,容错的群集中。
- 高可用性:Kafka在可用区上可以有效地扩展群集,某个节点宕机,集群照样能够正常工作。
Kafka安装
我们将采用Linux下的安装方式,安装环境为CentOS 7.6。此处没有采用Docker来安装部署,个人感觉直接安装更简单(主要是官方没提供Docker镜像)!
- 首先我们需要下载Kafka的安装包,下载地址:mirrors.bfsu.edu.cn/apache/kafk…
- 下载完成后将Kafka解压到指定目录:
cd /mydata/kafka/
tar -xzf kafka_2.13-2.8.0.tgz
- 解压完成后进入到解压目录:
cd kafka_2.13-2.8.0
- 虽然有消息称Kafka即将移除Zookeeper,但是在Kafka最新版本中尚未移除,所以启动Kafka前还是需要先启动Zookeeper;
- 启动Zookeeper服务,服务将运行在
2181端口;
# 后台运行服务,并把日志输出到当前文件夹下的zookeeper-out.file文件中
nohup bin/zookeeper-server-start.sh config/zookeeper.properties > zookeeper-out.file 2>&1 &
- 由于目前Kafka是部署在Linux服务器上的,外网如果想要访问,需要修改Kafka的配置文件
config/server.properties,修改下Kafka的监听地址,否则会无法连接;
############################# Socket Server Settings #############################
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://192.168.5.78:9092
- 最后启动Kafka服务,服务将运行在
9092端口。
# 后台运行服务,并把日志输出到当前文件夹下的kafka-out.file文件中
nohup bin/kafka-server-start.sh config/server.properties > kafka-out.file 2>&1 &
Kafka命令行操作
接下来我们使用命令行来操作下Kafka,熟悉下Kafka的使用。
- 首先创建一个叫
consoleTopic的Topic;
bin/kafka-topics.sh --create --topic consoleTopic --bootstrap-server 192.168.5.78:9092
- 接下来查看Topic;
bin/kafka-topics.sh --describe --topic consoleTopic --bootstrap-server 192.168.5.78:9092
- 会显示如下Topic信息;
Topic: consoleTopic TopicId: tJmxUQ8QRJGlhCSf2ojuGw PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: consoleTopic Partition: 0 Leader: 0 Replicas: 0 Isr: 0
- 向Topic中发送消息:
bin/kafka-console-producer.sh --topic consoleTopic --bootstrap-server 192.168.5.78:9092
- 直接在命令行中输入信息即可发送;

- 重新打开一个窗口,通过如下命令可以从Topic中获取消息:
bin/kafka-console-consumer.sh --topic consoleTopic --from-beginning --bootstrap-server 192.168.5.78:9092

