Redis性能测试jedis连接原理弱事务
Posted IT王小二
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis性能测试jedis连接原理弱事务相关的知识,希望对你有一定的参考价值。
Redis 性能测试、jedis连接原理、弱事务。
一、性能测试、jedis连接原理
1. 什么是Redis慢查询
和mysql一样:当sql执行时间超过 long_query_time 参数设定的时间阈值(比如2秒)时,会发生耗时命令记录。
通信流程如下:
redis命令的生命周期:发送、排队、执行、返回。
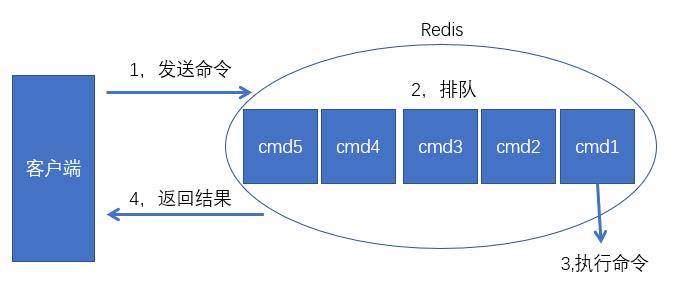
redis 的所有指令全部会存放到队列, 由单线程按顺序获取并执行指令。
如果某个指令执行很慢, 会出现阻塞, 以上图可以得出: Redis 的慢查询指的是在执行第 3 个操作的时候发生的。
2. Redis如何设置时间阈值
两种方式
第一种:修改配置文件redis.conf,重启redis。
// 修改set slowlog-log-slower-than为10000 (10毫秒)
slowlog-log-slower-than 10000
第二种:动态设置。
// 设置为10毫秒
127.0.0.1:6379> config set slowlog-log-slower-than 10000
OK
// 如果需要重启也生效
127.0.0.1:6379> config rewrite
OK
注意:slowlog-log-slower-than 0 记录所有命令,slowlog-log-slower-than -1 所有命令都不记录。
3. Redis慢查询记录原理
慢查询记录也是存在队列里的,slow-max-len 存放的记录最大条数,比如设置的 slow-max-len=10,当有第 11 条慢查询命令插入时,队列的第一条命令就会出列,第 11 条入列到慢查询队列中。
slow-max-len 默认值为128,可以 config set 动态设置,也可以修改 redis.conf 完成配置。
4. Redis慢查询命令
获取队列里慢查询的命令:slowlog get 。
获取慢查询列表当前的长度:slowlog len //以上只有 1 条慢查询,返回 1 。
- 对慢查询列表清理(重置):slowlog reset //再查 slowlog len 此时返回 0 清空
- 对于线上 slow-max-len 配置的建议:线上可加大 slow-max-len 的值,记录慢查询存
长命令时 redis 会做截断,不会占用大量内存,线上可设置 1000 以上 - 对于线上 slowlog-log-slower-than 配置的建议:默认为 10 毫秒,根据 redis 并发量来调整,对于高并发比建议为 1 毫秒
- 慢查询是先进先出的队列,访问日志记录出列丢失,需定期执行 slowlog get,将结果
存储到其它设备中(如 mysql)
5. Redis性能测试工具如何使用
安装时在 redis-cli 同目录下会有其他工具,比如 redis-benchmark 用于性能测试。
// 100个并发连接,10000个请求,检测服务器性能
redis-benchmark -c 100 -n 10000
// 测试存取大小为100字节的数据包的性能
redis-benchmark -q -d 100
// 只测试set,get 操作的性能
redis-benchmark -t set,get -n 100000 -q
6. 什么是RESP协议
引用 reidis官网 中有一段对RESP协议的描述。
Redis clients communicate with the Redis server using a protocol called RESP (REdis Serialization Protocol). While the protocol was designed specifically for Redis, it can be used for other client-server software projects.
RESP is a compromise between the following things:
- Simple to implement.
- Fast to parse.
- Human readable.
