Python爬虫编程思想:实战案例:抓取所有的网络资源
Posted 蒙娜丽宁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫编程思想:实战案例:抓取所有的网络资源相关的知识,希望对你有一定的参考价值。
到现在为止,我们已经对网络爬虫涉及到的基本知识有了一个初步的了解。本文会编写一个简单的爬虫应用,以便让读者对爬虫有一个基本的认识。本节要编写的爬虫属于全网爬虫类别,但我们肯定不会抓取整个互联网的资源。所以本节会使用7个html文件来模拟互联网资源,并将这7个HTML文件放在本地的nginx服务器的虚拟目录,以便抓取这7个HTML文件。
全网爬虫要至少有一个入口点(一般是门户网站的首页),然后会用爬虫抓取这个入口点指向的页面,接下来会将该页面中所有链接节点(a节点)中href属性的值提取出来。这样会得到更多的Url,然后再用同样的方式抓取这些Url指向的HTML页面,再提取出这些HTML页面中a节点的href属性的值,然后再继续,直到所有的HTML页面都被分析完为止。只要任何一个HTML页面都是通过入口点可达的,使用这种方式就可以抓取所有的HTML页面。这很明显是一个递归过程,下面就用伪代码来描述这一递归过程。
从前面的描述可知,要实现一个全网爬虫,需要下面两个核心技术。
- 下载Web资源(html、css、js、json)
- 分析Web资源
假设下载资源通过download(url)函数完成,url是要下载的资源链接。download函数返回了网络资源的文本内容。analyse(html)函数用于分析Web资源,html是download函数的返回值,也就是下载的HTML代码。analyse函数返回一个列表类型的值,该返回值包含了HTML页面中所有的URL(a节点href属性值)。如果HTML代码中没有a节点,那么analyse函数返回空列表(长度为0的列表)。下面的drawler函数就是下载和分析HTML页面文件的函数,外部程序第1次调用crawler函数时传入的URL就是入口点HTML页面的链接。
def crawler(url)
{
# 下载url指向的HTML页面
html = download(url)
# 分析HTML页面代码,并返回该代码中所有的URL
urls = analyse(html)
# 对URL列表进行迭代,对所有的URL递归调用crawler函数
for url in urls
{
crawler(url)
}
}
# 外部程序第一次调用crawler函数,http://localhost/files/index.html就是入口点的URL
crawler('http://localhost/files/index.html ')
本节的例子需要使用到nginx服务器,下面是nginx服务器的安装方法。
nginx是免费开源的,下载地址是https://nginx.org/en/download.html。如果读者使用的是Windows平台,直接下载nginx压缩包(一个zip压缩文件),直接解压即可。如果读者使用的是Mac OS X或Linux平台,需要使用下面的方式编译nginx源代码,并安装nginx。
进入nginx源代码目录,然后执行下的命令配置nginx。
