2021年最新最全Flink系列教程__Flink综合案例
Posted 大数据Manor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年最新最全Flink系列教程__Flink综合案例相关的知识,希望对你有一定的参考价值。
day09_综合案例
今日目标
- Flink FileSink 落地写入到 HDFS
- FlinkSQL 整合 Hive数据仓库
- 订单自动好评综合案例
Flink FileSink 落地写入到 HDFS
-
常用的文件存储格式
TextFile
csv
rcFile
parquet
orc
sequenceFile
-
支持流批一体的写入到 HDFS
-
File Sink 需求
将流数据写入到 HDFS
package cn.itcast.flink.filesink; import org.apache.flink.api.common.serialization.SimpleStringEncoder; import org.apache.flink.connector.file.sink.FileSink; import org.apache.flink.core.fs.Path; import org.apache.flink.runtime.state.filesystem.FsStateBackend; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig; import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink; import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner; import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy; import java.util.concurrent.TimeUnit; /** * Author itcast * Date 2021/6/24 10:52 * Desc TODO */ public class FileSinkDemo { public static void main(String[] args) throws Exception { //1.初始化流计算运行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //2.设置Checkpoint(10s)周期性启动 和 stateBackend 存储路径 // Sink保证仅一次语义使用 checkpoint 和 二段提交 env.enableCheckpointing(10000); env.setStateBackend(new FsStateBackend("file:///d:/chk/")); //4.接入socket数据源,获取数据 DataStreamSource<String> source = env.socketTextStream("node1", 9999); //5.创建Streamingfilesink对象 OutputFileConfig config = OutputFileConfig .builder() .withPartPrefix("coo") .withPartSuffix(".txt") .build(); //5-1. 创建输出文件配置,指定输出路径 /FlinkStreamFileSink/parquet FileSink sink = FileSink .forRowFormat( new Path("hdfs://node1:8020/FileSink/parquet"), new SimpleStringEncoder<String>("UTF-8")) // sink-kafka new FlinkKafkaProducer //5-2.StreamingFileSink 行格式化 , withBucketAssigner->DateTimeBucketAssigner .withBucketAssigner(new DateTimeBucketAssigner<>("yyyy-MM-dd--HH--mm")) //withRollingPolicy -> 默认滚筒策略 .withRollingPolicy(DefaultRollingPolicy.builder() .withMaxPartSize(64 * 1024 * 1024) .withRolloverInterval(TimeUnit.SECONDS.toMillis(10)) .withInactivityInterval(TimeUnit.SECONDS.toMillis(5)) .build()) //withOutputFileConfig -> 输出文件的配置 .withOutputFileConfig(config) .build(); //6.设置输出 sink source.print(); source.sinkTo(sink).setParallelism(1); //source.addSink(sink).setParallelism(1); //7.执行任务 env.execute(); } }
FlinkSQL 整合 Hive
-
FlinkSQL 整合 Hive 数据仓库
-
Flink1.9 之后支持 Hive 数据仓库, 在Flink1.12版本支持 Hive 可以在生产级环境使用
-
Hive 使用Hive,外部调用的使用,开启两个服务
hive --service metastore
hive --service hiveserver2
-
FlinkSQL 如何整合 Hive
-
在环境变量中配置 HADOOP_CLASSPATH=
hadoop classpathvim /etc/profile
source /etc/profile
-
上传 flink 依赖的 Hive jar包上传到 Flink/lib 目录下
[root@node3 lib]# wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-2.2.0_2.11/1.12.3/flink-sql-connector-hive-2.2.0_2.11-1.12.3.jar -
配置文件
① Hive/conf/hive-site.xml - 单节点 node3
vim /export/server/hive/conf/hive-site.xml <property> <name>hive.metastore.uris</name> <value>thrift://node3:9083</value> </property>② flink/conf/flink-conf.yaml - 三台节点 scp到三台节点上
-
开启 hive 的服务
hive --service metastore
-
-
FLink shell 操作
- Flink 启动 sql-client 的基础配置
