Redis消息队列性能测试及知识点整理
Posted 架构文摘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis消息队列性能测试及知识点整理相关的知识,希望对你有一定的参考价值。
一.概述
Redis是一个开源(BSD许可),内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列代理。它支持字符串、哈希表、列表、集合、有序集合,位图,hyperloglogs等数据类型。内置复制、Lua脚本、LRU收回、事务以及不同级别磁盘持久化功能,同时通过Redis Sentinel提供高可用,通过Redis Cluster提供自动分区。
本文档的目标是:整理出部署的事项,jedis快速入门,部分健壮性方案,并着重测试了消息机制的接收、发送性能。
二.安装部署
linux下安装
1. $ tar xzf redis-stable.tar.gz
2. $ cd redis-stable
3. $ make
make完后 redis-stable目录下会出现编译后的redis服务程序redis-server,还有用于测试的客户端程序redis-cli
下面启动redis服务.
1. $ ./redis-server
注意这种方式启动redis使用的是默认配置。也可以通过启动参数告诉redis使用指定配置文件使用下面命令启动。
1. $ ./redis-server redis.conf
redis.conf是一个默认的配置文件。我们可以根据需要使用自己的配置文件。
启动redis服务进程后,就可以使用测试客户端程序redis-cli和redis服务交互了。比如:
1. $ ./redis-cli
2. redis> set foo bar
3. OK
4. redis> get foo
5. "bar"
保护模式
Linux环境下安装启动redis server后,是默认采用保护模式(protectedmode)的,即只能本地访问,内网的其它主机访问会被拒绝。
解决方法:
接着采用配置密码来处理:
1. $ ./redis-cli
2. $ config set requirepass your_passowrd
3. OK
4. $ auth your_passowrd
5. OK
6. $ config rewrite
7. OK
注意:采用config set 命令来配置是立即生效的,不需要重启server。config rewrite是写入配置文件,以后重启server,此配置还是有效的。所以,此种方法在启动server是需要指定配置文件($ ./redis-server redis.conf)。
其它处理方式请参考:http://arui.me/index.php/archives/151/
客户端sdk
Java版 sdk
Java的redis sdk是jedis,参考资料:https://github.com/xetorthio/jedis/wiki
c版 sdk
hiRedis 是 Redis 官方指定的 C 语言客户端开发包,支持Redis 完整的命令集、管线以及事件驱动编程。参考资料:https://github.com/redis/hiredis
php版 sdk
Predis 是 Redis 官方首推的 PHP 客户端开发包,要求 PHP版本至少在 5.3 或者以上。参考资料:https://github.com/nrk/predis
phpredis是php的一个扩展,效率是相当高有链表排序功能,对创建内存级的模块业务关系很有用,参考资料:https://github.com/owlient/phpredis
更多客户端sdk请参考:http://redis.io/clients
使用jedis
Jedis提供了JedisPool类来保证线程安全,我们在开发环境中应使用此连接池方案来访问redis。(jedis连接池底层使用了common-pool,所以对线程池的优化需要了解到common-pool的实现机理,可参考:http://commons.apache.org/proper/commons-pool/)
依赖配置
在项目maven的pom.xml文件中添加jedis依赖:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.2.0</version>
</dependency>
JedisPool示例
[java] view plain copy 在CODE上查看代码片派生到我的代码片
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import java.util.Arrays;
import java.util.Set;
public class JedisPoolMain {
private static HostAndPort hnp = new HostAndPort("10.3.17.148",6379);
public static void main(String[] args){
/// Jedis pool config, host, port, timeout, password
JedisPool pool = new JedisPool(new JedisPoolConfig(),
hnp.getHost(), hnp.getPort(), 2000,"ucsoftware");
/// Jedis implements Closable. Hence,
/// the jedis instance will be auto-closed after the last statement.
