Pytorch RNN 实现新闻数据分类
Posted 我是小白呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch RNN 实现新闻数据分类相关的知识,希望对你有一定的参考价值。
概述
RNN (Recurrent Netural Network) 是用于处理序列数据的神经网络. 所谓序列数据, 即前面的输入和后面的输入有一定的联系.
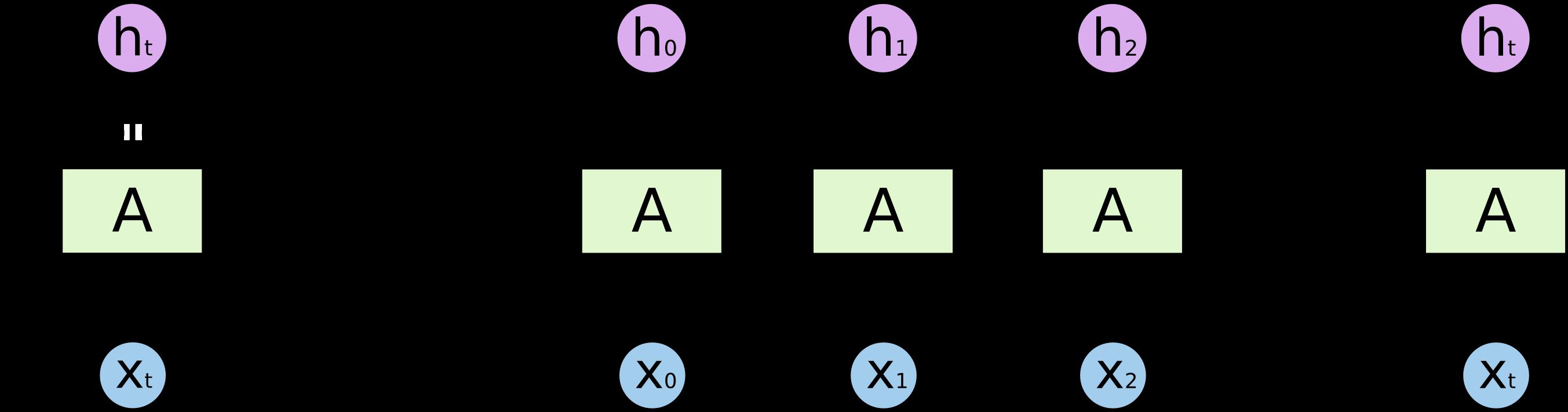
数据集
我们将使用 THUCNews 的一个子数据集, 该数据集包含 10 个类别的新闻数据, 单个类别有 10000 条数据.

Text RNN 模型
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Config(object):
"""配置参数"""
def __init__(self, dataset, embedding):
self.model_name = 'TextCNN'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()] # 类别名单
self.vocab_path = dataset + '/data/vocab.pkl' # 词表
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.log_path = dataset + '/log/' + self.model_name
self.embedding_pretrained = torch.tensor(
np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32'))\\
if embedding != 'random' else None # 预训练词向量
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.dropout = 0.5 # 随机失活
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.n_vocab = 0 # 词表大小,在运行时赋值
self.num_epochs = 20 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 1e-3 # 学习率
self.embed = self.embedding_pretrained.size(1)\\
if self.embedding_pretrained is not None else 300 # 字向量维度
self.filter_sizes = (2, 3, 4) # 卷积核尺寸
self.num_filters = 256 # 卷积核数量(channels数)
'''Convolutional Neural Networks for Sentence Classification'''
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.convs = nn.ModuleList(
[nn.Conv2d(1, config.num_filters, (k, config.embed)) for k in config.filter_sizes])
self.dropout = nn.Dropout(config.dropout)
self.fc = nn.Linear(config.num_filters * len(config.filter_sizes), config.num_classes)
def conv_and_pool(self, x, conv):
x = F.relu(conv(x)).squeeze(3)
x = F.max_pool1d(x, x.size(2)).squeeze(2)
return x
def forward(self, x):
#print (x[0].shape)
out = self.embedding(x[0])
out = out.unsqueeze(1)
out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)
out = self.dropout(out)
out = self.fc(out)
return out
评估函数
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from sklearn import metrics
import time
from utils import get_time_dif
from tensorboardX import SummaryWriter
# 权重初始化,默认xavier
def init_network(model, method='xavier', exclude='embedding', seed=123):
for name, w in model.named_parameters():
if exclude not in name:
if 'weight' in name:
if method == 'xavier':
nn.init.xavier_normal_(w)
elif method == 'kaiming':
