sklearn中的tf-idf计算公式详解
Posted Leonida
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sklearn中的tf-idf计算公式详解相关的知识,希望对你有一定的参考价值。
深入理解
tf-idf矢量化算法
TF-IDF是Term Frequency Inverse Document Frequency的缩写,是一个将文本转换为数字表示的常用算法,是词袋法的典型代表,常用于信息检索和文本挖掘,反映了一个字词对于一个语料库中的一份文件的重要程度。简单来说,一个词在一篇文章中出现的次数越多,同时在所有文章中出现的次数越少,那么这个词就越能代表这篇文章。它使用统计的方法将文本转化为有意义的稀疏矩阵。
给出以下训练样本和测试样本:
训练样本集:
d1: The sky is blue.
d2: The sun is bright.
测试样本集:
d3: The sun in the sky is bright.
d4: We can see the shining sun, the bright sun.
使用Python代码查看转化为数字后的向量表示:
# TfidfVectorizer
# CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer,CountVectorizer
import pandas as pd
# 文本集合
train = [\'The sky is blue.\',\'The sun is bright.\']
test = [\'The sun in the sky is bright\', \'We can see the shining sun, the bright sun.\']
# 实例化vectorizer对象
countvectorizer = CountVectorizer(analyzer= \'word\', stop_words=\'english\')
tfidfvectorizer = TfidfVectorizer(analyzer=\'word\',stop_words= \'english\',use_idf=True, norm=\'l2\')
# l2范数归一化(默认),use_idf=False时仅输出对应的tf值
# 文本转化为矩阵
count_wm = countvectorizer.fit_transform(train)
tfidf_wm = tfidfvectorizer.fit_transform(train)
# 获得对应的特征名字以dataframe形式输出
count_tokens = countvectorizer.get_feature_names()
tfidf_tokens = tfidfvectorizer.get_feature_names()
df_countvect = pd.DataFrame(data = count_wm.toarray(),index = [\'Doc1\',\'Doc2\'],columns = count_tokens)
df_tfidfvect = pd.DataFrame(data = tfidf_wm.toarray(),index = [\'Doc1\',\'Doc2\'],columns = tfidf_tokens)
print("Count Vectorizer\\n")
print(df_countvect)
print("\\nTD-IDF Vectorizer\\n")
print(df_tfidfvect)
输出:
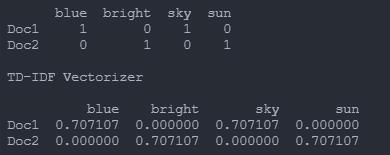
教科书上的计算公式如下:
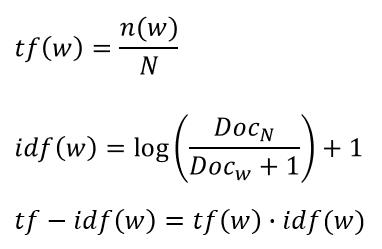
实际上sklearn不是这么计算tf-idf值的(算了很久很久才知道):
首先,sklearn中的tf只有分子上的,而没有上面公式的分母。也就是说sklearn中的tf只是数了一个词在一篇文档中出现的次数,并没有除以该文档的总词数(当计算tf-idf的时候)。
其次,sklearn中的idf是
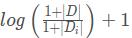
,其中分子是总文档数量,分母是含有该词的文档数量,默认分子分母都加1进行平滑处理。最后面的1,是先计算对数再加1,而不是先加1再计算对数。这里的对数是自然对数。
这一步结束后会得到一个原始tf-idf值,然后sklearn会进行一个范数归一化:
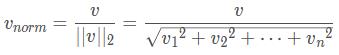
上述式子中每个分量对应每个特征的tf-idf值。
test = [\'The sun in the sky is bright\',
\'We can see the shining sun, the bright sun.\']
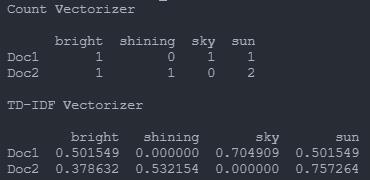
比如上图中Doc2中的sun :
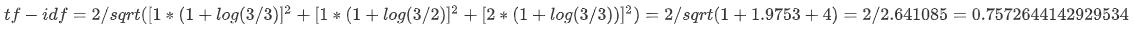
以上是关于sklearn中的tf-idf计算公式详解的主要内容,如果未能解决你的问题,请参考以下文章
在python中使用sklearn为n-gram计算TF-IDF
使用 sklearn tf-idf 查找矢量化文本文档中的簇数