try (Jedis jedis = pool.getResource()) {
/// ... do stuff here ... for example
jedis.set("foo", "bar");
String foobar = jedis.get("foo");
System.out.println("get foo:"+ foobar);
jedis.zadd("sose", 0, "car");
jedis.zadd("sose", 0, "bike");
Set<String> sose = jedis.zrange("sose", 0, -1);
System.out.println("zrange foo:"+
Arrays.toString(sose.toArray(new String[sose.size()])));
}
/// ... when closing your application:
pool.destroy();
}
}
说明:使用jedis后要注意调用redis.close()来归还资源给线程池,此示例代码使用了try-with-resource语法,在jedis使用后是有被及时关闭的。
发布订阅示例
[java] view plain copy 在CODE上查看代码片派生到我的代码片
package redis.clients.yealink.jedis;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import redis.clients.jedis.JedisPubSub;
public class JedisSubscriberMain {
private static HostAndPort hnp = new HostAndPort("10.3.17.148",6379);
public static void main(String[] args) throws InterruptedException {
JedisPool pool = new JedisPool(new JedisPoolConfig(), hnp.getHost(),
hnp.getPort(), 2000,"ucsoftware");
/// Jedis implements Closable. Hence, the jedis instance will be auto-
/// closed after the last statement.
try (Jedis subscriber = pool.getResource()) {
subscribe(subscriber);
}
pool.destroy();
}
public static void subscribe(final Jedis subscriber){
subscriber.subscribe(new JedisPubSub() {
public void onMessage(String channel, String message) {
try {
// wait 0.5 secs to slow down subscribe and
// client-output-buffer exceed
System.out.println("channel - " + channel
+ " / message - " + message);
Thread.sleep(100);
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
}, "huangyx_redis_chat");
}
}
[java] view plain copy 在CODE上查看代码片派生到我的代码片
package redis.clients.yealink.jedis;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisPublisherMain {
private static HostAndPort hnp = new HostAndPort("10.3.17.148",6379);
public static void main(String[] args){
JedisPool pool = new JedisPool(new JedisPoolConfig(), hnp.getHost(),
hnp.getPort(), 2000,"ucsoftware");
/// Jedis implements Closable. Hence,
/// the jedis instance will be auto-closed after the last statement.
try (Jedis publisher = pool.getResource()) {
publish(publisher);
}
pool.destroy();
}
public static void publish(final Jedis publisher){
String publishString = "this is a publish message!";
for (int i = 0; i < 10; i++) {
publisher.publish("huangyx_redis_chat", publishString);
}
publisher.disconnect();
}
}
说明:JedisSubscriberMain类是订阅者程序,必须先启动,JedisPublisherMain类是发布者程序,启动后,订阅者程序即可收到消息。
发布订阅流程可参考:http://www.redis.net.cn/tutorial/3514.html
更多的示例请参考jedis源码的test工程。
三.消息队列性能测试
发送测试
测试背景:
在发送程序(消息的生产者)中连续发送消息,记录完成发送任务所花费的时间,以此测试在高负载情况下的写入性能。
Redis的发送数据,性能上仍有很大提升空间(使用Luke协议等),请参考:http://www.redis.cn/topics/mass-insert.html。
接收测试
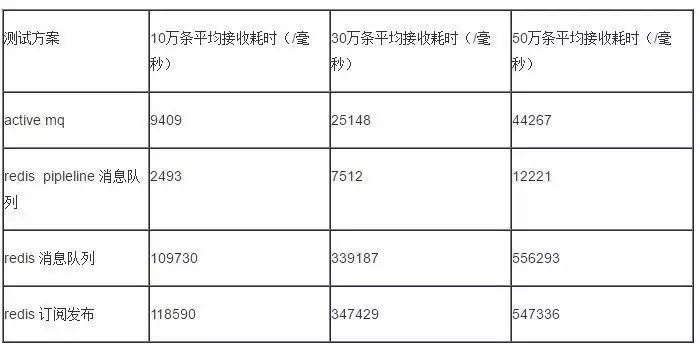
结论与比较
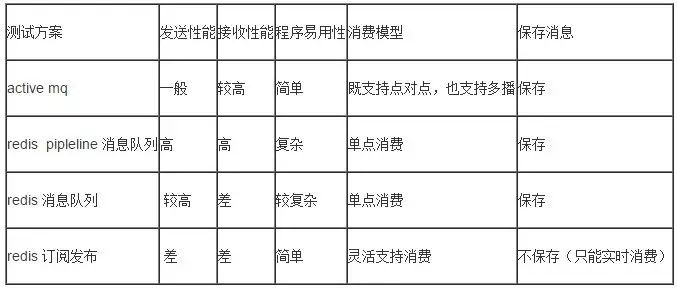
说明:
1. 性能分为四个等级(高,较高,一般,差);
2. redisPipeline消息队列的发送和接收性能都是最高的,但是由于异步模型(Pipeline原理请参考:http://www.redis.cn/topics/pipelining.html)造成了程序使用性上复杂,同时只支持单点消费;
3. redis的订阅发布机制的发送和接收性能都是最差的,但是适合灵活的订阅场景,支持了模式的订阅与发布,功能强大(具体参考:http://www.redis.cn/topics/pubsub.html);
4. redis普通的消息队列机制,在发送时支持批量方式,发送性能较高,但是接收性能差(不支持批量);
四.健壮性
持久化方案
Redis提供了多种不同级别的持久化方式:一种是RDB,另一种是AOF.
RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)。
AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。
Redis 还可以同时使用 AOF 持久化和 RDB 持久化。 在这种情况下, 当 Redis 重启时, 它会优先使用 AOF 文件来还原数据集, 因为 AOF 文件保存的数据集通常比RDB 文件所保存的数据集更完整。
RDB方式
redis.conf配置文件中与RDB相关的重要配置参数,默认文件已配置:
1) 时间范围内key变动的持久化策略配置
################################SNAPSHOTTING #######################
# save <seconds> <changes>
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
#
# Note: you can disable saving completely by commenting out all"save" lines.
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
# save ""
save 900 1 #900秒后至少1个key有变动
save 300 10 #300秒后至少10个key有变动
save 60 10000 #60秒后至少10000个key有变动
2) 持久化rdb文件名配置
# The filename where to dump the DB
dbfilename dump.rdb
3) 持久化rdb文件目录配置
# Note that you must specify adirectoryhere, not a file name.
dir"/usr/local/redis-stable/src"
配置好这些参数后即可启动RDB。如果想禁用快照保存的功能,可以通过注释掉所有"save"配置达到,或者在最后一条"save"配置后添加如下的配置:
save ""
AOF方式
配置方式,打开redis的配置文件。找到appendonly。默认是appendonly no。改成appendonly yes。
再找到appendfsync
配置参数说明,默认配置文件选择的是everysec:
# appendfsync always #每次收到写命令就立即强制写入磁盘,最慢的,但是保证完全的持久化,不推荐使用
appendfsync everysec #每秒钟强制写入磁盘一次,在性能和持久化方面做了很好的折中
# appendfsync no #完全依赖os,性能最好,持久化没保证
更多关于持久化配置说明请参考:https://segmentfault.com/a/1190000002906345
优缺点
RDB 的优点:
RDB 是一个非常紧凑(compact)的文件,它保存了 Redis 在某个时间点上的数据集。这种文件非常适合用于进行备份:比如说,你可以在最近的 24 小时内,每小时备份一次 RDB 文件,并且在每个月的每一天,也备份一个 RDB 文件。这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本。RDB 非常适用于灾难恢复(disaster recovery):它只有一个文件,并且内容都非常紧凑,可以(在加密后)将它传送到别的数据中心,或者亚马逊 S3 中。RDB 可以最大化 Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
RDB 的缺点:
如果你需要尽量避免在服务器故障时丢失数据,那么 RDB 不适合你。虽然 Redis 允许你设置不同的保存点(save point)来控制保存 RDB 文件的频率,但是, 因为RDB 文件需要保存整个数据集的状态, 所以它并不是一个轻松的操作。 因此你可能会至少 5 分钟才保存一次 RDB 文件。 在这种情况下, 一旦发生故障停机, 你就可能会丢失好几分钟的数据。每次保存RDB 的时候,Redis 都要 fork() 出一个子进程,并由子进程来进行实际的持久化工作。在数据集比较庞大时, fork() 可能会非常耗时,造成服务器在某某毫秒内停止处理客户端;如果数据集非常巨大,并且 CPU 时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒。虽然 AOF 重写也需要进行 fork() ,但无论 AOF 重写的执行间隔有多长,数据的耐久性都不会有任何损失。
AOF 的优点:
使用 AOF 持久化会让 Redis 变得非常耐久(much more durable):你可以设置不同的 fsync 策略,比如无 fsync ,每秒钟一次 fsync ,或者每次执行写入命令时 fsync 。 AOF 的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync 会在后台线程执行,所以主线程可以继续努力地处理命令请求)。AOF 文件是一个只进行追加操作的日志文件(append only log),因此对 AOF 文件的写入不需要进行 seek ,即使日志因为某些原因而包含了未写入完整的命令(比如写入时磁盘已满,写入中途停机,等等), redis-check-aof 工具也可以轻易地修复这种问题。
Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写:重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。AOF 文件有序地保存了对数据库执行的所有写入操作,这些写入操作以 Redis 协议的格式保存,因此 AOF 文件的内容非常容易被人读懂,对文件进行分析(parse)也很轻松。导出(export) AOF 文件也非常简单:举个例子, 如果你不小心执行了FLUSHALL 命令,但只要 AOF 文件未被重写,那么只要停止服务器,移除 AOF 文件末尾的 FLUSHALL 命令,并重启 Redis ,就可以将数据集恢复到 FLUSHALL 执行之前的状态。
AOF 的缺点:
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。AOF 在过去曾经发生过这样的 bug :因为个别命令的原因,导致 AOF 文件在重新载入时,无法将数据集恢复成保存时的原样。(举个例子,阻塞命令 BRPOPLPUSH 就曾经引起过这样的 bug 。)测试套件里为这种情况添加了测试:它们会自动生成随机的、复杂的数据集,并通过重新载入这些数据来确保一切正常。虽然这种 bug 在 AOF 文件中并不常见,但是对比来说, RDB 几乎是不可能出现这种 bug 的。
更多详细资料请参考:http://www.redis.cn/topics/persistence.html
主从复制
原理
1) 在Slave启动并连接到Master之后,它将主动发送一个SYNC命令。
2)此后Master将启动后台存盘进程,同时收集所有接收到的用于修改数据集的命令,在后台进程执行完毕后,Master将传送整个数据库文件到Slave,以完成一次完全同步。
3) 而Slave服务器在接收到数据库文件数据之后将其存盘并加载到内存中。
4)此后,Master继续将所有已经收集到的修改命令,和新的修改命令依次传送给Slaves,Slave将在依次执行这些数据修改命令,从而达到最终的数据同步。
如果Master和Slave之间的链接出现断连现象,Slave可以自动重连Master,但是在连接成功之后,一次完全同步将被自动执行。
Master和Slave端同步流程图:

Master发送RDB文件后,重复发送ping命令和变更命令:

看完这个图,你也许会有以下几个疑问:
1. 为什么在master发送完RDB文件后,还要定期的向slave发送PING命令?
2. 在发送完RDB文件之后,master发送的“变更”命令又是什么,有什么用?
