Ambari架构设计文档 -- (官方翻译版)
Posted 辰辰宇宇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Ambari架构设计文档 -- (官方翻译版)相关的知识,希望对你有一定的参考价值。
写作背景
首先如题目所示,这是一篇翻译自Ambari官方设计文档的文章,那么Ambari是什么就不多说了,翻译这篇文章的目的是,作者所在的项目组的大数据管理框架目前刚好决定要用Ambari代替了CDH,在Ambari基础上进行二次开发来满足我们的项目需求,作为QA同学要测好这个项目那么就需要对Ambari有一个基本的了解,所以有了翻译这篇技术文档的想法,一是满足自己学习的目的了二是想着也可以给类似和我一样需要的同学一个学习资料吧。由于作者水平有限,全文也是借助翻译软件一点点抠的,有不准确的地方欢迎指正。
设计目标
跨平台(Platform Independence )
系统架构必须支持在任何硬件和操作系统上运行,如:红帽,ubuntu,微软操作系统,平台的组成部分应该由定义好的插件方式存在(例如 组件安装依赖yum.rpm 包等)。
可插拔的组件 (Pluggable Components)
体系架构不能采用特定的工具和技术,任何特定的工具或技术都必须封装在插件中,整个体系架构应该更关心插件的可插拔性和其插件的工具配置的选择和数据库的存储状态,这个目标可能不会立即实现,但是但是在未来一定是可容易扩展的,可插拔性这个目标不应该包含组件协议或者第三方组件接口的标准。
版本管理和升级(Version Management & Upgrade )
运行在各个节点Ambari组件必须支持多种协议版本为了支持依赖组件的独立升级,升级任何组件都不能影响Ambari的集群状态。
可扩展性(Extensibility )
设计应该很简单就可以支持增加新的服务,组件和APIs的可扩展性也意味着很容易修改Hadoop堆栈的任意配置和配置步骤,此外,还要考虑指支持HDP以外的Hadoop堆栈的可能性
故障恢复(Failure Recovery )
系统必须可以从任意组件故障都能恢复到一致性状态,系统应该恢复后尝试完成挂起的操作。如果某些错误是不可恢复的,那么系统应该仍然可以一直保持状态一致性。
安全(Security)
安全意味着用户身份验证和Ambari基于角色的授权(包括API 和 WEBUI)的安装,管理,以及通过Kerberos安装保护的监控,对Ambari与组件之间的在线通信进行验证和加密
错误追踪(Error Trace )
