数栈技术分享:一文带你了解Flink jmtm启动过程和资源分配
Posted 数栈DTinsight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数栈技术分享:一文带你了解Flink jmtm启动过程和资源分配相关的知识,希望对你有一定的参考价值。

一、JM启动过程
1、从日志角度分析启动流程
1)client生成jobGraph
详情请参考:
https://www.bilibili.com/video/BV13K4y1P7ri
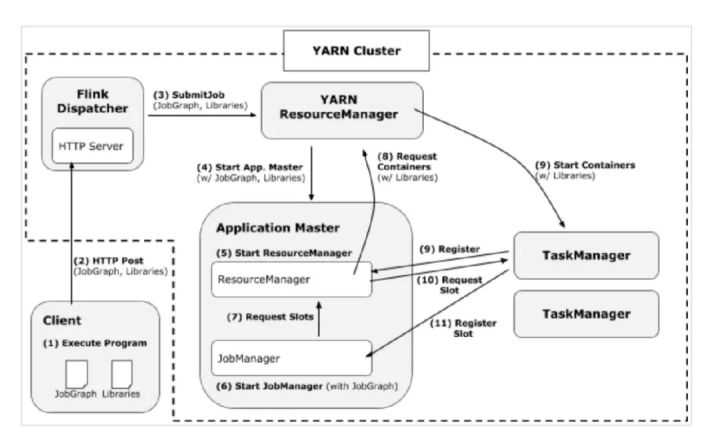
2)Yarn RM接收到请求(和yarn交互不重点分析)
3)在被分配的节点上的工作目录下启动launch_container.sh
4)在perJob模式下,最终调用的是YarnJobClusterEntrypoint
5)初始化相关运行环境,打印软件版本、运行环境、命令行参数、classpath 等信息
 6)加载flink配置文件、初始化文件系统、启动各种内部服务(RpcService、HAService、BlobServer、HeartbeatServices、MetricRegistry、ExecutionGraphStore 等)
6)加载flink配置文件、初始化文件系统、启动各种内部服务(RpcService、HAService、BlobServer、HeartbeatServices、MetricRegistry、ExecutionGraphStore 等)
7)启动Flink资源管理核心组件ResourceManager(包含 YarnResourceManager 和 SlotManager 两个子组件)
