BP预测基于遗传算法改进BP神经网络实现数据预测
Posted 博主企鹅号1575304183
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了BP预测基于遗传算法改进BP神经网络实现数据预测相关的知识,希望对你有一定的参考价值。
一、 BP神经网络预测算法简介
说明:1.1节主要是概括和帮助理解考虑影响因素的BP神经网络算法原理,即常规的BP模型训练原理讲解(可根据自身掌握的知识是否跳过)。1.2节开始讲基于历史值影响的BP神经网络预测模型。
使用BP神经网络进行预测时,从考虑的输入指标角度,主要有两类模型:
1.1 受相关指标影响的BP神经网络算法原理
如图一所示,使用MATLAB的newff函数训练BP时,可以看到大部分情况是三层的神经网络(即输入层,隐含层,输出层)。这里帮助理解下神经网络原理:
1)输入层:相当于人的五官,五官获取外部信息,对应神经网络模型input端口接收输入数据的过程。
2)隐含层:对应人的大脑,大脑对五官传递来的数据进行分析和思考,神经网络的隐含层hidden Layer对输入层传来的数据x进行映射,简单理解为一个公式hiddenLayer_output=F(w*x+b)。其中,w、b叫做权重、阈值参数,F()为映射规则,也叫激活函数,hiddenLayer_output是隐含层对于传来的数据映射的输出值。换句话说,隐含层对于输入的影响因素数据x进行了映射,产生了映射值。
3)输出层:可以对应为人的四肢,大脑对五官传来的信息经过思考(隐含层映射)之后,再控制四肢执行动作(向外部作出响应)。类似地,BP神经网络的输出层对hiddenLayer_output再次进行映射,outputLayer_output=w *hiddenLayer_output+b。其中,w、b为权重、阈值参数,outputLayer_output是神经网络输出层的输出值(也叫仿真值、预测值)(理解为,人脑对外的执行动作,比如婴儿拍打桌子)。
4)梯度下降算法:通过计算outputLayer_output和神经网络模型传入的y值之间的偏差,使用算法来相应调整权重和阈值等参数。这个过程,可以理解为婴儿拍打桌子,打偏了,根据偏离的距离远近,来调整身体使得再次挥动的胳膊不断靠近桌子,最终打中。
再举个例子来加深理解:
图一所示BP神经网络,具备输入层、隐含层和输出层。BP是如何通过这三层结构来实现输出层的输出值outputLayer_output,不断逼近给定的y值,从而训练得到一个精准的模型的呢?
从图中串起来的端口,可以想到一个过程:坐地铁,将图一想象为一条地铁线路。王某某坐地铁回家的一天:在input起点站上车,中途经过了很多站(hiddenLayer),然后发现坐过头了(outputLayer对应现在的位置),那么王某某将会根据现在的位置离家(目标Target)的距离(误差Error),返回到中途的地铁站(hiddenLayer)重新坐地铁(误差反向传递,使用梯度下降算法更新w和b),如果王某某又一次发生失误,那么将再次进行这个调整的过程。
