红外与可见光图像融合论文阅读
Posted SSyangguang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了红外与可见光图像融合论文阅读相关的知识,希望对你有一定的参考价值。
这两天新看了一篇使用深度学习方法融合红外和可见光图像的模型Infrared and Visible Image Fusion using a Deep Learning Framework,和上次博文是同组,这里分享一下。
本文提出一种深度学习方法融合可见光和红外图像的模型,首先将源图像分解为基部和细节部,然后基部用加权平均方法融合,细节部使用深度学习框架提取多层特征,再使用l1-norm和加权平均来产生候选融合细节部,用最大选择策略生成最终的融合细节部,结合该融合细节部和先前的融合基部进行重构即可获得最终的融合图像。方法代码见:https://github.com/hli1221/imagefusion deeplearning.
作者认为目前存在的很多深度学习方法只利用了网络的最后一层作为特征,这样中间层的信息就丢失了,网络越深丢失的信息越多。本文提出的模型主要有两部分:基部和细节部,它们都是从原始图像中分解得到的,基部使用加权平均获得融合基部,细节部通过深度神经网络提取多层特征,再用soft-max算子获得每层特征对应的权重图和候选细节部,再用最大选择策略从这几个候选细节部中得到最终的融合细节部,与融合基部组合后重构得到融合图像。
模型结构
模型总体结构如下图。

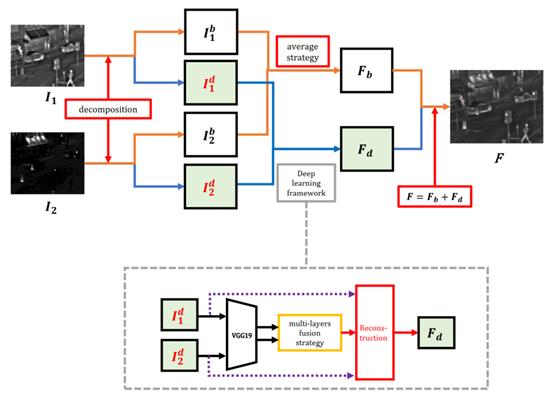
已获取K对源图像,本模型采用Image fusion with guided filtering这篇文章给出的方法进行分解,将源图像![]()
 分解为基部
分解为基部![]()
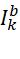 和细节部
和细节部![]()
 ,其中基部通过下面方法来优化。
,其中基部通过下面方法来优化。
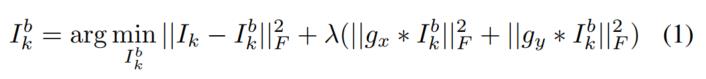

其中,![]() 和
和![]()
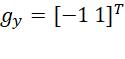 分别表示水平和竖直梯度算子,λ设置为5。得到基部后,使用下式计算细节部。
分别表示水平和竖直梯度算子,λ设置为5。得到基部后,使用下式计算细节部。
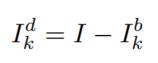
![]()
回到上面的总体结构图,红外和可见光图像分别被分解为基部和细节部,然后两个图像的基部直接使用平均加权算子来融合,至此都还没有使用深度学习方法。两个模态图像的细节部融合才使用了深度学习框架。最后的Fb和Fd融合后重建得到融合图像。
基部融合:使用下式加权平均的方法。

