地理探测器简介(R语言)
Posted 当时明月在曾照彩云归
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了地理探测器简介(R语言)相关的知识,希望对你有一定的参考价值。
地理探测器
1. 地理探测器原理
空间分异性是地理现象的基本特点之一。地理探测器是探测和利用空间分异性的工具。地理探测器包括4个探测器。
分异及因子探测:探测Y的空间分异性;以及探测某因子X多大程度上解释了属性Y的空间分异(图1)。用q值度量
,表达式为:
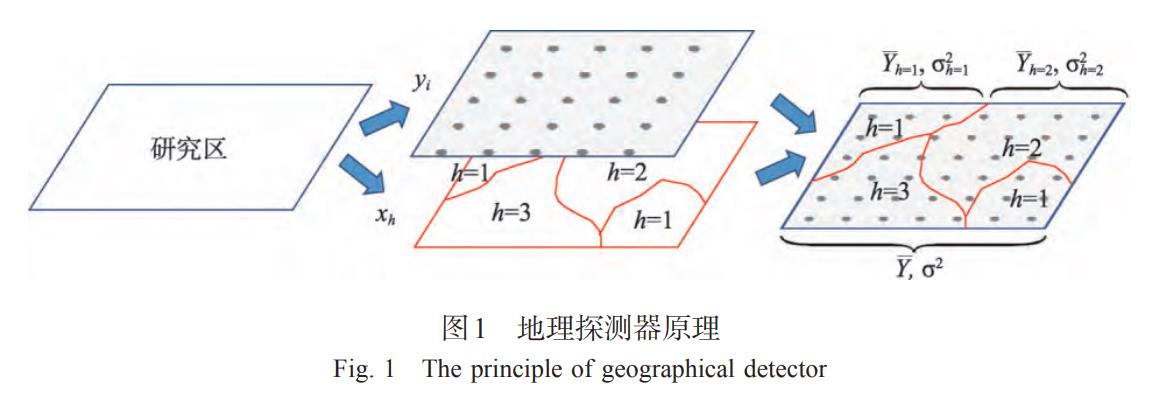
式中:h = 1, …, L为变量Y或因子X的分层 (Strata),即分类或分区;Nh和N分别为层h和全区的单元数; $ \\sigma_h^2$ 和 $ \\sigma^2$ 分别是层h和全区的Y值的方差。SSW和SST分别为层内方差之和 (Within Sum of Squares) 和全区总方差 (Total Sum of Squares)。q的值域为[0,1],值越大说明Y的空间分异性越明显;如果分层是由自变量X生成的,则q值越大表示自变量X对属性Y的解释力越强,反之则越弱。极端情况下,q值为1表明因子X完全控制了Y的空间分布,q值为0则表明因子X与Y没有任何关系,q值表示X解释了100×q%的Y。
q值的一个简单变换满足非中心F分布:
式中:\\(\\lambda\\)为非中心参数;\\(\\overline Y_h\\) 为层h的均值。根据式(3),可以查表或者使用地理探测器软件来检验q值是否显著。
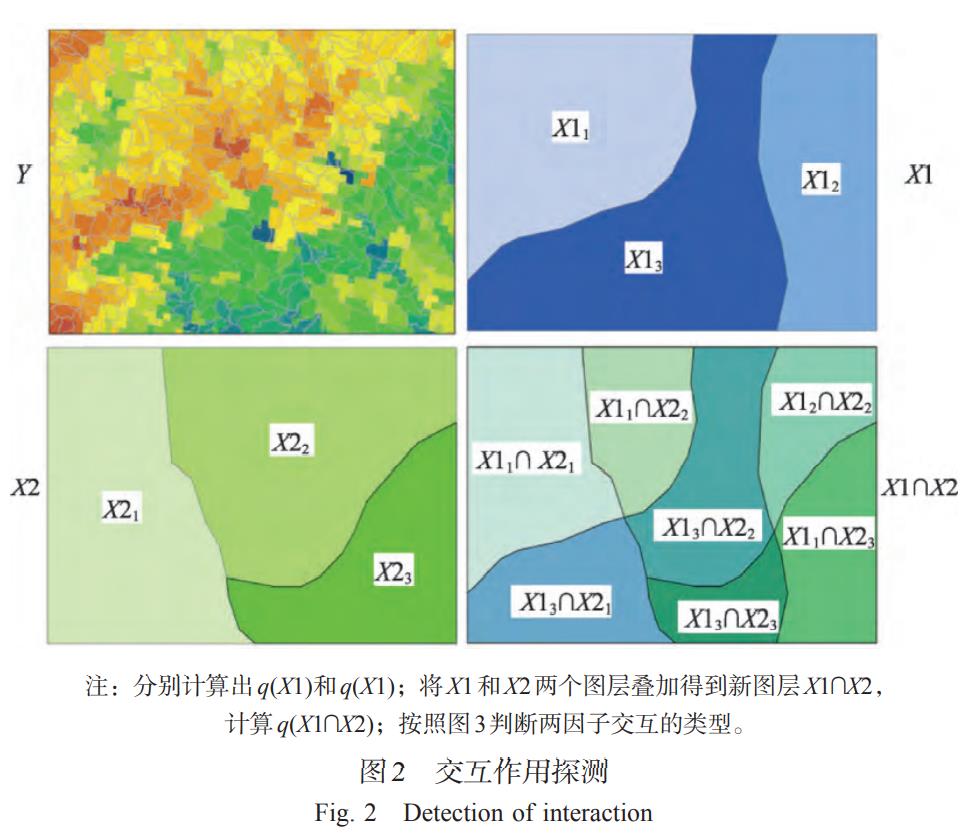
交互作用探测:识别不同风险因子Xs之间的交互作用,即评估因子X1和X2共同作用时是否会增加或减弱对因变量 Y 的解释力,或这些因子对Y的影响是相互独立的。评估的方法是首先分别计算两种因子 X1 和 X2 对 Y 的q 值 : q(X1) 和 q(X2),并且计算它们交互(叠加变量 X1 和 X2 两个图层相切所形成的新的多边形分布,图2)时的q值: q(X1 ∩ X2) ,并对q(X1)、q(X2)与q(X1 ∩ X2)进行比较。两个因子之间的关系可分为以下几类(图3);

风险区探测:用于判断两个子区域间的属性均值是否有显著的差别,用t统计量来检验:
式中: \\(\\overline Y _{h=1}\\) 表示子区域 h内的属性均值,如发病率或流行率;\\(n_h\\)为子区域h内样本数量,Var表示方差。统计量t近似地服从Student\'s t分布,其中自由度的计算方法为:
零假设\\(H_0\\):\\(\\overline Y_{h=1} = \\overline Y_{h=2}\\) ,如果在置信水平α下拒绝\\(H_0\\),则认为两个子区域间的属性均值存在着明显的差异。
生态探测:用于比较两因子X1和X2对属性Y的空间分布的影响是否有显著的差异,以F统计量来衡量:
式中:\\(N_{X1}\\)及\\(N_{X2}\\)分别表示两个因子X1和X2的样本量;\\(SSW_{X1}\\)和\\(SSW_{X2}\\)分别表示由X1和X2形成的分层的层内方差之和;L1和L2分别表示变量X1和X2分层数目。其中零假设\\(H_0\\):\\(SSW_{X1}=SSW_{X2}\\)。如果在α的显著性水平上拒绝\\(H_0\\),这表明两因子X1和X2对属性Y的空间分布的影响存在着显著的差异。
2. 地理探测器(R)
GeoDetector包包括五个功能:
- factor_detector,
- interaction_detector,
- risk_detector,ecological_detector
- geodetector
前四个功能实现因子检测器,交互检测器,风险检测器和生态检测器的算法,可以使用表数据计算,例如,可以计算 CSV格式(表1)。最后一个函数GeoDetector是一种辅助功能,可用于实现Shapefile格式映射数据的计算(图2)。
| incidence | watershed | soiltype | elevation |
|---|---|---|---|
| 7.20 | 2 | 3 | 6 |
| 7.01 | 2 | 3 | 6 |
| 6.79 | 2 | 3 | 6 |
| 6.73 | 4 | 3 | 6 |
| 6.77 | 4 | 3 | 1 |
| 6.74 | 4 | 3 | 6 |
GeoDetector包依赖于以下包:RGEO,SP,MapTools和RGDAL,应提前安装。
作为一个演示,提供了神经管畸形出生缺陷(NTDs)的发生Y和疑似村庄的环境风险因子或其代理变量Xs,包括健康效果GIS层和环境因子GIS图层,“海拔”,“土壤类型”的数据,以及 “流域”。
下载geodetector包:
install.packages("geodetector")
加载包:
library(geodetector)
读取数据:
data(CollectData)
class(CollectData)
\'data.frame\'
