小爬虫学习——Scrapy框架
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小爬虫学习——Scrapy框架相关的知识,希望对你有一定的参考价值。
文章目录
一、简介
Scrapy是纯Python开发的一个高效、结构化的网页抓取框架;
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。 Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试 Scrapy使用了Twisted 异步网络库来处理网络通讯。
使用原因:
1.为了更利于我们将精力集中在请求与解析上
2.企业级的要求
二、安装(Windows)
scrapy支持Python2.7和python3.4以上版本。
python包可以用全局安装(也称为系统范围),也可以安装在用户空间中。
直接安装
- 在https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted下载对应的Twisted的版本文件
- 在命令行进入到Twisted的目录 执行
pip install +Twisted文件名 - 执行
pip install scrapy
三、运行流程
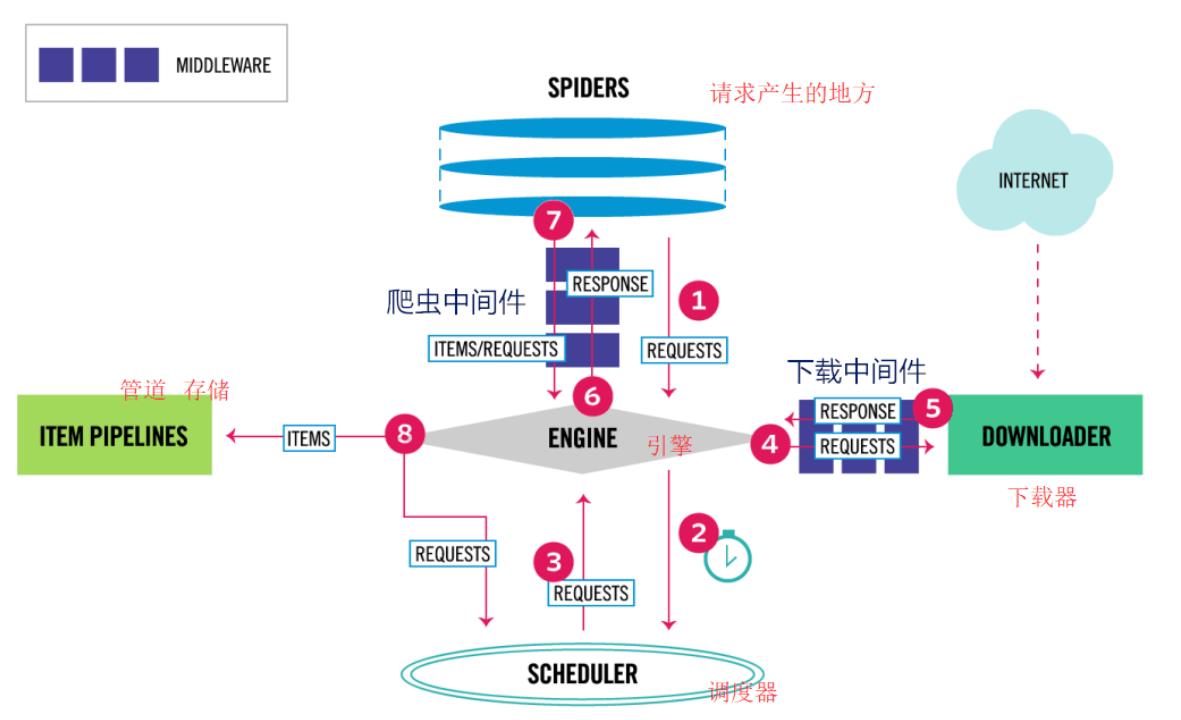
spiders:网页爬虫
items:项目
engine:引擎
scheduler:调度器
downloader:下载器
item pipelines:项目管道
middleware:中间设备,中间件
3.1、数据流
上图显示了Scrapy框架的体系结构及其组件,以及系统内部发生的数据流。(由红色的箭头显示)
Scrapy中的数据流由执行引擎控制,流程如下:
- 首先从网页爬虫获取初始的请求
- 将请求放入调度模块,然后获取下一个需要爬取的请求
- 调度模块返回下一个需要爬取的请求给引擎
- 引擎将请求发送给下载器,依次穿过所有的下载中间件
- 一旦页面下载完成,下载器会返回一个响应包含了页面数据,然后再依次穿过所有的下载中间件。
- 引擎从下载器接收到响应,然后发送给爬虫进行解析,依次穿过所有的爬虫中间件
- 爬虫处理接收到的响应,然后解析出item和生成新的请求,并发送给引擎
- 引擎将已经处理好的item发送给管道组件,将生成好的新的请求发送给调度模块,并请求下一个请求
- 该过程重复,直到调度程序不再有请求为止。
3.2、组件介绍
-
Scrapy Engine(引擎)
引擎负责控制系统所有组件之间的数据流,并在发生某些操作时触发事件。 -
scheduler(调度器)
调度程序接收来自引擎的请求,将它们排入队列,以便稍后引擎请求它们。 -
Downloader(下载器)
下载程序负责获取web页面并将它们提供给引擎,引擎再将它们提供给spider。 -
spider(爬虫)
爬虫是由用户编写的自定义的类,用于解析响应,从中提取数据,或其他要抓取的请求。 -
Item pipeline(管道)
管道负责在数据被爬虫提取后进行后续处理。典型的任务包括清理,验证和持久性(如将数据存储在数据库中) -
下载中间件
下载中间件是位于引擎和下载器之间的特定的钩子,它们处理从引擎传递到下载器的请求,以及下载器传递到引擎的响应。
如果你要执行以下操作之一,请使用Downloader中间件:
①在请求发送到下载程序之前处理请求(即在scrapy将请求发送到网站之前)
②在响应发送给爬虫之前
③直接发送新的请求,而不是将收到的响应传递给蜘蛛
④将响应传递给爬行器而不获取web页面;
