TF-IDF计算过程
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TF-IDF计算过程相关的知识,希望对你有一定的参考价值。
参考技术A 本文内容主要摘自python machine learning 2nd edition1、假设我们有以下三个文本
• 'The sun is shining'
• 'The weather is sweet'
• 'The sun is shining, the weather is sweet, and one and one is two
2、利用CountVectorizer类得到如下字典
'and': 0,'two': 7,'shining': 3,'one': 2,'sun': 4,'weather': 8,'the': 6,'sweet': 5, 'is': 1
3、将步骤1的文档转换为矩阵
[[0 1 0 1 1 0 1 0 0]
[0 1 0 0 0 1 1 0 1]
[2 3 2 1 1 1 2 1 1]]
4.计算tf-idf值
我们以is为例进行计算,is对应的是矩阵第二列。
tf值,表示term在该文本中出现的次数,这里即is在文本3出现的次数,很容易看出是3.
idf值,sklearn做了小小的改动,公式是 (1+log ). 的意思就是文本总数(number of document),df(d,t)表示包含is 的文件数目,很明显,这里也是3.这样,计算的结果为3*(1+log )=3.
需要注意的是,sklearn对结果进行了正则化处理。
最终得到的结果为
[[ 0. 0.43 0. 0.56 0.56 0. 0.43 0. 0. ]
[ 0. 0.43 0. 0. 0. 0.56 0.43 0. 0.56]
[ 0.5 0.45 0.5 0.19 0.19 0.19 0.3 0.25 0.19]]
每一行的平方和均为1,这是l2正则化处理的结果。
另外可以看出,原先is的词频是 1 1 3,最终tf-idf值是0.43 0.43 0.45 。
TF-IDF算法介绍,简单模拟,以及在图数据中应用
目录
一、百度百科关于TF-IDF的算法介绍
https://baike.baidu.com/item/tf-idf/8816134?fr=aladdin

二、简单模拟
既然是简单模拟,我们就用人们最常用的一种工具MySQL去模拟一下这个算法可以实现的效果
2.1、创建表以及数据
article_keywords.sql
CREATE TABLE `article_keywords` (
`id` int NOT NULL AUTO_INCREMENT,
`article` varchar(255) NOT NULL,
`keyword` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=126 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO `article_keywords` VALUES ('113', '悟空悟空芭蕉扇牛魔王', '悟空');
INSERT INTO `article_keywords` VALUES ('114', '悟空悟空芭蕉扇牛魔王', '悟空');
INSERT INTO `article_keywords` VALUES ('115', '悟空悟空芭蕉扇牛魔王', '芭蕉扇');
INSERT INTO `article_keywords` VALUES ('116', '悟空悟空芭蕉扇牛魔王', '牛魔王');
INSERT INTO `article_keywords` VALUES ('117', '悟空红孩儿红孩儿三昧真火三昧真火', '悟空');
INSERT INTO `article_keywords` VALUES ('118', '悟空红孩儿红孩儿三昧真火三昧真火', '红孩儿');
INSERT INTO `article_keywords` VALUES ('119', '悟空红孩儿红孩儿三昧真火三昧真火', '红孩儿');