names(CollectData)
- \'incidence\'
- \'watershed\'
- \'soiltype\'
- \'elevation\'
2.1 分异及因子探测
因子检测器q-statistic测量变量Y的空间分异性(SSH),或者决定了某因子X多大程度上解释了属性Y的空间分异。
Factor_Detector实现因子检测器的功能。 在以下演示中,第一个参数“incidence”表示解释的变量,第二个参数“elevation”表示解释变量,第三个参数“CollectData”表示数据集。
该函数的输出包括Q统计和相应的P值。
factor_detector("incidence","elevation",CollectData)
A data.frame: 1 × 2 q-statistic p-value <dbl> <dbl> elevation 0.6067087 0.04080407
另一种方式也可用于实现函数,其中输入参数可以是每个字段的索引。 例如,在以下演示中,第一个参数“1”表示数据集的第一列中的解释变量,第二个参数“3”表示数据集的第三列中的解释变量。
factor_detector(1,3, CollectData)
A data.frame: 1 × 2 q-statistic p-value <dbl> <dbl> soiltype 0.3857168 0.3632363
如果有多个变量,则该函数可以用作以下内容。 其中, c(“soiltype”,“watershed”,“elevation”)或c(2,3,4)是用于列2,3,4中的解释变量的场名和索引。
factor_detector ("incidence",c("soiltype","watershed","elevation"),CollectData)
A data.frame: 1 × 2 q-statistic p-value <dbl> <dbl> soiltype 0.3857168 0.3632363 A data.frame: 1 × 2 q-statistic p-value <dbl> <dbl> watershed 0.6377737 0.0001169914 A data.frame: 1 × 2 q-statistic p-value <dbl> <dbl> elevation 0.6067087 0.04080407
factor_detector (1,c(2,3,4), CollectData)
A data.frame: 1 × 2 q-statistic p-value <dbl> <dbl> watershed 0.6377737 0.0001169914 A data.frame: 1 × 2 q-statistic p-value <dbl> <dbl> soiltype 0.3857168 0.3632363 A data.frame: 1 × 2 q-statistic p-value <dbl> <dbl> elevation 0.6067087 0.04080407
2.2 交互探测
相互作用检测器显示风险因素X1和X2(或其他X)是否对疾病Y具有交互影响。
函数Interaction_Detector实现交互探测器。 在下面的演示中,第一个参数“incidence”表示解释的变量,第二个参数c(“soiltype”,“watershed”,“elevation”) 表示解释变量,第三个参数“CollectData”表示数据集。
interaction_detector("incidence",c("soiltype","watershed","elevation"),CollectData)
| soiltype | watershed | 0.735680548139531 |
| soiltype | soiltype | 0.385716842809428 |
| watershed | watershed | 0.637773670070423 |
| soiltype | elevation | 0.663523698335635 |
| soiltype | soiltype | 0.385716842809428 |
| elevation | elevation | 0.606708709727727 |
| watershed | elevation | 0.71359677853471 |
| watershed | watershed | 0.637773670070423 |
| elevation | elevation | 0.606708709727727 |
2.3 风险探测
风险检测器计算每个解释变量(x)的每个层中的平均值,并且如果两个地层之间存在差异,则会呈体现出来。
函数Risk_Detector实现风险探测器。 在下面的演示中,第一个参数 “incidence”表示解释的变量,第二个参数 “soiltype”表示解释变量,第三参数“collectData”表示数据集。
在该函数中,每个变量的结果信息以两部分呈现。
第一部分给出了解释变量的每个层中解释变量的平均值。