Kafka可视化
使用命令行操作Kafka确实有点麻烦,接下来我们试试可视化工具
kafka-eagle。
安装JDK
如果你使用的是CentOS的话,默认没有安装完整版的JDK,需要自行安装!
- 下载JDK 8,下载地址:mirrors.tuna.tsinghua.edu.cn/AdoptOpenJD…
- 下载完成后将JDK解压到指定目录;
cd /mydata/java
tar -zxvf OpenJDK8U-jdk_x64_linux_xxx.tar.gz
mv OpenJDK8U-jdk_x64_linux_xxx.tar.gz jdk1.8
- 在
/etc/profile文件中添加环境变量JAVA_HOME。
vi /etc/profile
# 在profile文件中添加
export JAVA_HOME=/mydata/java/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
# 使修改后的profile文件生效
. /etc/profile
安装kafka-eagle
- 下载
kafka-eagle的安装包,下载地址:github.com/smartloli/k…
- 下载完成后将
kafka-eagle解压到指定目录;
cd /mydata/kafka/
tar -zxvf kafka-eagle-web-2.0.5-bin.tar.gz
- 在
/etc/profile文件中添加环境变量KE_HOME;
vi /etc/profile
# 在profile文件中添加
export KE_HOME=/mydata/kafka/kafka-eagle-web-2.0.5
export PATH=$PATH:$KE_HOME/bin
# 使修改后的profile文件生效
. /etc/profile
-
安装mysql并添加数据库
ke,kafka-eagle之后会用到它; -
修改配置文件
$KE_HOME/conf/system-config.properties,主要是修改Zookeeper的配置和数据库配置,注释掉sqlite配置,改为使用MySQL;
######################################
# multi zookeeper & kafka cluster list
######################################
kafka.eagle.zk.cluster.alias=cluster1
cluster1.zk.list=localhost:2181
######################################
# kafka eagle webui port
######################################
kafka.eagle.webui.port=8048
######################################
# kafka sqlite jdbc driver address
######################################
# kafka.eagle.driver=org.sqlite.JDBC
# kafka.eagle.url=jdbc:sqlite:/hadoop/kafka-eagle/db/ke.db
# kafka.eagle.username=root
# kafka.eagle.password=www.kafka-eagle.org
######################################
# kafka mysql jdbc driver address
######################################
kafka.eagle.driver=com.mysql.cj.jdbc.Driver
kafka.eagle.url=jdbc:mysql://localhost:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
kafka.eagle.username=root
kafka.eagle.password=root
- 使用如下命令启动
kafka-eagle;
$KE_HOME/bin/ke.sh start
- 命令执行完成后会显示如下信息,但并不代表服务已经启动成功,还需要等待一会;

