傲腾持久内存如何为数据赋能,加速应用落地?
Posted 白玉兰开源
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了傲腾持久内存如何为数据赋能,加速应用落地?相关的知识,希望对你有一定的参考价值。
由Intel AI 实践日工作组和第四范式发起的“英特尔AI实践日第31期&AI应用与异构内存编程挑战赛总动员”线上研讨会将于6月10日晚上开播。
届时,来自英特尔的分享嘉宾胡风华是傲腾事业部云软件架构师,将对傲腾PMDK编程技术进行简单介绍,并探讨在人工智能领域的应用前景。
傲腾持久内存自2019年正式推出以来,已经在在众多领域展现出非凡实力,获得了广泛赞誉。特别是在人工智能方面,傲腾已经成功地应用在许多互联网公司的人工智能关键业务。
傲腾持久内存是如何为数据赋能,加速应用落地,本次特邀胡风华撰写详解持久内存编程技术。
01 傲腾持久内存及其使用模式
英特尔®傲腾™持久内存以创新的内存技术重新定义了传统存储架构,将高性价比的大容量内存与数据持久性巧妙地结合在一起,以合理的价格提供大型持久内存层级。凭借在内存密集型工作负载,虚拟机密度和快速存储容量方面的突破性性能水平,英特尔®傲腾™持久内存 (Intel® Optane™PMem) 可加速IT转型,以支持数据时代对算力的需求。
全新的PMem 200 系列与第三代英特尔®至强®可扩展处理器(Ice Lake, ICX)搭配,入门级PMem系列与第二代英特尔®至强®可扩展处理器(Cascade Lake, CLX)搭配,与针对数据库,数据分析和虚拟化等基础设施等工作负载打造的软件生态系统保持兼容,有助于更加有效地挖掘数据的潜在价值。开发人员可以利用行业标准的持久内存编程模式,构建更简单,更强大的应用,确保对数据中心的投资能够适应未来的需求。
持久内存产品可通过不同的方法使用,有些用法对应用来说是透明的。例如,所有持久内存产品都支持存储接口和标准文件 API,就像固态盘 (Solid State Disk, SSD) 一样;或者将持久内存配置成内存模式,系统的持久内存的使用方式和系统内存一样。通过这两种方式使用持久内存非常简单直接,我们不需要对应用做任何更改就可使用,用户除了感受到性能的大幅提升以外,甚至感受不到它们的存在。
但这两种方式也都有各自的弱点,对于第一种方式,因为基本上仍然沿用过去的软件栈,无法完全发挥傲腾持久内存的性能优势;而对于第二种方式,虽然能获得大容量的内存,但是在访问延迟性能方面与内存相比仍有差距,并不能很好地应对对内存延迟要求较高的场景,另外它也无法对数据进行持久化。
要充分发挥傲腾持久内存在性能和持久化方面的强大优势,我们引入了AppDirect模式。在这种模式下,应用可以从用户空间以类似内存的方式直接访问持久内存,不但能够完全发挥持久内存的性能优势,并对数据进行就地持久化。这种模式需要用户对应用做出少量修改。
02 持久内存的特征
每项新技术的兴起总会引发新的思考,持久内存也不例外。构建与开发解决方案时,请考虑持久内存的以下特征:
-
持久内存的性能(吞吐量、延迟和带宽)远高于 NAND,但是稍低于 DRAM。
-
不同于 NAND,持久内存很耐用。其耐用性通常比 NAND 高出多个数量级,可以超过服务器的生命周期。
-
持久内存模块的容量远大于 DRAM模块,并且可以共享相同的内存通道。支持持久内存的应用可原地更新数据,无需对数据进行序列化/反序列化处理。
-
持久内存支持字节寻址(类似于内存)。应用可以只更新所需的数据,不会产生任何读取-修改-写入(read-modify-write,RMW)开销。
-
数据与 CPU 高速缓存保持一致。持久内存可提供直接内存访问 (direct memory access, DMA) 和远程直接内存访问