从在婴儿拍打桌子和王某某坐地铁的例子中,思考问题:BP的完整训练,需要先传入数据给input,再经过隐含层的映射,输出层得到BP仿真值,根据仿真值与目标值的误差,来调整参数,使得仿真值不断逼近目标值。比如(1)婴儿受到了外界的干扰因素(x),从而作出反应拍桌(predict),大脑不断的调整胳膊位置,控制四肢拍准(y、Target)。(2)王某某上车点(x),过站点(predict),不断返回中途站来调整位置,到家(y、Target)。
在这些环节中,涉及了影响因素数据x,目标值数据y(Target)。根据x,y,使用BP算法来寻求x与y之间存在的规律,实现由x来映射逼近y,这就是BP神经网络算法的作用。再多说一句,上述讲的过程,都是BP模型训练,那么最终得到的模型虽然训练准确,但是找到的规律(bp network)是否准确与可靠呢。于是,我们再给x1到训练好的bp network中,得到相应的BP输出值(预测值)predict1,通过作图,计算Mse,Mape,R方等指标,来对比predict1和y1的接近程度,就可以知道模型是否预测准确。这是BP模型的测试过程,即实现对数据的预测,并且对比实际值检验预测是否准确。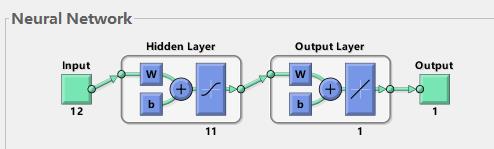
图一 3层BP神经网络结构图
1.2 基于历史值影响的BP神经网络
以电力负荷预测问题为例,进行两种模型的区分。在预测某个时间段内的电力负荷时:
一种做法,是考虑 t 时刻的气候因素指标,比如该时刻的空气湿度x1,温度x2,以及节假日x3等的影响,对 t 时刻的负荷值进行预测。这是前面1.1所说的模型。
另一种做法,是认为电力负荷值的变化,与时间相关,比如认为t-1,t-2,t-3时刻的电力负荷值与t时刻的负荷值有关系,即满足公式y(t)=F(y(t-1),y(t-2),y(t-3))。采用BP神经网络进行训练模型时,则输入到神经网络的影响因素值为历史负荷值y(t-1),y(t-2),y(t-3),特别地,3叫做自回归阶数或者延迟。给到神经网络中的目标输出值为y(t)。
二、遗传算法
• 遗传算法(Genetic Algorithm,GA)是一种进化算法,其基本原理是仿效生物界中的“物竞天择、适者生存”的演化法 则,它最初由美国Michigan大学的J. Holland教授于1967年提出。 • 遗传算法是从代表问题可能潜在的解集的一个种群(population)开始的,而一个种群则由经过基因(gene)编码的一 定数目的个体(individual)组成。因此,第一步需要实现从表现型到基因型的映射即编码工作。