第二部分测试两个地层的装置之间是否存在显着差异; 如果存在显着差异(T测试具有0.05的显着水平),相应的值是“TRUE”,否则它是“FALSE”。
risk_detector("incidence","soiltype",CollectData)
- $`Risk Detector`
A data.frame: 5 × 2 soiltype Mean of explained variable <int> <dbl> 1 6.340000 2 6.687500 3 6.583279 4 5.843810 5 6.347073 - $`Significance t-test:0.05`
A data.frame: 5 × 5 1 2 3 4 5 <chr> <chr> <chr> <chr> <chr> 1 FALSE TRUE TRUE TRUE FALSE 2 TRUE FALSE FALSE TRUE TRUE 3 TRUE FALSE FALSE TRUE TRUE 4 TRUE TRUE TRUE FALSE TRUE 5 FALSE TRUE TRUE TRUE FALSE
另一种方式也可用于实现函数,其中输入参数可以是每个字段的索引。 例如,在以下演示中,第一个参数“1”表示数据集的第一列中的解释变量,第二个参数“2”表示数据集的第二列中的解释变量。
risk_detector(1,2, CollectData)
- $`Risk Detector`
A data.frame: 9 × 2 watershed Mean of explained variable <int> <dbl> 1 6.167813 2 6.813103 3 6.474231 4 6.728000 5 5.910000 6 5.845714 7 6.494167 8 6.360769 9 6.579231 - $`Significance t-test:0.05`
A data.frame: 9 × 9 1 2 3 4 5 6 7 8 9 <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> 1 FALSE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE 2 TRUE FALSE TRUE FALSE TRUE TRUE TRUE TRUE TRUE 3 TRUE TRUE FALSE TRUE TRUE TRUE FALSE FALSE FALSE 4 TRUE FALSE TRUE FALSE TRUE TRUE TRUE TRUE TRUE 5 TRUE TRUE TRUE TRUE FALSE FALSE TRUE TRUE TRUE 6 TRUE TRUE TRUE TRUE FALSE FALSE TRUE TRUE TRUE 7 TRUE TRUE FALSE TRUE TRUE TRUE FALSE FALSE FALSE 8 TRUE TRUE FALSE TRUE TRUE TRUE FALSE FALSE TRUE 9 TRUE TRUE FALSE TRUE TRUE TRUE FALSE TRUE FALSE
如果有多个变量,则该函数可以用作以下内容。 其中,c(“soiltype”,“watershed”,“elevation”)和(c2,3,4)是用于解释变量的场名和索引。
risk_detector("incidence",c("soiltype","watershed","elevation"),CollectData)
- $`Risk Detector`
A data.frame: 5 × 2 soiltype Mean of explained variable <int> <dbl> 1 6.340000 2 6.687500 3 6.583279 4 5.843810 5 6.347073 - $`Significance t-test:0.05`
A data.frame: 5 × 5 1 2 3 4 5 <chr> <chr> <chr> <chr> <chr> 1 FALSE TRUE TRUE TRUE FALSE 2 TRUE FALSE FALSE TRUE TRUE 3 TRUE FALSE FALSE TRUE TRUE 4 TRUE TRUE TRUE FALSE TRUE 5 FALSE TRUE TRUE TRUE FALSE
- $`Risk Detector`
A data.frame: 9 × 2 watershed Mean of explained variable <int> <dbl> 1 6.167813 2 6.813103 3 6.474231 4 6.728000 5 5.910000 6 5.845714 7 6.494167 8 6.360769 9 6.579231 - $`Significance t-test:0.05`