![]()
本文的两个系数α都设置为0.5,相当于直接平均。
细节部融合:细节部的融合采用VGG网络提取深度特征,具体结构如下图。
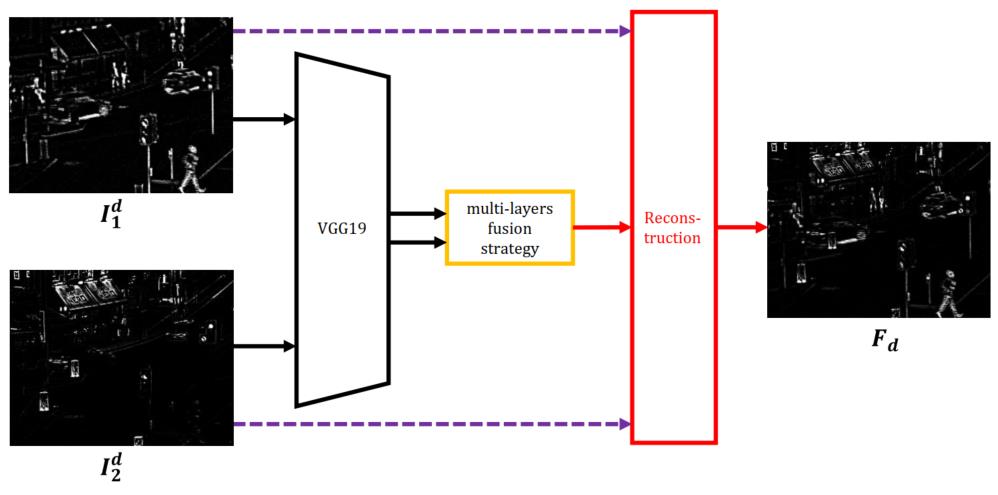
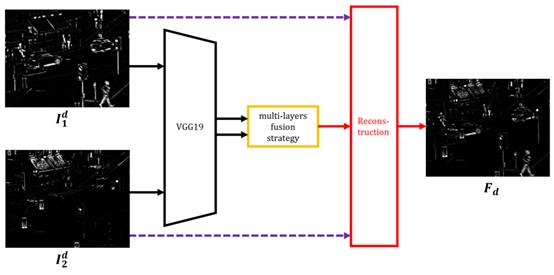
上图中左边第一个阶段就是VGG19网络进行特征提取获得多层特征图,然后使用multi-layers fusion strategy这个层进行融合得到权重图,再对权重图和细节部组合进行重建得到融合细节部。下面详细讲讲这个multi-layers fusion strategy,对于第细节部首先用VGG19网络提取特征,从多个层提取输出作为multi-layers的feature map,也就是中间要进行融合的多层特征,用下式表示。
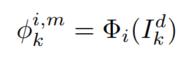
![]()
![]()
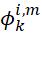 就表示VGG中第i层提取的特征,k和输出表示的意思一样,即模态,m是通道数量。本文从VGG中选择4个层输出feature map。有了上述feature map就可以用multi-layers fusion strategy融合特征了,结构如下图。
就表示VGG中第i层提取的特征,k和输出表示的意思一样,即模态,m是通道数量。本文从VGG中选择4个层输出feature map。有了上述feature map就可以用multi-layers fusion strategy融合特征了,结构如下图。
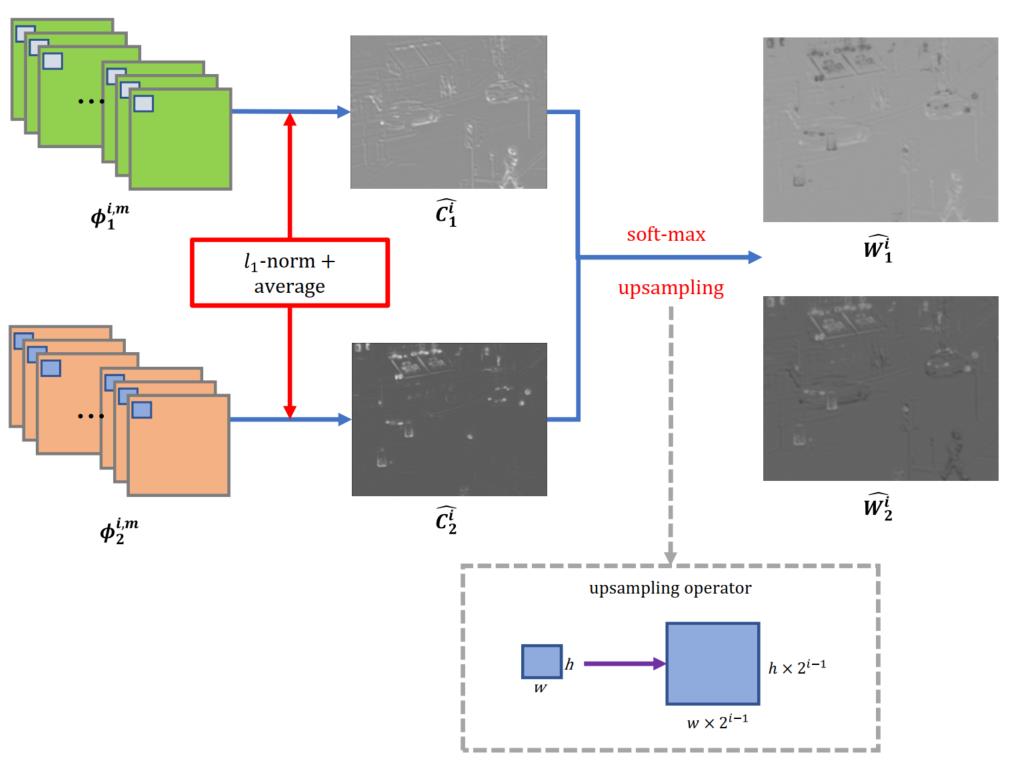