- 再介绍几个有用的
kafka-eagle命令:
# 停止服务
$KE_HOME/bin/ke.sh stop
# 重启服务
$KE_HOME/bin/ke.sh restart
# 查看服务运行状态
$KE_HOME/bin/ke.sh status
# 查看服务状态
$KE_HOME/bin/ke.sh stats
# 动态查看服务输出日志
tail -f $KE_HOME/logs/ke_console.out
- 启动成功可以直接访问,输入账号密码
admin:123456,访问地址:http://192.168.5.78:8048/
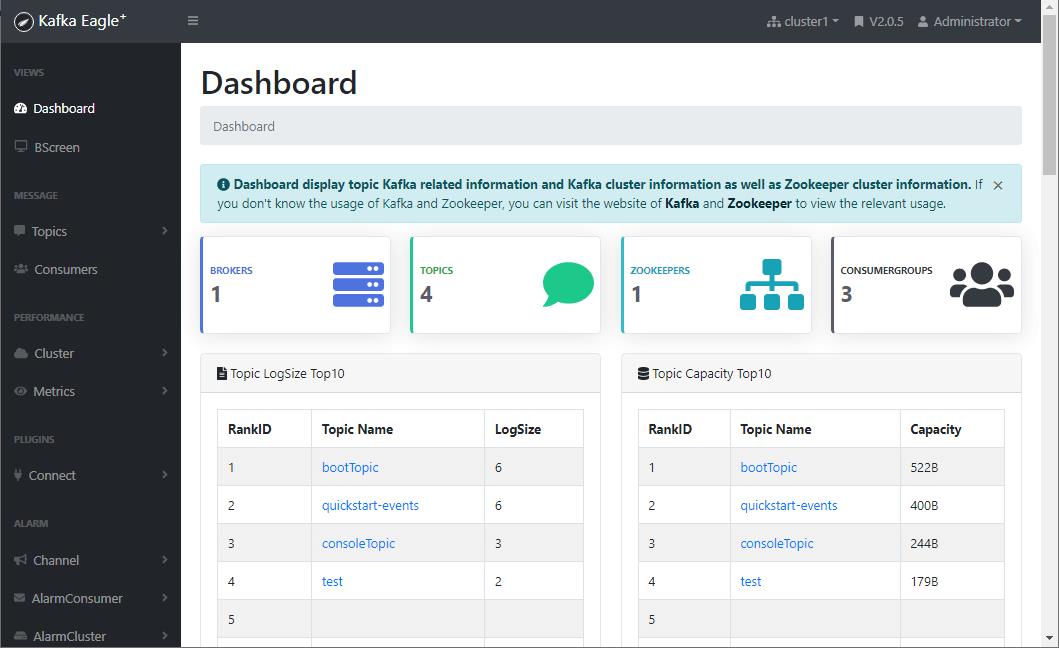