A data.frame: 9 × 9 1 2 3 4 5 6 7 8 9 <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> 1 FALSE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE 2 TRUE FALSE TRUE FALSE TRUE TRUE TRUE TRUE TRUE 3 TRUE TRUE FALSE TRUE TRUE TRUE FALSE FALSE FALSE 4 TRUE FALSE TRUE FALSE TRUE TRUE TRUE TRUE TRUE 5 TRUE TRUE TRUE TRUE FALSE FALSE TRUE TRUE TRUE 6 TRUE TRUE TRUE TRUE FALSE FALSE TRUE TRUE TRUE 7 TRUE TRUE FALSE TRUE TRUE TRUE FALSE FALSE FALSE 8 TRUE TRUE FALSE TRUE TRUE TRUE FALSE FALSE TRUE 9 TRUE TRUE FALSE TRUE TRUE TRUE FALSE TRUE FALSE
- $`Risk Detector`
A data.frame: 7 × 2 elevation Mean of explained variable <int> <dbl> 1 6.455882 2 6.171111 3 6.258108 4 6.621364 5 5.908889 6 6.888636 7 5.790000 - $`Significance t-test:0.05`
A data.frame: 7 × 7 1 2 3 4 5 6 7 <chr> <chr> <chr> <chr> <chr> <chr> <chr> 1 FALSE TRUE TRUE TRUE TRUE TRUE TRUE 2 TRUE FALSE FALSE TRUE TRUE TRUE TRUE 3 TRUE FALSE FALSE TRUE TRUE TRUE TRUE 4 TRUE TRUE TRUE FALSE TRUE TRUE TRUE 5 TRUE TRUE TRUE TRUE FALSE TRUE TRUE 6 TRUE TRUE TRUE TRUE TRUE FALSE TRUE 7 TRUE TRUE TRUE TRUE TRUE TRUE FALSE
risk_detector(1,c(2,3,4), CollectData)
- $`Risk Detector`
A data.frame: 9 × 2 watershed Mean of explained variable <int> <dbl> 1 6.167813 2 6.813103 3 6.474231 4 6.728000 5 5.910000 6 5.845714 7 6.494167 8 6.360769 9 6.579231 - $`Significance t-test:0.05`
A data.frame: 9 × 9 1 2 3 4 5 6 7 8 9 <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> 1 FALSE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE 2 TRUE FALSE TRUE FALSE TRUE TRUE TRUE TRUE TRUE 3 TRUE TRUE FALSE TRUE TRUE TRUE FALSE FALSE FALSE 4 TRUE FALSE TRUE FALSE TRUE TRUE TRUE TRUE TRUE 5 TRUE TRUE TRUE TRUE FALSE FALSE TRUE TRUE TRUE 6 TRUE TRUE TRUE TRUE FALSE FALSE TRUE TRUE TRUE 7 TRUE TRUE FALSE TRUE TRUE TRUE FALSE FALSE FALSE 8 TRUE TRUE FALSE TRUE TRUE TRUE FALSE FALSE TRUE 9 TRUE TRUE FALSE TRUE TRUE TRUE FALSE TRUE FALSE
- $`Risk Detector`
A data.frame: 5 × 2 soiltype Mean of explained variable <int> <dbl> 1 6.340000 2 6.687500 3 6.583279 4 5.843810 5 6.347073 - $`Significance t-test:0.05`
A data.frame: 5 × 5 1 2 3 4 5 <chr> <chr> <chr> <chr> <chr> 1 FALSE TRUE TRUE TRUE FALSE 2 TRUE FALSE FALSE TRUE TRUE 3 TRUE FALSE FALSE TRUE TRUE 4 TRUE TRUE TRUE FALSE TRUE 5 FALSE TRUE TRUE TRUE FALSE
- $`Risk Detector`
