如何利用Python计算景观指数AI
Posted smile_2019
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何利用Python计算景观指数AI相关的知识,希望对你有一定的参考价值。
可使用工具包
- pylandstats
- 此工具包基本是根据fragstats形成的,大部分fragstats里面的景观指数,这里都可以计算。但是,还是有一小部分指数这里没有涉及。
- LS_METRICS
自定义的aggregation index(AI)计算
原理
\\[AI=\\frac{e_{ii}}{max\\_e_{ii}}\\times100
\\]
-
这里的\\(e_{ii}\\)是同类型像元公共边的个数
-
\\(max\\_e_{ii}\\)是同类型像元最大公共边的个数, \\(max\\_e_{ii}\\)的计算有公式可寻,具体计算公式如下:
\\[\\begin{align*} & max\\_eii = 2n(n-1), & when \\quad m = 0, or\\\\ & max\\_eii = 2n(n-1) + 2m -1, & when\\quad m ≤ n, or\\\\ & max\\_eii = 2n(n-1) + 2m -2, & when \\quad m > n.\\\\ \\end{align*} \\]-
n为不超过某个类型像元总面积\\(A_i\\)的最大整数正方形的边长
-
m=\\(A_i-n^2\\)
-
实例
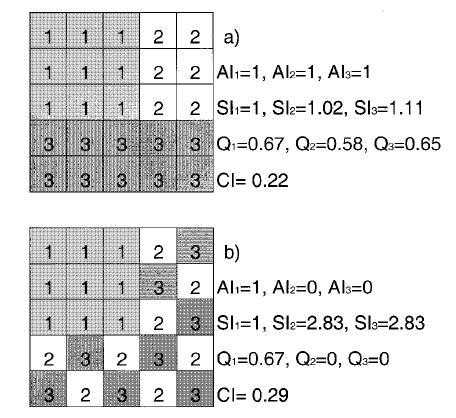
- 例如图a中类型1的聚居指数AI可为:\\[\\begin{align*} &e_{ii}=12\\\\ &max\\_e{ii}=2n(n-1)=2\\times3\\times2=12\\\\ &AI=\\frac{e_{ii}}{max\\_e{ii}}\\times100=100 \\end{align*} \\]这里AI为100是因为这里乘了一个系数100;
Python实现
- 函数依赖关系

class AI(Landscape, ABC):
def __init__(self, landscape, **kwargs):
super().__init__(landscape, **kwargs)
# 用于计算每种类型公共边的数量
def get_share_edge(self, class_):
# 1.将数据转换为二值型
binary_data = (self.landscape_arr == class_).astype(np.int8)
# 2.设置卷积模板
cov_template = np.array([[0, 0, 0],
[0, 0, 1],
[0, 1, 0]])
# 3.填充边缘
binary_pad = np.pad(binary_data, 1, mode=\'constant\', constant_values=0)
# 4.计算公共边总数
row_num, col_num = binary_pad.shape
count = 0
for i in range(1, row_num - 1):
for j in range(1, col_num - 1):
if binary_pad[i, j] == 1:
count += np.sum(binary_pad[i - 1:i + 2, j - 1:j + 2] * cov_template)
return count
# 计算eii
@property
def eii(self):
return pd.Series([self.get_share_edge(class_) for class_ in self.classes], index=self.classes)
# 计算最大的eii
@property
def max_eii(self):
arr = self.landscape_arr
flat_arr = arr.ravel()
# 规避nodata值
if self.nodata in flat_arr:
a_ser = pd.value_counts(flat_arr).drop(self.nodata).reindex(self.classes)
else:
a_ser = pd.value_counts(flat_arr).reindex(self.classes)
n_ser = np.floor(np.sqrt(a_ser))
m_ser = a_ser - np.square(n_ser)
max_eii = pd.Series(index=a_ser.index)
for i in a_ser.index:
if m_ser[i] == 0:
max_eii[i] = (2 * n_ser[i]) * (n_ser[i] - 1)
elif m_ser[i] <= n_ser[i]:
max_eii[i] = 2 * n_ser[i] * (n_ser[i] - 1) + 2 * m_ser[i] - 1
elif m_ser[i] >= n_ser[i]:
max_eii[i] = 2 * n_ser[i] * (n_ser[i] - 1) + 2 * m_ser[i] - 2
return max_eii
# 计算AI指数
def aggregation_index(self, class_val=None):
"""
计算斑块类型的聚集指数AI
:param class_val: 整型,需要计算AI的斑块类型代号
:return: 标量数值或者Series
"""
if len(self.classes) < 1:
warnings.warn("当前数组全是空值,没有需要计算的类型聚集指数",
RuntimeWarning,
)
return np.nan
if class_val is None:
return (self.eii / self.max_eii) * 100
else:
return ((self.eii / self.max_eii) * 100)[class_val]
-
参考文献
- An aggregation index (AI) to quantify spatial patterns of landscapes
- http://www.umass.edu/landeco/research/fragstats/documents/Metrics/Contagion - Interspersion Metrics/Metrics/C116 - AI.htm
以上是关于如何利用Python计算景观指数AI的主要内容,如果未能解决你的问题,请参考以下文章
ChatGPT竟写出毁灭人类计划书,还给出相应Python代码,网友:AI正在指数级发展...