论文阅读笔记(七十三)ECCV2020:Faster Person Re-Identification
Posted 橙同学的学习笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读笔记(七十三)ECCV2020:Faster Person Re-Identification相关的知识,希望对你有一定的参考价值。
Introduction
当前ReID方法在检索时速度受到gallery规模和特征编码长度影响:相比之下,计数排序的时间复杂度比快速排序更小;汉明距离的时间复杂度比欧氏距离更小。现有一些快速ReID的方法采用了哈希的思想,采用二进制特征编码,而不是实数编码。而汉明距离对应计算的为二进制特征编码。然而当前基于哈希编码的方法,将特征编码长度设置为了2048,计算成本依然较大。
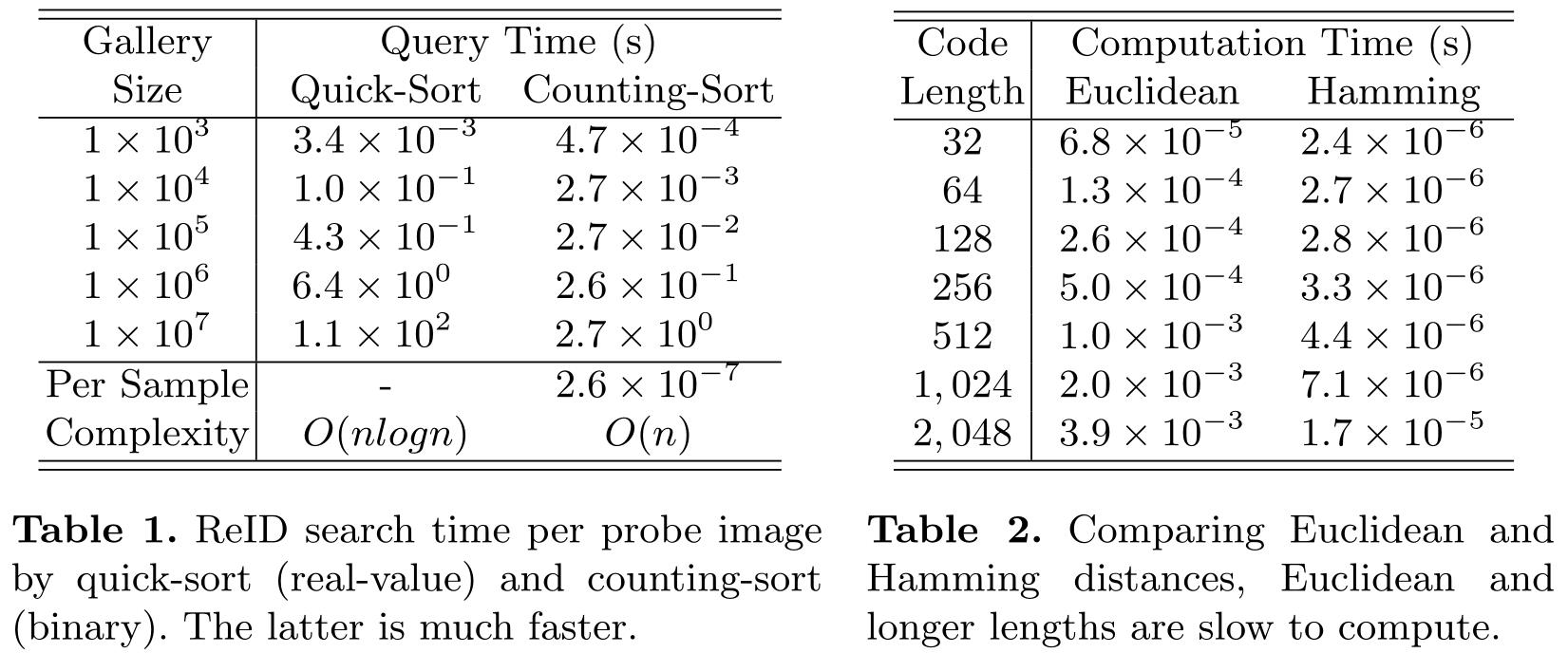
为此,作者提出了Coarse-to-Fine(CtF)搜索策略。CtF采用了更短的编码来对gallery进行粗糙排序,再使用更长的编码来对前若干名候选项进行精细排序。然而,这个思路存在三个困难:① 需要多种长度的编码,若采用多个模型提取将耗时且非最优;② ReID中短特征编码的准确度往往比较差,很难保证粗糙排序的准确性;③ 如何动态设置粗糙排序的距离阈值,来平衡最终的准确率和速度。
