Swin Transformer为主干,清华等提出MoBY自监督学习方法,代码已开源
Posted 机器学习算法与Python学习-公众号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Swin Transformer为主干,清华等提出MoBY自监督学习方法,代码已开源相关的知识,希望对你有一定的参考价值。
点击 机器学习算法与Python学习 ,选择加星标
精彩内容不迷路
选自arXiv,作者:Zhenda Xie等
机器之心编译
来自清华大学、西安交大、微软亚研的研究者提出了一种称为 MoBY 的自监督学习方法,其中以 Vision Transformer 作为其主干架构,将 MoCo v2 和 BYOL 结合,并在 ImageNet-1K 线性评估中获得相当高的准确率,性能优于 MoCo v3、DINO 等网络。
近两年来,计算机视觉领域经历了两次重大转变,第一次是由 MoCo(Momentum Contrast)开创的自监督视觉表征学习,其预训练模型经过微调可以迁移到不同的任务上;第二次是基于 Transformer 的主干架构,近年来在自然语言处理中取得巨大成功的 Transformer 又在计算机视觉领域得到了探索,进而产生了从 CNN 到 Transformer 的建模转变。
不久前,微软亚研的研究者提出了一种通过移动窗口(shifted windows)计算的分层视觉 Swin Transformer,它可以用作计算机视觉的通用主干网络。在各类回归任务、图像分类、目标检测、语义分割等方面具有极强性能。