该设计力求简化跟踪失败的过程,应该把故障传播给用户,并提供足够详细的信息进行分析。
接近实时的反馈和操作(Near Real-Time and Intermediate Feedback for Operations )
用户需要一段时间才能完成操作,系统应该向用户提供当前运行任务的中间进度反馈和操作完成的百分比,关联操作的日志,在之前安装的Ambari版本,由于Puppet的主-代理体系结构及其状态报告机制,之前版本对状态这些显示是不可用的。
术语(Terminology )
服务(Service )
Services是指Hadoop堆栈中的服务,例如:HDFS, HBase, and Pig这些都是服务,一个服务有多个组件组成(例如:HDFS有NameNode,副本NameNode,DataNode 等),服务也可以是一个客户端的库(例如:Pig没有守护进程只有一个客户端库)
组件(Component)
服务由一个或多个组件组成,HDFS有NameNode,副本NameNode,DataNode 有三个组件,组件是可选的,一个组件可以跨域多个节点(例如:DataNode就可以是多个节点上的实例)
节点(Node/Host )
节点是指集群中的一台机器,本文中的Node或Host可以互相使用。
节点组件(Node-Component)
节点组件是指特定节点上的组件,特定节点上的特定DataNode实例就是节点组件
操作(Operation)
操作是指在集群上一组修改或操作,为满足用户的亲故或实现集群中的理想状态的修改。例如:启动服务是一个操作,冒烟测试也是一个操作。如果用户请求是为了给集群增加一个新的服务那么就应该包含运行一个冒烟测试。满足用户的整个请求的所有动作即将构成一个操作,一个操作应该由多个有序的动作组成(见下文)
任务(Task)
任务是为了发送到节点为了执行的工作单元,任务是节点作为执行的一部分工作的。例如:执行包含在节点1上安装一个datanode 和安装一个datanode 和一个副本datanode在 n2;这个例子中任务就是在n1节点安装一个datanode 和在n2节点安装一个datanode和一个datanode 副本。
阶段(Stage)
阶段意味着完成一个操作所需要的一组任务,这些任务互相独立。相同阶段的任务可以在不同节点并行
动作/行为(Action )
一个动作由在一台机器或一组机器上的多个任务组成。每个操作由一个操作id追踪,节点上报状态至少是以动作粒度的。一个动作被认为是一个阶段,本文中除非另有说明否则动作和阶段就是一一对应的。action id将是request-id和stage-id的双应射。