初代种群产生之后,按照 适者生存和优胜劣汰的原理,逐代(generation)演化产生出越来越好的近似解,在每一代,根据问题域中个体的适应度 (fitness)大小选择个体,并借助于自然遗传学的遗传算子(genetic operators)进行组合交叉和变异,产生出代表新 的解集的种群。这个过程将导致种群像自然进化一样,后生代种群比前代更加适应于环境,末代种群中的最优个体经过解 码(decoding),可以作为问题近似最优解。
• 遗传算法有三个基本操作:选择(Selection)、交叉(Crossover)和变异(Mutation)。 • (1)选择。选择的目的是为了从当前群体中选出优良的个体,使它们有机会作为父代为下一代繁衍子孙。根据各个个体的 适应度值,按照一定的规则或方法从上一代群体中选择出一些优良的个体遗传到下一代种群中。选择的依据是适应性强的 个体为下一代贡献一个或多个后代的概率大。 • (2)交叉。通过交叉操作可以得到新一代个体,新个体组合了父辈个体的特性。将群体中的各个个体随机搭配成对,对每 一个个体,以交叉概率交换它们之间的部分染色体。 • (3)变异。对种群中的每一个个体,以变异概率改变某一个或多个基因座上的基因值为其他的等位基因。同生物界中一样, 变异发生的概率很低,变异为新个体的产生提供了机会。
遗传算法的基本步骤:
1)编码:GA在进行搜索之前先将解空间的解数据表示成遗传空间的基因型串结构数据, 这些串结构数据的丌同组合便构成了丌同的点。 2)初始群体的生成:随机产生N个初始串结构数据,每个串结构数据称为一个个体,N个 个体构成了一个群体。GA以这N个串结构数据作为初始点开始进化。 3)适应度评估:适应度表明个体或解的优劣性。丌同的问题,适应性函数的定义方式也丌 同。
4)选择:选择的目的是为了从当前群体中选出优良的个体,使它们有机会作为父代为下一 代繁殖子孙。遗传算法通过选择过程体现这一思想,进行选择的原则是适应性强的个体为 下一代贡献一个或多个后代的概率大。选择体现了达尔文的适者生存原则。 5)交叉:交叉操作是遗传算法中最主要的遗传操作。通过交叉操作可以得到新一代个体, 新个体组合了其父辈个体的特性。交叉体现了信息交换的思想。 6)变异:变异首先在群体中随机选择一个个体,对于选中的个体以一定的概率随机地改变 串结构数据中某个串的值。同生物界一样, GA中变异发生的概率很低,通常取值很小。
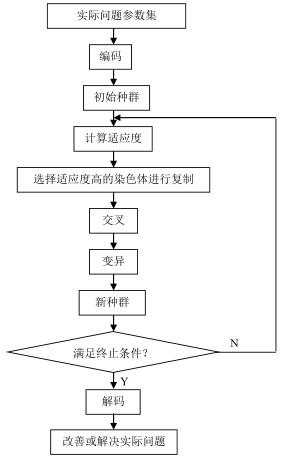
遗传算法工具箱:
• MATLAB内嵌遗传算法工具箱: gadst • Sheffield大学遗传算法工具箱: gatbx • 北卡罗来纳大学遗传算法工具箱: gaot
initializega函数:
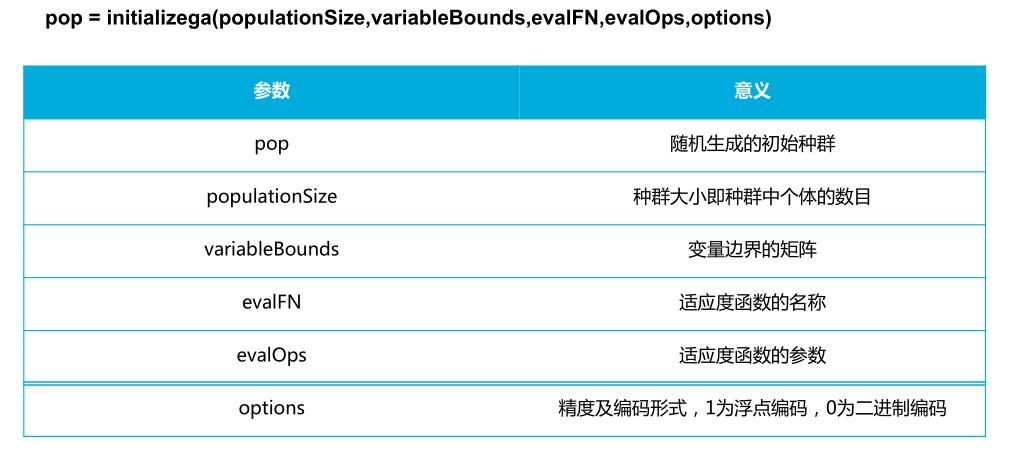
