python帮室友避险——爬虫加可视化
Posted 肥学大师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python帮室友避险——爬虫加可视化相关的知识,希望对你有一定的参考价值。
案件目录
起因
这都七月十几号了,大学生都该放假结束回家了,我们专业因为实训回去的比较晚我因为特殊情况回去更晚,正巧铁柱也没回呢。一大早铁柱探着脑袋来到我们宿舍。。。

铁柱:都走了?(试探性的询问暗指宿舍的人)
肥学:没啊,(从床上的帘子里伸出头)
肥学:wc!铁柱你这是怎么一脸姨妈疼样,出啥事了
铁柱:我的那条最好看的内衣(裤衩)不见了,你瞅见了吗
肥学:谁看你那玩意啊,没见!(他然后走了)
。。。
然后下午三点多突然:
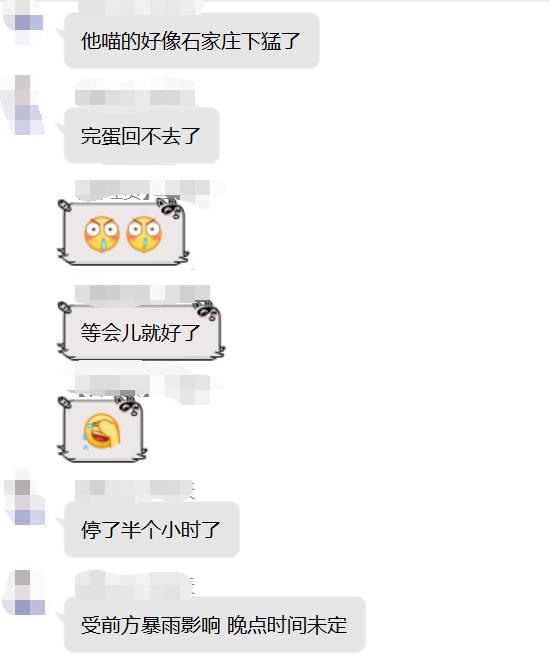
真的为他捏了把汗,正在我担心的时候。。。。等等,铁柱的裤衩,他遇暴雨这两者难道有什么内在的联系?
难道说内裤是他偷得糟了报应?
说着我展开了调查
调查(用到爬虫+数据分析和可视化)
思路
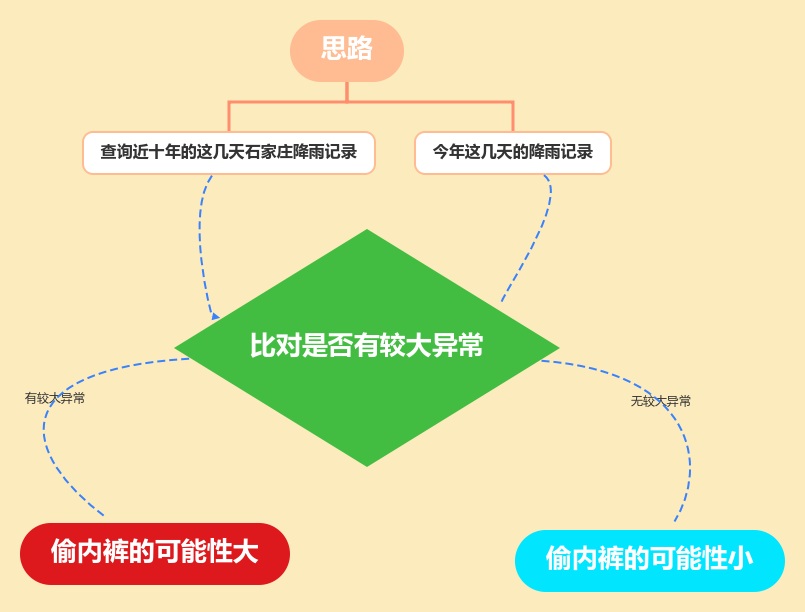
说干就干
爬虫爬取近十年石家庄近几天天气
先介绍我们即将用到的库
import requests # 用于URL的请求和数据的获取
import time # 用于时间的停顿
import random # 用于随机数的生成
import pandas as pd # 用于数据的导出
import re # 用于正则表达式的使用
接着我们先在来造一个爬虫常用手段之一的伪装请求头
headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': 'widget_dz_id=54511; widget_dz_cityValues=,; timeerror=1; defaultCityID=54511; defaultCityName=%u5317%u4EAC; Hm_lvt_a3f2879f6b3620a363bec646b7a8bcdd=1516245199; Hm_lpvt_a3f2879f6b3620a363bec646b7a8bcdd=1516245199; addFavorite=clicked',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/63.0.3236.0 Safari/537.36'
}
获取方式也很简单,在这个链接点击之后进入页面
然后——右键——如果你是谷歌浏览器点击检查出现
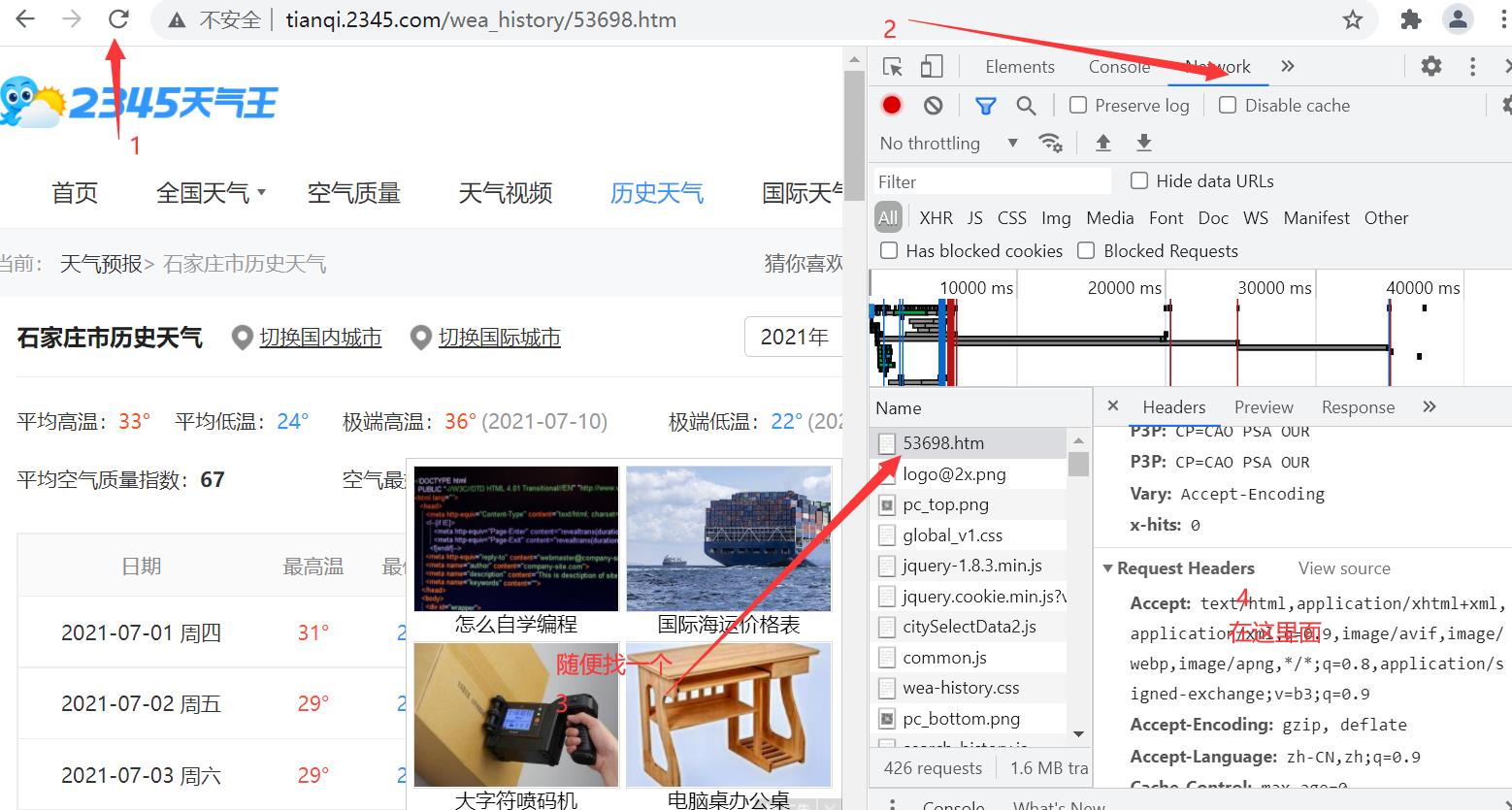