阶段计划(Stage Plan )
一个操作通常由不同机器上的多个任务组成,它们通常有依赖关系,要求它们以特定的顺序运行,在调度其他任务之前,有些任务需要先完成。因此,一个操作所需的任务可以分为不同的阶段,每个阶段必须在下一个阶段之前完成。但是所有相同阶段的所有任务可以在不同节点并行执行。
清单(Manifest )
Manifest指的是被发送到节点执行的任务的定义,清单必须完全定义任务,并且必须是可序列化的。清单也可以保存在磁盘上以进行恢复或记录
角色(Role)
角色可以映射到任意一个组件,例如:datanode,namedoe,或者是一个动作,例如:HDFS 重新平衡,Hbase冒烟测试,或其他管理命令等等
Ambari 架构(Architecture)
下图是Amabri的高级架构图
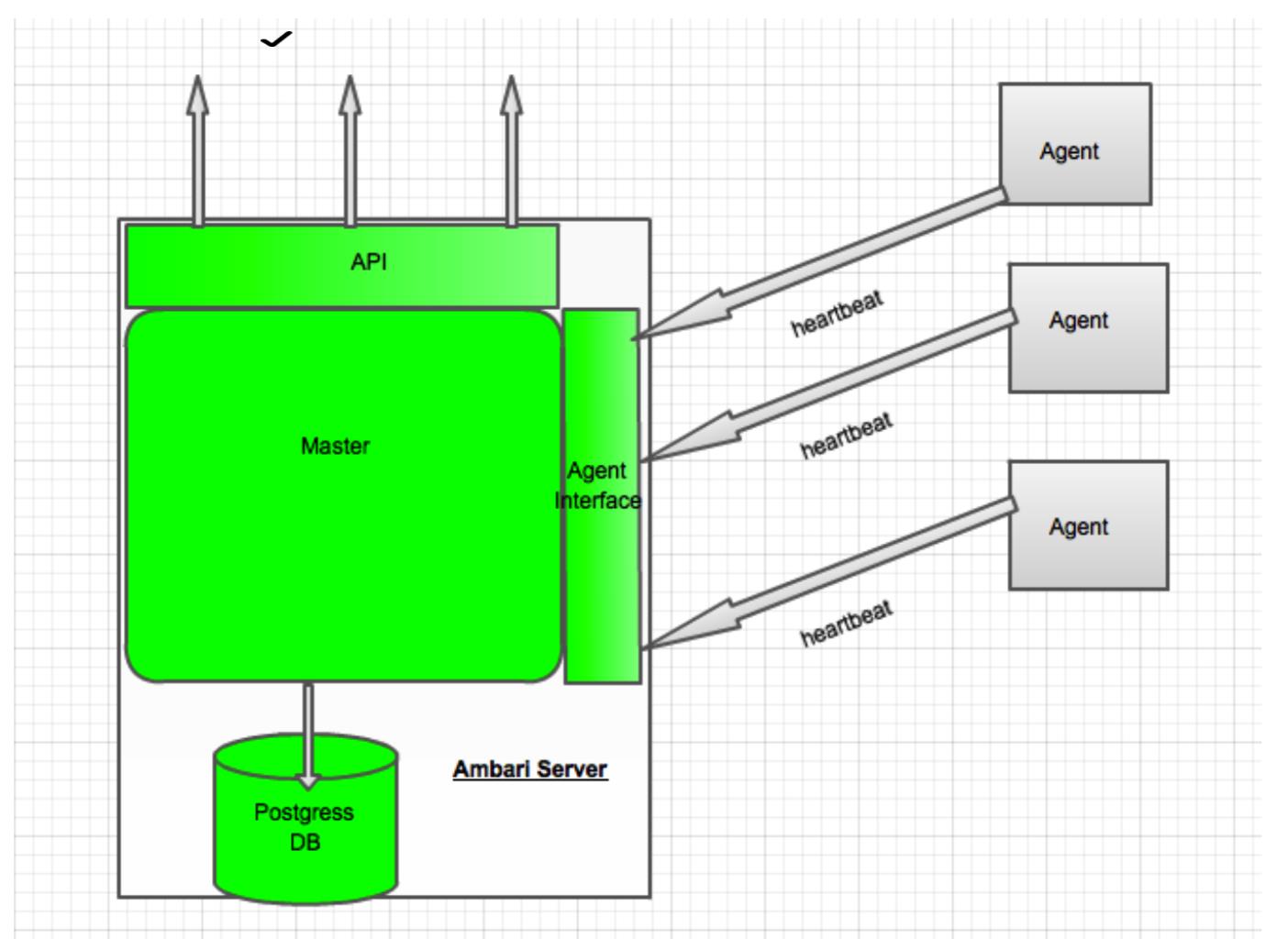
下面是Ambari的server端详细设计
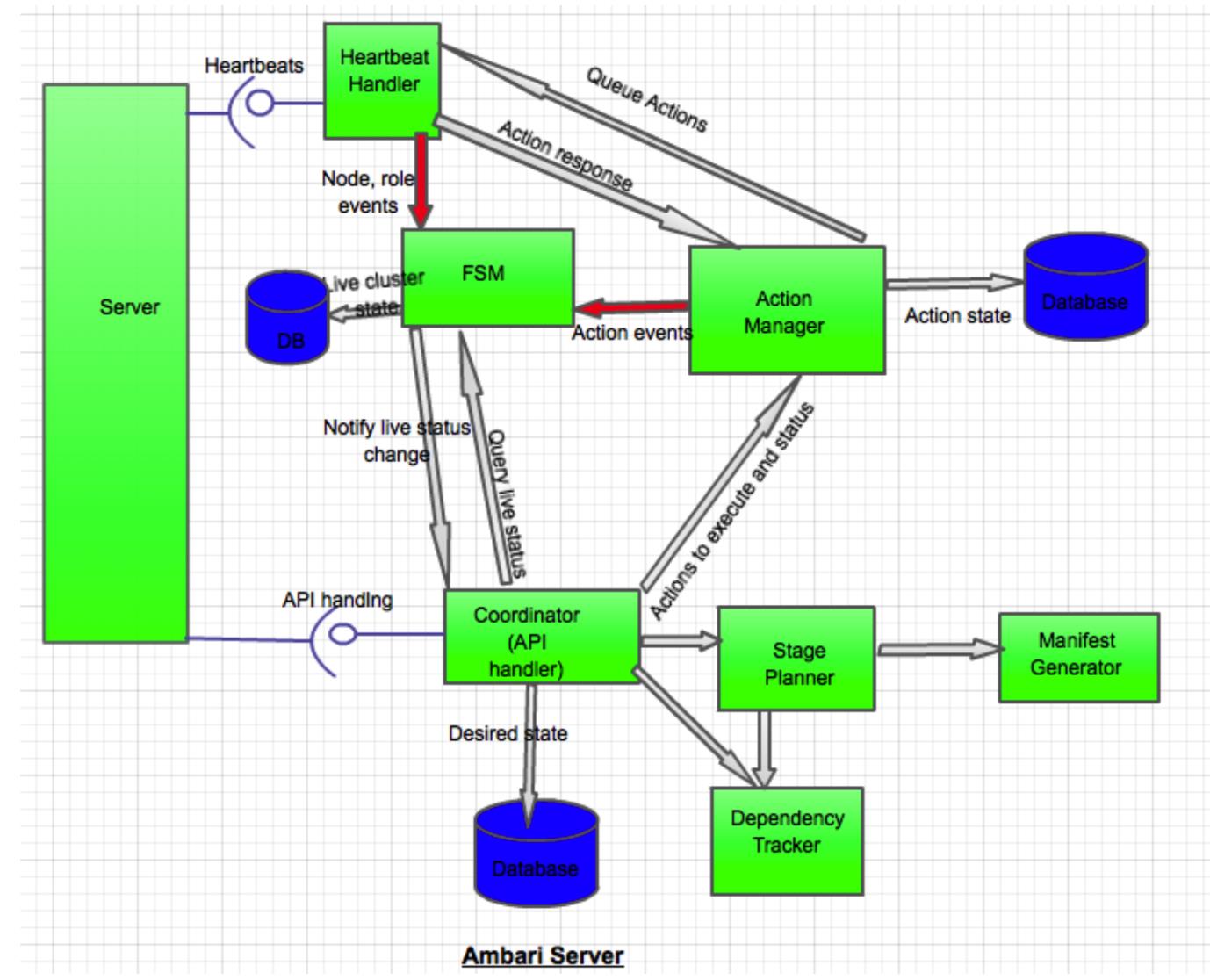
下图是Ambari的Agent详细设计
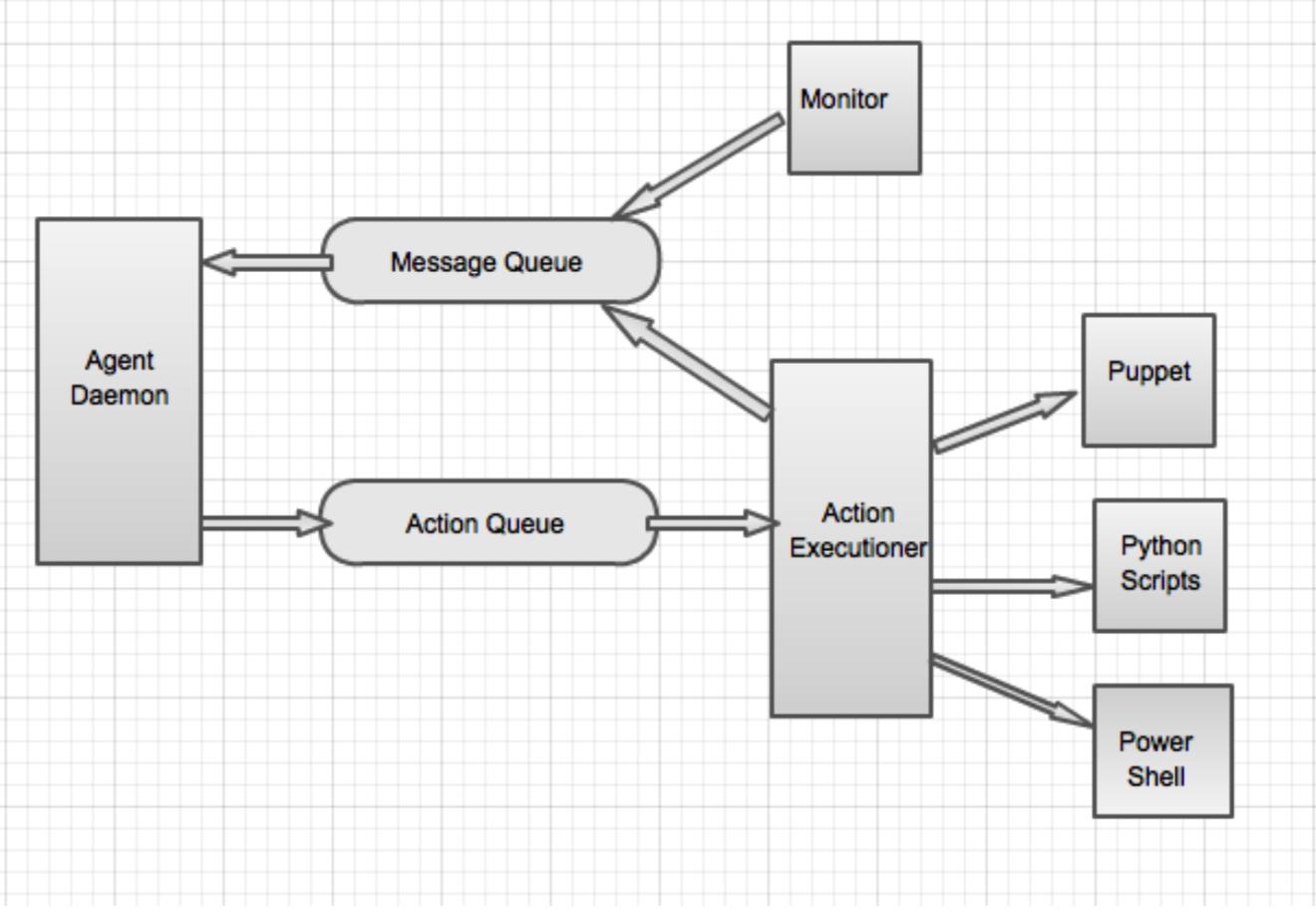
使用示例:
在本节中我们覆盖了一些基本使用例子和系统在更高层次上描述请求如何服务的和组件是如何交互的。
增加服务:
在已存在集群中增加一个服务,这里给出一个为一个已存在的集群增加 Hbase 服务的特殊例子,Habse的主和从将会增加到一个现有节点的子集(没有额外的节点),它将通过以下几个步骤:
- 请求通过API到达(lands on)服务器;每个请求都附有一个请求id,此API的处理在协调器中被调用;
- API的处理程序实现了向现有集群启动一个新的服务所需的所有步骤,在这种情况的步骤是:安装所有服务组件的必备条件,启动的先决条件是服务按着特定的顺序,并重新配置Nagios服务器和增加服务监控
- 协调器将在依赖跟踪其中查找并找到Hbase的先决条件,依赖跟踪器返回HDFS和ZK的组件,协调器也要查找Nagios服务的依赖项并且返回Habse的客户端。依赖跟踪器也将返回所需组件的依赖状态;因此(Thus ),协调器就会知道该组件的整个组成部分和他们所需要的状态,协调器将会在DB中设置所有组件的预期状态。
- 在上一步骤中(During the previous step),协调器也可能决定它需要用户输入来为ZK选择节点和返回一个适当的相应,这取决于API的定义。
