Python爬虫实战,Scrapy实战,知乎粉丝小爬虫
Posted 楚_阳
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫实战,Scrapy实战,知乎粉丝小爬虫相关的知识,希望对你有一定的参考价值。

前言
写个知乎粉丝小爬虫,分为数据爬取和数据的简单可视化两个部分。让我们愉快地开始吧~
开发工具
Python版本:3.6.4
相关模块:
scrapy模块;
pyecharts==1.5.1模块;
wordcloud模块;
jieba模块;
以及一些python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
数据爬取
先随手推一波自己开源的利用requests进行模拟登录的库:
https://github.com/CharlesPikachu/DecryptLogin
目前该库支持模拟登录的网站包括:
1\\. 微博
后续会不断添加和完善该库的功能以及该库相关的一些小应用。当然,今天是用不上了,因为我发现他喵的知乎的粉丝数据竟然一直是一个裸的API,即使是改版之后,也不需要验证什么登录后的cookies之类的东西直接就能抓取到了。
言归正传,简单说说这个数据怎么抓取吧,其实很简单,F12打开开发者工具,刷新一下关注者页面,就可以发现:
请求这个接口直接就能返回目标用户的粉丝数据了,接口的组成形式为:
https://www.zhihu.com/api/v4/members/{用户域名}/followers?
没有什么特别需要注意的地方,不用怀疑,就是这么简单,scrapy新建一个项目爬就完事了:
scrapy startproject zhihuFansSpider
定义一下items:
class ZhihufansspiderItem(scrapy.Item):
然后新建并写一个爬虫主程序就OK啦:
\'\'\'知乎粉丝小爬虫\'\'\'
运行以下命令开始爬取目标用户的粉丝数据:
scrapy crawl zhihuFansSpider -o followers_info.json -t json
数据可视化
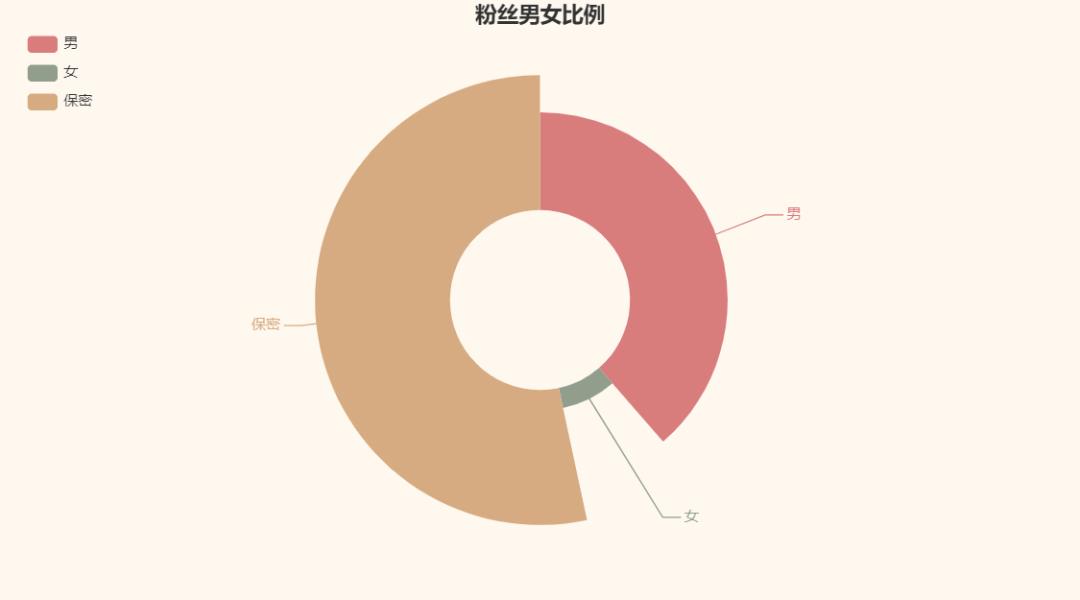
老规矩,可视化一下爬到数据呗(这里就以我自己知乎账号的关注者数据为例好了T_T)。
先画个粉丝主页标题的词云压压惊?
应该算是很真实吧?[图片上传失败...(image-b139c3-1617265093411)]
让我们再来看看我的关注者里有多少VIP用户?