伪造请求头是为了让网站以为是一个正常用户在请求数据,不是一只爬虫,不拒绝你的请求。
接着我们就去得到存放历史天气数据的的文件链接经过分析2016年以前链接是:'http://tianqi.2345.com/t/wea_history/js/58362_%s%s.js' % (year, month)这种形式后来的链接有了一点小小的差异,肥学直接放在一起了
urls = []
for year in range(2012, 2022): # 遍历2011年至2017年
for month in range(7, 8): # 遍历1月份至12月份
# 用于2011年~2016年的链接与2017年的链接存在一点点差异,需要分支处理
if year <= 2016:
urls.append('http://tianqi.2345.com/t/wea_history/js/58362_%s%s.js' % (year, month))
else:
# 2017年的月份中,1~9月前面都有数字0,需要分支处理
if month < 10:
urls.append('http://tianqi.2345.com/t/wea_history/js/%s0%s/53698_%s0%s.js' % (year, month, year, month))
else:
urls.append('http://tianqi.2345.com/t/wea_history/js/%s%s/53698_%s%s.js' % (year, month, year, month))
果然的到的数据是json格式:

接着我们就用正则匹配的方式来获取我们要的值(不会正则的话可以在这个链接推荐的网站里面学习:链接)
for url in urls:
print(url)
seconds = random.randint(1, 6) # 每次循环,都随机生成一个3~6之间的整数
response = requests.get(url, headers=headers).text # 发送url链接的请求,并返回响应数据
ymd = re.findall("ymd:'(.*?)',", response) # 正则表达式获取日期数据
high = re.findall("bWendu:'(.*?)℃',", response) # 正则表达式获取最高气温数据
low = re.findall("yWendu:'(.*?)℃',", response) # 正则表达式获取最低气温数据
tianqi = re.findall("tianqi:'(.*?)',", response) # 正则表达式获取天气状况数据
fengxiang = re.findall("fengxiang:'(.*?)',", response) # 正则表达式获取风向数据