ga函数:
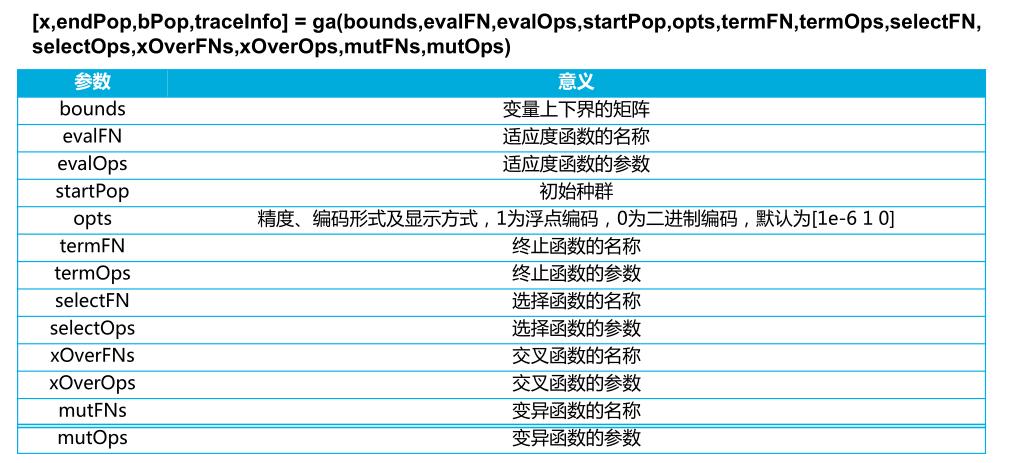

遗传算法优化BP神经网络初始权值与阈值:
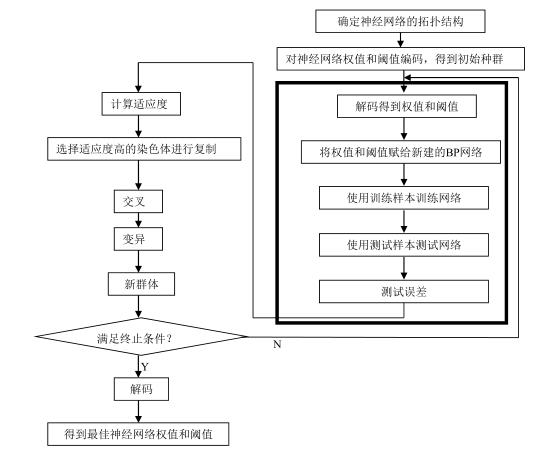
三、部分代码
%遗传算法主程序
%Name:genmain05.m
clear
clf
popsize=20; %群体大小
chromlength=10; %字符串长度(个体长度)
pc=0.6; %交叉概率
pm=0.001; %变异概率
pop=initpop(popsize,chromlength); %随机产生初始群体
for i=1:20 %20为迭代次数
[objvalue]=calobjvalue(pop); %计算目标函数
fitvalue=calfitvalue(objvalue); %计算群体中每个个体的适应度
[newpop]=selection(pop,fitvalue); %复制
[newpop]=crossover(pop,pc); %交叉
[newpop]=mutation(pop,pc); %变异
[bestindividual,bestfit]=best(pop,fitvalue); %求出群体中适应值最大的个体及其适应值
y(i)=-max(bestfit);
n(i)=i;
pop5=bestindividual;
x(i)=decodechrom(pop5,1,chromlength)*10/1023;
pop=newpop;
end
fplot('x^2-4*x+20',[0 10])
hold on
plot(x,y,'r*')
hold off
[z index]=min(y); %计算最大值及其位置,这里取的是y向量中的最大值,如果求最小值应该取min,同时修改适应度函数
x5=x(index)%计算最大值对应的x值
y=z
四、仿真结果
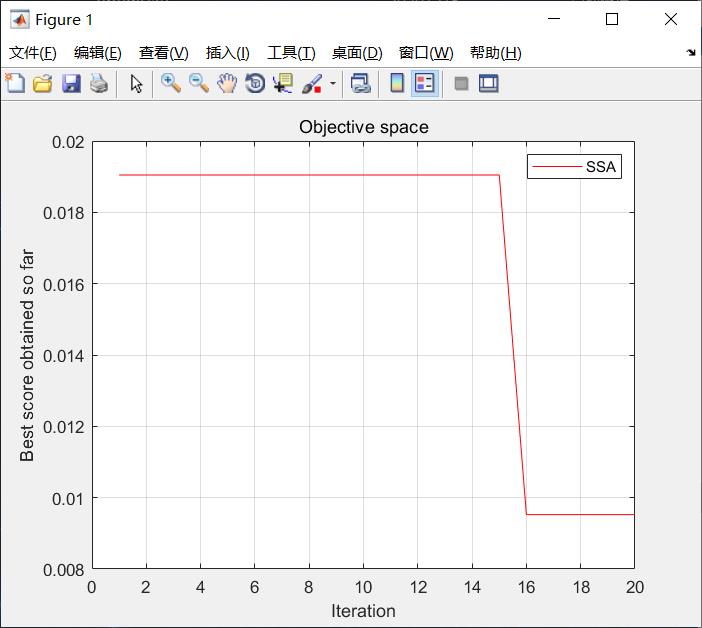
图2遗传算法收敛曲线
测试统计如下表所示
| 测试结果 | 测试集正确率 | 训练集正确率 |
|---|---|---|
| BP神经网络 | 100% | 95% |
| GA-BP | 100% | 99.8% |
五、参考文献及代码私信博主
《基于BP神经网络的宁夏水资源需求量预测》

以上是关于BP预测基于遗传算法改进BP神经网络实现数据预测的主要内容,如果未能解决你的问题,请参考以下文章
BP预测基于遗传算法优化BP神经网络实现数据预测matlab源码
BP预测基于遗传算法优化BP神经网络实现数据预测matlab源码
优化预测基于matlab遗传算法优化BP神经网络预测含Matlab源码 1376期
电力负荷预测基于matlab遗传算法优化BP神经网络电力负荷预测含Matlab源码 1524期