nn.init.kaiming_normal_(w)
else:
nn.init.normal_(w)
elif 'bias' in name:
nn.init.constant_(w, 0)
else:
pass
def train(config, model, train_iter, dev_iter, test_iter, writer):
start_time = time.time()
model.train()
optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)
# 学习率指数衰减,每次epoch:学习率 = gamma * 学习率
# scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
total_batch = 0 # 记录进行到多少batch
dev_best_loss = float('inf')
last_improve = 0 # 记录上次验证集loss下降的batch数
flag = False # 记录是否很久没有效果提升
# writer = SummaryWriter(log_dir=config.log_path + '/' + time.strftime('%m-%d_%H.%M', time.localtime()))
for epoch in range(config.num_epochs):
print('Epoch [{}/{}]'.format(epoch + 1, config.num_epochs))
# scheduler.step() # 学习率衰减
for i, (trains, labels) in enumerate(train_iter):
# print (trains[0].shape)
outputs = model(trains)
model.zero_grad()
loss = F.cross_entropy(outputs, labels)
loss.backward()
optimizer.step()
if total_batch % 100 == 0:
# 每多少轮输出在训练集和验证集上的效果
true = labels.data.cpu()
predic = torch.max(outputs.data, 1)[1].cpu()
train_acc = metrics.accuracy_score(true, predic)
dev_acc, dev_loss = evaluate(config, model, dev_iter)
if dev_loss < dev_best_loss:
dev_best_loss = dev_loss
torch.save(model.state_dict(), config.save_path)
improve = '*'
last_improve = total_batch
else:
improve = ''
time_dif = get_time_dif(start_time)
msg = 'Iter: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}, Time: {5} {6}'
print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, improve))
writer.add_scalar("loss/train", loss.item(), total_batch)
writer.add_scalar("loss/dev", dev_loss, total_batch)
writer.add_scalar("acc/train", train_acc, total_batch)
writer.add_scalar("acc/dev", dev_acc, total_batch)
model.train()
total_batch += 1
if total_batch - last_improve > config.require_improvement:
# 验证集loss超过1000batch没下降,结束训练
print("No optimization for a long time, auto-stopping...")
flag = True
break
if flag:
break
writer.close()
test(config, model, test_iter)
def test(config, model, test_iter):
# test
model.load_state_dict(torch.load(config.save_path))
model.eval()
start_time = time.time()
test_acc, test_loss, test_report, test_confusion = evaluate(config, model, test_iter, test=True)
msg = 'Test Loss: {0:>5.2}, Test Acc: {1:>6.2%}'
print(msg.format(test_loss, test_acc))
print("Precision, Recall and F1-Score...")
print(test_report)
print("Confusion Matrix...")