翻译过来就是: Redis客户端使用一种称为 RESP(Redis序列化协议) 的协议与Redis服务器通信。虽然该协议是专门为Redis设计的,但它可以用于其他客户机-服务器软件项目。
具有以下特点: 实现简单,解析速度快,人类可读。
RESP的底层实现原理
RESP 底层采用的是 TCP 的连接方式,通过 TCP 进行数据传输,然后根据 解析规则 解析相应信息,完成交互。
我们可以写个简单的例子来测试下,首先运行一个serverSocket监听6379,来接收redis客户端的请求信息,实现如下。
服务端代码:
//写一个伪的redis
public class ServerRedis {
public static void main(String[] args) {
try {
ServerSocket serverSocket = new ServerSocket(6379);
Socket socket = serverSocket.accept();
byte[] result = new byte[2048];
socket.getInputStream().read(result);
System.out.println(new String(result));
} catch (IOException e) {
e.printStackTrace();
}
}
}
客户端代码:
public class ClientTest {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1",6379);
jedis.set("name","SunnyBear");
jedis.close();
}
}
启动服务器端,启动客户端发送消息,客户端报错(因为jedis还需要返回,而我们写的伪redis端没有按格式返回),服务器端打印如下结果:
*3
$3
SET
$4
name
$9
SunnyBear
注:
*3 // *标识后面有几组数据,set key value,三组所以*3
$3 // $标识SET的长度,所以$3
SET
$4 // $标识name的长度,所以$4
name
$9 // $标识value的长度,所以$9
SunnyBear
这就是RESP协议的规则
7. 将现有表数据快速存放到Redis
流程如下:
- 使用用户名和密码登陆连接数据库
- 登陆成功后执行 order.sql 的 select 语句得到查询结果集 result
- 使用密码登陆 Redis
- Redis 登陆成功后, 使用 PIPE 管道将 result 导入 Redis. 测试操作如下:
建立order表
CREATE TABLE `order` (
`orderid` varchar(40) COLLATE utf8_bin DEFAULT NULL,
`ordertime` varchar(60) COLLATE utf8_bin DEFAULT NULL,
`ordermoney` varchar(40) COLLATE utf8_bin DEFAULT NULL,
`orderstatus` varchar(40) COLLATE utf8_bin DEFAULT NULL,
`version` varchar(40) COLLATE utf8_bin DEFAULT NULL
);
INSERT INTO `order` VALUES(\'1\',\'2019-01-01 14:04:05\',24,0,0);
INSERT INTO `order` VALUES(\'2\',\'2019-01-01 14:04:05\',24,0,0);
INSERT INTO `order` VALUES(\'3\',\'2019-01-01 14:04:05\',24,0,0);
INSERT INTO `order` VALUES(\'4\',\'2019-01-01 14:04:05\',24,0,0);
INSERT INTO `order` VALUES(\'5\',\'2019-01-01 14:04:05\',24,0,0);
INSERT INTO `order` VALUES(\'6\',\'2019-01-01 14:04:05\',24,0,0);
INSERT INTO `order` VALUES(\'7\',\'2019-01-01 14:04:05\',24,0,0);
INSERT INTO `order` VALUES(\'8\',\'2019-01-01 14:04:05\',24,0,0);
INSERT INTO `order` VALUES(\'9\',\'2019-01-01 14:04:05\',24,0,0);
INSERT INTO `order` VALUES(\'10\',\'2019-01-01 14:04:05\',24,0,0);
INSERT INTO `order` VALUES(\'11\',\'2019-01-01 14:04:05\',24,0,0);