- 登录成功后可以访问到Dashboard,界面还是很棒的!
可视化工具使用
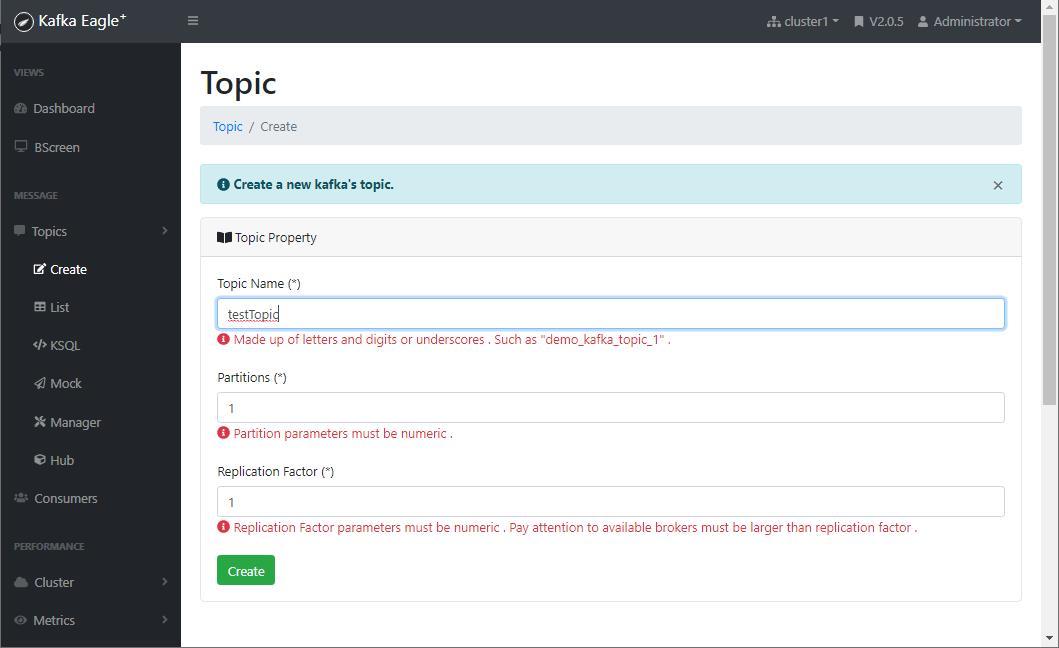
- 之前我们使用命令行创建了Topic,这里可以直接通过界面来创建;
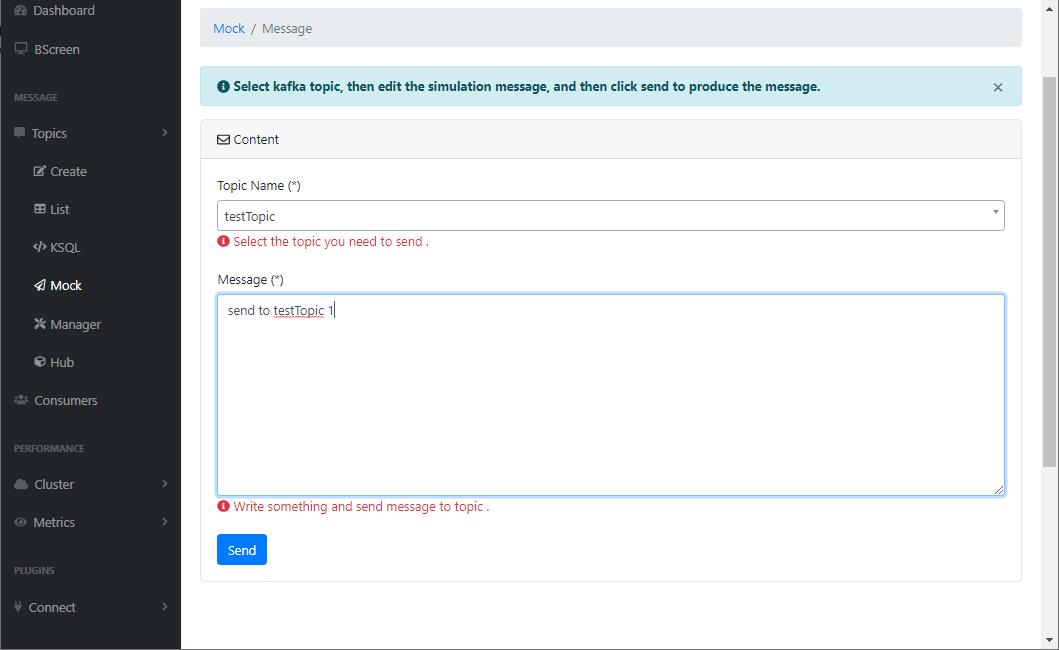
- 我们还可以直接通过
kafka-eagle来发送消息;
- 我们可以通过命令行来消费Topic中的消息;
bin/kafka-console-consumer.sh --topic testTopic --from-beginning --bootstrap-server 192.168.5.78:9092
- 控制台获取到信息显示如下;