print(test_confusion)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
def evaluate(config, model, data_iter, test=False):
model.eval()
loss_total = 0
predict_all = np.array([], dtype=int)
labels_all = np.array([], dtype=int)
with torch.no_grad():
for texts, labels in data_iter:
outputs = model(texts)
loss = F.cross_entropy(outputs, labels)
loss_total += loss
labels = labels.data.cpu().numpy()
predic = torch.max(outputs.data, 1)[1].cpu().numpy()
labels_all = np.append(labels_all, labels)
predict_all = np.append(predict_all, predic)
acc = metrics.accuracy_score(labels_all, predict_all)
if test:
report = metrics.classification_report(labels_all, predict_all, target_names=config.class_list, digits=4)
confusion = metrics.confusion_matrix(labels_all, predict_all)
return acc, loss_total / len(data_iter), report, confusion
return acc, loss_total / len(data_iter)
主函数
import time
import torch
import numpy as np
from train_eval import train, init_network
from importlib import import_module
import argparse
from tensorboardX import SummaryWriter
parser = argparse.ArgumentParser(description='Chinese Text Classification')
parser.add_argument('--model', type=str, default="TextRNN",
help='choose a model: TextCNN, TextRNN, FastText, TextRCNN, TextRNN_Att, DPCNN, Transformer')
parser.add_argument('--embedding', default='pre_trained', type=str, help='random or pre_trained')
parser.add_argument('--word', default=False, type=bool, help='True for word, False for char')
args = parser.parse_args()
if __name__ == '__main__':
dataset = 'THUCNews' # 数据集
# 搜狗新闻:embedding_SougouNews.npz, 腾讯:embedding_Tencent.npz, 随机初始化:random
embedding = 'embedding_SougouNews.npz'
if args.embedding == 'random':
embedding = 'random'
model_name = args.model # TextCNN, TextRNN,
if model_name == 'FastText':
from utils_fasttext import build_dataset, build_iterator, get_time_dif
embedding = 'random'
else:
from utils import build_dataset, build_iterator, get_time_dif
x = import_module('models.' + model_name)
config = x.Config(dataset, embedding)
np.random.seed(1)
torch.manual_seed(1)
torch.cuda.manual_seed_all(1)
torch.backends.cudnn.deterministic = True # 保证每次结果一样
start_time = time.time()
print("Loading data...")
vocab, train_data, dev_data, test_data = build_dataset(config, args.word)
train_iter = build_iterator(train_data, config)
dev_iter = build_iterator(dev_data, config)
test_iter = build_iterator(test_data, config)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
# train
config.n_vocab = len(vocab)
model = x.Model(config).to(config.device)
writer = SummaryWriter(log_dir=config.log_path + '/' + time.strftime('%m-%d_%H.%M', time.localtime()))
