Python爬虫实战,Scrapy实战,爬取旅行家游记信息
Posted 楚_阳
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫实战,Scrapy实战,爬取旅行家游记信息相关的知识,希望对你有一定的参考价值。

前言
我们先爬些简单点的内容,爬取汽车之家旅行家中的所有游记信息,让我们愉快地开始吧~
开发工具
Python版本:3.6.4
相关模块:
scrapy模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
资料推荐
scrapy入门教程:
https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
Scrapy框架入门简介:
https://segmentfault.com/a/1190000013178839
原理简介
首先,我们在cmd窗口输入下图所示的命令,从而新建一个爬虫项目:

我们需要爬的网站是:
https://you.autohome.com.cn/index/searchkeyword#pvareaid=2174276¤tView=best
简单抓包就可以发现这个:
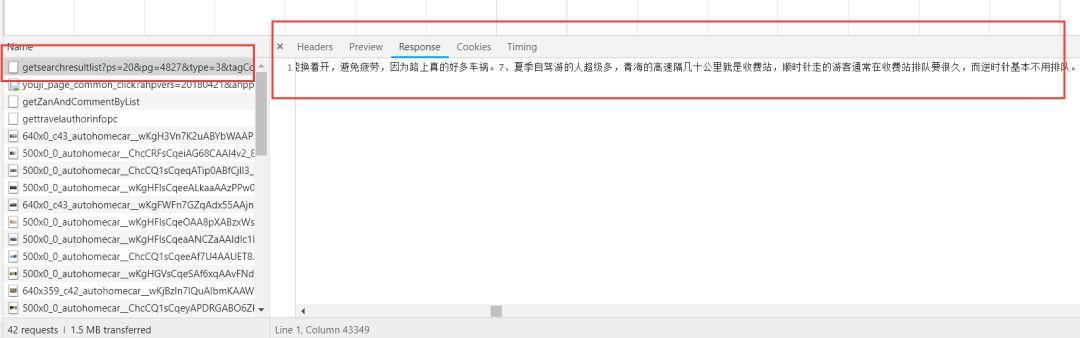
那么我们就爬这个。我们可以发现这个ajax请求返回的数据有:
该页所有游记的标题、摘要、日期、浏览量等等。
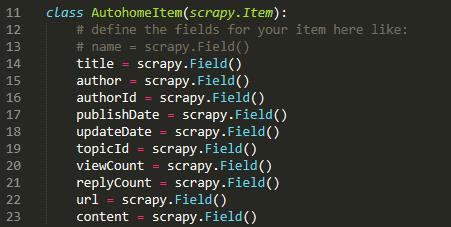
OK,明确了爬取目标之后,我们就可以开始写代码了。首先,打开爬虫项目里的item.py文件,定义一下我们要爬取的内容:
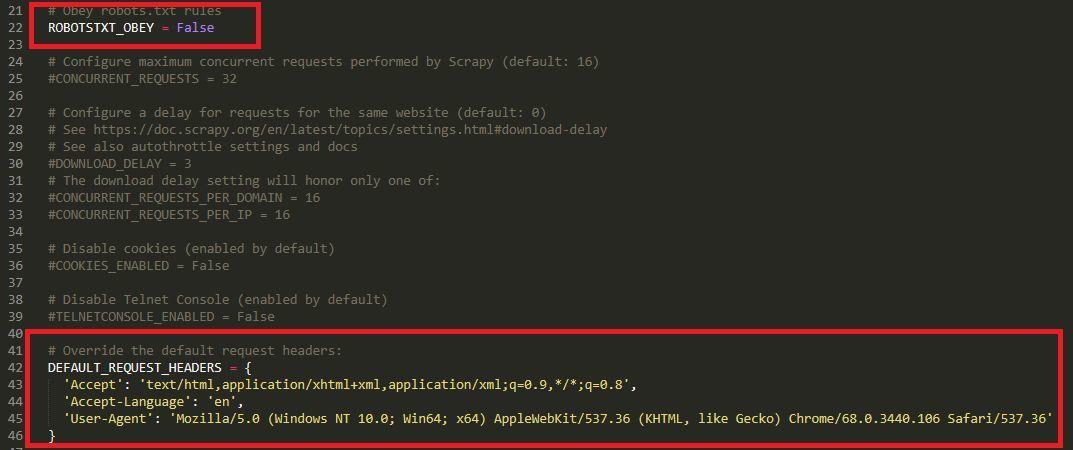
然后打开setting.py文件,定义一下请求头,并选择不遵守robots协议:
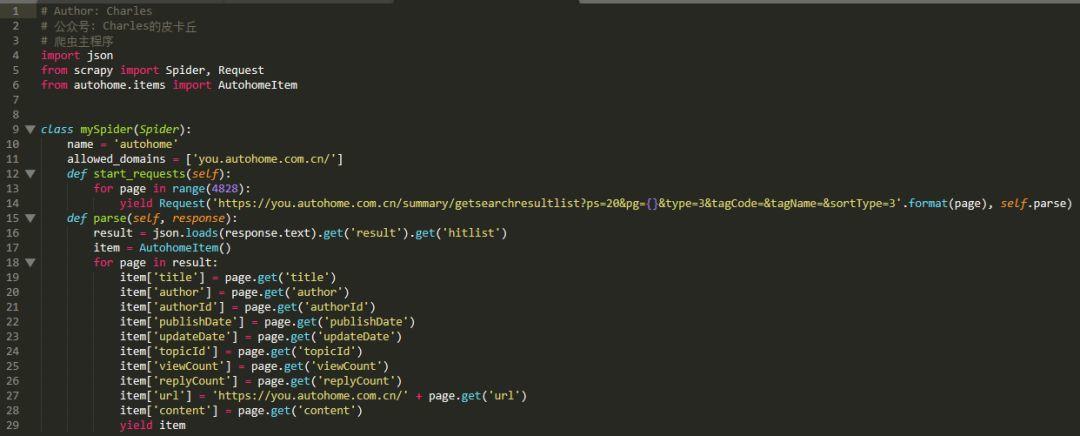
最后,在spiders文件夹内新建一个spider.py文件,并在该文件内编写我们的爬虫代码:
文章到这里就结束了,感谢你的观看,关注我每天分享Python模拟登录系列,下篇文章分享爬取并简单分析安居客租房信息。
为了感谢读者们,我想把我最近收藏的一些编程干货分享给大家,回馈每一个读者,希望能帮到你们。
干货主要有:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
All done~完整源代码+干货详见个人简介或者私信获取相关文件。。
以上是关于Python爬虫实战,Scrapy实战,爬取旅行家游记信息的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫实战,Scrapy实战,爬取并简单分析知网中国专利数据