8)启动Dispatcher加载JobGraph 文件、并启动JobManager
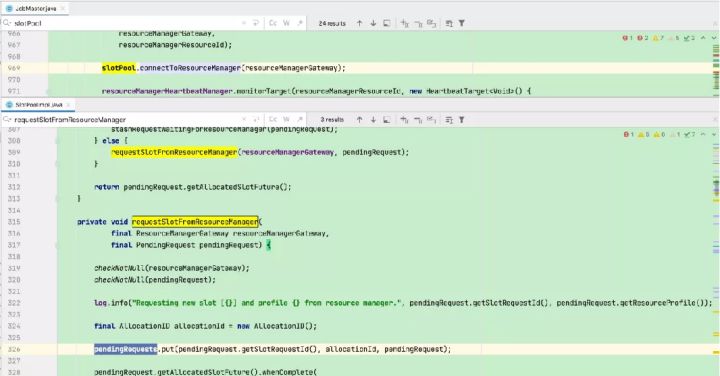
9)JobManager开始执行ExecutionGraph,向 ResourceManager申请资源
 10)Flink ResourceManager 接收到新分配的 Container 资源后,准备好 TaskManager 启动上下文
10)Flink ResourceManager 接收到新分配的 Container 资源后,准备好 TaskManager 启动上下文
11)TaskManager 进程加载并运行 YarnTaskExecutorRunner(Flink TaskManager入口类),初始化流程完成后启动 TaskExecutor(负责执行Task相关操作)
12)TaskExecutor向ResourceManager注册,向SlotManager汇报自己的 Slot 资源与状态
13)JobManager向TaskExecutor提交task,TaskExecutor启动新的线程运行Task
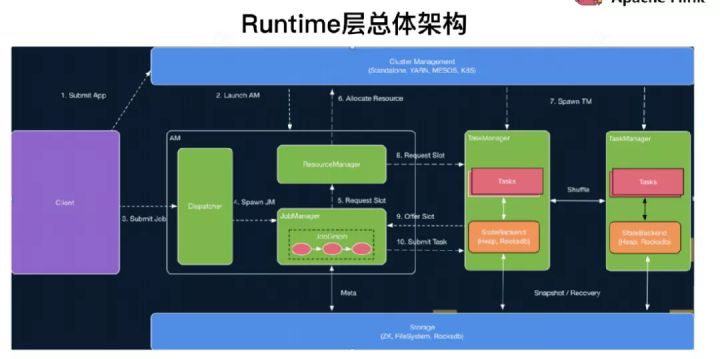
 2、整体流程分析
2、整体流程分析
![]()
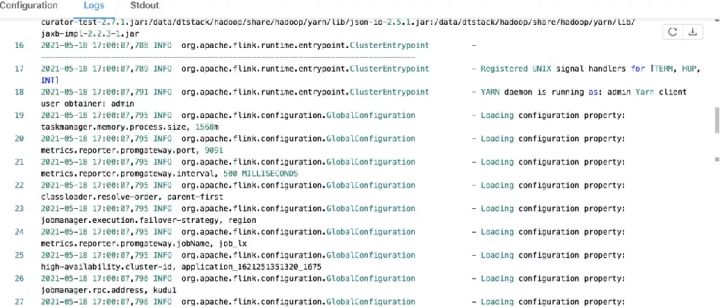
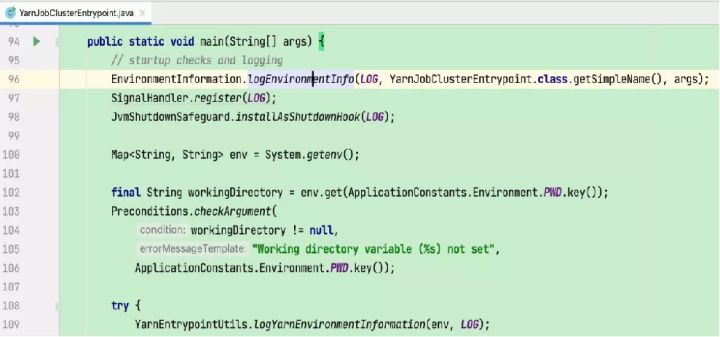
1)输出各软件版本及运行环境信息、命令行参数项、classpath等信息
2)注册处理各种SIGNAL的handler:记录到日志
3)注册JVM关闭保障的shutdown hook:避免JVM退出时被其他shutdown hook阻塞
