强化学习技巧四:模型训练速度过慢GPU利用率较低,CPU利用率很低问题总结与分析。
Posted 汀、
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习技巧四:模型训练速度过慢GPU利用率较低,CPU利用率很低问题总结与分析。相关的知识,希望对你有一定的参考价值。
1.PyTorchGPU利用率较低问题原因:
在服务器端或者本地pc端,
输入nvidia-smi
来观察显卡的GPU内存占用率(Memory-Usage),显卡的GPU利用率(GPU-util),然后采用top来查看CPU的线程数(PID数)和利用率(%CPU)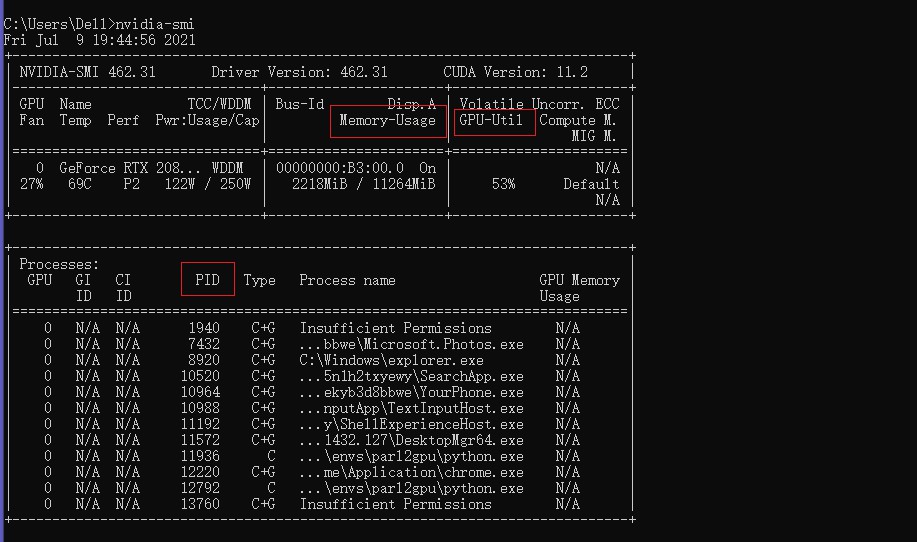
1.1 GPU内存占用率问题
这是由于模型的大小以及batch size的大小,来影响这个指标。
- GPU的内存占用率主要是模型的大小,包括网络的宽度,深度,参数量,中间每一层的缓存,都会在内存中开辟空间来进行保存,所以模型本身会占用很大一部分内存。
- 其次是batch size的大小,也会占用影响内存占用率。batch size设置为128,与设置为256相比,内存占用率是接近于2倍关系。当你batch size设置为128,占用率为40%的话,设置为256时,此时模型的占用率约等于80%所以在模型结构固定的情况下,尽量将batch size设置大,充分利用GPU的内存。
1.2 GPU利用率问题
这个是Volatile GPU-Util表示,当没有设置好CPU的线程数时,这个参数是在反复的跳动的,这样停息1-2 秒然后又重复起来。其实是GPU在等待数据从CPU传输过来,当从总线传输到GPU之后,GPU逐渐起计算来,利用率会突然升高,但是GPU的算力很强大,0.5秒就基本能处理完数据,所以利用率接下来又会降下去,等待下一个batch的传入。因此,这个GPU利用率瓶颈在内存带宽和内存介质上以及CPU的性能上面。
另外的一个方法是,在PyTorch这个框架里面,数据加载Dataloader上做更改和优化,包括num_workers(线程数),pin_memory,会提升速度。解决好数据传输的带宽瓶颈和GPU的运算效率低的问题。在TensorFlow下面,也有这个加载数据的设置。
torch.utils.data.DataLoader(image_datasets[x],
batch_size=batch_size,
shuffle=True,
num_workers=8,
pin_memory=True)为了提高利用率,首先要将num_workers(线程数)设置得体,4,8,16是几个常选的几个参数,建议打开pin_memory打开,就省掉了将数据从CPU传入到缓存RAM里面,再给传输到GPU上;为True时是直接映射到GPU的相关内存块上,省掉了一点数据传输时间。
2. 本人遇到问题原因分析:
因为训练的主要时间都花在了写日志上,文件IO耗时特别多,尤其是我设置的写入间隔还很小,所以GPU计算一瞬间,然后写很久的记录,计算一瞬间,再写很久的记录,最终导致速度特别慢。
在调试过程,
命令:top 实时查看你的CPU的进程利用率,这个参数对应你的num_workers的设置;
命令: watch -n 0.5 nvidia-smi 每0.5秒刷新并显示显卡设置。
实时查看你的GPU的使用情况,这是GPU的设置相关。这两个配合好。包括batch_size的设置。
3. 总结记录
最后总结一下,有的时候模型训练慢并不是因为显卡不行或者模型太大,而是在跑模型过程中有一些其他的操作导致速度很慢,尤其是文件的IO操作,这会导致GPU得不到连续性使用,整体速度特别慢。
第一:是增加batch size,增加GPU的内存占用率,尽量用完内存,而不要剩一半,空的内存给另外的程序用,两个任务的效率都会非常低。
第二:在数据加载时候,将num_workers线程数设置稍微大一点,推荐是8,16等,且开启pin_memory=True。不要将整个任务放在主进程里面做,这样消耗CPU,且速度和性能极为低下。
3.1 模型提速技巧
- 减少日志IO操作频率
- 使用pin_memory和num_workers
- 使用半精度训练
- 更好的显卡,更轻的模型
另外也可以通过增大batch size提高epoch速度,但是收敛速度也会变慢,需要再适当升高学习率
以上是关于强化学习技巧四:模型训练速度过慢GPU利用率较低,CPU利用率很低问题总结与分析。的主要内容,如果未能解决你的问题,请参考以下文章