(remote direct memory access, RDMA) 操作。 -
写入持久内存的数据不会在断电后丢失。
-
权限检查完成后,可以直接从用户空间访问持久内存上的数据。数据访问不经过任何内核代码、文件系统页面缓存(page cache)或中断。
-
持久内存上的数据可立即使用,也就是说:
o 系统通电后即可使用数据。
o 应用不需要花时间来预热高速缓存。
o 它们可在内存映射后立即访问数据。 -
持久内存上的数据不占用 DRAM 空间,除非应用将数据复制到 DRAM,以便更快地访问数据。
-
写入持久内存模块的数据位于系统本地。应用负责在不同系统之间复制数据。
应用开发人员通常会考虑内存驻留(memory-resident)数据结构和存储驻留(storage-resident)数据结构。就数据中心应用而言,开发人员要谨慎地在存储中保持一致的数据结构,即使系统崩溃时也不例外。
这个问题通常可以使用日志技巧(如预写日志)来解决,先将更改写入日志,然后再将其刷新到持久存储中。如果数据修改过程中断,应用可以借助日志中的信息,在重启时完成恢复操作。这样的技巧已存在多年;但正确的实施方法开发难度很大,维护起来也很耗时。开发人员通常要依赖于数据库、编程库和现代文件系统的组合来提供一致性。
即便如此,最终还是要应用开发人员设计一种策略,在运行时和从应用和系统崩溃中恢复系统时确保存储中数据结构的一致性。
03 SNIA NVM编程模型
持久内存可以被应用程序直接访问,并将数据执行就地持久化,因此可以让操作系统支持一种全新的编程模型,在提供媲美内存的高性能的同时,像非易失性存储设备一样持久存储数据。
对开发人员而言幸运的是,在第一代持久内存还处于开发阶段时, Microsoft Windows 和 Linux 设计师、架构师和开发人员已与存储网络工业协会( SNIA)合作定义了一个持久内存编程通用编程模型 SNIA NVM编程模型,如图1所示。
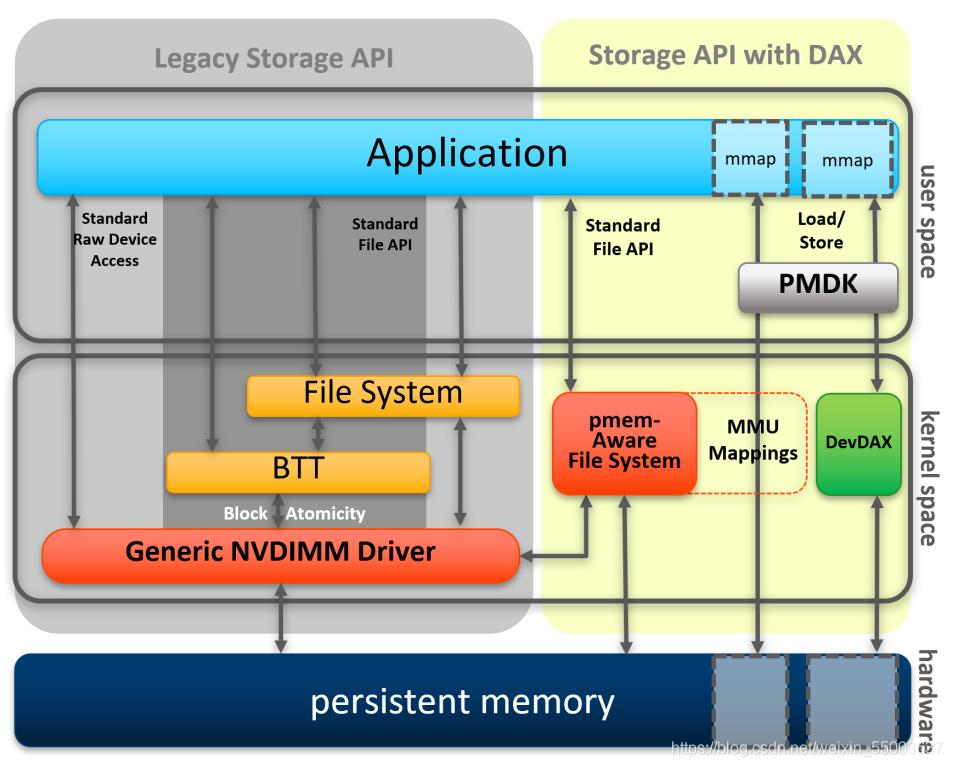
▲图1 SNIA NVM编程模型
持久内存用作块存储
操作系统能够检测是否存在持久内存模块,并将设备驱动程序加载到操作系统的 I/O 子系统中,如图 1左半部分所示。非易失性双列直插式内存模块( NVDIMM)驱动程序具有两项重要功能。
首先,它为系统管理员提供了管理程序接口,用于配置和监控持久内存硬件的状态。其次,它具有类似于存储设备驱动程序的功能。NVDIMM 驱动程序将持久内存作为快速块存储设备呈现给应用程序和操作系统模块。
这意味着应用程序、文件系统、卷管理器和其他存储中间件层可以不经修改,像当前使用存储那样使用持久内存。
持久内存感知型文件系统
操作系统的另一项扩展是支持文件系统感知并针对持久内存进行优化。这类文件系统被称为持久内存感知型文件系统(PMem-Aware File System)。
当前持久内存感知文件系统包括 Linux ext4 和 XFS,以及 Microsoft Windows NTFS。如图 1所示,这些文件系统既可以使用 I/O 子系统中的块驱动程序(如上文所述),也可以绕过 I/O 子系统,直接将持久内存用作可字节寻址加载 / 存储的内存,以最快、最短的路径访问存储在持久内存中的数据。
除了清除了传统的 I/O 操作外,这条路径使得小数据块写入的执行速度比传统块存储设备更快,因为相比之下,传统块存储设备要求文件系统读取设备的原生块大小,修改块,然后将整个数据块写回到设备。这些持久内存感知型文件系统向应用程序提供熟悉的标准文件 API,包括 open、close、 read 和 write 系统调用。这样应用程序可以继续使用熟悉的文件 API,同时发挥持久内存更高性能的优势。