- 还有一个很有意思的功能叫
KSQL,可以通过SQL语句来查询Topic中的消息;
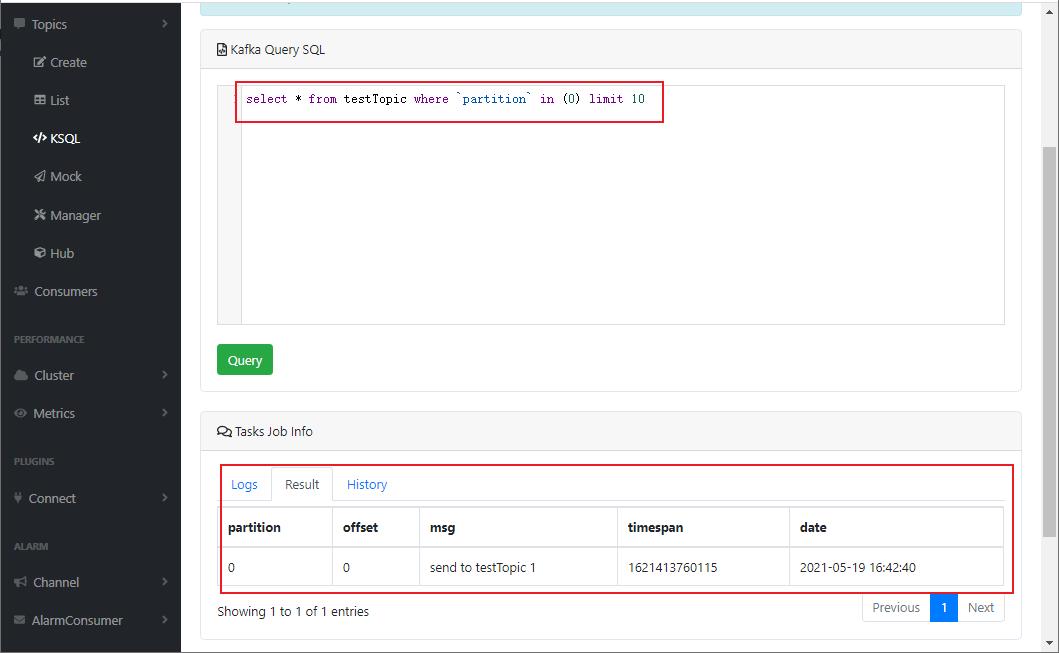
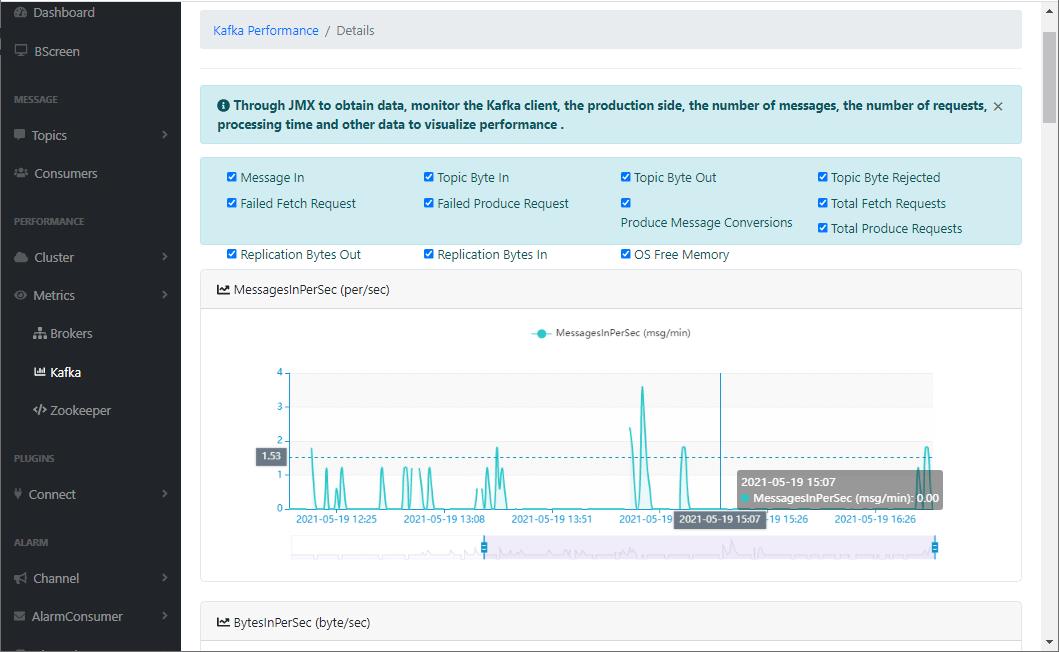
- 可视化工具自然少不了监控,如果你想开启
kafka-eagle对Kafka的监控功能的话,需要修改Kafka的启动脚本,暴露JMX的端口;
vi kafka-server-start.sh
# 暴露JMX端口
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70"
export JMX_PORT="9999"
fi
- 来看下监控图表界面;
- 还有一个很骚气的监控大屏功能;