INSERT INTO `article_keywords` VALUES ('120', '悟空红孩儿红孩儿三昧真火三昧真火', '三昧真火');
INSERT INTO `article_keywords` VALUES ('121', '悟空红孩儿红孩儿三昧真火三昧真火', '三昧真火');
INSERT INTO `article_keywords` VALUES ('122', '悟空三昧真火火眼金睛', '三昧真火');
INSERT INTO `article_keywords` VALUES ('123', '悟空三昧真火火眼金睛', '火眼金睛');
INSERT INTO `article_keywords` VALUES ('124', '悟空三昧真火火眼金睛', '悟空');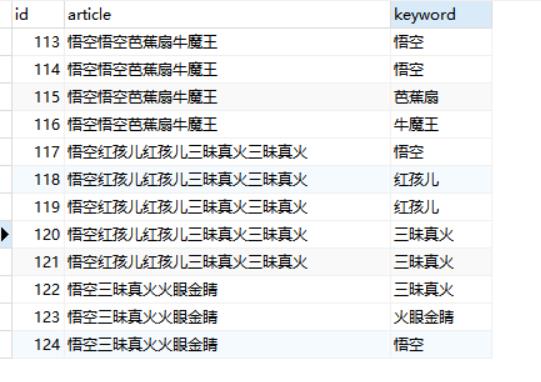
2.2、模拟实现TF-IDF的统计算分
实现sql
#实现TF-IDF的统计算分值
SELECT * FROM (
#计算TF-IDF的值
SELECT *,(TF * IDF)as 'TF-IDF' FROM (
#分别计算TF和IDF的值
SELECT *,(keyword_in_current_article_count / current_article_keyword_count) as TF,(article_count / keyword_in_all_article_count) as IDF FROM(
#查询表中数据以及联查计算TF-IDF所需的各种聚合值以及直接聚合文章总数量的值
SELECT article_keywords.*,keyword_in_current_article_count.keyword_in_current_article_count,current_article_keyword_count.current_article_keyword_count,keyword_in_all_article_count.keyword_in_all_article_count,(SELECT COUNT(1) FROM (SELECT article FROM article_keywords GROUP BY article) as a)as article_count FROM article_keywords as article_keywords
#联查关键词在当前文章中出现的频率的聚合表
LEFT JOIN (SELECT article,keyword,COUNT(1) as keyword_in_current_article_count FROM article_keywords GROUP BY article,keyword)as keyword_in_current_article_count
ON article_keywords.article = keyword_in_current_article_count.article AND article_keywords.keyword = keyword_in_current_article_count.keyword
#联查当前文章中所有关键词的个数的聚合表
LEFT JOIN (SELECT article,COUNT(keyword) as current_article_keyword_count FROM article_keywords GROUP BY article) as current_article_keyword_count
ON article_keywords.article = current_article_keyword_count.article
#联查出现此关键词的文章个数的聚合表
LEFT JOIN (SELECT a.keyword as keyword,COUNT(article) keyword_in_all_article_count FROM (
SELECT article,keyword FROM article_keywords GROUP BY article,keyword
)as a GROUP BY a.keyword)as keyword_in_all_article_count