4)打印YARN运行环境信息:用户名
5)从运行目录中加载flink conf
3、AM启动过程
1)创建并启动各类内部服务(包括RpcService、HAService、BlobServer、HeartbeatServices、MetricRegistry、ExecutionGraphStore等)
2)将RPC address和port更新到flink conf配置
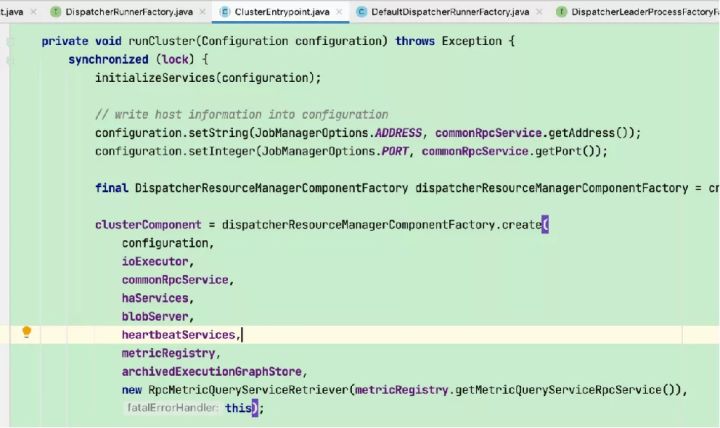
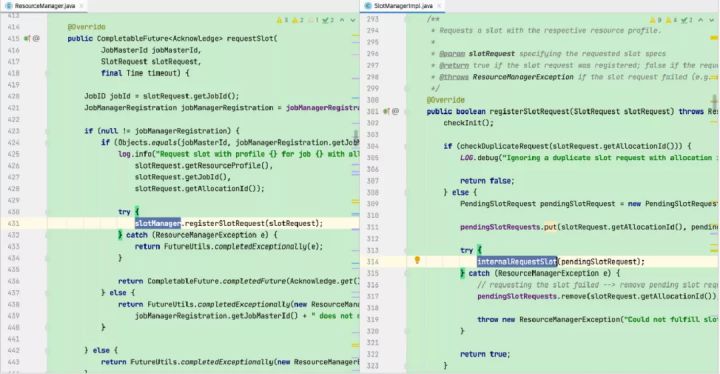
3)创建并启动resourceManager对象(Flink资源管理核心组件,包含YarnResourceManager和SlotManager两个子组件,YarnResourceManager负责外部资源管理,与YARN RM建立通信并保持心跳,申请或释放TaskManager资源,注销应用等;SlotManager则负责内部资源管理,维护全部Slot信息和状态)
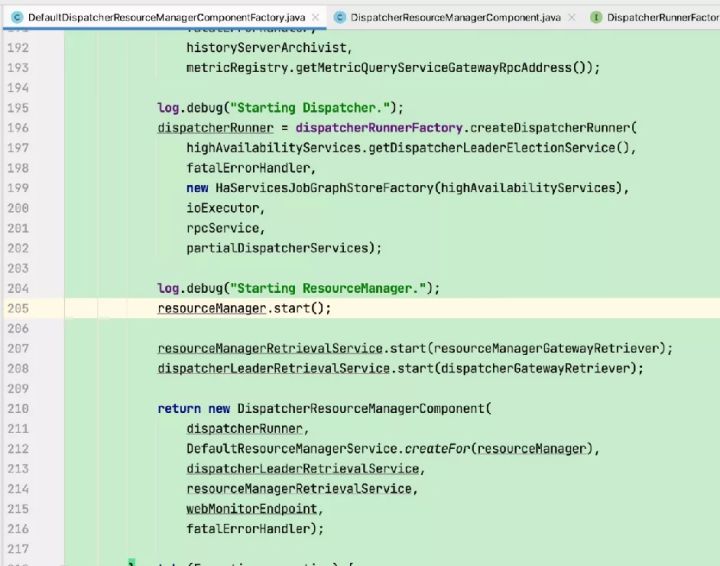
4)创建并启动dispatcher(负责接收用户提供的作业,并且负责为这个新提交的作业拉起一个新的 JobManager)及相关服务(包括REST endpoint等)并加载JobGraph。

![]()
二、JM资源分配
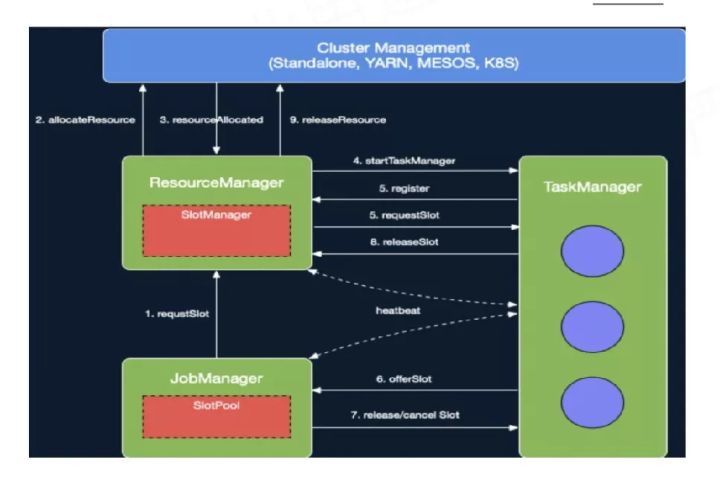
JobManager开始执行ExecutionGraph,向ResourceManager申请资源。
ResourceManager将资源请求加入等待请求队列,并通过心跳向YARN RM申请新的Container资源来启动TaskManager进程。