持久内存直接访问
操作系统中的持久内存直接访问特性(在 Linux 和 Windows 中被称为 Direct Access,DAX)使用操作系统所提供的内存映射文件接口,但却能充分利用持久内存的原生功能,既能存储数据,又能用作内存。持久内存可以原生地映射成应用程序内存,因此操作系统无须在易失性主内存中缓存文件。
为了使用 DAX,系统管理员需要在持久内存模块上创建一个文件系统,并将该文件系统挂载在操作系统的文件系统树中。对于 Linux 用户,持久内存设备将显示为 /dev/pmem*设备特殊文件。若要显示持久内存物理设备,系统管理员可以使用ndctl 和 ipmctl 程序。
04 持久内存开发套件PMDK
如前文提到,应用程序可以通过使用内存映射文件的方式来直接访问持久内存,但是这需要用户修改它们的应用程序。为了降低用户修改应用的成本,我们引入了持久内存开发套件(PMDK)。我们将介绍如何利用PMDK来修改应用,使得其高效管理驻留在持久内存中的可字节寻址的数据结构。
PMDK 库基于 SNIA NVM 编程模型构建。它们对该模型进行了不同程度的扩展,一些只是将操作系统提供的原语封装成简单易用的函数,另一些则提供了复杂的数据结构和算法以便用于持久内存。这意味着你要负责决定哪个抽象级别最适合你的用例。
PMDK 经过多年的发展,目前已经包含了大量的开源库,如图2所示。这些库能帮助应用开发人员和系统管理员简化持久内存设备的应用开发和管理。
PMDK 提供两种类型的库:
1) 易失性库:适用于只想利用持久内存大容量这一优势的用户和场景。
2) 持久性库:适用于想实现故障安全持久内存算法的软件。
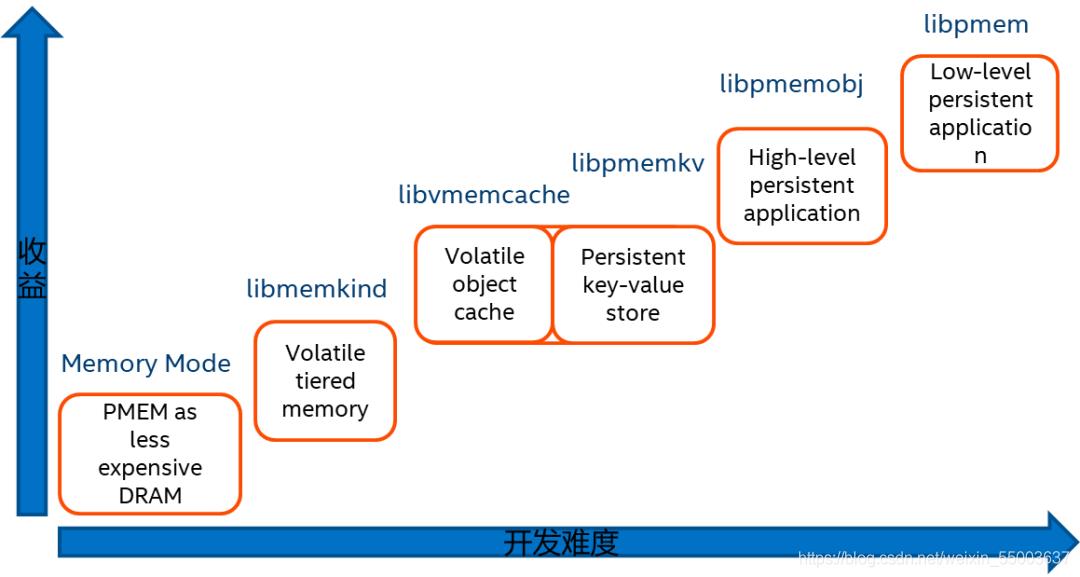
▲ 图 2 PMDK 相关的开发库
libmemkind
libmemkind是构建在 jemalloc 之上的用户可扩展堆管理器,支持控制内存特性以及在不同类型的内存之间对堆进行分区。内存的类型由应用于虚拟地址范围的操作系统内存策略进行定义。在没有用户扩展的情况下, memkind 支持的内存特性包括控制非一致性内存访问( NUMA)和内存页大小特性。
jemalloc 非标准接口经过扩展,支持专门的类型通过 memkind 分区接口从操作系统请求虚拟内存。通过其他 memkind 接口,你可以控制和扩展内存分区特性和分配内存,同时选择已启用的特性。借助 memkind 接口,你可以从支持 PMEM 类型的持久内存创建和控制基于文件支持的内存。
libmemcache
libvmemcache 是一种可嵌入式轻量级内存缓存解决方案,可以通过高效、可扩展的内存映射,充分利用大容量存储,例如支持 DAX的持久内存。libvmemcache 具有自身的独特性:
- 基于区间的内存分配器可避免出现影响大多数内存数据库的碎片化问题,并支持缓存在大多数工作负载中实现极高的空间利用率。
- 缓冲的最近最少使用( LRU)算法将传统的 LRU 双向链表和非阻塞环形缓冲区相结合,可在现代多核 CPU 上实现较高的可扩展性。
- critnib 索引结构可提供高性能,同时非常节省空间。缓存经过调优,能够以最佳方式处理大小相对较大的值,最小为 256 字节,但libvmemcache 最适用于预期数值大小超过 1 KB 的情况。
pmemkv
pmemkv 是为持久内存而优化设计的通用嵌入式本地键值存储。它易于使用,且附带许多不同的语言集成,包括 C、 C++ 和 javascript。