fengli = re.findall(",fengli:'(.*?)'", response) # 正则表达式获取风力数据
aqi = re.findall("aqi:'(.*?)',", response) # 正则表达式获取空气质量指标数据
aqiInfo = re.findall("aqiInfo:'(.*?)',", response) # 正则表达式获取空气质量说明数据
aqiLevel = re.findall(",aqiLevel:'(.*?)'", response) # 正则表达式获取空气质量水平数据
简单的非贪心算法找到每个url里面我要的数据,接着我们要简单拆分一下数据得到的是整个七月的数据,我们只要最近几天的所以有了以下下操作
# 由于2011~2015没有空气质量相关的数据,故需要分开处理
if len(aqi) == 0:
aqi = None
aqiInfo = None
aqiLevel = None
df=pd.DataFrame(
{'ymd': ymd, 'high': high, 'low': low, 'tianqi': tianqi, 'fengxiang': fengxiang, 'fengli': fengli,
'aqi': aqi, 'aqiInfo': aqiInfo, 'aqiLevel': aqiLevel})
df.drop(index=[i for i in range(0,8)],inplace=True)#删除匹配到的多余数据
df.drop(index=[i for i in range(14,31)],inplace=True)
print(df)
info.append(df)
else:
df = pd.DataFrame(
{'ymd': ymd, 'high': high, 'low': low, 'tianqi': tianqi, 'fengxiang': fengxiang, 'fengli': fengli,
'aqi': aqi, 'aqiInfo': aqiInfo, 'aqiLevel': aqiLevel})
df.drop([i for i in range(0,8)],inplace=True)
try:
df.drop([i for i in range(14,31)],inplace=True)
except:
print('2021年\\n\\n')
print(df)
info.append(df)
介绍一下pd.DataFrame.drop用法
pd.DataFrame都知道吧,常用的数据框架,其他功能大家自己可以挖掘增加学习力嘛,我是经常用它画图,或者来将字典类型的数据转换成行列类型的数据,详情可以往下看
