python实战爬虫+数据可视化帮表弟选大学,直呼牛X
Posted 一条IT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python实战爬虫+数据可视化帮表弟选大学,直呼牛X相关的知识,希望对你有一定的参考价值。
哈喽,大家好,我是一条。
高考第一天已经结束,高考之后学子和家长们又会迎来第二个难题——报志愿。
中国教育在线网显示国内目前共有2857所高等院校,报一个理想的学校简直是千里挑一。正好表弟求着我让我帮他选学校,我想着十年寒窗苦读也不容易,不如就用python帮帮他。
分析一下目前国内的大学
下一期为大家分析一下高校里有哪些专业。
写在前面:需要完整代码和数据的同学,一键三连+评论:“全国高校”,私发给你全部资料。
获取url
打开中国教育在线网,按 F12,顶部选择NetWork,选择XHR
刷新页面,观察url,通过对Reponse的分析找到真正的url为:https://api.eol.cn/gkcx/api/
数据存储在Json中。
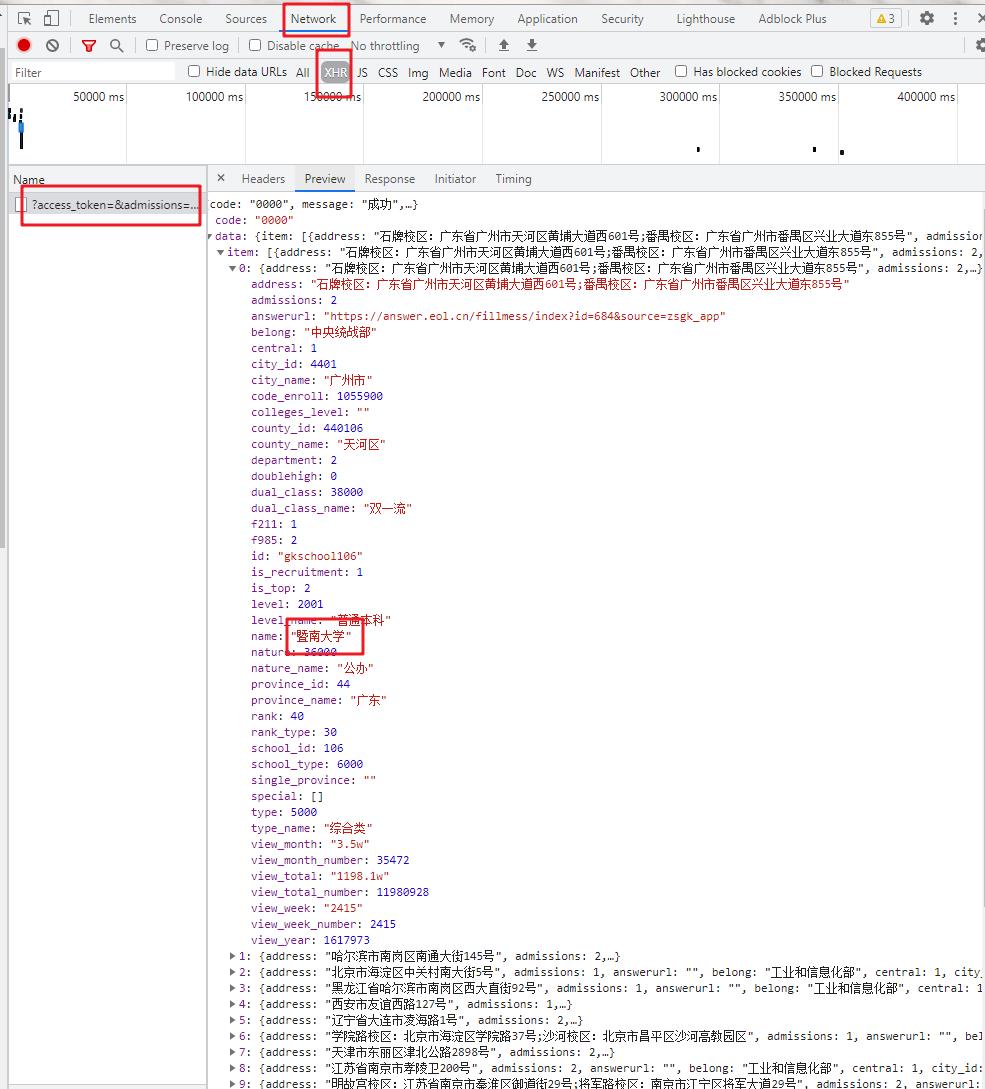
再点击Headers,查看请求参数
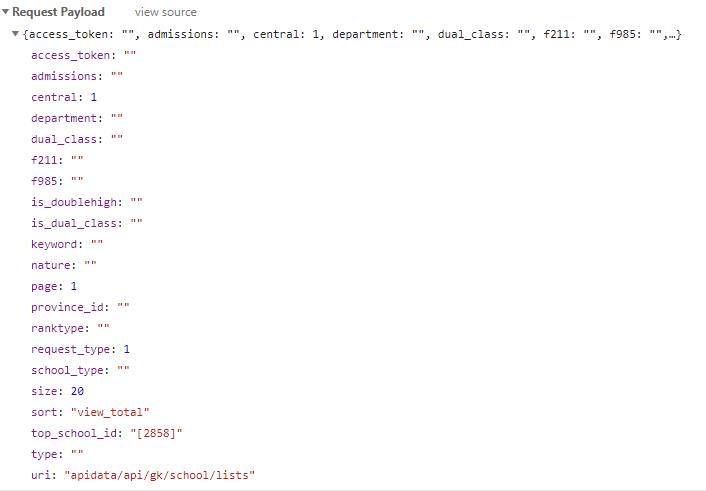
请求方式为POST
发送请求