A data.frame: 7 × 2 elevation Mean of explained variable <int> <dbl> 1 6.455882 2 6.171111 3 6.258108 4 6.621364 5 5.908889 6 6.888636 7 5.790000 - $`Significance t-test:0.05`
A data.frame: 7 × 7 1 2 3 4 5 6 7 <chr> <chr> <chr> <chr> <chr> <chr> <chr> 1 FALSE TRUE TRUE TRUE TRUE TRUE TRUE 2 TRUE FALSE FALSE TRUE TRUE TRUE TRUE 3 TRUE FALSE FALSE TRUE TRUE TRUE TRUE 4 TRUE TRUE TRUE FALSE TRUE TRUE TRUE 5 TRUE TRUE TRUE TRUE FALSE TRUE TRUE 6 TRUE TRUE TRUE TRUE TRUE FALSE TRUE 7 TRUE TRUE TRUE TRUE TRUE TRUE FALSE
2.4 生态探测
生态检测器测试了两个风险因素x1〜x2之间是否存在显着差异。
函数Ecological_Detector实现生态探测器。 在以下演示中,第一个参数“incidence”表示解释的变量,第二个参数c(“soiltype”,“watershed”)表示解释变量,第三个参数“collectData”表示数据集。 在该功能中,F统计用于测试差异,使用0.05的显着水平。
ecological_detector("incidence",c("soiltype","watershed"),CollectData)
$Significance.F-test:0.05 =
| soiltype | watershed | |
|---|---|---|
| <chr> | <chr> | |
| soiltype | FALSE | TRUE |
| watershed | TRUE | FALSE |
如果有两个以上的变量,则该函数可以用作以下内容,其中,c("soiltype","watershed","elevation")是用于解释变量的场的场名称。
ecological_detector("incidence",c("soiltype","watershed","elevation"),CollectData)
$Significance.F-test:0.05 =
| soiltype | watershed | elevation | |
|---|---|---|---|
| <chr> | <chr> | <chr> | |
| soiltype | FALSE | TRUE | TRUE |
| watershed | TRUE | FALSE | FALSE |
| elevation | TRUE | FALSE | FALSE |
2.5 将数据从地图转换为表格格式
如果输入数据处于表格格式,则可以直接用作上述功能中的输入参数。 但是,如果输入数据以ShapeFeile格式映射,则名为GeoDetector的函数可用于从Shapefile Map转换为表格式,然后可以使用上述功能。 请注意,这些Shapefile层应具有相同的投影坐标系。
加载MapTools包:
library(sp)
library(rgeos)
library(maptools)
rgeos version: 0.5-5, (SVN revision 640)
GEOS runtime version: 3.8.0-CAPI-1.13.1
Linking to sp version: 1.4-5
Polygon checking: TRUE
Checking rgeos availability: TRUE
读取数据:
data(DiseaseData_shp)
data(SoilType_shp)
data(Watershed_shp)
data(Elevation_shp)
在下面的演示中,第一个参数“disexicata_shp”表示 shape file数据存储解释的变量,第二个参数c(sallype_shp,watershed_shp,expation_shp)表示 shape file数据存储解释变量,以及第三个参数c(‘incidence’, ‘soiltype’, ‘watershed’, ‘elevation’)表示分别用于解释的变量和解释变量的实地名称。
CollectData2 <- maps2dataframe(DiseaseData_shp,c(SoilType_shp, Watershed_shp,
Elevation_shp),namescolomn= c(\'incidence\',
\'soiltype\', \'watershed\', \'elevation\'))
head(CollectData2)
| incidence | soiltype | watershed | elevation | |