- 还有Zookeeper的命令行功能,总之功能很全,很强大!

SpringBoot整合Kafka
在SpringBoot中操作Kafka也是非常简单的,比如Kafka的消息模式很简单,没有队列,只有Topic。
- 首先在应用的
pom.xml中添加Spring Kafka依赖;
<!--Spring整合Kafka-->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.7.1</version>
</dependency>
- 修改应用配置文件
application.yml,配置Kafka服务地址及consumer的group-id;
server:
port: 8088
spring:
kafka:
bootstrap-servers: '192.168.5.78:9092'
consumer:
group-id: "bootGroup"
- 创建一个生产者,用于向Kafka的Topic中发送消息;
/**
* Kafka消息生产者
* Created by macro on 2021/5/19.
*/
@Component
public class KafkaProducer {
@Autowired
private KafkaTemplate kafkaTemplate;
public void send(String message){
kafkaTemplate.send("bootTopic",message);
}
}
- 创建一个消费者,用于从Kafka中获取消息并消费;
/**
* Kafka消息消费者
* Created by macro on 2021/5/19.
*/
@Slf4j
@Component
public class KafkaConsumer {
@KafkaListener(topics = "bootTopic")
public void processMessage(String content) {
log.info("consumer processMessage : {}",content);
}
}
- 创建一个发送消息的接口,调用生产者去发送消息;
/**
* Kafka功能测试
* Created by macro on 2021/5/19.
*/
@Api(tags = "KafkaController", description = "Kafka功能测试")
@Controller
@RequestMapping("/kafka")
public class KafkaController {
@Autowired
private KafkaProducer kafkaProducer;
@ApiOperation("发送消息")
@RequestMapping(value = "/sendMessage", method = RequestMethod.GET)
@ResponseBody
public CommonResult sendMessage(@RequestParam String message) {
kafkaProducer.send(message);
return CommonResult.success(null);
}
}
- 直接在Swagger中调用接口进行测试;
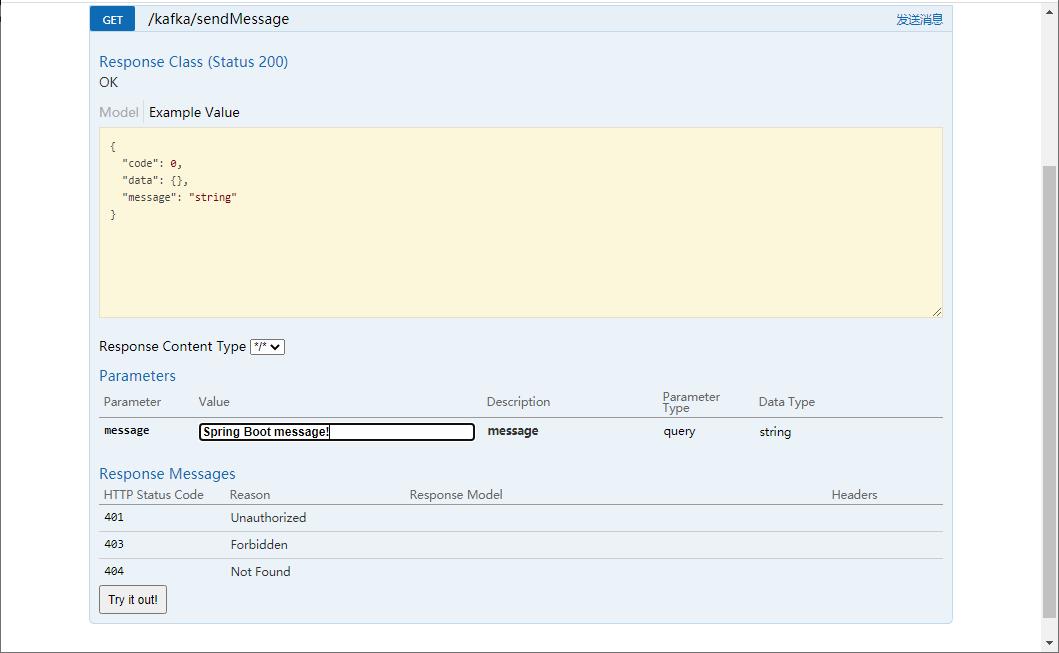
- 项目控制台会输出如下信息,表明消息已经被接收并消费掉了。
2021-05-19 16:59:21.016 INFO 2344 --- [ntainer#0-0-C-1] c.m.mall.tiny.component.KafkaConsumer : consumer processMessage : Spring Boot message!
总结
通过本文的一波实践,大家基本就能入门Kafka了。安装、可视化工具、结合SpringBoot,这些基本都是和开发者相关的操作,也是学习Kafka的必经之路。
参考资料
-
Kafka官方文档:kafka.apache.org/quickstart
-
kafka-eagle官方文档:www.kafka-eagle.org/articles/do…
项目源码地址
本文 GitHub github.com/macrozheng/… 已经收录,欢迎大家Star!
一直想整理出一份完美的面试宝典,但是时间上一直腾不开,这套一千多道面试题宝典,结合今年金三银四各种大厂面试题,以及 GitHub 上 star 数超 30K+ 的文档整理出来的,我上传以后,毫无意外的短短半个小时点赞量就达到了 13k,说实话还是有点不可思议的。
一千道互联网 Java 工程师面试题
内容涵盖:Java、MyBatis、ZooKeeper、Dubbo、Elasticsearch、Memcached、Redis、MySQL、Spring、SpringBoot、SpringCloud、RabbitMQ、Kafka、Linux等技术栈(485页)

