Yolov3网络架构分析
Posted 吴建明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Yolov3网络架构分析相关的知识,希望对你有一定的参考价值。
Yolov3网络架构分析
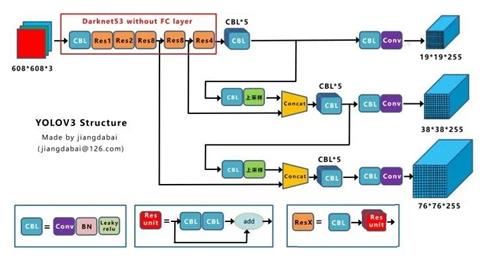
上图三个蓝色方框内表示Yolov3的三个基本组件:
l CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。
l Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
l ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。
其他基础操作:
l Concat:张量拼接,会扩充两个张量的维度,例如26*26*256和26*26*512两个张量拼接,结果是26*26*768。Concat和cfg文件中的route功能一样。
l add:张量相加,张量直接相加,不会扩充维度,例如104*104*128和104*104*128相加,结果还是104*104*128。add和cfg文件中的shortcut功能一样。
Backbone中卷积层的数量:
每个ResX中包含1+2*X个卷积层,因此整个主干网络Backbone中一共包含1+(1+2*1)+(1+2*2)+(1+2*8)+(1+2*8)+(1+2*4)=52,再加上一个FC全连接层,即可以组成一个Darknet53分类网络。不过在目标检测Yolov3中,去掉FC层,不过为了方便称呼,仍然把Yolov3的主干网络叫做Darknet53结构。
- backbone:Darknet-53

在第1个卷积操作DarknetConv2D_BN_Leaky()中,是3个操作的组合,即
- 1个Darknet的2维卷积Conv2D层,即DarknetConv2D();
- 1个正则化(BN)层,即BatchNormalization();
- 1个LeakyReLU层,斜率是0.1,LeakyReLU是ReLU的变换;
backbone部分由Yolov2时期的Darknet-19进化至Darknet-53,加深了网络层数,引入了Resnet中的跨层加和操作。原文列举了Darknet-53与其他网络的对比:
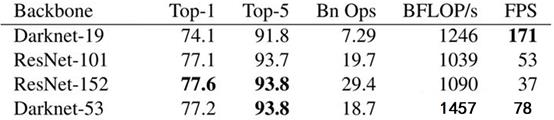
图三. Darknet精度性能对比
Darknet-53处理速度每秒78张图,比Darknet-19慢不少,但是比同精度的ResNet快很多。Yolov3依然保持了高性能。
(这里解释一下Top1和Top5:模型在ImageNet数据集上进行推理,按照置信度排序总共生成5个标签。按照第一个标签预测计算正确率,即为Top1正确率;前五个标签中只要有一个是正确的标签,则视为正确预测,称为Top5正确率)
- Yolov3网络结构细节
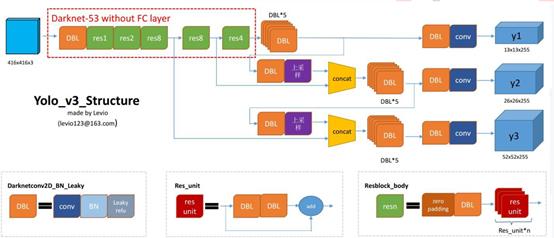
DBL: 上图左下角所示,也就是代码中的Darknetconv2d_BN_Leaky,是yolo_v3的基本组件。就是卷积+BN+Leaky relu。对于v3来说,BN和leaky relu(正则化和激励)已经是和卷积层不可分离的部分了(最后一层卷积除外),共同构成了最小组件。
resn:n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。这是yolo_v3的大组件,yolo_v3开始借鉴了ResNet的残差结构,使用这种结构可以让网络结构更深(从v2的darknet-19上升到v3的darknet-53,前者没有残差结构)。对于res_block的解释,可以在图1的右下角直观看到,其基本组件也是DBL。
concat:张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
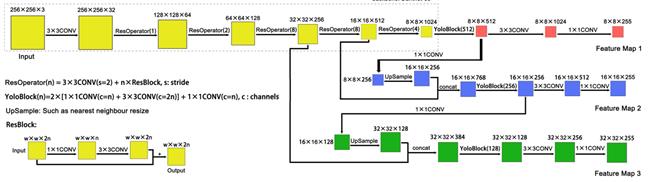
网络结构解析:
- Yolov3中,只有卷积层,通过调节卷积步长控制输出特征图的尺寸。所以对于输入图片尺寸没有特别限制。流程图中,输入图片以256*256作为样例。Yolov3借鉴了金字塔特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。特征图的输出维度为
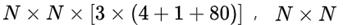 为输出特征图格点数,一共3个Anchor框,每个框有4维预测框数值
为输出特征图格点数,一共3个Anchor框,每个框有4维预测框数值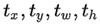 ,1维预测框置信度,80维物体类别数。所以第一层特征图的输出维度为
,1维预测框置信度,80维物体类别数。所以第一层特征图的输出维度为 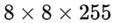 。