在回答问题之前1,我们先回答问题2:
master保存RDB文件是通过一个子进程进行的,所以master依然可以处理客户端请求而不被阻塞,但这也导致了在保存RDB文件期间,“键空间”可能发生变化(譬如接收到一个客户端请求,执行"set name diaocow"命令),因此为了保证数据同步的一致性,master会在保存RDB文件期间,把接受到的这些可能变更数据库“键空间”的命令保存下来,然后放到每个slave的回复列表中,当RDB文件发送完master会发送这些回复列表中的内容,并且在这之后,如果数据库发生变更,master依然会把变更的命令追加到回复列表发送给slave,这样就可以保证master和slave数据的一致性。
对于问题1:由于在发送完RDB文件之后,master会不定时的给slave发送“变更”命令,可能过1s,也可能过1小时,所以为了防止slave无意义等待(譬如master已经挂掉的情况),master需要定时发送“保活”命令PING,以此告诉slave:我还活着,不要中断与我的连接
有了master-slave主从复制,可以通过其他的客户端程序去读取Slave磁盘数据库的数据,而对Master进行数据变更操作,从而达到了读写分离的目的。
特点
1) 同一个Master可以同步多个Slaves。
2) Slave同样可以接受其它Slaves的连接和同步请求,这样可以有效的分载Master的同步压力。因此我们可以将Redis的Replication架构视为图结构。
3) Master Server是以非阻塞的方式为Slaves提供服务。所以在Master-Slave同步期间,客户端仍然可以提交查询或修改请求。
4) SlaveServer同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据。
5) 为了分载Master的读操作压力,Slave服务器可以为客户端提供只读操作的服务,写服务仍然必须由Master来完成。即便如此,系统的伸缩性还是得到了很大的提高。
6) Master可以将数据保存操作交给Slaves完成,从而避免了在Master中要有独立的进程来完成此操作。
潜在的问题:
Slave从库在连接Master主库时,Master会进行内存快照,然后把整个快照文件发给Slave,也就是没有象mysql那样有复制位置的概念,即无增量复制,这会给整个集群搭建带来非常多的问题。
比如Slave由于网络或者其它原因与Master断开了连接,那么当 Slave进行重新连接时,需要重新获取整个Master的内存快照,Slave所有数据跟着全部清除,然后重新建立整个内存表,一方面Slave恢复的时间会非常慢,另一方面也会给主库带来压力。
配置
配置参数说明:
1) slaveof <masterip><masterport>
slave实例需要配置该项,指向master的(ip, port)。
2) masterauth <master-password>
如果master实例启用了密码保护,则该配置项需填master的启动密码;若master未启用密码,该配置项需要注释掉。
3) slave-serve-stale-data
指定slave与master连接中断时的动作。默认为yes,表明slave会继续应答来自client的请求,但这些数据可能已经过期(因为连接中断导致无法从master同步)。若配置为no,则slave除正常应答"INFO"和"SLAVEOF"命令外,其余来自客户端的请求命令均会得到"SYNC with master in progress"的应答,直到该slave与master的连接重建成功或该slave被提升为master。
4) slave-read-only
指定slave是否只读,默认为yes。若配置为no,这表示slave是可写的,但写的内容在主从同步完成后会被删掉。
5) repl-ping-slave-period
Redis部署为Replication模式后,slave会以预定周期(默认10s)发PING包给master,该配置可以更改这个默认周期。
6) repl-timeout
有2种情况的超时均由该配置指定:1) Bulk transfer I/O timeout; 2) master data or ping responsetimeout。需要特别注意的是:若修改默认值,则用户输入的值必须大于repl-ping-slave-period的配置值,否则在主从链路延时较高时,会频繁timeout。
7) repl-disable-tcp-nodelay
指定向slave同步数据时,是否禁用socket的NO_DELAY选项。若配置为yes,则禁用NO_DELAY,则TCP协议栈会合并小包统一发送,这样可以减少主从节点间的包数量并节省带宽,但会增加数据同步到slave的时间。若配置为no,表明启用NO_DELAY,则TCP协议栈不会延迟小包的发送时机,这样数据同步的延时会减少,但需要更大的带宽。通常情况下,应该配置为no以降低同步延时,但在主从节点间网络负载已经很高的情况下,可以配置为yes。
备注:socket的NO_DELAY选项涉及到TCP协议栈的拥塞控制算法—Nagle's Algorithm。
8) slave-priority
指定slave的优先级。在不只1个slave存在的部署环境下,当master宕机时,Redis Sentinel会将priority值最小的slave提升为master。需要注意的是,若该配置项为0,则对应的slave永远不会被Redis Sentinel自动提升为master。
(未完待续)
来源:http://blog.csdn.net/gufachongyang02/article/details/52274126
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。
-END-
架构文摘
ID:ArchDigest
互联网应用架构丨架构技术丨大型网站丨大数据丨机器学习
更多精彩文章,请点击下方:阅读原文
以上是关于Redis消息队列性能测试及知识点整理的主要内容,如果未能解决你的问题,请参考以下文章