⑤默默的放弃一些请求 -
爬虫中间件
爬虫中间件是位于引擎和爬虫之间的特定的钩子,能够处理传入的响应和传递出去的item和请求。
如果你需要以下操作请使用爬虫中间件:
①处理爬虫回调之后的请求或item
②处理start_requests
③处理爬虫异常
④根据响应内容调用errback而不是回调请
3.3、简单使用
3.3.1、项目命令
1.创建项目
scrapy startproject <project_name> [project_dir] # ps: "<>"表示必填 ,"[]"表示可选
示例:
scrapy startproject db
2.cd 到项目下,创建爬虫文件
scrapy genspider [options] <name> <domain>
#name:爬虫文件名
#domain:域名
示例 :
scrapy genspider db250 movie.douban.com
#注意:会创建在项目/spider下 ;其中db250是爬虫文件名,movie.douban.com是域名
3.setting 里配置
是否遵循机器协议 修改 ROBOTSTXT_OBEY=False;
默认请求头 取消注释(必要时添加User-Agent) DEFAULT_REQUEST_HEADERS
4.运行项目
scrapy crawl 爬虫文件名 #注重流程
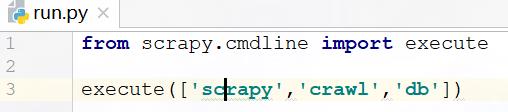
补:这里有个小技巧可以不用命令运行,可以像运行普通文件一样直接右击“运行”:
① 在项目里随便建一个文件;
② 导入模块:from scrapy.cmdline import execute
③ 写上代码:execute(['scrapy','crawl','db']) (db:指的是你的爬虫文件名)
示例(下面案例项目的创建):
1.创建项目
(这里我项目的名称是:db250 ,项目文件夹是:scrapy1)
2.cd 到项目下
创建爬虫文件:(这里我爬虫文件名:db)
3.setting 里配置
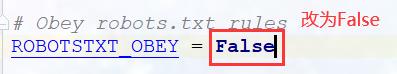

4.运行项目
方法一:
方法二:
然后直接执行该文件就可以运行整个项目了
3.3.2、shell 交互式平台
scrapy shell start_url #获取我们项目中的response测试 xpath进行匹配
示例(下面案例项目分析):
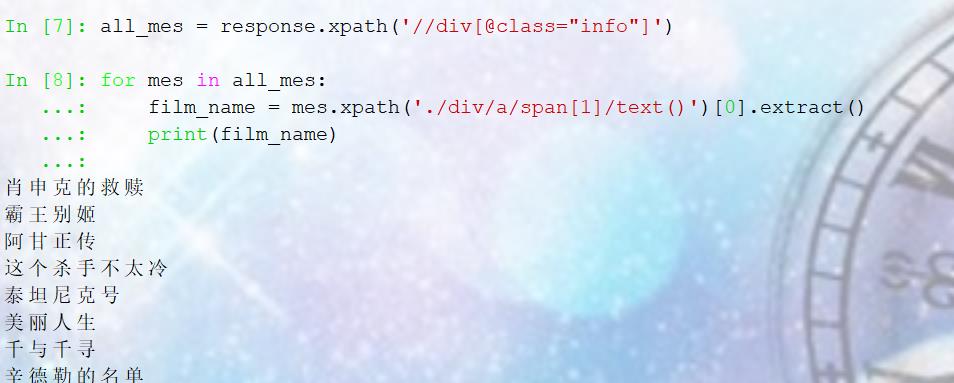
接下来我们就可以直接用response.xpath() 直接提取数据(下面是我提取的数据的节选),同理我们就可以得到:导演的信息、评分
四、小案例:爬取豆瓣电影
4.1、目标数据要求
-
豆瓣电影250个电影信息
-
电影信息为:电影名字,导演信息(可以包含演员信息),评分
-
将电影信息直接本地保存
-
将电影信息通过管道进行保存
4.2、项目文件
4.2.1、爬虫文件
import scrapy
from ..items import Db250Item #是一个安全的字典
class DbSpider(scrapy.Spider):
name = 'db' #爬虫文件名字 必须存在且唯一
# allowed_domains = ['movie.douban.com'] #允许的域名 可以不存在,不存在:任何域名都可以
start_urls = ['http://movie.douban.com/'] #初始url 必须要存在
page = 0 #要爬取的页码
def parse(self, response): #解析函数 处理响应数据