- 协调器将传递组件列表和期望的状态给Stage Planner,Stage Planner 将返回那些组件需要在每个节点上执行安装/启动/修改的操作序列阶段。Stage Planner 使用 Manifest 生成器生成清单(为每个单独节点每个阶段的任务)
- 协调器(Coordinator )将有序的阶段列表传递给具有相应请求ID给 Action Manager。
- Action Manager将在FSM中更新每个节点组件的状态,这将反映一个操作正在进行中。需要注意的是,所有受影响的节点组件的FSM都已更新。在这一步中,FSM可能会检测到一个无效的事件并抛出失败,这将中止操作,所有的操作都将被标记为失败并出现错误
- Action Manager将为每个操作创建一个操作id,并将其添加到Plan中。Action Manager将从计划中选择第一个Stage,并将这个Stage中的每个操作添加到每个受影响节点的队列中。当第一阶段完成时将选择下一个阶段。Action Manager还将为预定的操作启动一个计时器
- Heartbeat Handler将接收操作的响应并通知操作管理器。Action Manager将发送一个事件到FSM来更新状态。如果出现超时,将再次安排该操作或将其标记为失败。一旦某个操作的所有节点都完成(收到响应或最终超时),则认为该操作已完成。一旦一个阶段的所有操作都完成了,这个阶段就被认为已经完成了
- 操作完成也记录在数据库中
- Action Manager 继续到下一个阶段和重复
执行冒烟测试
机器已激活,HDFS和HBase服务处于激活状态,用户想执行HBase的冒烟测试
- 请求通过API到达服务器,请求中带有一个请求ID
- API处理程序调用依赖服务跟踪程序并且找到HBase服务并运行起来,如果HBase得服务状态未运行,API处理器将跑出异常错误信息,处理程序还确定应该在何处运行冒烟测试。Dependency Tracker将公开一个方法,该方法将告诉协调器主机上需要哪个客户端组件,应该在哪里运行冒烟测试。调用阶段规划器来生成冒烟测试计划。在这种情况下,计划很简单,只有一个节点组件。其余的步骤与前面的用例类似
- 在这种情况下,FSM将专门用于hbase-smoketest角色
重新配置服务(Reconfigure Service )
- 集群已经激活了服务及其依赖项
- 请求将配置保存在服务器上,新的配置快照存储在服务器上,这个请求还应该包含关于配置更改影响哪些服务和/或角色的信息。
- 用户可以保存多个检查点