该库还有面向不同存储引擎可插拔的后端插件。尽管设计之初主要是用于支持持久性的应用程序场景,然而它也可用作易失性库。pmemkv 作为单独的项目创建,不仅为 PMDK 中的一套库提供云原生支持,还 提 供 面 向 持 久 内 存 构 建 的 键 值 API。pmemkv 开发人员的主要目标之一是为开源社区创建一个友好的环境,支持他们在PMDK 的帮助下开发新引擎,并将它与其他编程语言集成。
pmemkv API 与大多数键值数据库类似在底层,它实现了多种存储引擎。这些存储引擎都具备出色的灵活性和功能性。每种引擎都具有不同的性能特点,用于解决不同的问题。因此,每种引擎提供的功能各不相同,可以通过以下特性来描述:
- 持久:持久引擎确保修改能够得到保存,而且是断电安全的,而易失性引擎仅在应用程序生命周期内保留其内容。
- 并发:并发引擎确保某些方法(如 get()、 put()、 remove())是线程安全的。
- 键的排序:“排序”(sorted)引擎提供范围查询方法(如 get_above())。pmemkv
与其他键值数据库的不同之处在于,它支持直接访问数据。这意味着从持久内存中读取数据不需要复制到 DRAM 中。
直接访问数据可以显著加快应用程序的速度。在程序仅对数据库中存储的部分数据感兴趣时,这种优势最为明显。在传统方法中,需要将所有数据复制到某个缓冲区中,然后将其返回给应用程序。借助 pmemkv,我们为应用程序提供直接指针,应用程序仅读取所需的数据即可。
凭借其模块化设计、灵活的引擎 API 以及与许多常见云编程语言的集成, pmemkv 已经成为许多云原生软件开发人员的首选。作为一种开源轻量级库,它可以轻松集成到现有应用程序中,并立即发挥持久内存的优势;或者以此为基础针对特定的应用需求进行开发。
libpmemobj
libpmemobj 是一种提供事务对象存储的 C 库,可为持久内存编程提供动态内存分配器、事务和常规功能。libpmemobj 库为需要事务和持久内存管理的应用程序提供了事务性对象,该对象以直接访问( DAX)的方式存储在持久内存中。该库可以解决在持久内存编程时遇到的许多常见的算法和数据问题。
libpmemobj支持应用程序在持久内存感知型文件系统上内存映射文件,提供直接加载 / 存储操作,而无须从块存储设备中对块进行分页。它可以绕过内核,避免上下文切换和中断,并支持应用程序在可字节寻址的持久内存中直接读写。
libpmemobj 库提供便捷的 API,用于轻松管理内存池的创建和访问,避免直接映射和数据同步的复杂性。PMDK 还提供了 pmempool 程序,用于通过命令行来管理内存池。对于持久内存,可以使用 pmemobj_alloc()、 pmemobj_reserve()或 pmemobj_ xreserve() 为临时对象保留内存,其使用方法与 malloc() 相同。
libpmemobj 提供以下 三组API:原子操作 API,保留 / 发布 API,事务 API,可以使用它们来实现数据的持久化。这些API都提供了故障安全原子性和一致性,可减少创建应用程序时的错误,同时确保数据的完整性。
Libpmemobj-cpp
libpmemobj 库面向底层系统软件开发人员和语言创建人员,提供了分配器、事务以及自动操作对象的方法。然而由于它不会修改编译器,导致它的 API 冗长,且包含大量的宏。为了简化持久内存编程,减少错误,英特尔创建了针对 libpmemobj 的高级语言绑定,并将其添加至 PMDK。其中C++语言绑定是libpmemobj-cpp ,也称 libpmemobj++,是一种 C++ 仅头文件(header-only)库,可以使用C++ 的元编程特性,为 libpmemobj 提供更简单且更不易出错的接口。