|---|---|---|---|---|
| <dbl> | <int> | <int> | <int> | |
| 1 | 5.94 | 5 | 5 | 5 |
| 2 | 5.87 | 4 | 5 | 5 |
| 3 | 5.92 | 4 | 5 | 5 |
| 4 | 6.32 | 1 | 7 | 1 |
| 5 | 6.49 | 3 | 2 | 4 |
| 6 | 6.46 | 3 | 2 | 4 |
使用从Maps2dataframe函数计算的数据集 CollectData,可以计算以下功能。
风险探测器:
risk_detector("incidence","soiltype",CollectData2)
- $`Risk Detector`
A data.frame: 5 × 2 soiltype Mean of explained variable <int> <dbl> 1 6.340000 2 6.687500 3 6.583279 4 5.843810 5 6.347073 - $`Significance t-test:0.05`
A data.frame: 5 × 5 1 2 3 4 5 <chr> <chr> <chr> <chr> <chr> 1 FALSE TRUE TRUE TRUE FALSE 2 TRUE FALSE FALSE TRUE TRUE 3 TRUE FALSE FALSE TRUE TRUE 4 TRUE TRUE TRUE FALSE TRUE 5 FALSE TRUE TRUE TRUE FALSE
risk_detector("incidence",c("soiltype"),CollectData2)
- $`Risk Detector`
A data.frame: 5 × 2 soiltype Mean of explained variable <int> <dbl> 1 6.340000 2 6.687500 3 6.583279 4 5.843810 5 6.347073 - $`Significance t-test:0.05`
A data.frame: 5 × 5 1 2 3 4 5 <chr> <chr> <chr> <chr> <chr> 1 FALSE TRUE TRUE TRUE FALSE 2 TRUE FALSE FALSE TRUE TRUE 3 TRUE FALSE FALSE TRUE TRUE 4 TRUE TRUE TRUE FALSE TRUE 5 FALSE TRUE TRUE TRUE FALSE
risk_detector(1,2,CollectData2)
- $`Risk Detector`
A data.frame: 5 × 2 soiltype Mean of explained variable <int> <dbl> 1 6.340000 2 6.687500 3 6.583279 4 5.843810 5 6.347073 - $`Significance t-test:0.05`
A data.frame: 5 × 5 1 2 3 4 5 <chr> <chr> <chr> <chr> <chr> 1 FALSE TRUE TRUE TRUE FALSE 2 TRUE FALSE FALSE TRUE TRUE 3 TRUE FALSE FALSE TRUE TRUE 4 TRUE TRUE TRUE FALSE TRUE 5 FALSE TRUE TRUE TRUE FALSE
risk_detector(1,c(2,3,4),CollectData2)
- $`Risk Detector`
A data.frame: 5 × 2 soiltype Mean of explained variable <int> <dbl> 1 6.340000 2 6.687500 3 6.583279 4 5.843810 5 6.347073 - $`Significance t-test:0.05`
A data.frame: 5 × 5 1 2 3 4 5 <chr> <chr> <chr> <chr> <chr> 1 FALSE TRUE TRUE TRUE FALSE 2 TRUE FALSE FALSE TRUE TRUE 3 TRUE FALSE FALSE TRUE TRUE 4 TRUE TRUE TRUE FALSE TRUE 5 FALSE TRUE TRUE TRUE FALSE
- $`Risk Detector`
A data.frame: 9 × 2 watershed Mean of explained variable <int> <dbl> 1 6.167813 2 6.813103 3 6.474231 4 6.728000 5 5.910000 6 5.845714 7 6.494167 8 6.360769 9 6.579231 - $`Significance t-test:0.05`