INSERT INTO `order` VALUES(\'12\',\'2019-01-01 14:04:05\',24,0,0);
INSERT INTO `order` VALUES(\'13\',\'2019-01-01 14:04:05\',24,0,0);
INSERT INTO `order` VALUES(\'14\',\'2019-01-01 14:04:05\',24,0,0);
INSERT INTO `order` VALUES(\'15\',\'2019-01-01 14:04:05\',24,0,0);
INSERT INTO `order` VALUES(\'16\',\'2019-01-01 14:04:05\',24,0,0);
INSERT INTO `order` VALUES(\'17\',\'2019-01-01 14:04:05\',24,0,0);
INSERT INTO `order` VALUES(\'18\',\'2019-01-01 14:04:05\',24,0,0);
新建order.sql内容如下
SELECT CONCAT(
\'*10\\r\\n\',
\'$\', LENGTH(redis_cmd), \'\\r\\n\', redis_cmd, \'\\r\\n\',
\'$\', LENGTH(redis_key), \'\\r\\n\', redis_key, \'\\r\\n\',
\'$\', LENGTH(hkey1),\'\\r\\n\',hkey1,\'\\r\\n\',
\'$\', LENGTH(hval1),\'\\r\\n\',hval1,\'\\r\\n\',
\'$\', LENGTH(hkey2),\'\\r\\n\',hkey2,\'\\r\\n\',
\'$\', LENGTH(hval2),\'\\r\\n\',hval2,\'\\r\\n\',
\'$\', LENGTH(hkey3),\'\\r\\n\',hkey3,\'\\r\\n\',
\'$\', LENGTH(hval3),\'\\r\\n\',hval3,\'\\r\\n\',
\'$\', LENGTH(hkey4),\'\\r\\n\',hkey4,\'\\r\\n\',
\'$\', LENGTH(hval4),\'\\r\\n\',hval4,\'\\r\'
)
FROM (
SELECT
\'HSET\' AS redis_cmd,
CONCAT(\'order:info:\',orderid) AS redis_key,
\'ordertime\' AS hkey1, ordertime AS hval1,
\'ordermoney\' AS hkey2, ordermoney AS hval2,
\'orderstatus\' AS hkey3, orderstatus AS hval3,
\'version\' AS hkey4, `version` AS hval4
FROM `order`
) AS t
操作指令
mysql -uSunnyBear -p123456 sunny --default-character-set=utf8 --skip-column-names --raw < order.sql | redis-cli -h 192.168.182.130 -p 6379 -a 123456 --pipe
注: order.sql脚本最好放在redis安装目录下执行,方便管理
8. PIPELINE解决批量操作网络开销
大多数情况下,我们都会通过请求-相应机制去操作redis。只用这种模式的一般的步骤是:先获得 jedis 实例,然后通过 jedis 的 get/put 方法与 redis 交互。由于 redis 是单线程的,下一次请求必须等待上一次请求执行完成后才能继续执行。
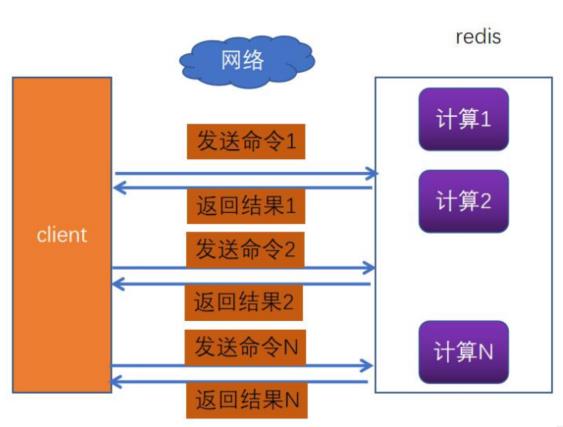
然而批量操作下这样网络开销很大,导致速度慢,使用 Pipeline 模式,客户端可以一次性的发送多个命令,无需等待服务端返回。这样就大大的减少了网络往返时间,提高了系统性能。
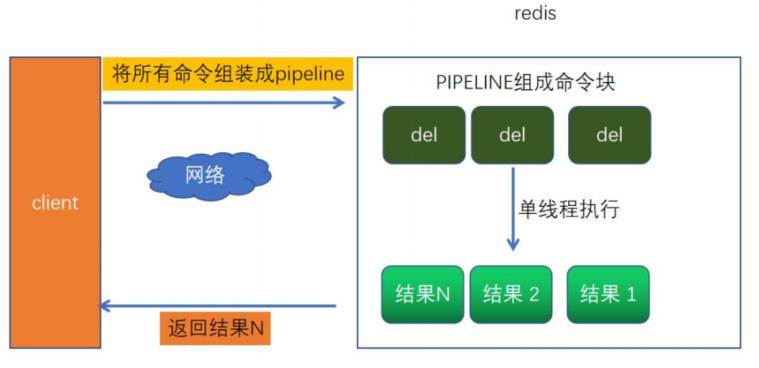
示例代码,初始化10000个key,批量删除5000个。
/**
* 初始化数据,批量设值
*/
public class RedisTools {
public static int arraylength = 10000;
public static String ip = "192.168.192.130";
public static int port = 6379;
public static String auth = "123456";
public static String[] keys = new String[arraylength / 2];
/**
* 初始化数据,批量设值
* redis提供的批量设值mset 批量取值 mget,但没有批量删除mdel指令
*/
public static void initRedisData() {