。 - Yolov3总共输出3个特征图,第一个特征图下采样32倍,第二个特征图下采样16倍,第三个下采样8倍。输入图像经过Darknet-53(无全连接层),再经过Yoloblock生成的特征图被当作两用,第一用为经过3*3卷积层、1*1卷积之后生成特征图一,第二用为经过1*1卷积层加上采样层,与Darnet-53网络的中间层输出结果进行拼接,产生特征图二。同样的循环之后产生特征图三。
- 上采样层(upsample):作用是将小尺寸特征图通过插值等方法,生成大尺寸图像。例如使用最近邻插值算法,将8*8的图像变换为16*16。上采样层不改变特征图的通道数。
- 激活函数concat操作与加和操作的区别:加和操作来源于ResNet思想,将输入的特征图,与输出特征图对应维度进行相加,即
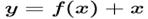
;而concat操作源于DenseNet网络的设计思路,将特征图按照通道维度直接进行拼接,例如8*8*16的特征图与8*8*16的特征图拼接后生成8*8*32的特征图。
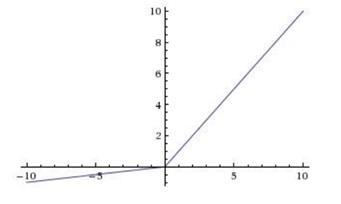
LeakyReLU的激活函数,如下
其中,Darknet的2维卷积DarknetConv2D,具体操作如下:
- 将核权重矩阵的正则化,使用L2正则化,参数是5e-4,即操作w参数;
- Padding,一般使用same模式,只有当步长为(2,2)时,使用valid模式。避免在降采样中,引入无用的边界信息;
- 其余参数不变,都与二维卷积操作Conv2D()一致;
kernel_regularizer是将核权重参数w进行正则化,而BatchNormalization是将输入数据x进行正则化。
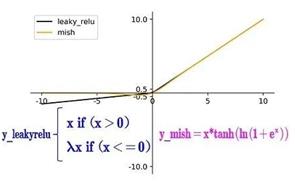
Leaky_Relu(yolov3)与mish(yolov4),如下
- 残差流程
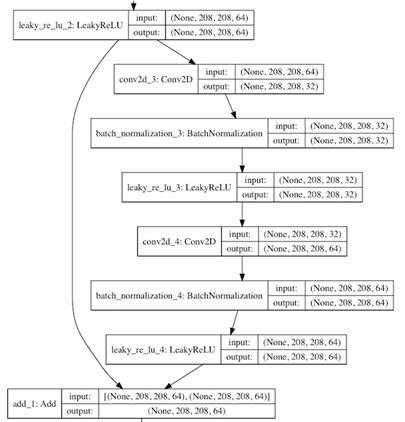
在darknet_body()中,执行5组resblock_body()残差块,重复[1, 2, 8, 8, 4]次,双卷积(1x1和3x3)操作,每组均含有一次步长为2的卷积操作,因而一共降维5次32倍,即32=2^5,则输出的特征图维度是13,即13=416/32。最后1层的通道(filter)数是1024,因此,最终的输出结构是(?, 13, 13, 1024)。
- 特征图
特征图
在YOLO v3网络中,输出3个不同尺度的检测图,用于检测不同大小的物体。调用3次make_last_layers(),产生3个检测图,即y1、y2和y3。
13x13检测图
第1个部分,输出维度是13x13。在make_last_layers()方法中,输入参数如下:
- darknet.output:DarkNet网络的输出,即(?, 13, 13, 1024);
- num_filters:通道个数512,用于生成中间值x,x会传导至第2个检测图;
- out_filters:第1个输出y1的通道数,值是锚框数*(类别数+4个框值+框置信度);
在make_last_layers()方法中,执行2步操作:
- 第1步,x执行多组1x1的卷积操作和3x3的卷积操作,filter先扩大再恢复,最后与输入的filter保持不变,仍为512,则x由(?,13, 13, 1024)转变为(?, 13, 13, 512);
- 第2步,x先执行3x3的卷积操作,再执行不含BN和Leaky的1x1的卷积操作,作用类似于全连接操作,生成预测矩阵y;
26x26检测图
第2个部分,输出维度是26x26,包含以下步骤:
- 通过DarknetConv2D_BN_Leaky卷积,将x由512的通道数,转换为256的通道数;
- 通过2倍上采样UpSampling2D,将x由13x13的结构,转换为26x26的结构;
- 将x与DarkNet的第152层拼接Concatenate,作为第2个尺度特征图;
52x52检测图
第3部分的输出结构,52x52,与第2部分类似,如下:
逻辑如下:
- x经过128个filter的卷积,再执行上采样,输出为(?, 52, 52, 128);
- darknet.layers[92].output,与152层类似,结构是(?, 52, 52, 256);
- 两者拼接之后是(?, 52, 52, 384);
- 最后输入至make_last_layers,生成y3是(?, 52, 52, 18),忽略x的输出;
- 最后,则是模型的重组,输入inputs依然保持不变,即(?, 416, 416, 3),而输出转换为3个尺度的预测层,即[y1, y2,
y3]。
参考链接:
https://blog.csdn.net/loco1223/article/details/92078816
https://zhuanlan.zhihu.com/p/76802514
https://blog.csdn.net/weixin_47196664/article/details/106536656
以上是关于Yolov3网络架构分析的主要内容,如果未能解决你的问题,请参考以下文章