而在近日,来自清华大学、西安交通大学以及微软亚洲研究院的研究者也在计算机视觉领域发力,提出了名为 MoBY 自监督学习方法,以 Vision Transformers 作为其主干架构,将 MoCo v2 和 BYOL 结合在一起,在 ImageNet-1K 线性评估中获得相当高的准确率:通过 300-epoch 训练,分别在 DeiT-S 和 Swin-T 获得 72.8% 和 75.0% 的 top-1 准确率。与使用 DeiT 作为主干的 MoCo v3 和 DINO 相比,性能略好,但trick要轻得多。
更重要的是,使用 Swin Transformer 作为主干架构,还能够评估下游任务中(目标检测和语义分割等)的学习表征,其与最近的 ViT/DeiT 方法相比,由于 ViT / DeiT 不适合这些密集的预测任务,因此仅在 ImageNet-1K 上报告线性评估结果。研究者希望该结果可以促进对 Transformer 架构设计的自监督学习方法进行更全面的评估。

论文地址:https://arxiv.org/pdf/2105.04553.pdf
GitHub 地址:https://github.com/SwinTransformer/Transformer-SSL
方法介绍
自监督学习方法 MoBY 由 MoCo v2 和 BYOL 这两个比较流行的自监督学习方法组成,MoBY 名字的由来是各取了 MoCo v2 和 BYOL 前两个字母。MoBY 继承了 MoCo v2 中的动量设计、键队列、对比损失,此外 MoBY 还继承了 BYOL 中非对称编码器、非对称数据扩充、动量调度(momentum scheduler)。MoBY 架构图如下图 1 所示:
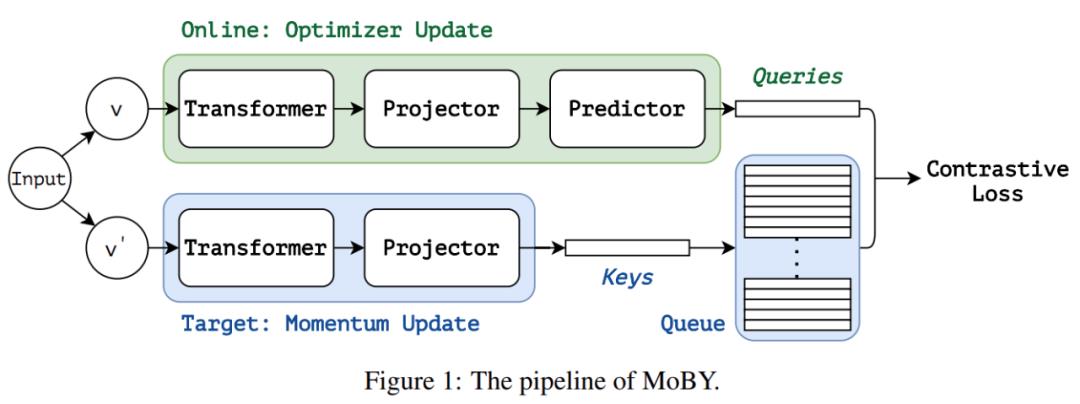
