Pysyft学习笔记四:MINIST数据集下的联邦学习(并行训练与非并行训练)
Posted 一只特立独行的猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pysyft学习笔记四:MINIST数据集下的联邦学习(并行训练与非并行训练)相关的知识,希望对你有一定的参考价值。
目录
经过前面几篇笔记的学习,基本上已经知道了联邦学习的基本代码框架。联邦学习也有两种实现方式,一种是C/S架构,服务器整合模型,一种是P2P架构,不需要第三方。现在先实现C/S架构下的横向联邦学习模型。
大概处理过程如下:
1.数据预处理,得到data_loader
2.建立虚拟机,分配数据集
3.初始化模型
4.将模型发送给虚拟机
5.指导虚拟机训练
6.回收模型
熟悉了基本的处理流程以后,打算自己写一个用MINIST数据集的手写数字识别联邦学习模型。
手写数字识别模型(非并行训练)
概述图

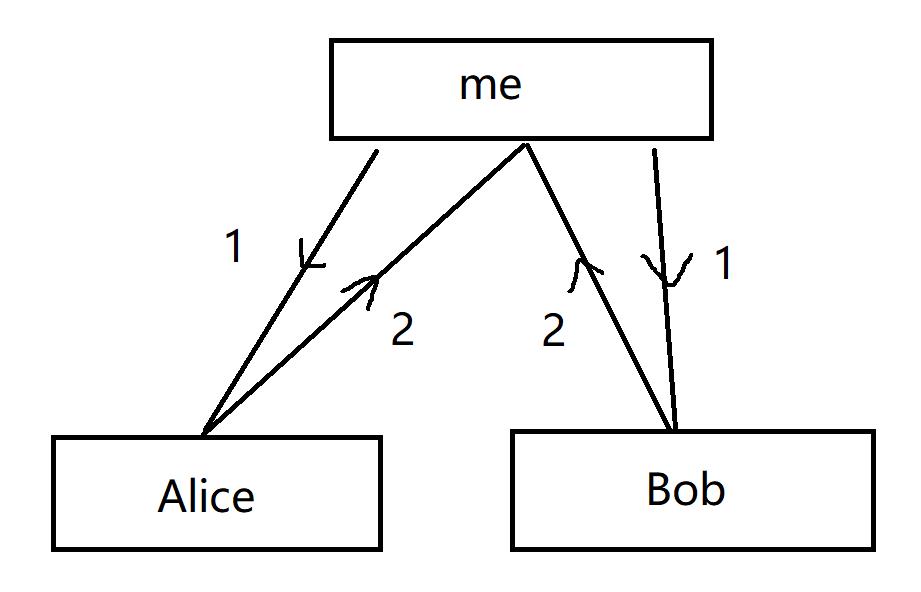
服务器先将model发送Alice,Alice利用本地数据进行训练以后,再将模型发送给Server,Server接受到模型后,将模型发送给Bob,Bob利用本地数据进行训练,训练完成后,交给Server,Server利用本地的测试数据对model进行评估,然后将这个模型分发给Alice和Bob。
但是这样训练的缺点非常明显:Bob可以对接受模型的参数进行推理,可能能得到Alice本地数据的部分特征,从而破坏了数据的隐私性。非并行训练,训练时间长,Bob的数据是后训练的,可能占总模型的大,而不能很好的利用到双方的数据。
目前在写训练代码时还遇到了一些困惑,写在了本文的最后面,欢迎各位大佬留言,万分感谢。
导入基本包
import torch
#用于构建NN
import torch.nn as nn
#需要用到这个库里面的激活函数
import torch.nn.functional as F
#用于构建优化器
import torch.optim as optim
#用于初始化数据
from torchvision import datasets, transforms
#用于分布式训练
import syft as sy
hook = sy.TorchHook(torch)
创建客户机
Bob = sy.VirtualWorker(hook,id='Bob')
Alice = sy.VirtualWorker(hook,id='Alice')
设置训练参数
class Arguments():
def __init__(self):
self.batch_size = 1
self.test_batch_size = 100
self.epochs = 3
self.lr = 0.01
self.momentum = 0.5
self.no_cuda = False
self.seed = 1
self.log_interval = 30
self.save_model = False
#实例化参数类
args = Arguments()
#判断是否使用GPu
use_cuda = not args.no_cuda and torch.cuda.is_available()
#固定化随机数种子,使得每次训练的随机数都是固定的
torch.manual_seed(args.seed)
device = torch.device('cuda' if use_cuda else 'cpu')
初始化数据集
#定义联邦训练数据集,定义转换器为 x=(x-mean)/标准差
fed_dataset = datasets.MNIST('data',download=True,train=True,
transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))]))
#定义数据加载器,shuffle是采用随机的方式抽取数据,顺便也把数据集定义在了客户端上
fed_loader = sy.FederatedDataLoader(federated_dataset=fed_dataset.federate((Alice,Bob)),batch_size=args.batch_size,shuffle=True)
#定义测试集
test_dataset = datasets.MNIST('data',download=True,train=False,
transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))]))
#定义测试集加载器
test_loader = torch.utils.data.DataLoader(test_dataset,batch_size=args.test_batch_size,shuffle=True)
搭建神经网络模型
#构建神经网络模型
class Net(nn.Module):
def __init__(self) -> None:
super(Net,self).__init__()
#输入维度为1,输出维度为20,卷积核大小为:5*5,步幅为1
self.conv1 = nn.Conv2d(1,20,5,1)
self.conv2 = nn.Conv2d(20,50,5,1)
self.fc1 = nn.Linear(4*4*50,500)
#最后映射到10维上
self.fc2 = nn.Linear(500,10)
def forward(self,x):
#print(x.shape)
x = F.relu(self.conv1(x))#28*28*1 -> 24*24*20
#print(x.shape)
#卷机核:2*2 步幅:2
x = F.max_pool2d(x,2,2)#24*24*20 -> 12*12*20
#print(x.shape)
x = F.relu(self.conv2(x))#12*12*20 -> 8*8*30
#print(x.shape)
x = F.max_pool2d(x,2,2)#8*8*30 -> 4*4*50
#print(x.shape)
x = x.view(-1,4*4*50)
x = F.relu(self.fc1(x))
x = self.fc2(x)
#使用logistic函数作为softmax进行激活吗就
return F.log_softmax(x, dim = 1)
定义训练与测试函数
def train(model:Net,fed_loader:sy.FederatedDataLoader,opt:optim.SGD,epoch):