- 在某个时刻,用户决定部署新的配置。在这个场景中,用户将发送一个请求,将新的配置部署到所需的地方 服务/组件/节点
- 当这个请求通过协调器处理程序登陆到服务器时,它会 导致将相关对象所需的配置版本更新为 版本指定或基于API规范的最新配置
- 协调器将分两个步骤执行重新配置。首先,它将生成一个停止相关服务的阶段计划。然后,它将生成一个阶段计划,以使用新配置启动服务。协调器将附加两个计划,stop和start,并将其传递给动作管理器。剩下的 步骤按照前面的用例进行
Ambari 主当机和重新启动(Ambari master crashed and restarted)
-
Ambari主挂掉有多种情况需要解决
-
假如:
- 所需的状态已持久化到DB中
- 所有挂起的操作都在数据库中定义
- 实时状态在DB中被跟踪。但是,代理不能返回 当前的生活状态,所以要求将基于数据库状态
- 所有的动作都是幂等的
-
操作要求:
- Ambari主
- 操作层需要将所有未决的或先前已排队(但未完成)的阶段重新排队,返回到Heartbeat Handler,并允许代理重新执行相关步骤
- 在完全恢复之前,Ambari服务器不应该接受任何新的操作/请求
- 如果实际活动状态和所需状态之间存在任何差异(即活动状态为STARTED或STARTING,但所需状态为STOPPED),那么阶段计划器/事务管理器应该有一个触发器来启动操作,使状态变为所需状态,但是,如果活动状态是STOP FAILED,而期望的状态是STOPPED,那么这是一个无法恢复的操作,因为在这种情况下,Ambari服务器本身不会启动操作。对于后一种情况,管理/用户有责任为失败的节点重新发起停止[这可能取决于API规范和产品决策
- Ambari agent
- 如果突然挂掉,代理不应该死亡。它 应继续定期轮询,并在主服务器恢复时根据需要恢复
- Ambari代理应该保留所有必要的信息,以便在连接失败时发送给主机,并在主机恢复后重新发送这些信息
- 如果之前在注册过程中,可能需要重新注册
- Ambari主
退掉一个datanode子集(Decommission a subset of Datanodes)
- 退役将作为在Puppet层hadoop- admin角色上执行的一个操作来实现。hadoop-admin将是定义的一个新角色,涵盖hadoop管理操作。此角色将要求安装hadoop-client并具有可用的管理特权
- 退役操作的清单将由hadoop-admin角色和某些参数组成,如数据节点列表和指定操作的标志
- 协调器将识别指定运行hadoop-admin操作的节点。该信息必须在集群状态下可用