拿到url,我们就可以利用requests模拟浏览器发送请求,拿到返回的Json数据。代码如下:
# 导入包
import numpy as np
import pandas as pd
import requests
import json
from fake_useragent import UserAgent
import time
# 获取一页
def get_one_page(page_num):
# 获取URL
url = 'https://api.eol.cn/gkcx/api/'
# 构造headers
headers = {
'User-Agent': UserAgent().random,
'Origin': 'https://gkcx.eol.cn',
'Referer': 'https://gkcx.eol.cn/school/search?province=&schoolflag=&recomschprop=',
}
# 构造data
data = {
'access_token': "",
'admissions': "",
'central': "",
'department': "",
'dual_class': "",
'f211': "",
'f985': "",
'is_dual_class': "",
'keyword': "",
'page': page_num,
'province_id': "",
'request_type': 1,
'school_type': "",
'size': 20,
'sort': "view_total",
'type': "",
'uri': "apigkcx/api/school/hotlists",
}
# 发起请求
try:
response = requests.post(url=url, data=data, headers=headers)
except Exception as e:
print(e)
time.sleep(3)
response = requests.post(url=url, data=data, headers=headers)
解析json数据
根据Response返回的Json格式,解析出我们想要的内容,代码如下:
# 解析获取数据
school_data = json.loads(response.text)['data']['item']
# 学校名
school_name = [i.get('name') for i in school_data]
# 隶属部门
belong = [i.get('belong') for i in school_data]
# 高校层次
dual_class_name = [i.get('dual_class_name') for i in school_data]