A data.frame: 9 × 9 1 2 3 4 5 6 7 8 9 <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> 1 FALSE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE 2 TRUE FALSE TRUE FALSE TRUE TRUE TRUE TRUE TRUE 3 TRUE TRUE FALSE TRUE TRUE TRUE FALSE FALSE FALSE 4 TRUE FALSE TRUE FALSE TRUE TRUE TRUE TRUE TRUE 5 TRUE TRUE TRUE TRUE FALSE FALSE TRUE TRUE TRUE 6 TRUE TRUE TRUE TRUE FALSE FALSE TRUE TRUE TRUE 7 TRUE TRUE FALSE TRUE TRUE TRUE FALSE FALSE FALSE 8 TRUE TRUE FALSE TRUE TRUE TRUE FALSE FALSE TRUE 9 TRUE TRUE FALSE TRUE TRUE TRUE FALSE TRUE FALSE
- $`Risk Detector`
A data.frame: 7 × 2 elevation Mean of explained variable <int> <dbl> 1 6.455882 2 6.171111 3 6.258108 4 6.621364 5 5.908889 6 6.888636 7 5.790000 - $`Significance t-test:0.05`
A data.frame: 7 × 7 1 2 3 4 5 6 7 <chr> <chr> <chr> <chr> <chr> <chr> <chr> 1 FALSE TRUE TRUE TRUE TRUE TRUE TRUE 2 TRUE FALSE FALSE TRUE TRUE TRUE TRUE 3 TRUE FALSE FALSE TRUE TRUE TRUE TRUE 4 TRUE TRUE TRUE FALSE TRUE TRUE TRUE 5 TRUE TRUE TRUE TRUE FALSE TRUE TRUE 6 TRUE TRUE TRUE TRUE TRUE FALSE TRUE 7 TRUE TRUE TRUE TRUE TRUE TRUE FALSE
因子探测器:
factor_detector("incidence","elevation",CollectData2)
A data.frame: 1 × 2 q-statistic p-value <dbl> <dbl> elevation 0.6067087 0.04080407
factor_detector ("incidence",c("elevation","watershed"),CollectData2)
A data.frame: 1 × 2 q-statistic p-value <dbl> <dbl> elevation 0.6067087 0.04080407 A data.frame: 1 × 2 q-statistic p-value <dbl> <dbl> watershed 0.6377737 0.0001169914
factor_detector(1,3,CollectData2)
A data.frame: 1 × 2 q-statistic p-value <dbl> <dbl> watershed 0.6377737 0.0001169914
factor_detector (1,c(2,3,4),CollectData2)
A data.frame: 1 × 2 q-statistic p-value <dbl> <dbl> soiltype 0.3857168 0.3632363 A data.frame: 1 × 2 q-statistic p-value <dbl> <dbl> watershed 0.6377737 0.0001169914 A data.frame: 1 × 2 q-statistic p-value <dbl> <dbl> elevation 0.6067087 0.04080407
生态探测器:
ecological_detector("incidence",c("soiltype","watershed"),CollectData2)
$Significance.F-test:0.05 =
| soiltype | watershed | |
|---|---|---|
| <chr> | <chr> | |
| soiltype | FALSE | TRUE |
| watershed | TRUE | FALSE |
ecological_detector("incidence",c("soiltype","watershed","elevation"),CollectData2)
$Significance.F-test:0.05 =
| soiltype | watershed | elevation | |
|---|---|---|---|