if model_name != 'Transformer':
init_network(model)
print(model.parameters)
train(config, model, train_iter, dev_iter, test_iter, writer)
输出结果
Loading data...
Vocab size: 4762
180000it [00:03, 56090.03it/s]
10000it [00:00, 32232.86it/s]
10000it [00:00, 61166.60it/s]
Time usage: 0:00:04
<bound method Module.parameters of Model(
(embedding): Embedding(4762, 300)
(lstm): LSTM(300, 128, num_layers=2, batch_first=True, dropout=0.5, bidirectional=True)
(fc): Linear(in_features=256, out_features=10, bias=True)
)>
Epoch [1/10]
Iter: 0, Train Loss: 2.3, Train Acc: 11.52%, Val Loss: 2.3, Val Acc: 10.00%, Time: 0:00:00 *
Iter: 100, Train Loss: 1.3, Train Acc: 50.39%, Val Loss: 1.3, Val Acc: 49.63%, Time: 0:00:02 *
Iter: 200, Train Loss: 0.72, Train Acc: 77.54%, Val Loss: 0.74, Val Acc: 75.92%, Time: 0:00:04 *
Iter: 300, Train Loss: 0.47, Train Acc: 84.18%, Val Loss: 0.55, Val Acc: 82.34%, Time: 0:00:06 *
Epoch [2/10]
Iter: 400, Train Loss: 0.5, Train Acc: 83.59%, Val Loss: 0.48, Val Acc: 85.13%, Time: 0:00:07 *
Iter: 500, Train Loss: 0.41, Train Acc: 88.48%, Val Loss: 0.43, Val Acc: 86.42%, Time: 0:00:09 *
Iter: 600, Train Loss: 0.37, Train Acc: 88.48%, Val Loss: 0.41, Val Acc: 86.93%, Time: 0:00:11 *
Iter: 700, Train Loss: 0.42, Train Acc: 86.33%, Val Loss: 0.37, Val Acc: 87.90%, Time: 0:00:12 *
Epoch [3/10]
Iter: 800, Train Loss: 0.35, Train Acc: 89.06%, Val Loss: 0.39, Val Acc: 87.81%, Time: 0:00:14
Iter: 900, Train Loss: 0.3, Train Acc: 89.06%, Val Loss: 0.36, Val Acc: 88.51%, Time: 0:00:16 *
Iter: 1000, Train Loss: 0.3, Train Acc: 90.43%, Val Loss: 0.36, Val Acc: 88.81%, Time: 0:00:17
Epoch [4/10]
Iter: 1100, Train Loss: 0.29, Train Acc: 90.82%, Val Loss: 0.34, Val Acc: 89.07%, Time: 0:00:19 *
Iter: 1200, Train Loss: 0.28, Train Acc: 90.82%, Val Loss: 0.33, Val Acc: 89.43%, Time: 0:00:21 *
Iter: 1300, Train Loss: 0.28, Train Acc: 90.62%, Val Loss: 0.33, Val Acc: 89.41%, Time: 0:00:22
Iter: 1400, Train Loss: 0.25, Train Acc: 91.60%, Val Loss: 0.33, Val Acc: 89.37%, Time: 0:00:24
Epoch [5/10]
Iter: 1500, Train Loss: 0.26, Train Acc: 91.80%, Val Loss: 0.34, Val Acc: 89.56%, Time: 0:00:26
Iter: 1600, Train Loss: 0.18, Train Acc: 94.34%, Val Loss: 0.35, Val Acc: 89.14%, Time: 0:00:27
Iter: 1700, Train Loss: 0.23, Train Acc: 92.58%, Val Loss: 0.33, Val Acc: 89.80%, Time: 0:00:29 *
Epoch [6/10]
Iter: 1800, Train Loss: 0.23, Train Acc: 92.97%, Val Loss: 0.34, Val Acc: 89.46%, Time: 0:00:31
Iter: 1900, Train Loss: 0.18, Train Acc: 94.34%, Val Loss: 0.32, Val Acc: 89.76%, Time: 0:00:33 *