# 是否985
f985 = [i.get('f985') for i in school_data]
# 是否211
f211 = [i.get('f211') for i in school_data]
# 办学类型
level_name = [i.get('level_name') for i in school_data]
# 院校类型
type_name = [i.get('type_name') for i in school_data]
# 是否公办
nature_name = [i.get('nature_name') for i in school_data]
# 人气值
view_total = [i.get('view_total') for i in school_data]
# 省份
province_name = [i.get('province_name') for i in school_data]
# 城市
city_name = [i.get('city_name') for i in school_data]
# 区域
county_name = [i.get('county_name') for i in school_data]
# 保存数据
df_one = pd.DataFrame({
'school_name': school_name,
'belong': belong,
'dual_class_name': dual_class_name,
'f985': f985,
'f211': f211,
'level_name': level_name,
'type_name': type_name,
'nature_name': nature_name,
'view_total': view_total,
'province_name': province_name,
'city_name': city_name,
'county_name': county_name,
})
return df_one
存入Excel
先将数据存入Pandas,用于做数据分析,再写入Excel存储。
# 获取多页
def get_all_page(all_page_num):
# 存储表
df_all = pd.DataFrame()
# 循环页数
for i in range(all_page_num):
# 打印进度
print(f'正在获取第{i + 1}页的高校信息')
# 调用函数
df_one = get_one_page(page_num=i+1)
# 追加
df_all = df_all.append(df_one, ignore_index=True)
