Python机器学习预测苹果酸甜度
Posted 柯兆祥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python机器学习预测苹果酸甜度相关的知识,希望对你有一定的参考价值。
一、选题背景
经常无法判断哪个苹果会比较酸或者甜,有的人喜欢甜,有的人喜欢酸,但是都是只能运用乡间办法以及猜测,都属于并不科学的办法,所以想要用机器学习来预测苹果的酸甜度。
二、机器学习案例设计方案
数据集来源:
数据来源于Kaggle,主要为开发商和数据科学家提供举办机器学习竞赛、托管数据库、编写和分享代码的平台。该平台已经吸引了80万名数据科学家的关注,这些用户资源或许正是吸引谷歌的主要因素。
采用的机器学习框架描述:
卷积神经网络(Convolutional Neural Network, CNN):卷积神经网络是深度学习技术中极具代表的网络结构之一,在图像处理领域取得了很大的成功,在国际标准的 ImageNet 数据集上,许多成功的模型都是基于 CNN 的。
Keras:Keras是一个模型级( model-level)的库,为开发深度学习模型提供了高层次的构建模块。它不处理张量操作、求微积分等基础的运算,而是依赖--个专门的、高度优化的张量库来完成这些运算。这个张量库就是Keras的后端引擎(backend engine),如TensorFlow等。
TensorFlow :TensorFlow 是一个开源机器学习框架,具有快速、灵活并适合产品级大规模应用等特点,让每个开发者和研究者都能方便地使用人工智能来解决多样化的挑战。
涉及到的技术难点:
容易测试中断,需要多多尝试
导入所需的库
1 import os 2 import random 3 import itertools 4 import numpy as np 5 import pandas as pd 6 import seaborn as sns 7 import tensorflow as tf 8 import matplotlib.pyplot as plt 9 from tensorflow.keras import layers 10 from sklearn import preprocessing 11 from sklearn.decomposition import PCA 12 from sklearn import model_selection as ms 13 from sklearn.metrics import confusion_matrix 14 from tensorflow.keras.optimizers import Adamax 15 from tensorflow.keras.initializers import RandomNormal 16 from sklearn.linear_model import LogisticRegression 17 from sklearn.metrics import classification_report 18 from sklearn.model_selection import train_test_split 19 from sklearn.preprocessing import StandardScaler 20 from sklearn import metrics
查看库对应的版本
1 pip list


原始数据读取
定义读取txt文件函数,对数据进行读取
1 def getInfo(samplePath): 2 with open(samplePath, "r") as f: # 打开文件 3 datas = f.readlines() 4 5 totalList = [] # 定义空列表 6 for data in datas: 7 list1 = data.split("\\t") 8 list2 = [] 9 for i in list1: 10 list2.append(float(i)) 11 totalList.append(list2) # 将读取后的文件放入列表 12 return totalList # 返回装有数据的列表
将处特征数据的txt文件读取后放至空列表中