MoBY 包含两个编码器:在线编码器和目标编码器。这两个编码器都包含一个主干和 projector head(2 层 MLP),在线编码器引入了额外的预测头(2 层 MLP),使得这两个编码器具有非对称性。在线编码器采用梯度更新,目标编码器则是在线编码器在每次训练迭代中通过动量更新得到的移动平均值。对目标编码器采用逐渐增加动量更新策略:训练过程中,动量项值默认起始值为 0.99,并逐渐增加到 1。
学习表征采用对比损失,具体而言,对于一个在线视图(online view)q,其对比损失计算公式如下所示:
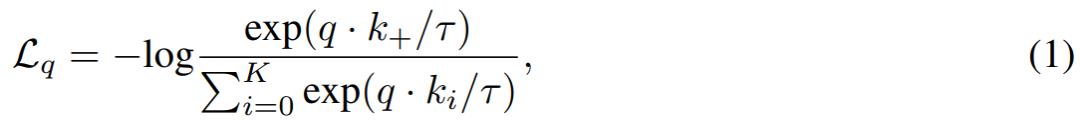
式中,κ_+ 为同一幅图像的另一个视图(view)的目标特征;κ_i 是键队列( key queue )中的目标特性;τ是 temperature 项;Κ是键队列的大小(默认为 4096)。
在训练中,与大多数基于 Transformer 的方法一样,研究者还采用了 AdamW 优化器。
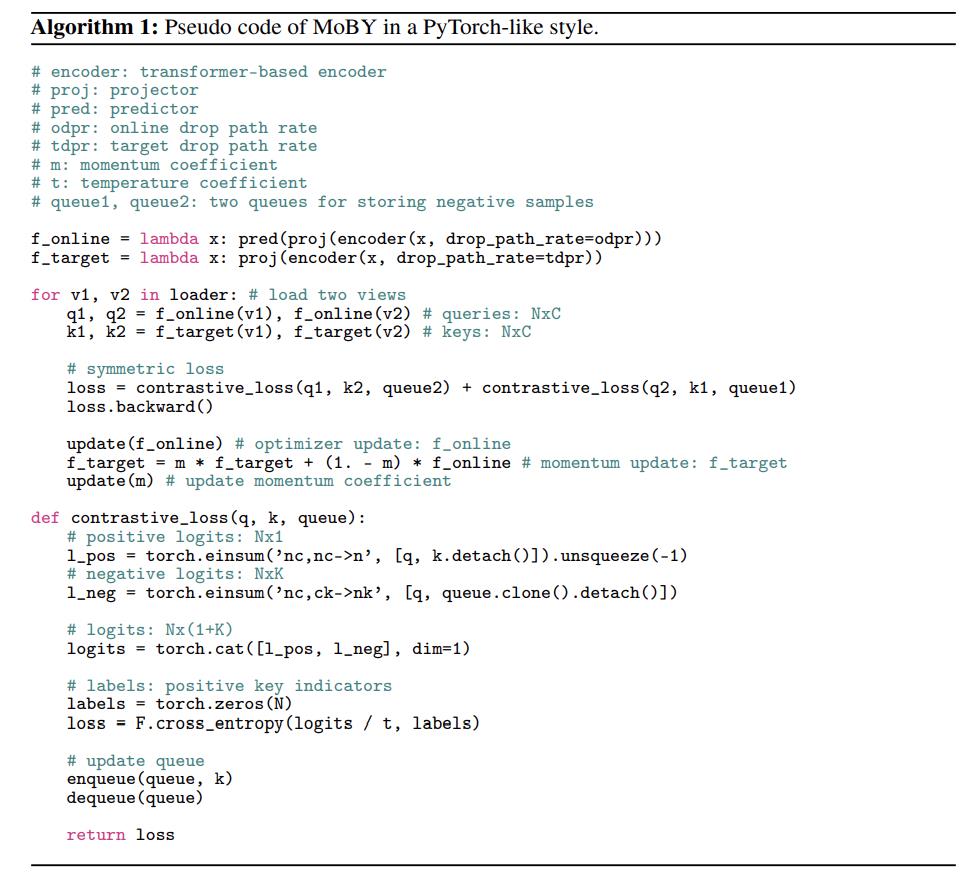
MoBY 伪代码如下所示:
实验
在 ImageNet-1K 上的线性评估
在 ImageNet-1K 数据集上进行线性评估是一种常用的评估学得的表征质量的方式。在该方式中,线性分类器被用于主干,主干权重被冻结,仅训练线性分类器。训练完线性分类器之后,使用中心裁剪(center crop)在验证集上取得了 top-1 准确率。
表 1 给出了使用各种自监督学习方法和主干网络架构的预训练模型的主要性能结果。
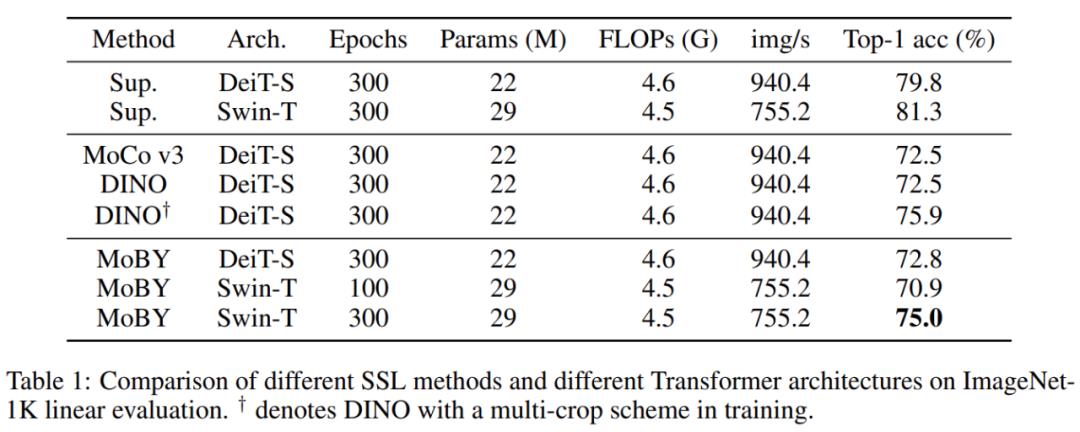
1.与使用 Transformer 架构的其他 SSL 方法进行比较