ON article_keywords.keyword = keyword_in_all_article_count.keyword
) as article_keywords_tf_idf
) as article_keywords_tfidf
)as article_keywords_tfidf_order
#WHERE keyword = '三昧真火'
GROUP BY article,keyword ORDER BY article_keywords_tfidf_order.`TF-IDF` DESC
结果样例
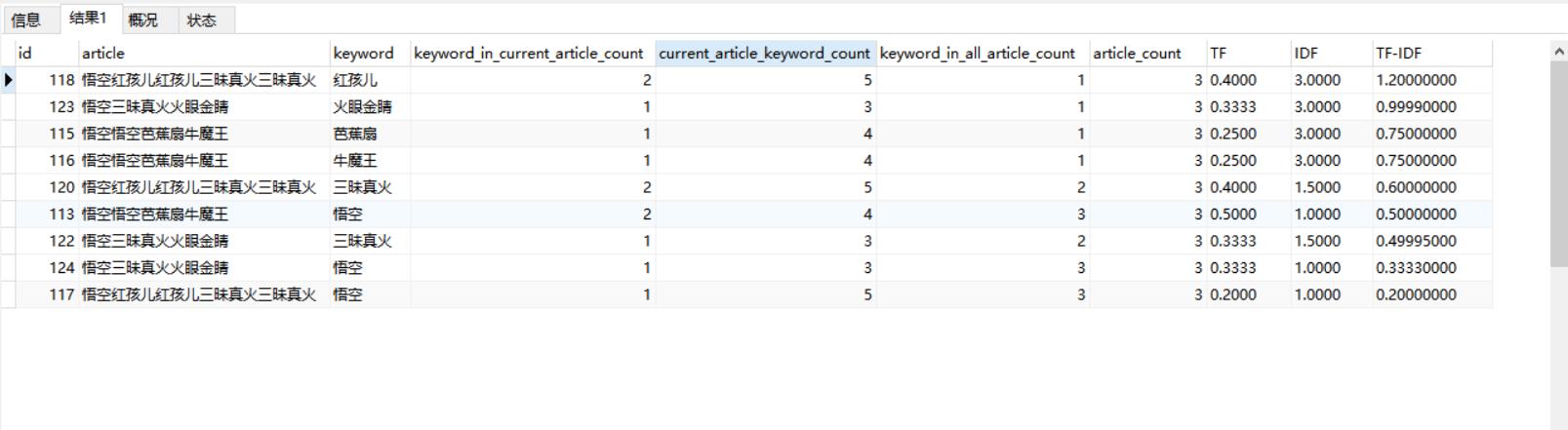
这只是用大家都熟悉的一个MySQL做一个简单的模拟实现的效果
当然,在实际应用中的场景比这要复杂的多,而且实际应用也不会使用MySQL来实现
下面我们来看看在图数据中的一个实际应用场景
三、图数据中应用
像我们常见的文档检索,比如ES的分词+倒排索引,通过对搜索内容的分词,对应找到包含这些关键词的文档,并且对结果进行一个计分排序,返回给用户。
这里我们用图数据库来做这样的事。
数据大概是这样的:
我们有文档节点,关键词节点(通过对文档分词的结果),以及他们的包含关系。
3.1、图数据模型
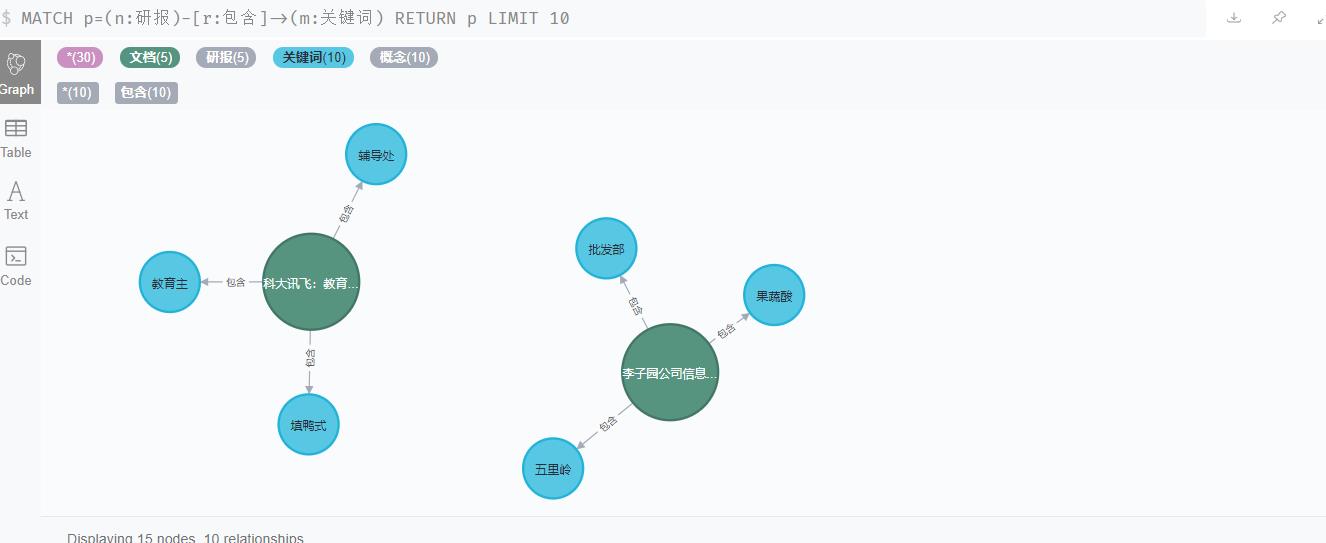
(文档详细属性)-[包含词频,TF-IDF分值]->(关键词)



3.2、计算文档中关键词的TF-IDF的分值
3.2.1、cypher实现TF-IDF 分数计算算法
指定研报以及研报中的一个关键词计算TF-IDF分数
// 获取研报以及关键词,计算该词在这篇研报的TF-IDF分数
// 获取研报`HDOC6a0250e61f91a856cd5dd6c39327fa57`和关键词`HCEPT69305efd9563834a4e7b67d6d5ac4674`,以及该关键词在研报中出现的次数count
MATCH (yb:研报)-[r:包含]->(kw:关键词) WHERE yb.hcode='HDOC6a0250e61f91a856cd5dd6c39327fa57' AND kw.hcode='HCEPT69305efd9563834a4e7b67d6d5ac4674'
WITH ID(yb) AS ybId,r.count AS count,ID(kw) AS kwId
// 获取该研报中关键词总数
MATCH (yb)-[r:包含]->(kw:关键词) WHERE ID(yb)=ybId
WITH ybId,SUM(r.count) AS kwCount,count,kwId
// 计算TF-词频(Term Frequency)
WITH ybId,1.0*count/kwCount AS tf,kwId
// 获取研报总数
MATCH (yb:研报) WITH COUNT(*) AS ybCount,ybId,tf,kwId
// 该关键词出现在多少篇研报中
MATCH (yb:研报)-[:包含]->(kw:关键词) WHERE ID(kw)=kwId WITH COUNT(yb) AS ybKwCount,ybCount,ybId,tf,kwId
// 计算IDF-逆文本频率指数(Inverse Document Frequency)
WITH tf,log10(ybCount/ybKwCount) AS idf,ybId,kwId
RETURN ybId,kwId,tf*idf AS `TF-IDF`3.2.2、存储过程实现
CALL apoc.custom.asProcedure(
'yanbao.kw.tfidf',
'// 获取研报以及关键词,计算该词在这篇研报的TF-IDF分数
// 获取研报`HDOC6a0250e61f91a856cd5dd6c39327fa57`和关键词`HCEPT69305efd9563834a4e7b67d6d5ac4674`,以及该关键词在研报中出现的次数count
MATCH (yb:研报)-[r:包含]->(kw:关键词) WHERE yb.hcode=$yanbaoHcode AND kw.hcode=$kwHcode