model.train()
for batch_idx,(data,target) in enumerate(fed_loader):
#传递模型
model.send(data.location)
opt.zero_grad()
pred = model(data)
loss = F.nll_loss(pred,target)
loss.backward()
opt.step()
model.get()
if batch_idx % args.log_interval==0:
#获得loss
loss = loss.get()
print('Train Epoch : [ / (:.0f%)] \\tLoss: :.6f'.format(
epoch, batch_idx * args.batch_size, len(fed_loader) *
args.batch_size,
100.* batch_idx / len(fed_loader), loss.item()))
#定义测试函数
def test(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output=model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.argmax(1, keepdim=True)
correct+= pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\\nTest set : Average loss : :.4f, Accuracy: / ( :.0f%)\\n'.format(
test_loss, correct, len(test_loader.dataset),
100.* correct / len(test_loader.dataset)))
定义主函数
if __name__ == '__main__':
model = Net().to(device)
optimizer = optim.SGD(model.parameters(), lr = args.lr)
for epoch in range(1, args.epochs +1):
train(model, fed_loader, optimizer, epoch)
test(model, test_loader)
训练效果
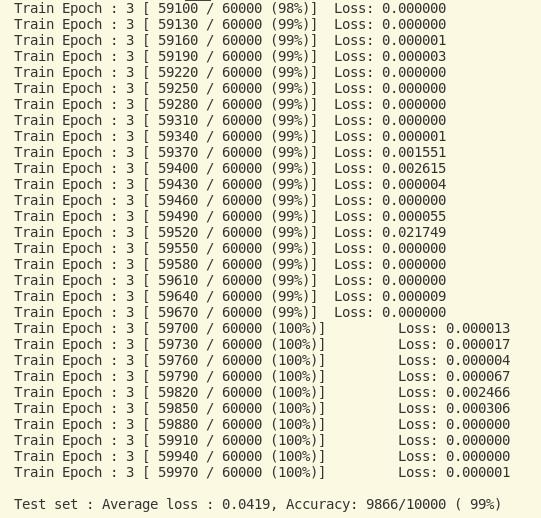 感觉误差还挺小,但是训练时间过长。
感觉误差还挺小,但是训练时间过长。
手写数字识别模型(并行训练)
概述图
导入必要的包
from imaplib import Time2Internaldate
import torch
import time
#用于构建NN
import torch.nn as nn
#需要用到这个库里面的激活函数
import torch.nn.functional as F
#用于构建优化器
import torch.optim as optim
#用于初始化数据
from torchvision import datasets, transforms
#用于分布式训练
import syft as sy
hook = sy.TorchHook(torch)
建立客户机
Bob = sy.VirtualWorker(hook,id='Bob')
Alice = sy.VirtualWorker(hook,id='Alice')
初始化训练参数
class Arguments():
def __init__(self):
self.batch_size = 1
self.test_batch_size = 100
self.epochs = 1
self.lr = 0.01
self.momentum = 0.5
self.seed = 1
self.log_interval = 1
self.save_model = True
#实例化参数类
args = Arguments()
#固定化随机数种子,使得每次训练的随机数都是固定的
torch.manual_seed(args.seed)
定义训练集与测试集
#定义联邦训练数据集,定义转换器为 x=(x-mean)/标准差
fed_dataset_Bob = datasets.MNIST('data',download=False,train=True,
transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))]))
#定义数据加载器,shuffle是采用随机的方式抽取数据
fed_loader_Bob = torch.utils.data.DataLoader(fed_dataset_Bob,batch_size=args.batch_size,shuffle=True)
#定义联邦训练数据集,定义转换器为 x=(x-mean)/标准差
fed_dataset_Alice = datasets.MNIST('data',download=False,train=True,
transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))]))
#定义数据加载器,shuffle是采用随机的方式抽取数据
fed_loader_Alice = torch.utils.data.DataLoader(fed_dataset_Alice,batch_size=args.batch_size,shuffle=True)
#定义测试集
test_dataset = datasets.MNIST('data',download=True,train=False,
transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,),(0.3081,))]))
#定义测试集加载器
test_loader = torch.utils.data.DataLoader(test_dataset,batch_size=args.test_batch_size,shuffle=True)
定义神经网络
#构建神经网络模型
class Net(nn.Module):
def __init__(self) -> None:
super(Net,self).__init__()
#输入维度为1,输出维度为20,卷积核大小为:5*5,步幅为1