初级—中级—高级三个级别的大厂面试真题
阿里云——Java 实习生/初级
List 和 Set 的区别 HashSet 是如何保证不重复的
HashMap 是线程安全的吗,为什么不是线程安全的(最好画图说明多线程环境下不安全)?
HashMap 的扩容过程
HashMap 1.7 与 1.8 的 区别,说明 1.8 做了哪些优化,如何优化的?
对象的四种引用
Java 获取反射的三种方法
Java 反射机制
Arrays.sort 和 Collections.sort 实现原理 和区别
Cloneable 接口实现原理
异常分类以及处理机制
wait 和 sleep 的区别
数组在内存中如何分配
答案展示:


美团——Java 中级
BeanFactory 和 ApplicationContext 有什么区别
Spring Bean 的生命周期
Spring IOC 如何实现
说说 Spring AOP
Spring AOP 实现原理
动态代理(cglib 与 JDK)
Spring 事务实现方式
Spring 事务底层原理
如何自定义注解实现功能
Spring MVC 运行流程
Spring MVC 启动流程
Spring 的单例实现原理
Spring 框架中用到了哪些设计模式
为什么选择 Netty
说说业务中,Netty 的使用场景
原生的 NIO 在 JDK 1.7 版本存在 epoll bug
什么是 TCP 粘包/拆包
TCP 粘包/拆包的解决办法
Netty 线程模型
说说 Netty 的零拷贝
Netty 内部执行流程
答案展示:


蚂蚁金服——Java 高级
题 1:
jdk1.7 到 jdk1.8 Map 发生了什么变化(底层)?
ConcurrentHashMap
并行跟并发有什么区别?
jdk1.7 到 jdk1.8 java 虚拟机发生了什么变化?
如果叫你自己设计一个中间件,你会如何设计?
什么是中间件?
ThreadLock 用过没有,说说它的作用?
Hashcode()和 equals()和==区别?
mysql 数据库中,什么情况下设置了索引但无法使用?
mysql 优化会不会,mycat 分库,垂直分库,水平分库?
分布式事务解决方案?
sql 语句优化会不会,说出你知道的?
mysql 的存储引擎了解过没有?
红黑树原理?
题 2:
说说三种分布式锁?
redis 的实现原理?
redis 数据结构,使⽤场景?
redis 集群有哪⼏种?
codis 原理?
是否熟悉⾦融业务?记账业务?蚂蚁⾦服对这部分有要求。
好啦~展示完毕,大概估摸一下自己是青铜还是王者呢?
前段时间,在和群友聊天时,把今年他们见到的一些不同类别的面试题整理了一番,于是有了以下面试题集,也一起分享给大家~
如果你觉得这些内容对你有帮助,可以加入csdn进阶交流群,领取资料
基础篇


JVM 篇

MySQL 篇



Redis 篇



由于篇幅限制,详解资料太全面,细节内容太多,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!
如果你觉得这些内容对你有帮助,可以加入csdn进阶交流群,领取资料
以上是关于吊炸天的 Kafka 图形化工具 Eagle,必须推荐给你!的主要内容,如果未能解决你的问题,请参考以下文章
吊炸天的 Kafka 图形化工具 Eagle,必须推荐给你!
吊炸天的 Docker 图形化工具 Portainer,必须推荐给你!
牛掰!吊炸天的 Docker 图形化工具 Portainer,必须推荐给你!