vim /export/server/flink/conf/sql-client-defaults.yaml catalogs: - name: myhive type: hive hive-conf-dir: /export/server/hive/conf default-database: default- FlinkSQL 操作 Hive
show catalogs; # myhive show catalog myhive # 列出hive中所有数据库 show databases; # 使用指定的数据库 bigdata use bigdata; # 查询当前数据库中所有的表 show tables; # 查询指定表信息 desc person; select * from person; -
Flink Java API 操作
import org.apache.flink.table.api.EnvironmentSettings; import org.apache.flink.table.api.TableEnvironment; import org.apache.flink.table.api.TableResult; import org.apache.flink.table.catalog.hive.HiveCatalog; public class HiveDemo { public static void main(String[] args){ //创建流执行环境 EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().build(); //表执行环境 TableEnvironment tableEnv = TableEnvironment.create(settings); String name = "myhive"; String defaultDatabase = "bigdata"; String hiveConfDir = "./conf"; //创建 Hive的catalog sql-client HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir); //注册catalog show catalogs 在sql-client-default.xml tableEnv.registerCatalog("myhive", hive); //使用注册的catalog use catalog myhive tableEnv.useCatalog("myhive"); //向Hive表中写入数据 String insertSQL = "insert into person values (6,'zhaoliu',30)"; //执行当前插入SQL语句 TableResult result = tableEnv.executeSql(insertSQL); //查看执行 Job 状态 System.out.println(result.getJobClient().get().getJobStatus()); } }
Flink实现订单自动好评
-
需求
如果用户买了商品,在订单完成之后,一定时间(5s)之内没有做出评价,系统自动给与五星好评,我们今天主要使用Flink的定时器来简单实现这一功能。
-
分析流程
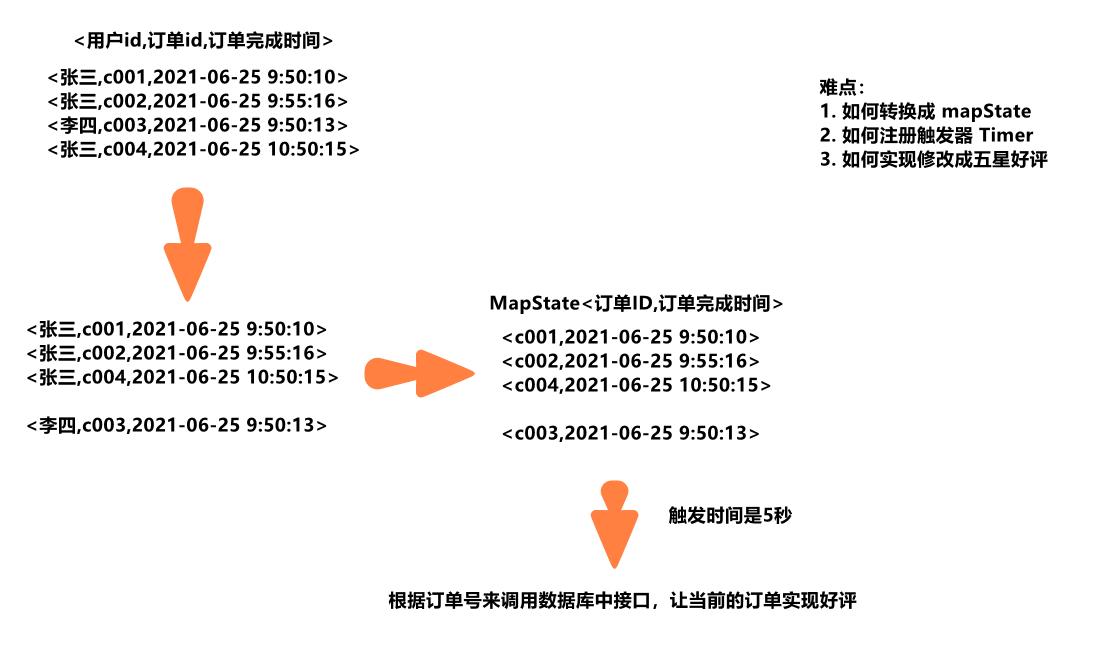
-
开发步骤
package cn.itcast.flink; import org.apache.flink.api.common.state.MapState; import org.apache.flink.api.common.state.MapStateDescriptor; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.streaming.api.functions.source.SourceFunction; import org.apache.flink.util.Collector; import java.util.Iterator; import java.util.Map; import java.util.Random; import java.util.UUID; /** * Author itcast * Date 2021/6/25 9:45 * 开发步骤: * 1. 创建流执行环境 , 设置并行度 * 2. 读取数据源, <userId,orderId,createTime> 数据源 * 3. 转换操作 将数据源.keyBy(userId).process * 获取 MapState<orderId,createTime> 中间结果状态 state * 将当前的订单的数据信息进行处理 开启一个触发器 * onTimer 执行这个触发器,mapState 移除掉 */ public class OrderAutoFarorableComment { public static void main(String[] args) throws Exception { //1.创建流执行环境,设置并行度 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //2.创建数据源 /// Tuple3<用户id,订单id,订单完成时间> DataStreamSource<Tuple3<String, String, Long>> source = env.addSource(new MySource()); //3.transformation //设置假如 interval=5秒,若用户未对订单做出评价,自动给与好评. source.keyBy(t->t.f0) //根据用户id进行分组,然后处理 TimerProcessFunction:KeyedProcessFunction .process(new TimerProcessFunction(5000L)) //4.打印结果到控制台 .print(); //5.