Jedis jedis = new Jedis(ip, port);
jedis.auth(auth);
String[] str = new String[arraylength];
int j = 0;
for (int i = 0; i < str.length / 2; i++) {
str[j] = "key:" + i;
str[j + 1] = "v" + i;
j = j + 2;
keys[i] = "key:" + i;
}
jedis.mset(str);
jedis.close();
}
}
public static void delNoPipe(String... keys){
Jedis jedis = new Jedis(RedisTools.ip,RedisTools.port);
Pipeline pipelined = jedis.pipelined();
for(String key : keys){
// 将所有要删除的key封装到pipelined
pipelined.del(key);
}
// 发送请求,执行删除操作
pipelined.sync();
jedis.close();
}
public static void main(String[] args) {
RedisTools.initRedisData();
long t = System.currentTimeMillis();
delNoPipe(RedisTools.keys);
System.out.println(System.currentTimeMillis()-t);
}
二、Redis弱事务
pipeline 是多条命令的组合,为了保证它的原子性,redis提供了简单的事务。
什么是事务?事务是指一组动作的执行,这一组动作要么成功,要么失败。
但是redis的事务没有MySQL等关系型数据库强大,为什么这么说呢?因为redis的事务只能保证语法错误的多条命令的原子性,而没办法保证多条命令语法正确,但是发生其他错误的情况。
1. Redis弱事务的基本使用
将需要执行的命令放入 multi 和 exec 两个命令之间。
127.0.0.1:6379> flushall // 线上环境慎用
OK
127.0.0.1:6379> multi // 事务开始
OK
127.0.0.1:6379> set user:name SunnyBear // 业务操作1
QUEUED
127.0.0.1:6379> set user:age 22 // 业务操作2
QUEUED
127.0.0.1:6379> sadd user:list user:1 user:2 // 业务操作3
QUEUED
127.0.0.1:6379> exec //事务结束,执行操作及返回结果
1) OK
2) OK
3) (integer) 2
2. Redis弱事务的两种情况
语法错误可以保证原子性
127.0.0.1:6379> flushall // 线上环境慎用
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set name SunnyBear
QUEUED
127.0.0.1:6379> set age 22
QUEUED
127.0.0.1:6379> sett name zhangsan
(error) ERR unknown command `sett`, with args beginning with: `name`, `zhangsan`,
127.0.0.1:6379> exec
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379> get age
(nil)
但是如果其他错误则无法保证原子性
127.0.0.1:6379> flushall // 线上环境慎用
OK
127.0.0.1:6379> set user:name SunnyBear
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set user:age 22
QUEUED
127.0.0.1:6379> sadd user:name zhangsan
QUEUED
127.0.0.1:6379> get user:name
QUEUED
127.0.0.1:6379> exec
1) OK
2) (error) WRONGTYPE Operation against a key holding the wrong kind of value
3) "SunnyBear"
127.0.0.1:6379> get user:name
"SunnyBear"
3. 停止事务
127.0.0.1:6379> flushall // 线上环境慎用
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379> set tt 1
QUEUED
127.0.0.1:6379> discard // 停止事务
OK
127.0.0.1:6379> exec