Iter: 2000, Train Loss: 0.16, Train Acc: 93.75%, Val Loss: 0.34, Val Acc: 89.28%, Time: 0:00:34
Iter: 2100, Train Loss: 0.22, Train Acc: 92.19%, Val Loss: 0.32, Val Acc: 90.12%, Time: 0:00:36 *
Epoch [7/10]
Iter: 2200, Train Loss: 0.21, Train Acc: 92.77%, Val Loss: 0.34, Val Acc: 89.67%, Time: 0:00:38
Iter: 2300, Train Loss: 0.18, Train Acc: 94.73%, Val Loss: 0.35, Val Acc: 89.81%, Time: 0:00:39
Iter: 2400, Train Loss: 0.21, Train Acc: 92.38%, Val Loss: 0.36, Val Acc: 89.21%, Time: 0:00:41
Epoch [8/10]
Iter: 2500, Train Loss: 0.19, Train Acc: 93.75%, Val Loss: 0.35, Val Acc: 89.56%, Time: 0:00:43
Iter: 2600, Train Loss: 0.19, Train Acc: 94.53%, Val Loss: 0.31, Val Acc: 90.38%, Time: 0:00:45 *
Iter: 2700, Train Loss: 0.2, Train Acc: 93.75%, Val Loss: 0.33, Val Acc: 89.95%, Time: 0:00:46
Iter: 2800, Train Loss: 0.15, Train Acc: 94.92%, Val Loss: 0.33, Val Acc: 90.05%, Time: 0:00:48
Epoch [9/10]
Iter: 2900, Train Loss: 0.22, Train Acc: 93.16%, Val Loss: 0.35, Val Acc: 89.47%, Time: 0:00:49
Iter: 3000, Train Loss: 0.16, Train Acc: 94.53%, Val Loss: 0.36, Val Acc: 89.72%, Time: 0:00:51
Iter: 3100, Train Loss: 0.19, Train Acc: 93.95%, Val Loss: 0.37, Val Acc: 89.51%, Time: 0:00:53
Epoch [10/10]
Iter: 3200, Train Loss: 0.13, Train Acc: 95.70%, Val Loss: 0.35, Val Acc: 89.67%, Time: 0:00:54
Iter: 3300, Train Loss: 0.2, Train Acc: 93.36%, Val Loss: 0.35, Val Acc: 90.27%, Time: 0:00:56
Iter: 3400, Train Loss: 0.12, Train Acc: 96.48%, Val Loss: 0.34, Val Acc: 89.92%, Time: 0:00:57
Iter: 3500, Train Loss: 0.12, Train Acc: 95.70%, Val Loss: 0.35, Val Acc: 89.98%, Time: 0:00:59
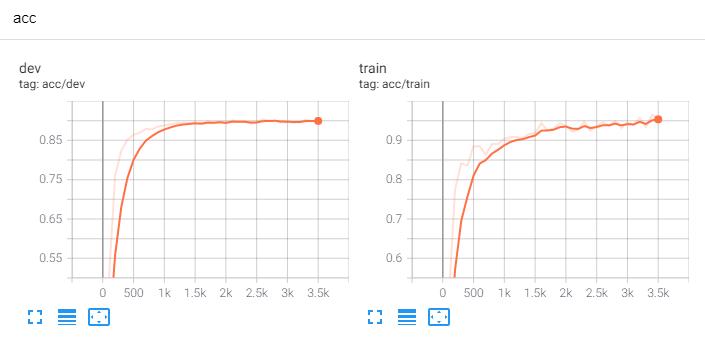
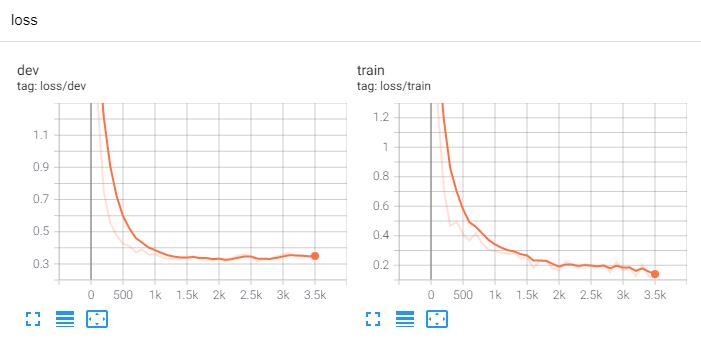
Test Loss: 0.3, Test Acc: 90.66%
Precision, Recall and F1-Score...
precision recall f1-score support
finance 0.8777 0.9040 0.8906 1000
realty 0.9353 0.9110 0.9230 1000
stocks 0.8843 0.7950 0.8373 1000
education 0.9319 0.9440 0.9379 1000
science 0.8297 0.8770 0.8527 1000
society 0.9012 0.9210 0.9110 1000
politics 0.9001 0.8740 0.8869 1000
sports 0.9788 0.9680 0.9734 1000
game 0.9299 0.9290 0.9295 1000
entertainment 0.9015 0.9430 0.9218 1000
accuracy 0.9066 10000
macro avg 0.9070 0.9066 0.9064 10000
weighted avg 0.9070 0.9066 0.9064 10000
Confusion Matrix...
[[904 11 38 5 16 10 9 1 1 5]
[ 14 911 14 6 9 12 10 4 6 14]
[ 72 25 795 5 57 1 33 0 9 3]
[ 2 1 2 944 10 18 7 0 5 11]
[ 11 6 18 8 877 17 15 0 32 16]
[ 4 12 1 18 7 921 14 1 7 15]
[ 16 3 21 14 26 29 874 4 2 11]
[ 1 1 3 1 3 2 4 968 0 17]
[ 2 1 5 5 39 4 3 1 929 11]
[ 4 3 2 7 13 8 2 10 8 943]]
Time usage: 0:00:00
以上是关于Pytorch RNN 实现新闻数据分类的主要内容,如果未能解决你的问题,请参考以下文章
pytorch+huggingface实现基于bert模型的文本分类(附代码)