| <chr> | <chr> | <chr> | |
| soiltype | FALSE | TRUE | TRUE |
| watershed | TRUE | FALSE | FALSE |
| elevation | TRUE | FALSE | FALSE |
interaction_detector("incidence",c("soiltype","watershed"),CollectData2)
| soiltype | watershed | 0.735680548139531 |
| soiltype | soiltype | 0.385716842809428 |
| watershed | watershed | 0.637773670070423 |
interaction_detector("incidence",c("soiltype","watershed","elevation"),CollectData2)
| soiltype | watershed | 0.735680548139531 |
| soiltype | soiltype | 0.385716842809428 |
| watershed | watershed | 0.637773670070423 |
| soiltype | elevation | 0.663523698335635 |
| soiltype | soiltype | 0.385716842809428 |
| elevation | elevation | 0.606708709727727 |
| watershed | elevation | 0.71359677853471 |
| watershed | watershed | 0.637773670070423 |
| elevation | elevation | 0.606708709727727 |
2.6 输出
因子检测器函数或风险检测器函数的结果可以保存为一个CSV文件,例如:
Result_1 <- factor_detector ("incidence",c("soiltype","watershed", "elevation"),CollectData)
write.csv(Result_1 [[1]],\'./Geodetector_R/output_factor_detector_soiltype.csv\')
write.csv(Result_1 [[2]],\'./Geodetector_R/output_factor_detector_watershed.csv\')
write.csv(Result_1 [[3]],\'./Geodetector_R/output_factor_detector_elevation.csv\')
Result_2 <- risk_detector("incidence",c("soiltype","watershed"),CollectData)
write.csv(Result_2 [[1]][1],\'./Geodetector_R/output_risk_detector_soiltype_Mean.csv\')
write.csv(Result_2 [[1]][2],\'./Geodetector_R/output_risk_detector_soiltype_Significance.csv\')
write.csv(Result_2 [[2]][1],\'./Geodetector_R/output_risk_detector_watershed_Mean.csv\')
write.csv(Result_2 [[2]][2],\'./Geodetector_R/output_risk_detector_watershed_Significance.csv\')
交互探测器函数或生态检测器功能的结果也可以保存为CSV文件,例如:
Result_3 <- interaction_detector("incidence",c("soiltype","watershed","elevation"),CollectData)
write.csv(Result_3,\'./Geodetector_R/output_interaction_detector.csv\')
Result_4 <- ecological_detector("incidence",c("soiltype","watershed"),CollectData)
write.csv(Result_4,\'./Geodetector_R/output_ecological_detector.csv\')
3. 资料参考:
A tutorial for the geodetector R package (Chengdong Xu, Yue Hou, Jinfeng Wang, Qian Yin (IGSNRR, CAS))
地理探测器:原理与展望 (王劲峰, 徐成东)
以上是关于地理探测器简介(R语言)的主要内容,如果未能解决你的问题,请参考以下文章
R语言distRhumb函数计算距离实战(两个地理点之间的Rhumb距离)