MoCo v3、DINO 等方法采用 ViT/DeiT 作为主干网络架构,该研究首先给出了使用 DeiT-S 的 MoBY 的性能结果,以便与该研究的方法进行合理比较。经过了 300 个 epoch 的训练,MoBY 达到了 72.8% top-1 的准确率,这比 MoCo v3 和 DINO(不含多次裁剪(multi-crop))略胜一筹,结果如表 1 所示。
2.Swin-T VS DeiT-S
研究者还比较了在自监督学习中各种 Transformer 架构的使用情况。如表 1 所示,Swin-T 达到了 75.0% top-1 的准确率,比 DeiT-S 高出 2.2%。值得一提的是,这一性能差距比使用监督学习还大(+1.5%)。
该研究进行的初步探索表明,固定 patch 嵌入对 MoBY 没有用,并且在 MLP 块之前用批归一化代替层归一化层可以让 top-1 准确率提升 1.1%(训练 epoch 为 100),如表 2 所示。

在下游任务上的迁移性能
研究者评估了学得的表征在 COCO 目标检测 / 实例分割和 ADE20K 语义分割的下游任务上的迁移性能。
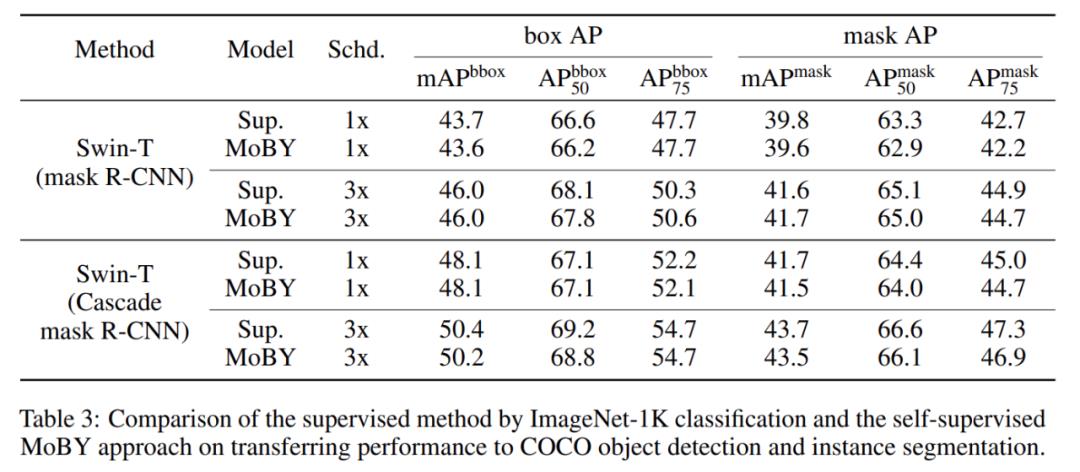
1.COCO 目标检测和实例分割
评估中采用了两个检测器:Mask R-CNN 和 Cascade Mask R-CNN。表 3 给出了在 1x 和 3x 设置下由 MoBY 学得的表征和预训练监督方法的比较结果。
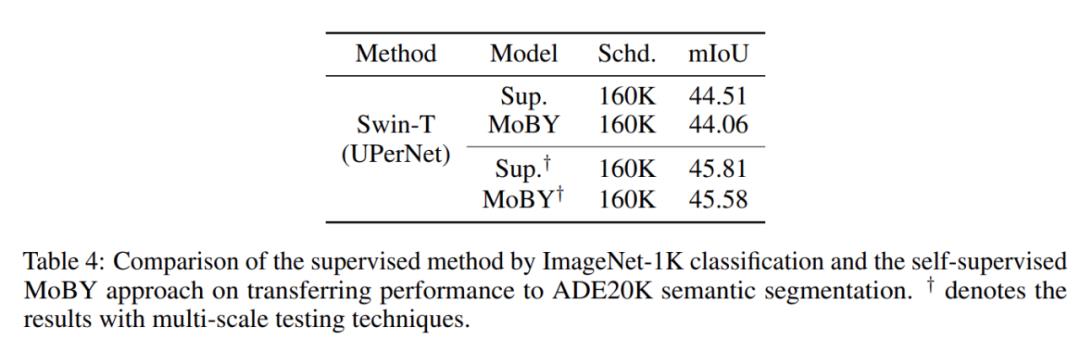
2.ADE20K 语义分割
研究者采用 UPerNet 方法和 ADE20K 数据集进行评估。表 4 给出了监督和自监督预训练模型的比较结果。这表明 MoBY 的性能比监督方法稍差一点,这意味着使用 Transformer 架构进行自监督学习具有改进空间。
消融实验
研究者又进一步使用 ImageNet-1K 线性评估进行了消融实验,其中 Swin-T 为主干网络架构。