用法:DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False)
#参数说明
labels 就是要删除的行列的名字,用列表给定
axis 默认为0,指删除行,因此删除columns时要指定axis=1;
index 直接指定要删除的行
columns 直接指定要删除的列
inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe;
inplace=True,则会直接在原数据上进行删除操作,删除后无法返回。
最后就是将数据合并并保存
# 将存储的所有的天气数据进行合并,生成数据表格
weather = pd.concat(info)
# 数据导出
weather.to_csv('weather.xlsx', index=False,encoding='gbk')
得到了数据我们现在就开始解密这件事的真相吧
数据分析及可视化
用到的方法大家可以参考一下:几十个炫酷可视化数据分析网站你值得拥有
分析是对上面得到的Excel格式的数据进行的所以我们主要使用
import xlrd
我们先画一个饼图
数据简单处理
data=xlrd.open_workbook('weather.xlsx')#读取文件数据
table=data.sheet_by_name('weather')#sheet名为weather的table
tianshu=table.nrows-1#因为第一行为表头所以要减一
xiayv=0
#饼状图
for i in range(1,tianshu):
a = table.row(i)[3].value
print(a)
if a!='晴' and a!='多云' and a!='晴~多云' and a!='多云~晴':
xiayv=xiayv+1
print(tianshu)
print(xiayv)
将数据输入我上面链接平台里画出如下图就是这篇文章《几十个炫酷可视化数据分析网站你值得拥有》
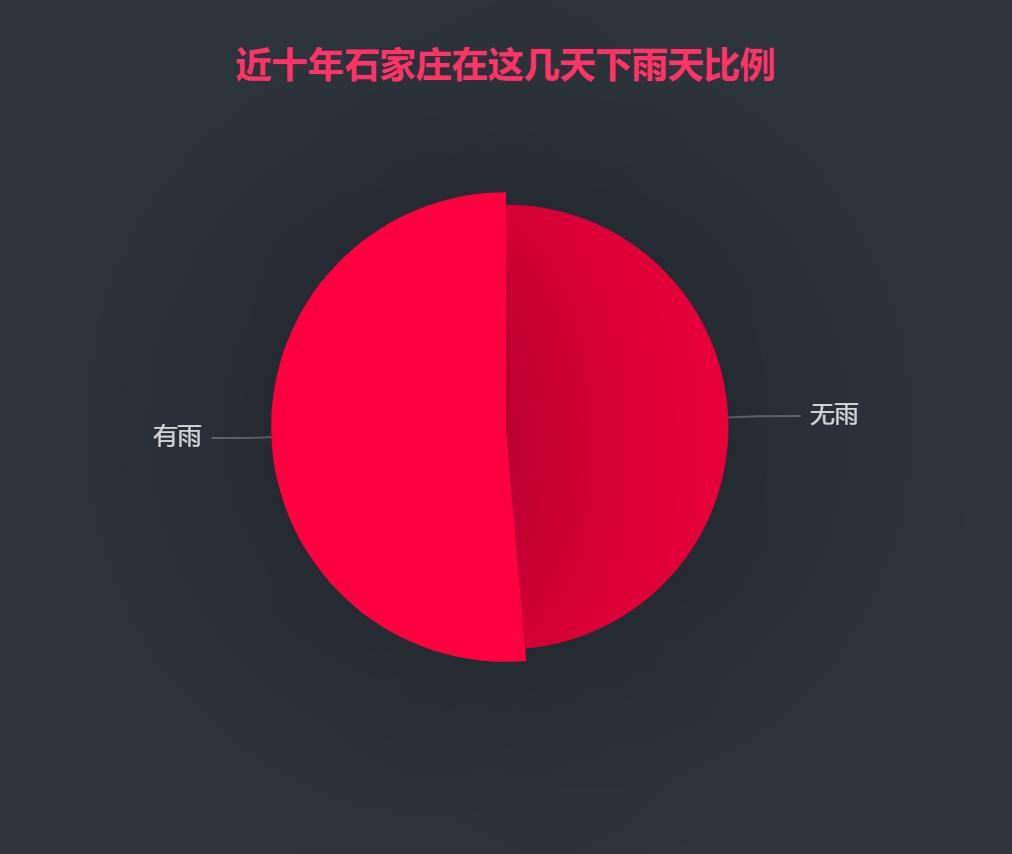
直观的看出下雨的比例挺高的,我们接着分析。
散点图
这种格式是为了符合上面平台给的数据类型
ri_wendu=[]
j=1
for i in range(1,tianshu):
if i%7==0:
j=1
ri_wendu.append([j,table.row(i)[1].value])
j=j+1
else:
ri_wendu.append([j,table.row(i)[1].value])
j=j+1
print(ri_wendu)
这张是关于温度的
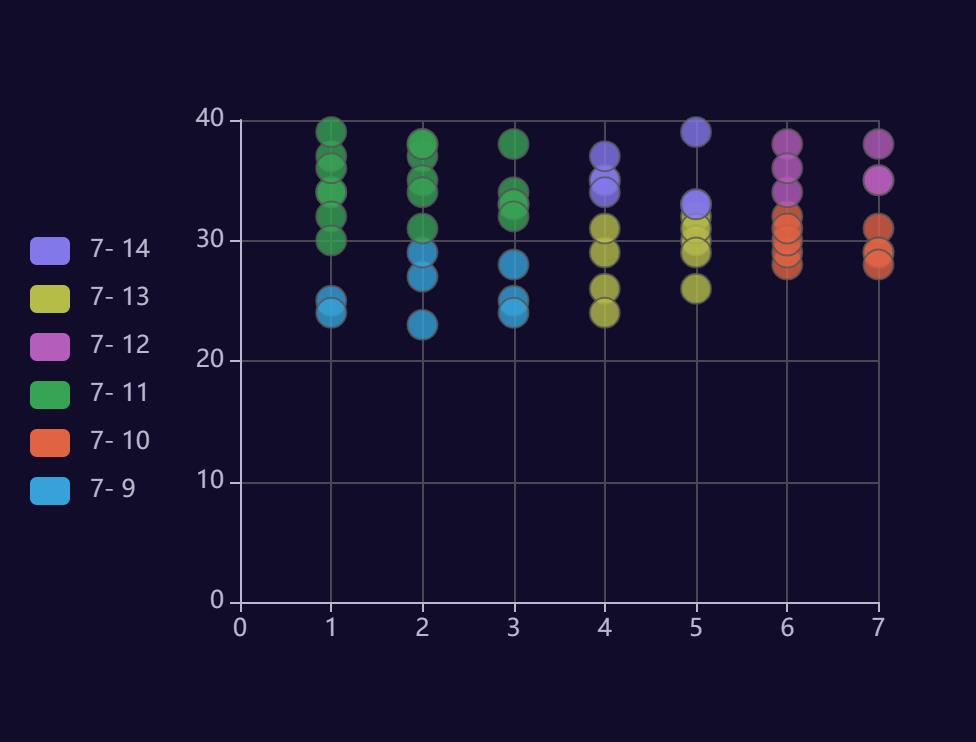