执行当前程序 env.execute(); } /** * 自定义source实时产生订单数据Tuple3<用户id,订单id, 订单完成时间> * */ public static class MySource implements SourceFunction<Tuple3<String, String, Long>> { private boolean flag = true; Random random = new Random(); @Override public void run(SourceContext<Tuple3<String, String, Long>> ctx) throws Exception { while (flag) { String userId = random.nextInt(5) + ""; String orderId = UUID.randomUUID().toString(); long currentTimeMillis = System.currentTimeMillis(); ctx.collect(Tuple3.of(userId, orderId, currentTimeMillis)); Thread.sleep(500); } } @Override public void cancel() { flag = false; } } /** * * 自定义处理函数用来给超时订单做自动好评! * 如一个订单进来:<订单id, 2020-10-10 12:00:00> * 那么该订单应该在12:00:00 + 5s 的时候超时! * 所以我们可以在订单进来的时候设置一个定时器,在订单时间 + interval的时候触发! * KeyedProcessFunction<K, I, O> * KeyedProcessFunction<String, Tuple3<用户id, 订单id, 订单生成时间>, Object> * * @param <K> Type of the key. String * @param <I> Type of the input elements. Tuple3<用户id,订单id, 订单完成时间> * @param <O> Type of the output elements. */ private static class TimerProcessFunction extends KeyedProcessFunction<String,Tuple3<String,String,Long>,Object> { MapState<String, Long> mapState; Long interval = 0L; public TimerProcessFunction(Long _interval){ interval = _interval; } //3.2在open 方法中获取 MapState @Override public void open(Configuration parameters) throws Exception { MapStateDescriptor<String, Long> mapStateDesc = new MapStateDescriptor<>("mapState", String.class, Long.class); //从当前上下文获取到 mapstate mapState = getRuntimeContext().getMapState(mapStateDesc); } //3.3处理每个订单信息 @Override public void processElement(Tuple3<String, String, Long> value, Context ctx, Collector<Object> out) throws Exception { //将订单id和订单时间put到mapState,ctx注册处理时间Timer=创建时间+间隔时间 String orderId = value.f1; //订单完成时间 Long orderFinish = value.f2; //放到mapState mapState.put(orderId,orderFinish); //注册触发器 ctx.timerService().registerProcessingTimeTimer(interval+orderFinish); } //执行了当前的触发器 //3.4到这里处理超时的问题 @Override public void onTimer(long timestamp, OnTimerContext ctx, Collector<Object> out) throws Exception { //能够执行到这里说明订单超时了!超时了得去看看订单是否评价了,从map状态中获取已经超过间隔时间的订单信息, //我们这里没有接口调用,直接模拟查询订单,没有评价才给默认好评!并直接输出提示! 已经评价了,直接输出提示! Iterator<Map.Entry<String, Long>> iterator = mapState.iterator(); while(iterator.hasNext()){ Map.Entry<String, Long> next = iterator.next(); //读出来订单id, 如果当前的这个订单id ,将数据库中的指定的 comment 这个字段将 null -> 五星好评 String orderId = next.getKey(); //正式环境 通过一个接口,传入 订单id -> 执行结果 updateByOrderId(orderId) => // update t_order_comment set comment='5' WHERE orderId = $'orderId' boolean result = isEvaluation(orderId); if (result) {//已评价 System.out.println("订单(orderid: " + orderId + ")在" + interval + "毫秒时间内已经评价,不做处理"); } else {//未评价 System.out.println("订单(orderid: " + orderId + ")在" + interval + "毫秒时间内未评价,系统自动给了默认好评!"); //实际中还需要调用订单系统将该订单orderId设置为5星好评! } //已经被处理过的订单,要从 mapstate 中移除掉 iterator.remove(); } } //在生产环境下,可以去查询相关的订单系统. //模拟给 orderId 随机给是否已经点评,如果被2整除,已经点评过了,否则还没有点评 private boolean isEvaluation(String key) { return key.hashCode() % 2 == 0;//随机返回订单是否已评价 } } }
问题
- Streaming File sink 落地到 HDFS 上, 无法正常写入到 HDFS
- 导入依赖,确定是否有问题
- 确定 hdfs 服务启动
();
}
}
//在生产环境下,可以去查询相关的订单系统.
//模拟给 orderId 随机给是否已经点评,如果被2整除,已经点评过了,否则还没有点评
private boolean isEvaluation(String key) {
return key.hashCode() % 2 == 0;//随机返回订单是否已评价
}
}
}
## 问题
+ Streaming File sink 落地到 HDFS 上, 无法正常写入到 HDFS
1. 导入依赖,确定是否有问题
2. 确定 hdfs 服务启动
以上是关于2021年最新最全Flink系列教程__Flink综合案例的主要内容,如果未能解决你的问题,请参考以下文章
2021年最新最全Flink系列教程__Flink高级API
2021年最新最全Flink系列教程_Flink流批一体API
2021年最新最全Flink系列教程_Flink原理初探和流批一体API