./configure --prefix=/usr/local/nginx上面的配置指定了nginx的安装目录是/usr/local/nginx。
接下来执行下面的命令编译和安装nginx。
make && make install如果安装成功,会在/usr/local目录下看到nginx目录。
下面会使用递归的方式编写了一个全网爬虫,该爬虫会从本地的nginx服务器(其他Web服务器也可以)抓取所有的HTML页面,并通过正则表达式分析HTML页面,提取出a节点的href属性值,最后将获得的所有URL输出到Console。
在编写代码之前,先要准备一个Web服务器(Nginx、Apache、IIS都可以),并建立一个虚拟目录。Nginx默认的虚拟目录路径是根目录>/html。然后准备7个HTML文件,这些HTML文件的名称和关系如图1所示。
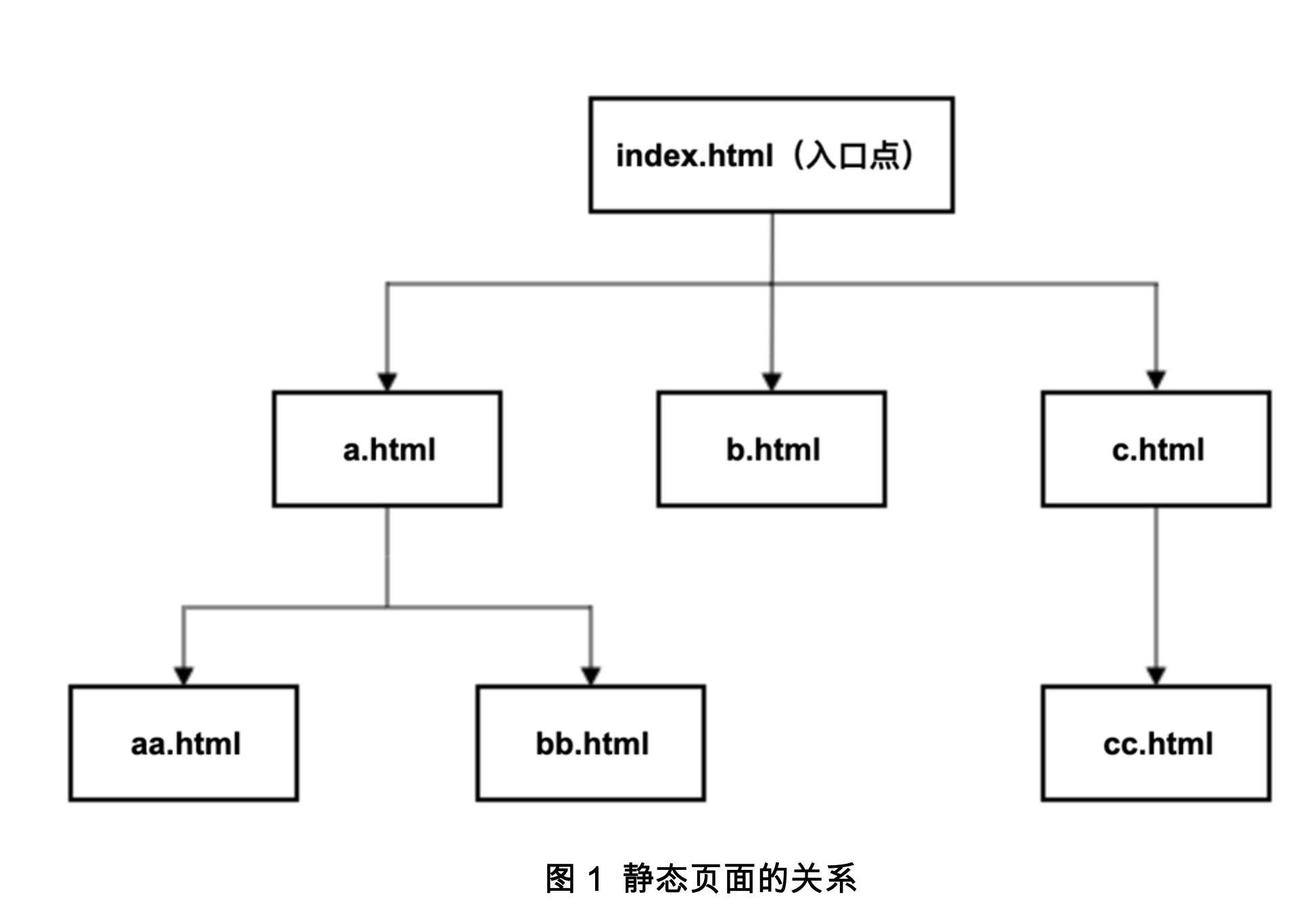
很明显,index.html文件是入口点,从index.html文件可以导向a.html、b.html和c.html。从a.html可以导向aa.html和bb.html,从c.html可以导向cc.html。也就是说,只要从index.html文件开始抓取,就可以成功抓取所有的HTML文件。
现在将这7个HTML文件都放在根目录>/html/files目录下,然后按下面的代码编写爬虫程序。
7个HTML文件所在的目录位置是src/firstspider/files
下面是本例的7个HTML文件的代码,爬虫会抓取和分析这7个HTML文件的代码。
<!-- index.html 入口点 -->
<html>
<head><title>index.html</title></head>
<body>
<a href='a.html'>first page</a>
<p>
<a href='b.html'>second page</a>
<p>
<a href='c.html'>third page</a>
<p>
</body>
</html>
<!-- a.html -->
<html>
<head><title>a.html</title></head>
<body>
<a href='aa.html'>aa page</a>
<p>
<a href='bb.html'>bb page</a>
</body>
</html>
<!-- b.html -->
<html>
<head><title>b.html</title></head>
<body>
b.html
</body>
</html>
<!-- c.html -->
<html>
<head><title>c.html</title></head>
<body>
<a href='cc.html'>cc page</a>
</body>
</html>
<!-- aa.html -->
<html>
<head><title>aa.html</title></head>
<body>
aa.html
</body>
</html>
<!-- bb.html -->
<html>
<head><title>bb.html</title></head>
<body>
bb.html
</body>
</html>
<!-- cc.html -->
<html>