self.conv1 = nn.Conv2d(1,20,5,1)
self.conv2 = nn.Conv2d(20,50,3,1)
self.fc1 = nn.Linear(800,500)
#最后映射到10维上
self.fc2 = nn.Linear(500,10)
def forward(self,x):
#print(x.shape)
x = F.relu(self.conv1(x))#28*28*1 -> 12*12*20
#卷机核:2*2 步幅:2
x = F.max_pool2d(x,2,2)
#print(x.shape)
x = F.relu(self.conv2(x))
#print(x.shape)
x = F.max_pool2d(x,2,2)
#print(x.shape)
x = x.view(-1,4*4*50)
x = F.relu(self.fc1(x))
x = self.fc2(x)
#使用logistic函数作为softmax进行激活吗就
return F.log_softmax(x, dim = 1)
使用Fed_avg算法整合模型
def fedavg_updata_weight(model:Net, Alice_model:Net, Bob_model:Net, num:int):
"""
训练中需要修改的参数如下,对以下参数进行avg
conv1.weight
conv1.bias
conv2.weight
conv2.bias
fc1.weight
fc1.bias
fc2.weight
fc2.bias
"""
model.conv1.weight.set_((Bob_model.conv1.weight.data+Alice_model.conv1.weight.data)/num)
model.conv1.bias.set_((Bob_model.conv1.bias.data+Alice_model.conv1.bias.data)/num)
model.conv2.weight.set_((Bob_model.conv2.weight.data+Alice_model.conv2.weight.data)/num)
model.conv2.bias.set_((Bob_model.conv2.bias.data+Alice_model.conv2.bias.data)/num)
model.fc1.weight.set_((Bob_model.fc1.weight.data+Alice_model.fc1.weight.data)/num)
model.fc1.bias.set_((Bob_model.fc1.bias.data+Alice_model.fc1.bias.data)/num)
model.fc2.weight.set_((Bob_model.fc2.weight.data+Alice_model.fc2.weight.data)/num)
model.fc2.bias.set_((Bob_model.fc2.bias.data+Alice_model.fc2.bias.data)/num)
定义训练
def train(model:Net,fed_loader:torch.utils.data.DataLoader):
Bob_model = Net()
Alice_model = Net()
#定义Bob的优化器
Bob_opt = optim.SGD(Bob_model.parameters(), lr = args.lr)
#定义Alice的优化器
Alice_opt = optim.SGD(Alice_model.parameters(), lr = args.lr)
model.train()
Bob_model.train()
Alice_model.train()
Bob_model.send(Bob)
Alice_model.send(Alice)
for epoch in range(1, args.epochs +1):
#传递模型
Alice_loss = 0
Bob_loss = 0
#模拟Bob训练数据
for epoch_ind, (data, target) in enumerate(fed_loader):
data = data.send(Bob)
target = target.send(Bob)
Bob_opt.zero_grad()
pred = Bob_model(data)
Bob_loss = F.nll_loss(pred,target)
Bob_loss.backward()
Bob_opt.step()
if(epoch_ind%50==0):
print("There is epoch: epoch_ind: in Bob loss::.6f".format(epoch,epoch_ind,Bob_loss.get().data.item()))
#模拟Alice训练模型
for epoch_ind, (data, target) in enumerate(fed_loader):
data = data.send(Alice)
target = target.send(Alice)
Alice_opt.zero_grad()
pred = Alice_model(data)
Alice_loss = F.nll_loss(pred,target)
Alice_loss.backward()
Alice_opt.step()
if(epoch_ind%50==0):
print("There is epoch: epoch_ind: in Alice loss::.6f".format(epoch,epoch_ind,Alice_loss.get().data.item()))
with torch.no_grad():
Bob_model.get()
Alice_model.get()
#更新权重
fedavg_updata_weight(model,Alice_model,Bob_model,2)
if epoch % args.log_interval==0:
#获得loss
#模型的loss
# pred = model(fed_loader)
# Loss = F.nll_loss(pred,target)
print("Bob in train:")
test(Bob_model,test_loader)
print(以上是关于Pysyft学习笔记四:MINIST数据集下的联邦学习(并行训练与非并行训练)的主要内容,如果未能解决你的问题,请参考以下文章