all_mes = response.xpath('//div[@class="info"]')
for mes in all_mes:
#电影名字
film_name = mes.xpath('./div/a/span[1]/text()')[0].extract()
#评分
score = mes.xpath('./div/div/span[2]/text()')[0].extract()
#导演信息
director = mes.xpath('./div/p/text()')[0].extract().strip()
#使用管道存储
item = Db250Item() #创建Db250Item对象 当成字典来使用
item['film_name'] = film_name
item['score'] = score
item['director'] = director
yield item
#发送新一页的请求
#构造url
self.page+=1
if self.page == 3: #这里我们就只爬取了3页,太多的话ip可能会被封
return
#页码是有规律的,根据规律,我们就可以构建出各个页面的URL了
page_url = 'https://movie.douban.com/top250?start={}&filter='.format(self.page*25)
yield scrapy.Request(page_url)
4.2.2、items文件
import scrapy
class DbItem(scrapy.Item):
class Db250Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
film_name = scrapy.Field()
score = scrapy.Field()
director = scrapy.Field()
4.2.3、piplines文件
import json
class Db250Pipeline(object):
def open_spider(self,spider): #注意这个函数名是固定的
#爬虫文件开启,此方法执行
self.f=open("film_pipe.txt","w",encoding="utf-8")
def process_item(self, item, spider):
json_data=json.dumps(dict(item),ensure_ascii=False)+"\\n"
self.f.write(json_data)
return item
def close_spider(self,spider): #注意这个函数名是固定的
# 爬虫文件关闭,此方法执行
self.f.close() #关闭文件
4.2.4、settings文件
(这里我就只写需要我们修改的几个部分)
#1.机器协议 设置False
ROBOTSTXT_OBEY = False
#2.取消默认请求头的注释,添加User-Agent
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36 Edg/91.0.864.48'
}
#3.这个也是特别重要的一点 打开管道
ITEM_PIPELINES = {
'db250.pipelines.Db250Pipeline': 300,
}
结果:

以上是关于小爬虫学习——Scrapy框架的主要内容,如果未能解决你的问题,请参考以下文章
最网最全python框架--scrapy(体系学习,爬取全站校花图片),学完显著提高爬虫能力(附源代码),突破各种反爬