它通过重复使用 C++程序员熟悉的概念(如智能指针和闭包事务),提供了便捷的 API 来修改结构体和类,而只需对函数进行细微改动,从而支持快速开发持久内存应用程序。该库还附带兼容 STL 的定制数据结构和容器,因此应用程序开发人员无须重新为持久内存开发基本算法。
Libpmem
libpmem 是一种低级 C 库,可针对操作系统呈现的原语提供基本抽象功能。它可以自动检测平台中的功能,选择合适的持久性语义以及面向持久内存优化的内存传输( memcpy())方法。大多数应用程序都至少需要使用这个库的一部分。
libpmem负责处理与持久内存相关的 CPU 指令,以最佳方式将数据复制到持久内存以及文件映射。
libpmem 库包含一些用于内存映射文件的便捷函数。使用这些函数替代操作系统提供的内存映射函数,有如下优点:
- libpmem 可以保证操作系统映射调用的正确参数。
- libpmem 可以检测映射是否为持久内存以及使用 CPU 指令直接刷新是否安全。
- libpmem 也提供多个接口支持以最佳方式复制或清零持久内存区域以对数据进行持久化。
程序员如果只想完全原始地访问持久内存并且无须库提供分配器或事务功能,那么可能想将libpmem 用作开发的基础。
对于大多数程序员而言, libpmem 非常底层,可以获得最大的编程灵活性,但是由此带来的编码和调试的代价相对较高,如果不是必须,应该考虑使用更加上层的库来提高开发效率,降低调试成本。
05 持久内存编程资源
英特尔®傲腾™持久内存介绍:
https://www.intel.cn/content/www/cn/zh/products/memory-storage/optane-dc-persistent-memory.html
SNIA NVM 编程模型规范:
https://www.snia.org/tech_activities/standards/curr_standards/npm
PMDK官方网站:
https://pmem.io/
书籍:持久内存编程中文版
https://item.jd.com/13201774.html
PMDK:
https://github.com/pmem/pmdk
libmemkind:
http://memkind.github.io/memkind/
libvmemcache:
https://github.com/pmem/vmemcache
pmemkv:
https://github.com/pmem/pmemkv
libpmemobj-cpp:
https://github.com/pmem/libpmemobj-cpp
本文作者:胡风华/Cloud Software Architect
胡风华,英特尔傲腾事业部云软件架构师,致力于探索持久内存在云计算,大数据、人工智能和物联网等领域的应用创新。曾在阿里巴巴集团和EMC中国研发中心担任软件架构师和软件工程经理, 在文件系统,分布式存储系统,云计算和大数据等领域有超过15年的工作经验。
6月10日晚19:30-21:00
胡风华老师将做客线上研讨会
英特尔AI实践日第31期 -AI应用与异构内存编程挑战赛总动员

研讨会对傲腾PMDK编程技术进行简单介绍,并探讨在人工智能领域的应用前景。研讨会同时重磅官宣AI 应用与异构内存编程挑战赛,赛事官网:https://opensource.4paradigm.com/ai2021/ 。
通过此次比赛,你将会对人工智能如何在异构内存架构上受益有全新的认识,步入技术新境界。
以上是关于傲腾持久内存如何为数据赋能,加速应用落地?的主要内容,如果未能解决你的问题,请参考以下文章
盘古开源分析:区块链技术重构市场,Filecoin如何赋能落地?
盘古开源丨区块链技术推动时代经济发展,Filecoin如何赋能落地?