1 path0 = \'./res_data/Feature_0.txt\' 2 path1 = \'./res_data/Feature_1.txt\' 3 path2 = \'./res_data/Feature_2.txt\' 4 path3 = \'./res_data/Feature_3.txt\' 5 path4 = \'./res_data/Feature_4.txt\' 6 path5 = \'./res_data/Feature_5.txt\' 7 path6 = \'./res_data/Feature_6.txt\' 8 path7 = \'./res_data/Feature_7.txt\' 9 path8 = \'./res_data/Feature_8.txt\' 10 path9= \'./res_data/Feature_9.txt\' 11 path10 = \'./res_data/Feature_10.txt\' 12 path11 = \'./res_data/Feature_11.txt\' 13 path12 = \'./res_data/Feature_12.txt\' 14 path13 = \'./res_data/Feature_13.txt\' 15 path14 = \'./res_data/Feature_14.txt\' 16 path15 = \'./res_data/Feature_15.txt\' 17 path16 = \'./res_data/Feature_16.txt\' 18 19 totalList = [] 20 data0 = getInfo(path0) 21 data1 = getInfo(path1) 22 data2 = getInfo(path2) 23 data3 = getInfo(path3) 24 data4 = getInfo(path4) 25 data5 = getInfo(path5) 26 data6 = getInfo(path6) 27 data7 = getInfo(path7) 28 data8 = getInfo(path8) 29 data9 = getInfo(path9) 30 data10 = getInfo(path10) 31 data11 = getInfo(path11) 32 data12 = getInfo(path12) 33 data13 = getInfo(path13) 34 data14 = getInfo(path14) 35 data15 = getInfo(path15) 36 data16 = getInfo(path16) 37 38 for i in range(len(data1)): 39 totalList.append(data1[i] + data2[i] + data3[i] + data4[i] + data5[i] + data6[i] + data7[i] + data8[i] + data9[i] + data10[i] + data11[i] + data12[i] + data13[i] + data14[i] + data15[i] + data16[i])
读取标签数据集(已对数据进行了二分类标签处理,0-酸苹果,1-甜苹果)
1 labelPath = \'./labels.txt\' 2 3 labels = open(labelPath, "r") 4 label = labels.readlines() 5 trueLabelList = [] 6 for r in label: 7 labelList = [] 8 labelList = r.split("\\t") 9 trueLabelList.append(int(labelList[len(labelList)-1]))
查看数据的数量
1 label0 = np.sum(np.array(trueLabelList) == 0) 2 label1 = np.sum(np.array(trueLabelList) == 1) 3 4 print(label0) 5 print(label1)

数据集打乱及划分