(error) ERR EXEC without MULTI
127.0.0.1:6379> get tt
(nil)
4. watch让事务失效

三、补充点
1. redis订阅功能
redis 提供了发布消息、订阅频道、取消订阅以及按照模式订阅和取消订阅。
不过实际不常用,术业有专攻嘛(消息队列)。
2. 键的迁移(了解即可)
move key db // reids 有 16 个库, 编号为 0-15
set name SunnyBear;
move name 5 // 迁移到第 6 个库
select 5 ;// 数据库切换到第 6 个库, get name 可以取到 james1
这种模式不建议在生产环境使用,在同一个 reids 里可以用。
dump key
restore key ttl value//实现不同 redis 实例的键迁移,ttl=0 代表没有过期时间
例子:在 A 服务器上 192.168.42.111
set name SunnyBear;
dump name; // 得到"\\x00\\tSunnyBear\\t\\x00\\xe7\\xf9 \\xe6\\x84\\x9d\\xc0\\xab"
在B服务器上:192.168.1.118
restore name 0 "\\x00\\tSunnyBear\\t\\x00\\xe7\\xf9 \\xe6\\x84\\x9d\\xc0\\xab"
get name // 返回SunnyBear
migrate
migrate用于在Redis实例间进行数据迁移,实际上migrate命令是将dump、restore、del三个命令进行组合,从而简化了操作流程。
migrate命令具有原子性,从Redis3.0.6版本后已经支持迁移多个键的功能。
migrate命令的数据传输直接在源Redis和目标Redis上完成,目标Redis完成restore后会发送OK给源Redis。
| migrat | 192.168.182.130 | 6379 | name | 0 | 1000 | copy | replace | keys |
|---|---|---|---|---|---|---|---|---|
| 指令 | 要迁移的目标ip | 端口 | 迁移键值 | 目标库 | 超时时间 | 迁移后不删除原键 | 不管目标库是不存在test键都迁移成功 | 迁移多个键 |
将128的name键值迁移到130上。
192.168.182.128:6379>migrat 192.168.182.130 6379 name 0 100 copy
3. 键的遍历(了解)
redis提供了两个命令来遍历所有键。
键全量遍历
注: 考虑到是单线程,在生产环境不建议使用,如果键多可能会阻塞。
keys * // * 代表匹配任意字符
keys *y // 标识以y结尾的key, 如my, yy
keys n?me // ? 代表匹配一个字符,如name, ndme
渐进式遍历
注: 特点是不会阻塞进程。
// 初始化示例数据
127.0.0.1:6379> mset n1 1 n2 2 n3 3 n4 4 n5 5 n6 6 n7 7 n8 8 n9 9 n10 10 n11 11 n12 12 n13 13
OK
// 渐进取值,最大取8条,从scan 0开始,但是count 的值不一定准确,例如下面设置8却取了10条
127.0.0.1:6379> scan 0 match n* count 8
1) "3"
2) 1) "n13"
2) "n4"
3) "n1"
4) "n8"
5) "n9"
6) "n11"
7) "n7"
8) "n12"
9) "n6"
10) "n10"
127.0.0.1:6379> scan 3 match n* count 8
1) "0"
2) 1) "n5"
2) "n2"
3) "n3"
两种遍历方式对比
scan 相比 keys 具备有以下特点:
- 通过游标分布进行的,不会阻塞线程。
- 提供 limit 参数,可以控制每次返回结果的最大条数,limit 不准,返回的
结果可多可少。 - 同 keys 一样,Scan 也提供模式匹配功能。
- 服务器不需要为游标保存状态,游标的唯一状态就是 scan 返回给客户端的
游标整数。 - scan 返回的结果可能会有重复,需要客户端去重复。
- scan 遍历的过程中如果有数据修改,改动后的数据能不能遍历到是不确定的。
- 单次返回的结果是空的并不意味着遍历结束,而要看返回的游标值是否为零。
都读到这里了,来个 点赞、评论、关注、收藏 吧!
文章作者:IT王小二
首发地址:https://www.itwxe.com/posts/6a029d95/
版权声明:文章内容遵循 署名-非商业性使用-禁止演绎 4.0 国际 进行许可,转载请在文章页面明显位置给出作者与原文链接。
以上是关于Redis性能测试jedis连接原理弱事务的主要内容,如果未能解决你的问题,请参考以下文章
第125天学习打卡(Redis Jedis 常用的API 事务 springboot整合)