好的,答案是0个~
再来看看follow我的人一般有多少followers呗:
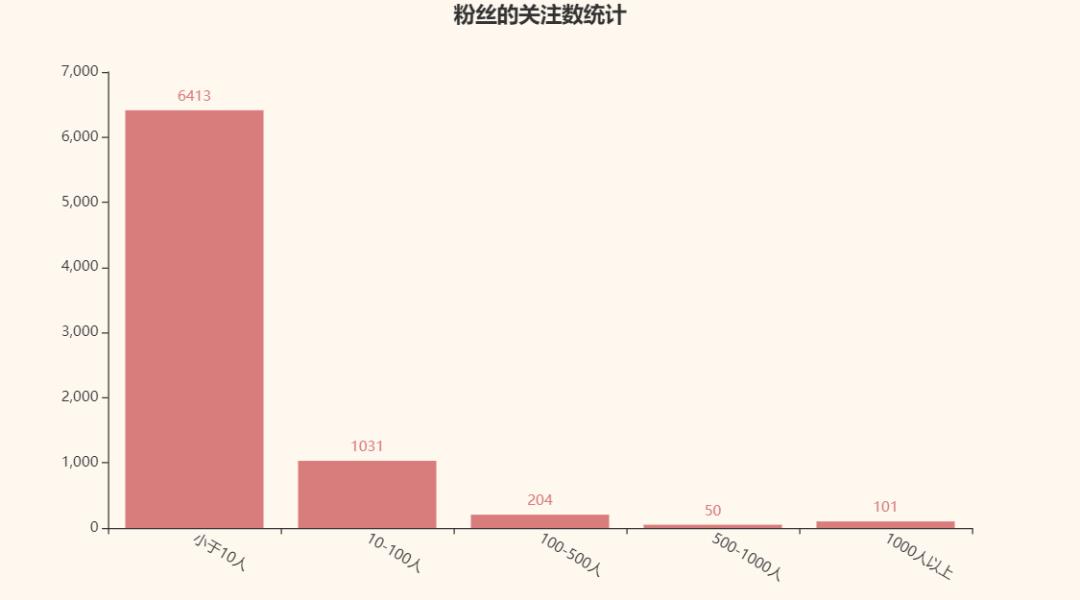
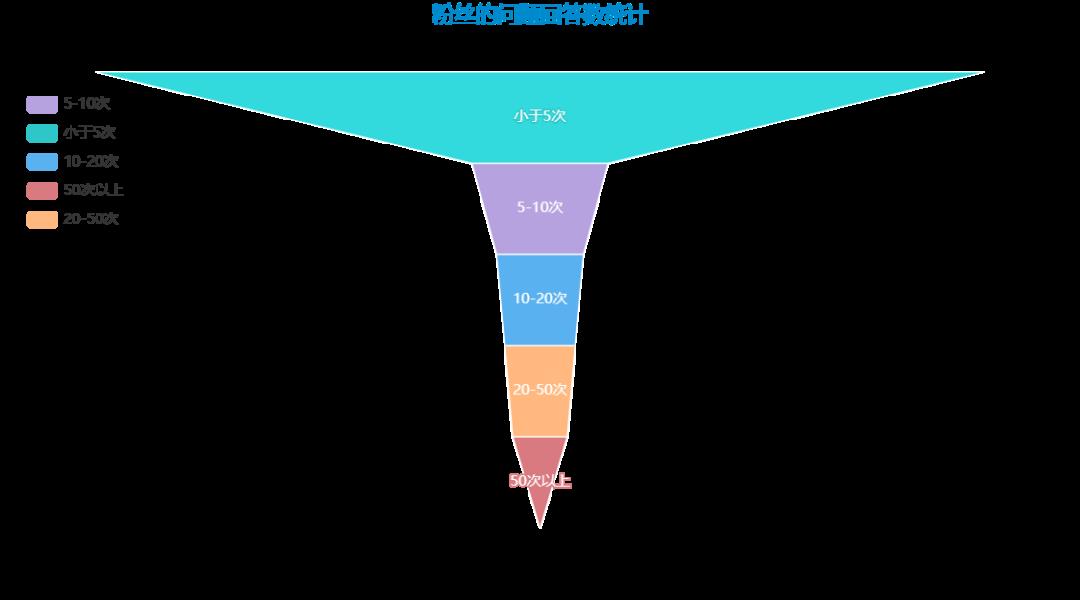
最后再来看看粉丝的回答数统计呗:
文章到这里就结束了,感谢你的观看,关注我每天分享Python模拟登录系列,下篇文章分享爬取旅行家游记信息。
为了感谢读者们,我想把我最近收藏的一些编程干货分享给大家,回馈每一个读者,希望能帮到你们。
干货主要有:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
All done~完整源代码+干货详见个人简介或者私信获取相关文件。。
以上是关于Python爬虫实战,Scrapy实战,知乎粉丝小爬虫的主要内容,如果未能解决你的问题,请参考以下文章
Python网络爬虫实战-Scrapy视频教程 Python系统化项目实战课程 Scrapy技术课程
Python爬虫实战:利用scrapy,短短50行代码下载整站短视频