1 totalArr = np.array(totalList, dtype=float) # 将数据转为数组格式 2 trueLabelArr = np.array(trueLabelList, dtype=int) 3 4 indx = [i for i in range(len(totalArr))] 5 random.shuffle(indx) 6 totalArr = totalArr[indx] 7 trueLabelArr = trueLabelArr[indx] 8 9 input_features = preprocessing.StandardScaler().fit_transform(totalArr) # 对数据进行标准化 10 11 train_x, test_x, train_y, test_y = ms.train_test_split(input_features, trueLabelArr, test_size=0.2) # 数据集划分
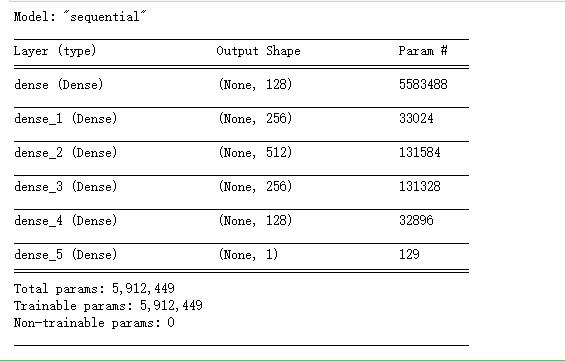
1 # 搭建网络模型 2 model= tf.keras.Sequential() 3 model.add(layers.Dense(128,kernel_initializer=RandomNormal(mean=0.0,stddev=0.05,seed=None),input_dim=43620)) 4 5 # model.add(layers.Dropout(0.2)) 6 model.add(layers.Dense(256,activation=\'relu\',use_bias=True)) 7 8 # model.add(layers.Dropout(0.3)) 9 model.add(layers.Dense(512,activation=\'relu\',use_bias=True)) 10 11 # model.add(layers.Dropout(0.4)) 12 model.add(layers.Dense(256, activation=\'relu\', use_bias=True)) 13 14 # model.add(layers.Dropout(0.3)) 15 model.add(layers.Dense(128, activation=\'relu\', use_bias=True)) 16 17 # model.add(layers.Dropout(0.2)) 18 19 # model.add(layers.Dense(128,activation=\'relu\',use_bias=True)) 20 21 # model.add(layers.Dropout(0.1)) 22 model.add(layers.Dense(1,activation=\'sigmoid\')) 23 24 model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.0001), 25 loss = \'binary_crossentropy\', metrics=[\'accuracy\']) 26 27 model.summary()
模型训练过程
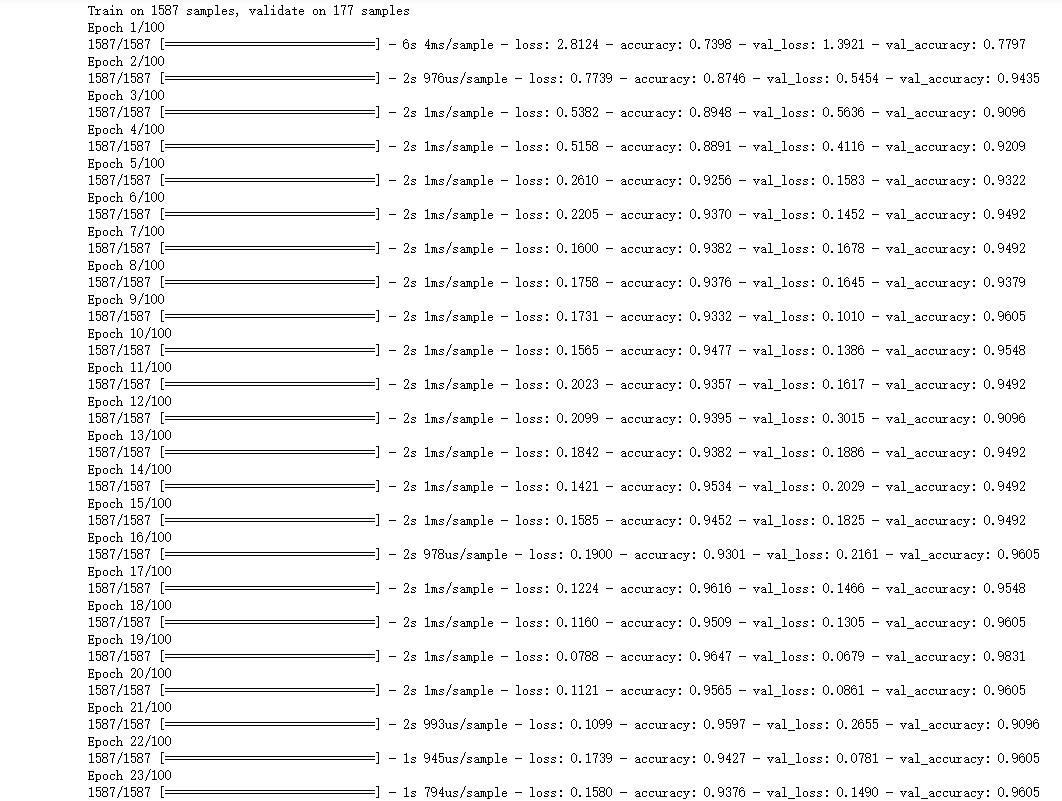
1 model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.001), 2 loss = \'binary_crossentropy\', metrics=[\'accuracy\']) 3 history = model.fit(train_x, train_y,validation_split=0.1, epochs=100,batch_size=32, verbose=1)


1 # 使用predict方法进行预测 2 yPre = model.predict(test_x)
1 # 打印输出BP神经网络的评估 2 print("BP神经网络准确值:{}".format(metrics.accuracy_score(test_y,yPre.round()))) 3 print("BP神经网络精确度:{}".format(metrics.precision_score(test_y,yPre.round()))) 4 print("BP神经网络召回率:{}".format(metrics.recall_score(test_y,yPre.round()))) 5 print("BP神经网络的F1评分{}".format(metrics.f1_score(test_y,yPre.round())))