# 休眠
time.sleep(np.random.uniform(2))
return df_all
# 运行函数
df_school = get_all_page(all_page_num=143)
# 读出数据
df_school.to_excel('./data/全国高校数据.xlsx', index=False)
运行代码
数据展示
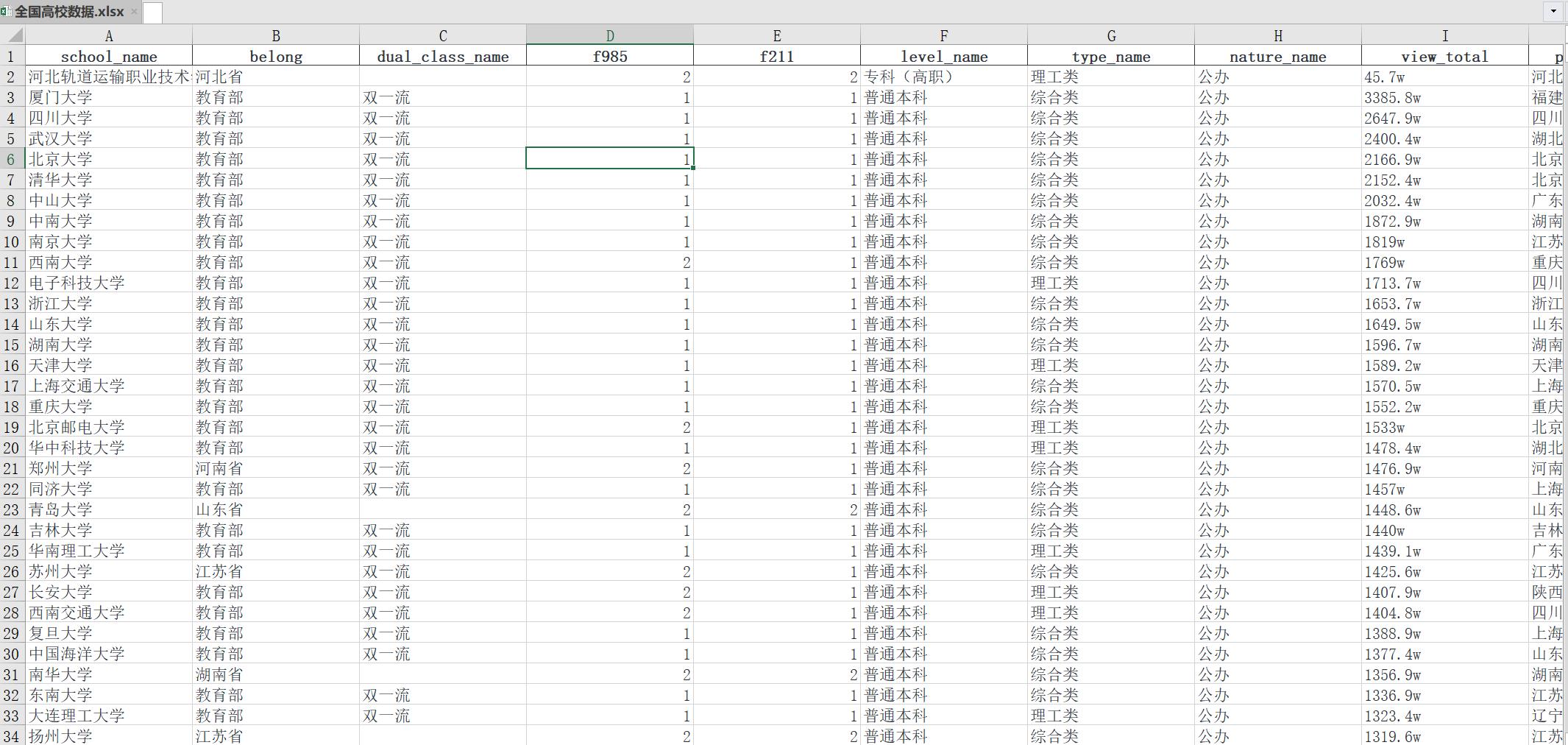
数据可视化
1.各省市地区高校数量分布
柱形图:
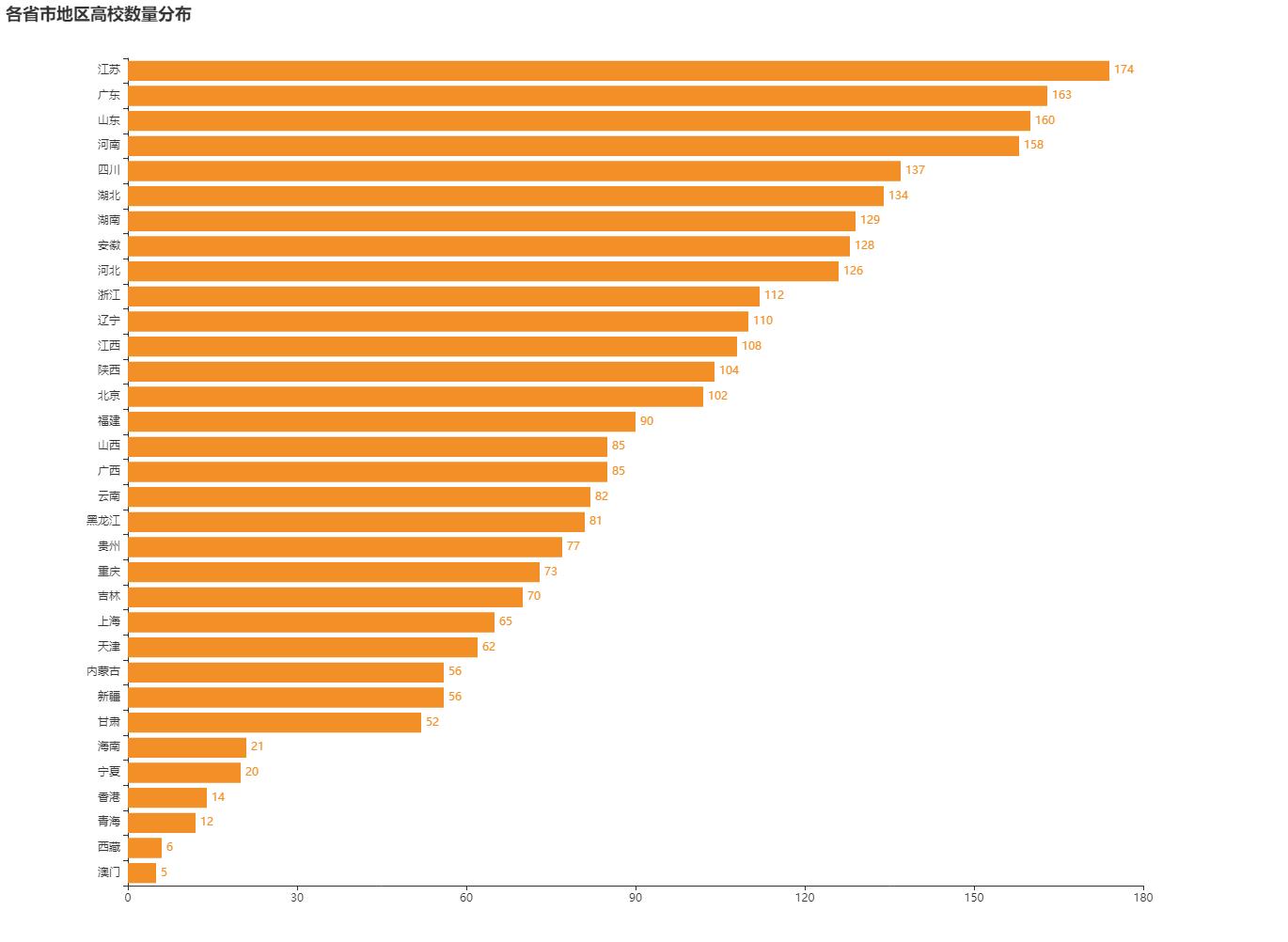
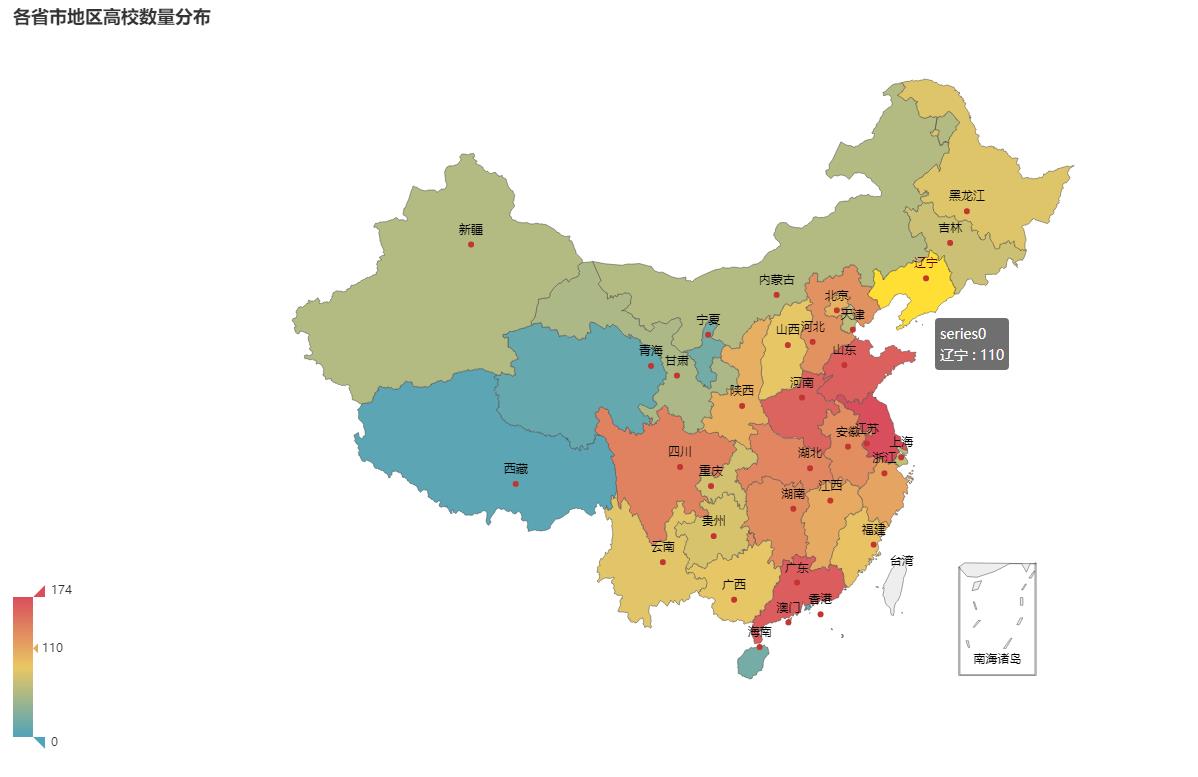
地图
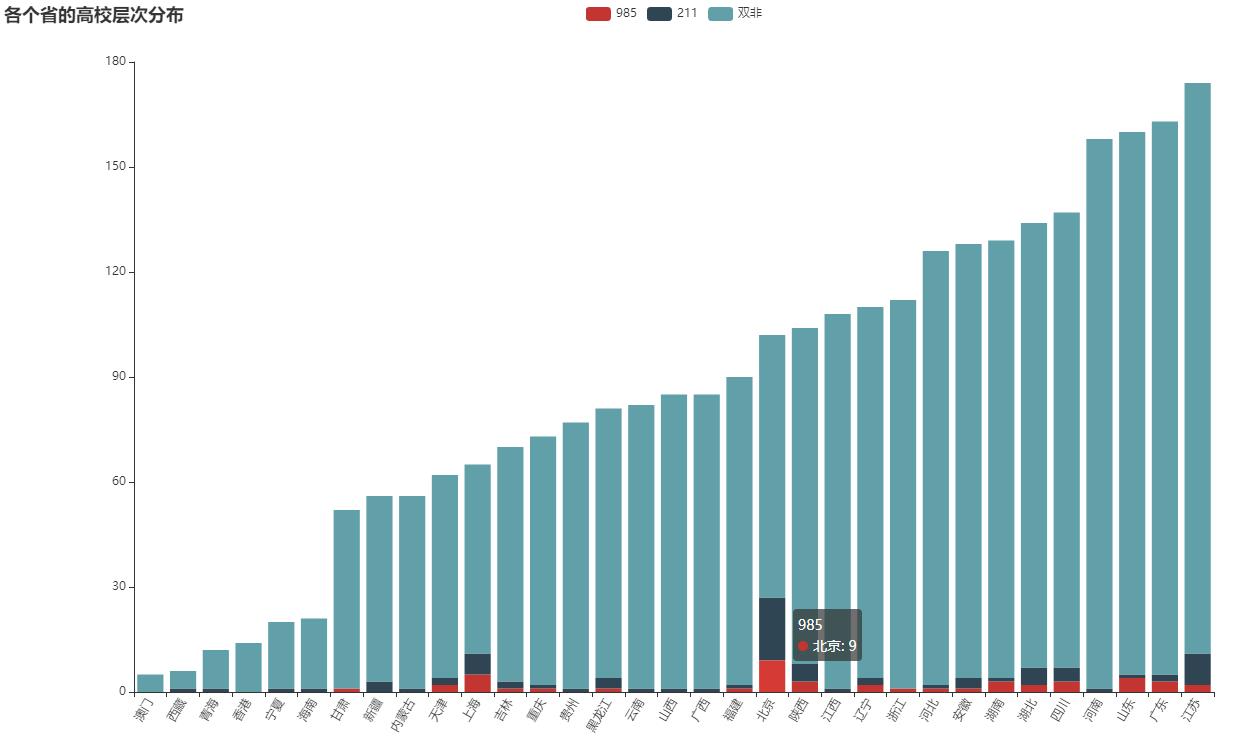
各个省的高校层次分布
全国高校类型分布
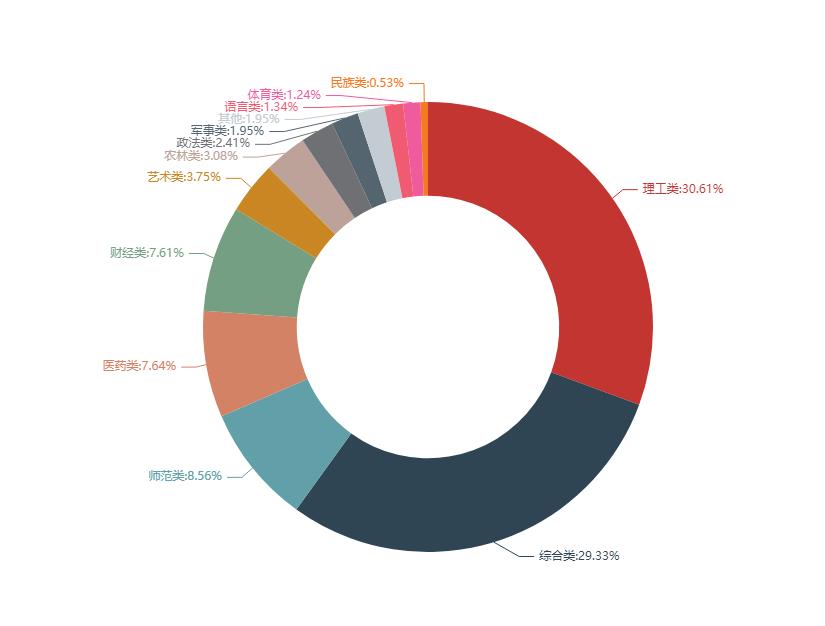
有了上面的数据,是不是对全国的高校有一定了解了
表弟看了直呼”牛X“
你觉得呢,别忘了一键三连哦!
我是一条,一个在互联网摸爬滚打的程序员。
道阻且长,行则将至。
大家的 【点赞,收藏,关注】 就是一条创作的最大动力,我们下期见!
以上是关于python实战爬虫+数据可视化帮表弟选大学,直呼牛X的主要内容,如果未能解决你的问题,请参考以下文章