为了解决上述的三个问题,作者提出了All-in-One (AiO)框架以及Distance Threshold Optimization (DTO)算法。其中AiO框架结合了金字塔结构,可以用单模型来学习并增强多种长度的特征编码。
Proposed Method
(1) Coarse-to-Fine Search:
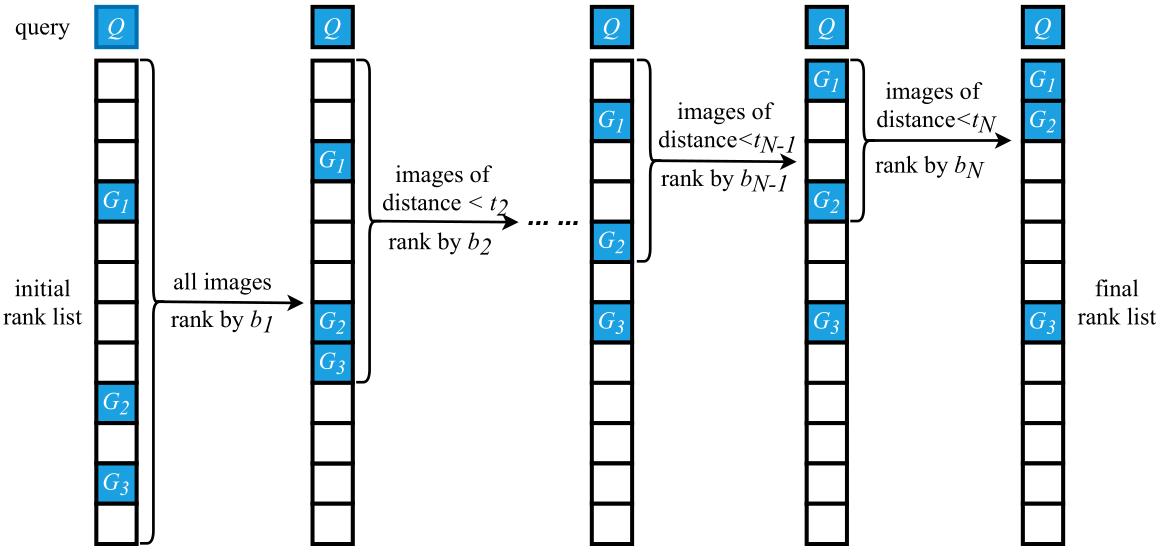
(2) All-in-One Framework:
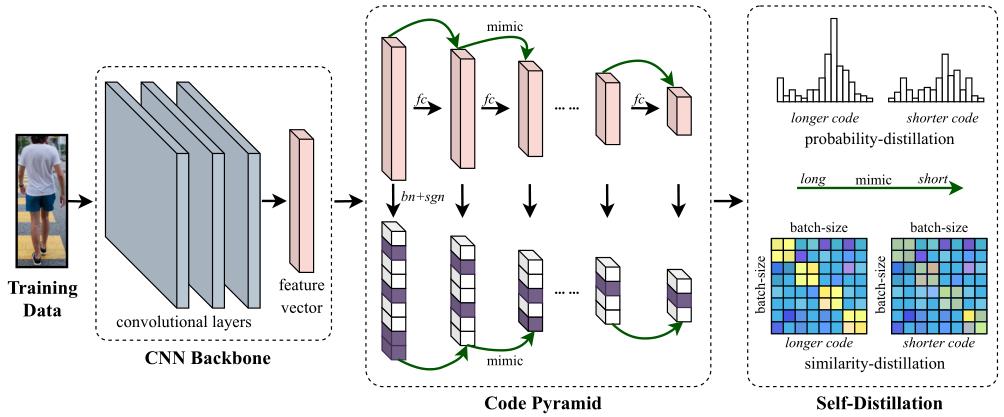
提取到的实数特征编码转为二进制特征编码的方法:通过BN层使得其均值为0,再转为0/1值(原文我并没有理解的很清晰,我的理解是小于0的值设置为0,大于0的值设置为1)。
为了增强长特征的判别能力,作者采用了自蒸馏(self-distillation)学习方法。 自蒸馏不需要额外的teacher模型,这里包含了概率蒸馏和相似性蒸馏。其中概率蒸馏为:
![]()
其中Lce为交叉熵损失,这个公式可以理解为长特征的特征分布作为ground truth,让短特征的特征分布向其靠近。其中相似性蒸馏为:
![]()
其中G表示汉明距离,l表示特征长度,这个公式理解为:让不同长度的特征拥有相似的距离度量。
(3) Distance Threshold Optimization:
高效的查询要满足两个条件:高准确率和快速。其中快速的前提是粗查询得到的候选项要少,高准确率的前提是候选项中正样本要多。要满足这两者,需要平衡好候选项数量的阈值。为此,作者设计了DTO。