<head><title>cc.html</title></head>
<body>
cc.html
</body>
</html>
从上面的代码可以看到,b.html、aa.html、bb.html和cc.html文件中并没有a节点,所以这4个HTML文件是递归的终止条件。
下面是基于递归算法的爬虫的代码。
from urllib3 import *
from re import *
http = PoolManager()
disable_warnings()
# 下载HTML文件
def download(url):
result = http.request('GET', url)
# 将下载的HTML文件代码用utf-8格式解码成字符串
htmlStr = result.data.decode('utf-8')
# 输出当前抓取的HTML代码
print(htmlStr)
return htmlStr
# 分析HTML代码
def analyse(htmlStr):
# 利用正则表达式获取所有的a节点,如<a href='a.html'>a</a>
aList = findall('<a[^>]*>',htmlStr)
result = []
# 对a节点列表进行迭代
for a in aList:
# 利用正则表达式从a节点中提取出href属性的值,如<a href='a.html'>中的a.html
g = search('href[\\s]*=[\\s]*[\\'"]([^>\\'""]*)[\\'"]',a)
if g != None:
# 获取a节点href属性的值,href属性值就是第1个分组的值
url = g.group(1)
# 将Url变成绝对链接
url = 'http://localhost/files/' + url
# 将提取出的Url追加到result列表中
result.append(url)
return result
# 用于从入口点抓取HTML文件的函数
def crawler(url):
# 输出正在抓取的Url
print(url)
# 下载HTML文件
html = download(url)
# 分析HTML代码
urls = analyse(html)
# 对每一个Url递归调用crawler函数
for url in urls:
crawler(url)
# 从入口点Url开始抓取所有的HTML文件
crawler('http://localhost/files')
在运行程序之前,要先启动nginx服务,启动方式如下:
- Windows:双击nginx.exe文件。
- macOS和Linux:在终端进入nginx根目录,执行sudo sbin/nginx命令。
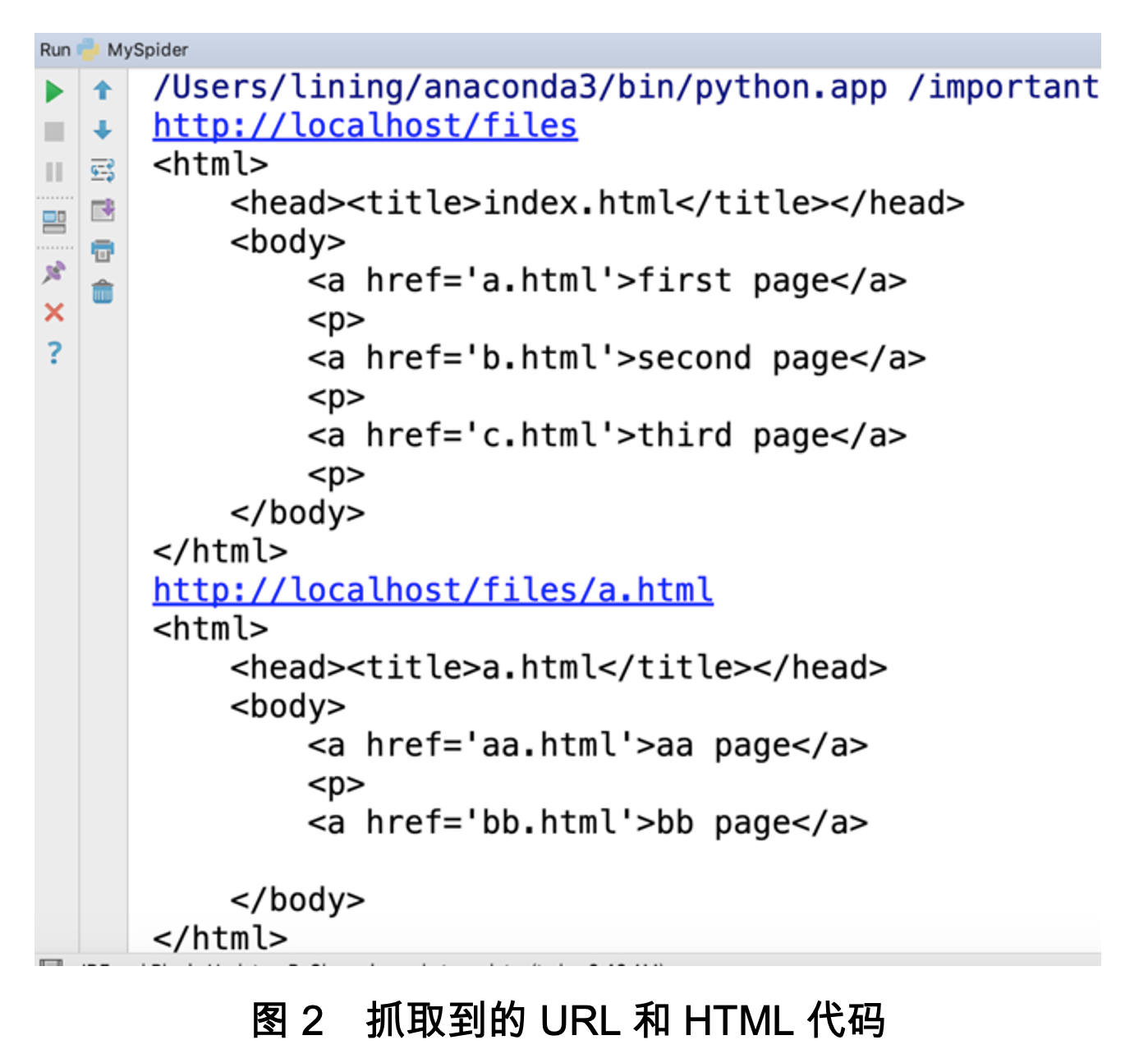
程序运行结果如图2所示。
以上是关于Python爬虫编程思想:实战案例:抓取所有的网络资源的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫编程思想(62): 项目实战:抓取酷狗网络红歌榜
Python爬虫编程思想(62): 项目实战:抓取酷狗网络红歌榜
Python爬虫编程思想(36):项目实战-抓取斗破小说网的目录和全文
Python爬虫编程思想(143):项目实战:多线程和多进程爬虫