这几天的天气在夏天来说还可以接受,没什么诡异的,我们接着分析。
词云并可以设置颜色
要用到的库
from matplotlib import colors
import jieba
import xlrd
from wordcloud import WordCloud
词云这个库使用挺简单的我就不说了,就是设置颜色这块可能大家不太熟悉可以参考一下
f=open(r'tianqi.txt','r',encoding='utf-8')#将上面数据风向和风力取出来
text=f.read()
cut_text = "".join(jieba.cut(text))
color_list=['#FF0000','#9955FF','#66FFFF']#建立颜色数组
colormap=colors.ListedColormap(color_list)#调用
#color_mask = cv2.imread("11.jpg")
word_cloud=WordCloud(
font_path="msyh.ttc",
background_color='black',
mode="RGBA",
prefer_horizontal=1,
#mask=color_mask,
height=200,
width=200,
scale=1,
colormap=colormap,#设置颜色
margin=5
)
word_cloud1=word_cloud.generate(cut_text)
word_cloud1.to_file('1.png')
print("图片保存成功")

由图可以看出风还挺小的,但是雨为什么这么大呢???往下看
设置词云比色卡
FFFFFF #DDDDDD #AAAAAA #888888 #666666 #444444 #000000
#FFB7DD #FF88C2 #FF44AA #FF0088 #C10066 #A20055 #8C0044
#FFCCCC #FF8888 #FF3333 #FF0000 #CC0000 #AA0000 #880000
#FFC8B4 #FFA488 #FF7744 #FF5511 #E63F00 #C63300 #A42D00
#FFDDAA #FFBB66 #FFAA33 #FF8800 #EE7700 #CC6600 #BB5500
#FFEE99 #FFDD55 #FFCC22 #FFBB00 #DDAA00 #AA7700 #886600
#FFFFBB #FFFF77 #FFFF33 #FFFF00 #EEEE00 #BBBB00 #888800
#EEFFBB #DDFF77 #CCFF33 #BBFF00 #99DD00 #88AA00 #668800