- 退役操作将跟随作为操作的节点角色的状态机。这将被认为是成功的,当退役已经开始在namenode,即当管理命令datanode成功
- 应单独查询节点是否已退役的信息。这些信息在namenode UI中可用。Ambari应该有另一个API来查询退役或退役的数据节点
- Ambari不跟踪datanode是退役还是退役。为了从Ambari中删除退役的节点,应该对Ambari进行单独的API调用,以停止/卸载这些datanode
Agent
代理将每隔几秒钟与主服务器进行心跳,并在心跳响应中接收来自主服务器的命令。心跳响应将是master向代理发送命令的唯一方式。命令将在操作队列中排队,操作执行程序将拾取操作队列。Action executioner将根据命令类型和操作类型选择正确的工具(Puppet, Python等)执行。因此,在心跳响应中发送的操作将在代理上异步处理。动作执行器将把响应或进度消息放在消息队列中
Recovery
在主恢复方面有两个主要选择
-
有基于操作的恢复:在这种情况下,每个操作都是持久化的,在重新启动时,主程序检查挂起的操作并重新调度它们。集群的状态也会持久化到数据库中,并且主服务器会在重新启动时重新构建状态机。可能存在一个竞态条件,即某些操作可能已经完成,但是主服务器在记录它们的完成之前崩溃了,这将通过确保操作是幂等的来处理,主服务器将重新调度DB中未标记为完成或失败的所有操作。持久化操作可以被视为重做日志,重做日志是一个
-
与上述方法交替使用的是基于所需状态的恢复。在这种方法中,主服务器将保持所需的状态,并在重新启动时将所需的状态与活动状态匹配,并尝试将集群恢复到所需的状态
基于行动的方法更好地与我们的整体设计相结合,因为我们预先计划了一个行动并坚持它,因此,即使我们坚持想要的状态,恢复将需要重新计划行动。另外,从Ambari的观点来看,理想的状态方法不捕获某些不会改变集群状态的操作,例如烟雾测试或hdfs重新平衡。持久化操作可以被视为重做日志 -
代理恢复只需要重新启动代理,因为代理是无状态的。主机将通过心跳损失超过时间阈值检测到代理失败。
待定:如何重新启动代理?
结尾
如何获取Ambari原文PDF可直接加作者 VX
欢迎和作者一起探讨如何成为一名优秀的软件测试工程师,实现软件测试工程师的自我价值~ 从而实现升职加薪 迎娶白富美 走向人生巅峰…(😏😏😏😏😏😏😏😏😏😏)
作者VX:1010584905
以上是关于Ambari架构设计文档 -- (官方翻译版)的主要内容,如果未能解决你的问题,请参考以下文章