WITH ID(yb) AS ybId,r.count AS count,ID(kw) AS kwId
// 获取该研报中关键词总数
MATCH (yb)-[r:包含]->(kw:关键词) WHERE ID(yb)=ybId
WITH ybId,SUM(r.count) AS kwCount,count,kwId
// 计算TF-词频(Term Frequency)
WITH ybId,1.0*count/kwCount AS tf,kwId
// 获取研报总数
MATCH (yb:研报) WITH COUNT(*) AS ybCount,ybId,tf,kwId
// 该关键词出现在多少篇研报中
MATCH (yb:研报)-[:包含]->(kw:关键词) WHERE ID(kw)=kwId WITH COUNT(yb) AS ybKwCount,ybCount,ybId,tf,kwId
// 计算IDF-逆文本频率指数(Inverse Document Frequency)
WITH tf,log10(ybCount/ybKwCount) AS idf,ybId,kwId
RETURN ybId,kwId,tf*idf AS tfidf,$yanbaoHcode as yanbaoHcode,$kwHcode as kwHcode',
'READ',
[['yanbaoHcode','STRING'],['kwHcode','STRING'],['ybId','LONG'],['kwId','LONG'],['tfidf','DOUBLE']],
[['yanbaoHcode','STRING'],['kwHcode','STRING']],
'计算研报中某关键词TF-IDF分数'
);调用过程结果
CALL custom.yanbao.kw.tfidf('HDOC6a0250e61f91a856cd5dd6c39327fa57','HCEPT69305efd9563834a4e7b67d6d5ac4674') YIELD yanbaoHcode,kwHcode,ybId,kwId,tfidf RETURN yanbaoHcode,kwHcode,ybId,kwId,tfidf
结果是实现了,但是可以发现,一次计算耗时400ms~700ms
我们的模型数据集大概有一亿左右,这个效率要计算到猴年马月
3.3、优化3.2的查询
对于大批量使用这个过程的情况下的优化
这个存储过程的算法的计算,需要用到的值为4个【当前关键词在当前研报中包含的数量,当前研报中所包含的关键词的个数,研报的总数量,包含当前关键词的研报数量】
- 当前关键词在当前研报中包含的数量:(yb:研报)-[r:包含]->(kw:关键词),可以直接获取,无需消耗
- 当前研报中所包含的关键词的个数:存量计算时,可以直接聚合计算每个研报包含的关键词总数,加载至内存(耗时巨大,不采取)
- 研报的总数量:存量计算时,可以直接聚合研报总数量的值加载至内存(采用)
- 包含当前关键词的研报数量:存量计算时,可以直接聚合关键词的研报数量加载至内存(耗时巨大,不采取)
3.3.1、cypher优化去除ybCount计算的实现
//直接获取研报数量,免去在过程中每次都要获取研报数量
MATCH (n:研报) RETURN COUNt(n) as ybCount//1081720
// 获取研报以及关键词,计算该词在这篇研报的TF-IDF分数
// 获取研报`HDOC6a0250e61f91a856cd5dd6c39327fa57`和关键词`HCEPT69305efd9563834a4e7b67d6d5ac4674`,以及该关键词在研报中出现的次数count
MATCH (yb:研报)-[r:包含]->(kw:关键词) WHERE yb.hcode='HDOC6a0250e61f91a856cd5dd6c39327fa57' AND kw.hcode='HCEPT69305efd9563834a4e7b67d6d5ac4674'
WITH ID(yb) AS ybId,r.count AS count,ID(kw) AS kwId,1081720 as ybCount
// 获取该研报中关键词总数
MATCH (yb)-[r:包含]->(kw:关键词) WHERE ID(yb)=ybId