#CCFF99 #BBFF66 #99FF33 #77FF00 #66DD00 #55AA00 #227700
#99FF99 #66FF66 #33FF33 #00FF00 #00DD00 #00AA00 #008800
#BBFFEE #77FFCC #33FFAA #00FF99 #00DD77 #00AA55 #008844
#AAFFEE #77FFEE #33FFDD #00FFCC #00DDAA #00AA88 #008866
#99FFFF #66FFFF #33FFFF #00FFFF #00DDDD #00AAAA #008888
#CCEEFF #77DDFF #33CCFF #00BBFF #009FCC #0088A8 #007799
#CCDDFF #99BBFF #5599FF #0066FF #0044BB #003C9D #003377
#CCCCFF #9999FF #5555FF #0000FF #0000CC #0000AA #000088
#CCBBFF #9F88FF #7744FF #5500FF #4400CC #2200AA #220088
#D1BBFF #B088FF #9955FF #7700FF #5500DD #4400B3 #3A0088
#E8CCFF #D28EFF #B94FFF #9900FF #7700BB #66009D #550088
#F0BBFF #E38EFF #E93EFF #CC00FF #A500CC #7A0099 #660077
#FFB3FF #FF77FF #FF3EFF #FF0 0FF #CC00CC #990099 #770077
对应颜色

结论
事情逐渐浮出水面从上面的图我们就能很直观的看出来了,近十年的这几天下雨比例还是很高的所以这可能就是巧合,内裤可能也不是室友拿的,但是

我正想关了电脑睡觉的时候一条数据让我瞬间清醒:
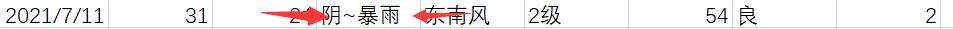
虽然下雨挺多可这次竟然是大暴雨,案件逐渐的迷离起来。

于是我赶紧给室友打电话问问他走的时候有没有收衣服。结果真被我这一套精确的计算给蒙对了,他走的时候收了衣服不知道有没有收错,都放在衣柜里了,我去找了半天发现柜子里不仅有条花裤衩还有其他不能言语的东西,哈哈哈。就赶紧通知铁柱来看看,结果还真是,接着就收到了室友安全到家的消息。我猜上天一定以为室友偷裤衩要惩罚的一下(到底是不是偷裤衩还不确定,我们就认为是拿错了吧)
好了今天的案件就调查到这里,欢迎订阅练手项目我们一起进步学知识。
最后别忘了给热情的肥学点个赞哦!!!真诚的希望室友不要看到这篇文。
以上是关于python帮室友避险——爬虫加可视化的主要内容,如果未能解决你的问题,请参考以下文章