上图中首先要用l1-norm和平均来获得activity level map,也就是![]()
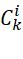 ,具体计算方法是首先用l1-norm计算每个层feature map的activity level map,使用下式得到。
,具体计算方法是首先用l1-norm计算每个层feature map的activity level map,使用下式得到。

![]()
这里的![]()
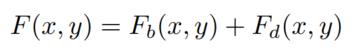 就是上面所说的VGG中第i层提取的特征的每个像素点代表的向量,因为有M个通道,所以每个像素点就是M维向量,使用l1-norm计算得到每个像素点的
就是上面所说的VGG中第i层提取的特征的每个像素点代表的向量,因为有M个通道,所以每个像素点就是M维向量,使用l1-norm计算得到每个像素点的![]()
 。有了每个像素点的activity level map后就用基于block的平均算子得到final activity level map,这样的方法对配准不良的图像对比较鲁棒。使用下式计算。
。有了每个像素点的activity level map后就用基于block的平均算子得到final activity level map,这样的方法对配准不良的图像对比较鲁棒。使用下式计算。

其中r代表block的尺寸,本文设置为1。如果该值设置的较大可以对配准不良的图像对更鲁棒,但是信息会丢失的更多。有了final activity level map再用softmax算子计算,表示initial weight map value ,值的范围是0到1,如下式。
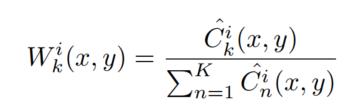

下一步是使用上采样算子得到和输出尺寸相同的final weight map,如下式。
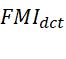

这样就获得4层feature map处理后的4对weight maps ,每对有2个模态的weight maps ,所以共8张weight maps。每对通过下式进行融合。
![]()
这样8张weight maps进一步融合为四张,最后使用最大选择策略融合4层weight maps,通过下式。

![]()
这样,终于得到了融合基部和融合细节部,我们通过直接相加的方式获得最终融合图像,如下式。
![]()
实验部分
实验中VGG采用了VGG19的预训练模型。为了对比选择了其他模型进行融合:cross bilateral filter fusion method(CBF), the joint-sparse representation model(JSR), the JSR model with saliency detection fusion method(JSRSD), weighted least square optimization-based method(WLS) and the convolutional sparse representation model(ConvSR)。
融合结果对比如下图。



结果来看,CBF得到的结果噪声较多,且红外特征不显著。JSR, JSRSD, WLS得到的结果不够自然,也存在细节被模糊的问题。ConvSR和本文提出的模型对细节保护的较好。总的来说我们提出的方法融合结果比较自然。作者也计算了评价指标,即![]()
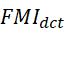 和
和![]() (分别计算离散余弦和小波特征的互信息(FMI))、
(分别计算离散余弦和小波特征的互信息(FMI))、![]() (表示通过融合过程添加到融合图像的噪声或伪影的比率)、modified structural similarity(
(表示通过融合过程添加到融合图像的噪声或伪影的比率)、modified structural similarity(![]()
 )。本文的
)。本文的![]()
 通过下式计算。
通过下式计算。

![]()
SSIM是结构相似性算子,F是融合图像,I1和I2分别是红外和可见光图像。
指标计算的结果见下表。结果显示本文模型对![]() 、
、![]()
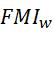 、
、![]()
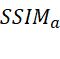 均有提升,相反
均有提升,相反![]() 较小时融合结果的噪声和不自然的信息较少。结果也说明了本模型保留更多自然细节的同时噪声也小,融合结果喜人。
较小时融合结果的噪声和不自然的信息较少。结果也说明了本模型保留更多自然细节的同时噪声也小,融合结果喜人。


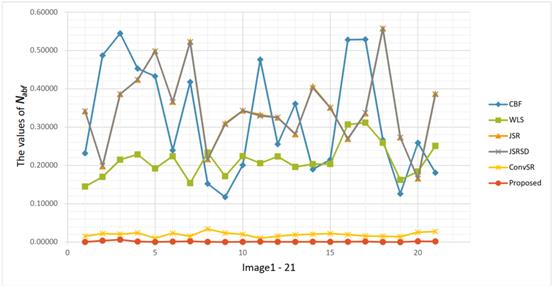
作者还对测试集中21个图像对的融合结果都计算了![]() ,本模型的
,本模型的![]()
 基本都很小,说明融合结果噪声和不自然的信息较少。测试结果表格和曲线图下图。
基本都很小,说明融合结果噪声和不自然的信息较少。测试结果表格和曲线图下图。



以上是关于红外与可见光图像融合论文阅读的主要内容,如果未能解决你的问题,请参考以下文章