WITH ybId,SUM(r.count) AS kwCount,count,kwId,ybCount
// 计算TF-词频(Term Frequency)
WITH ybId,1.0*count/kwCount AS tf,kwId,ybCount
// 该关键词出现在多少篇研报中
MATCH (yb:研报)-[:包含]->(kw:关键词) WHERE ID(kw)=kwId WITH COUNT(yb) AS ybKwCount,ybCount,ybId,tf,kwId
// 计算IDF-逆文本频率指数(Inverse Document Frequency)
WITH tf,log10(ybCount/ybKwCount) AS idf,ybId,kwId
RETURN ybId,kwId,tf*idf AS `TF-IDF`3.3.2、优化去除ybCount计算的存储过程实现
CALL apoc.custom.asProcedure(
'yanbao.kw.tfidf.withYbCount',
'// 获取研报以及关键词,计算该词在这篇研报的TF-IDF分数
// 获取研报`HDOC6a0250e61f91a856cd5dd6c39327fa57`和关键词`HCEPT69305efd9563834a4e7b67d6d5ac4674`,以及该关键词在研报中出现的次数count
MATCH (yb:研报)-[r:包含]->(kw:关键词) WHERE yb.hcode=$yanbaoHcode AND kw.hcode=$kwHcode
WITH ID(yb) AS ybId,r.count AS count,ID(kw) AS kwId,$ybCount as ybCount
// 获取该研报中关键词总数
MATCH (yb)-[r:包含]->(kw:关键词) WHERE ID(yb)=ybId
WITH ybId,SUM(r.count) AS kwCount,count,kwId,ybCount
// 计算TF-词频(Term Frequency)
WITH ybId,1.0*count/kwCount AS tf,kwId,ybCount
// 该关键词出现在多少篇研报中
MATCH (yb:研报)-[:包含]->(kw:关键词) WHERE ID(kw)=kwId WITH COUNT(yb) AS ybKwCount,ybCount,ybId,tf,kwId
// 计算IDF-逆文本频率指数(Inverse Document Frequency)
WITH tf,log10(ybCount/ybKwCount) AS idf,ybId,kwId
RETURN ybId,kwId,tf*idf AS tfidf,$yanbaoHcode as yanbaoHcode,$kwHcode as kwHcode',
'READ',
[['yanbaoHcode','STRING'],['kwHcode','STRING'],['ybId','LONG'],['kwId','LONG'],['tfidf','DOUBLE']],
[['yanbaoHcode','STRING'],['kwHcode','STRING'],['ybCount','LONG']],
'计算研报中某关键词TF-IDF分数,增加存量数据时传入研报数量参数'
);调用过程结果
CALL custom.yanbao.kw.tfidf.withYbCount('HDOC6a0250e61f91a856cd5dd6c39327fa57','HCEPT69305efd9563834a4e7b67d6d5ac4674',1081720) YIELD yanbaoHcode,kwHcode,ybId,kwId,tfidf RETURN yanbaoHcode,kwHcode,ybId,kwId,tfidf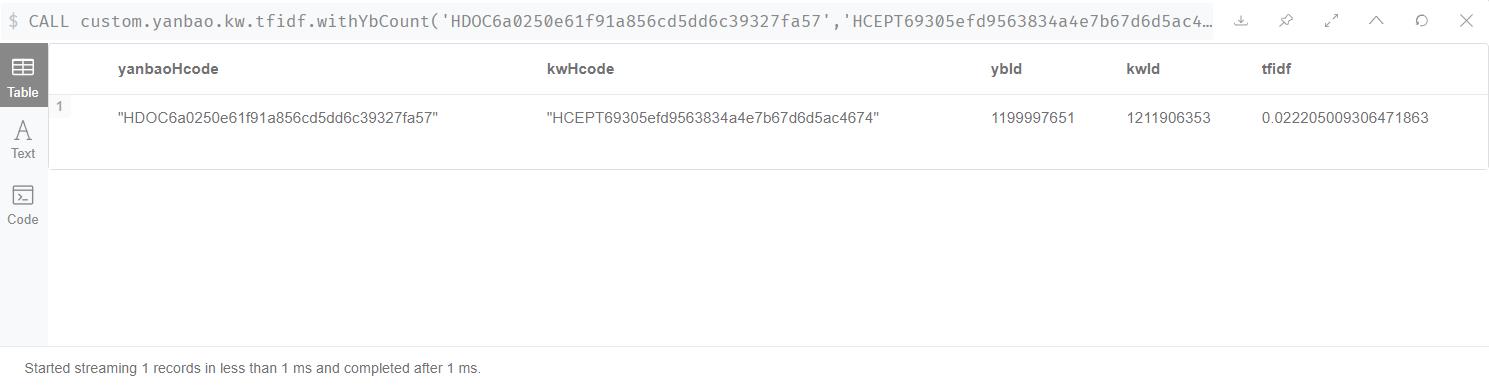
可以看到,我们去除了算法中最耗时的一步操作,COUNT()聚合是很耗性能的,现在的结果是一次计算耗时1ms,500倍的提升。
以上是关于TF-IDF计算过程的主要内容,如果未能解决你的问题,请参考以下文章