作者首先计算了precision(P)和recall(R),再融合为一个指标:
![]()
其中TP表示候选项中正样本数,FP表示候选项中负样本数,FN表示未纳入候选项的正样本数。
由于TP/FP/FN三个指标没法进行优化,因此引入了概率密度函数PDF和累积分布函数CDF:
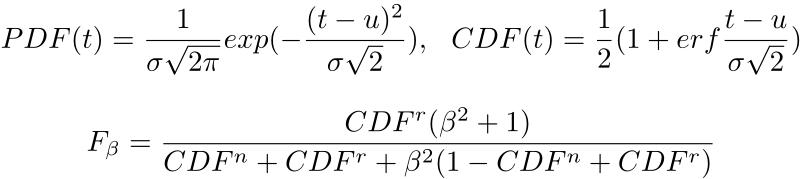
公式中的u和σ通过验证集评估固定,DTO算法如下:【这部分Fβ的计算没理解】

Experiments
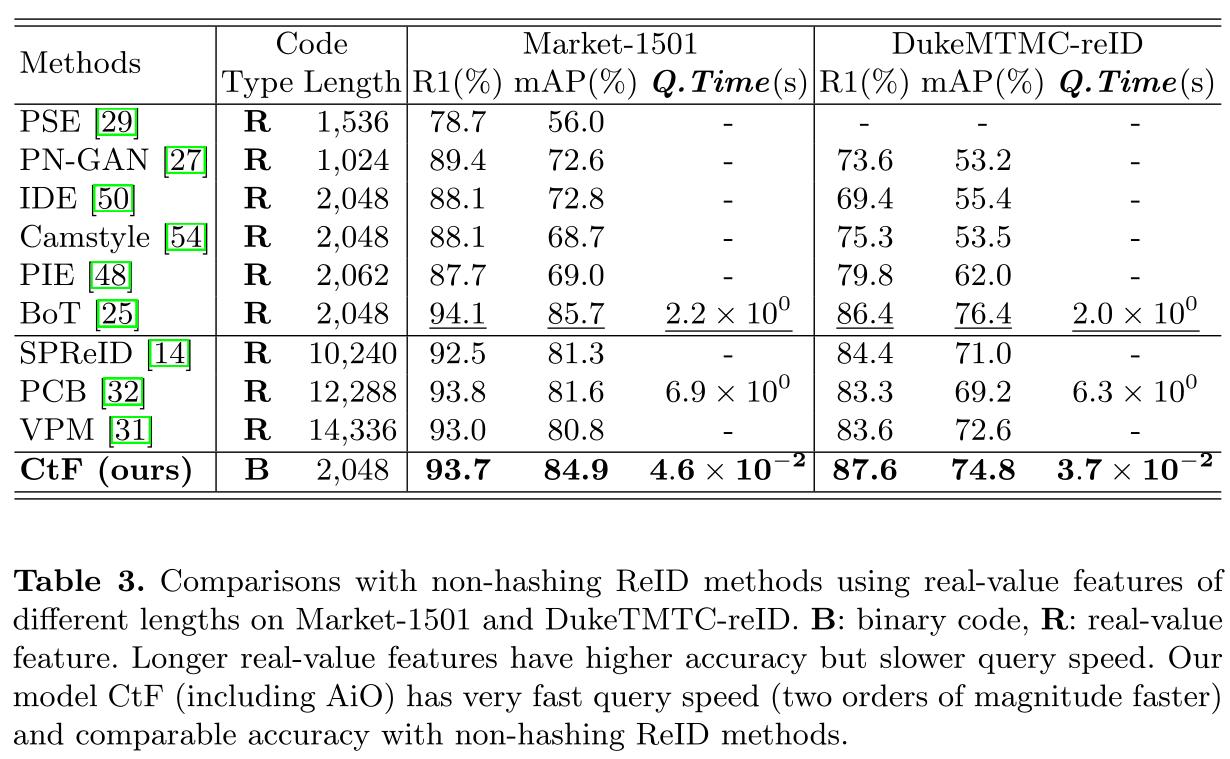

以上是关于论文阅读笔记(七十三)ECCV2020:Faster Person Re-Identification的主要内容,如果未能解决你的问题,请参考以下文章
论文阅读笔记(七十)CVPR2021:Combined Depth Space based Architecture Search For Person Re-identification
论文阅读笔记(七十六)TIP2021:Cross-Modal Knowledge Adaptation for Language-Based Person Search
DETR:Facebook提出基于Transformer的目标检测新范式,性能媲美Faster RCNN | ECCV 2020 Oral