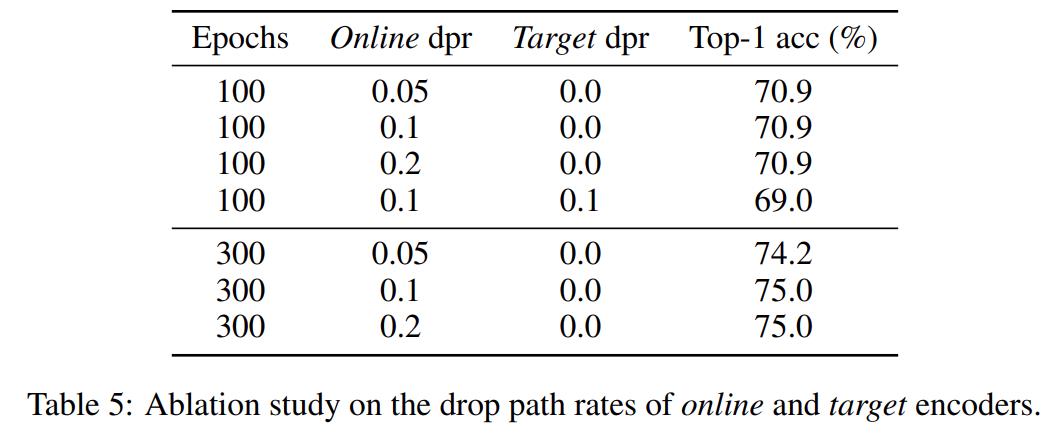
1.不对称的 drop path rate 是有益的
对于使用图像分类任务和 Transformer 架构的监督表征学习来说,drop path 是一种有效的正则化方法。研究者通过消融实验探究了该正则化方法的影响,实验结果如下表 5 所示。
2.其他超参数
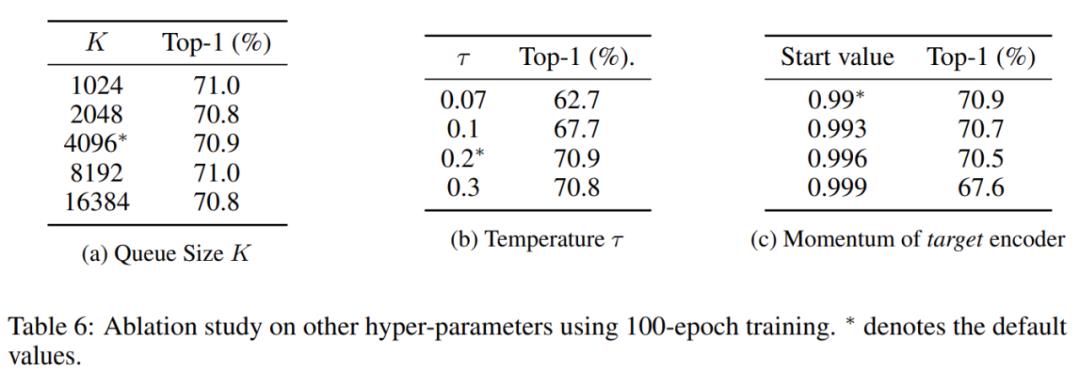
第一组消融实验探究了键队列大小 K 从 1024 到 16384 的影响,实验结果如表 6(a) 所示。该方法在不同 K(从 1024 到 16384)下都能够稳定执行,其中采用 4096 作为默认值。
第二组消融实验探究了温度(temperature)τ的影响,实验结果如表 6(b) 所示。其中τ为 0.2 时性能最佳,0.2 也是默认值。
第三组消融实验探究了目标编码器的初始动量值的影响,实验结果如表 6(c) 所示。其中值为 0.99 时性能最佳,并被设为默认值。
如果对你有帮助。
请不吝点赞,点在看,谢谢
以上是关于Swin Transformer为主干,清华等提出MoBY自监督学习方法,代码已开源的主要内容,如果未能解决你的问题,请参考以下文章
改进YOLOv5系列:增加Swin-Transformer小目标检测头
Swin Transformer v2实战:使用Swin Transformer v2实现图像分类
论文解析[9] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
论文笔记:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows