数据并行与模型并行
Posted 吴建明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据并行与模型并行相关的知识,希望对你有一定的参考价值。
数据并行与模型并行
为了加快模型的训练,可以使用分布式计算的思路,把这个大批次分割为很多小批次,使用多个节点进行计算,在每个节点上计算一个小批次,对若干个节点的梯度进行汇总后再加权平均,最终求和就得到了最终的大批次的梯度结果。
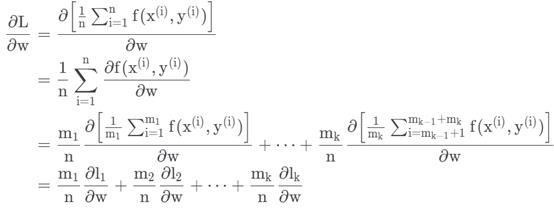
在上面这个公式中:w是模型的参数;
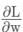 是采用batch_size = n计算得到的真实梯度。这个公式想要证明的是,可以在不同的节点上分别对n的一部分进行梯度的计算,将各个GPU的梯度进行汇总后的加权平均值。公式中最后一行中,在第k个节点有
是采用batch_size = n计算得到的真实梯度。这个公式想要证明的是,可以在不同的节点上分别对n的一部分进行梯度的计算,将各个GPU的梯度进行汇总后的加权平均值。公式中最后一行中,在第k个节点有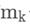 个数据,
个数据,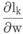 是该节点上计算得到梯度。
是该节点上计算得到梯度。
,n个样本数据被分拆到了多个节点上。
其中,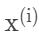 ,
,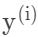 是样本数据i的特征和标签;对于样本数据i,f(,)是前向传播的损失函数。
是样本数据i的特征和标签;对于样本数据i,f(,)是前向传播的损失函数。
如果对每个节点上的数据量平分,有:
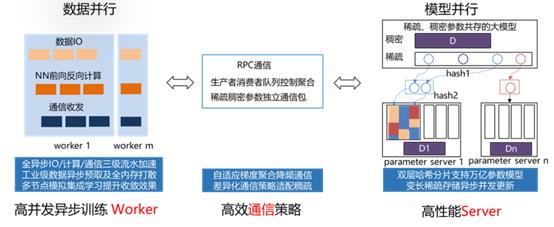
图1. 传统参数服务器工作流程
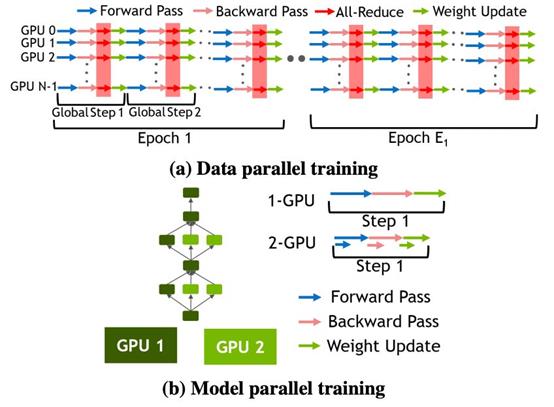
图 2. 不同的训练并行化策略,2(a) 展示了数据并行化训练,2(b) 展示了模型并行化训练
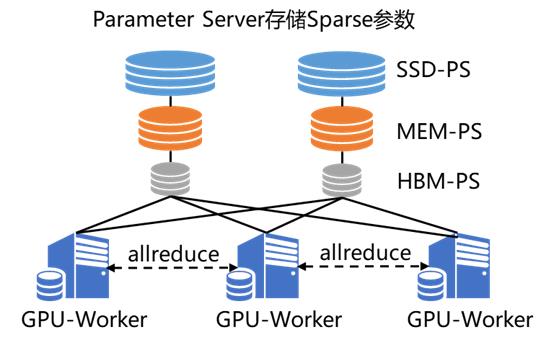
图3. 纯GPU参数服务器工作流程
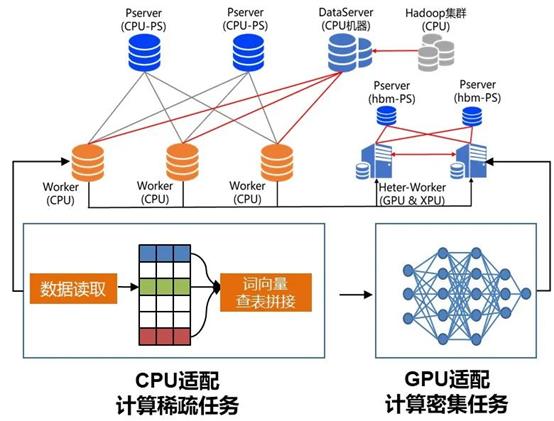
图4. 异构参数服务器示意图
以上是关于数据并行与模型并行的主要内容,如果未能解决你的问题,请参考以下文章
『AI原理解读』MindSpore1.2强大并行能力介绍与解读
『AI原理解读』MindSpore1.2强大并行能力介绍与解读