打印出其混淆矩阵
1 cMatrix = metrics.confusion_matrix(test_y, yPre.round(), normalize=None) 2 3 pdMatrix = pd.DataFrame(cMatrix, index=["0","1"], columns=["0","1"]) 4 plt.subplots(figsize=(8,8)) 5 sns.heatmap(pdMatrix, annot=True, cbar=None, fmt=\'g\') 6 plt.ylabel("True Class") 7 plt.xlabel("Predicted Class") 8 plt.show()

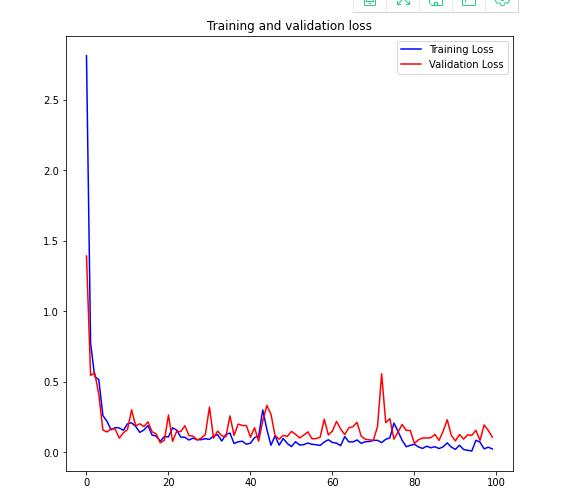
画出训练集和验证集accuracy以及loss的走向
1 acc = history.history[\'accuracy\'] 2 val_acc = history.history[\'val_accuracy\'] 3 loss = history.history[\'loss\'] 4 val_loss = history.history[\'val_loss\'] 5 6 epochs = range(len(acc)) 7 8 plt.subplots(figsize=(8,8)) 9 plt.plot(epochs, acc, \'b\', label=\'Training accuracy\') 10 plt.plot(epochs, val_acc, \'r\', label=\'Validation accuracy\') 11 plt.title(\'Training and validation accuracy\') 12 plt.legend() 13 14 # plt.figure() 15 plt.subplots(figsize=(8,8)) 16 plt.plot(epochs, loss, \'b\', label=\'Training Loss\') 17 plt.plot(epochs, val_loss, \'r\', label=\'Validation Loss\') 18 plt.title(\'Training and validation loss\') 19 plt.legend() 20 21 plt.show()

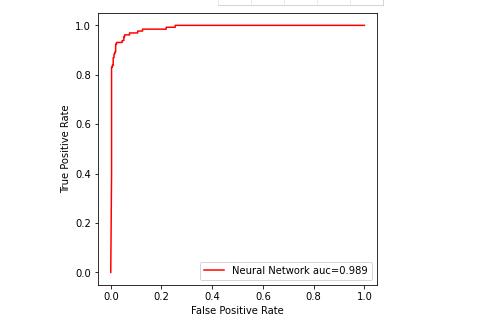
ROC曲线
1 yPreProb = model.predict_proba(test_x) 2 p1, p2, _ = metrics.roc_curve(test_y, yPreProb) 3 PBAUC = metrics.roc_auc_score(test_y, yPreProb) 4 5 plt.subplots(figsize=(5,5)) 6 plt.plot(p1, p2, color=\'r\', label="Neural Network auc={:.3f}".format(PBAUC)) 7 plt.xlabel("False Positive Rate") 8 plt.ylabel("True Positive Rate") 9 plt.legend(loc=4) 10 plt.show()
四、总结
机器学习对于人类来说是有益的技术。尽管机器学习仍有一些内容需要重新审视和研究,但不可否认,它使人们的工作和生活变得更好。虽然机器学习的概念很难理解,但随着时间的推移,专家可以用一种更简单的方式表达。机器学习如今仍处于开发阶段,专家需要更多的努力才能挖掘其所提供的更多功能。
以上是关于Python机器学习预测苹果酸甜度的主要内容,如果未能解决你的问题,请参考以下文章
《Python机器学习及实践》----良/恶性乳腺癌肿瘤预测
水果识别基于matlab PCA苹果酸甜度识别含Matlab源码 1634期
学习《Python机器学习—预测分析核心算法》高清中文版PDF+高清英文版PDF+源代码