后续流程如果有空闲Slot资源,SlotManager将其分配给等待请求队列中匹配的请求,不用再通过YarnResourceManager申请新的TaskManager。
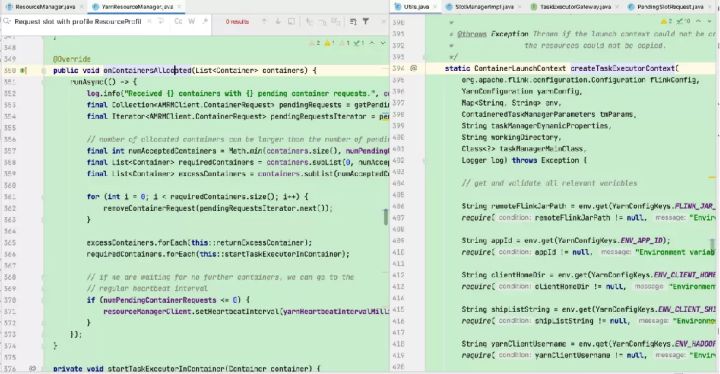
Flink ResourceManager接收到新分配的Container资源后,准备好TaskManager启动上下文(ContainerLauncherContext,生成TaskManager配置并上传至分布式存储,配置其他依赖和环境变量等)。
然后向YARN NM申请启动TaskManager进程,YARN NM启动Container的流程与AM Container启动流程基本类似。
三、TM启动过程
输出各软件版本及运行环境信息、命令行参数项、classpath等信息
注册处理各种SIGNAL的handler:记录到日志
注册JVM关闭保障的shutdown hook:避免JVM退出时被其他shutdown hook阻塞
加载flink配置文件、初始化文件系统、启动各种内部服务(RpcService、HAService、BlobServer、HeartbeatServices、MetricRegistry等)
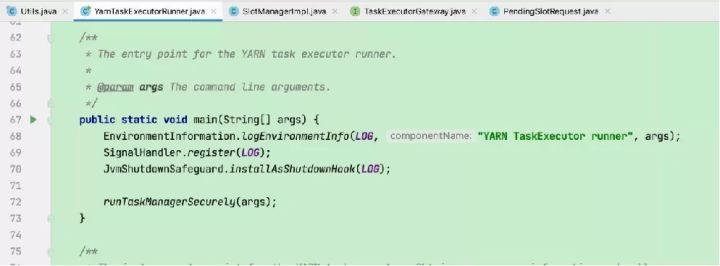
启动tm后就可以通过RPC接收远程调用,submitTask就是接收任务的服务。
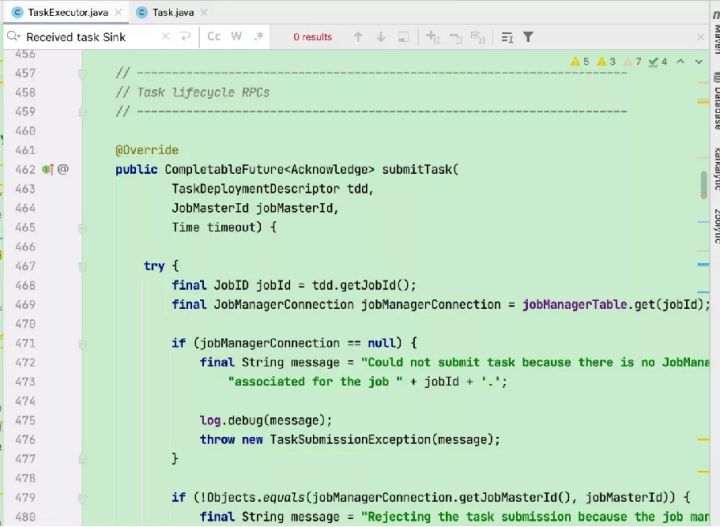
回到在JM端启动scheduler后,就开始调度Execution,在Execution的deploy()方法中通过rpc调用TM的submitTask接口。

交互流程图如下:
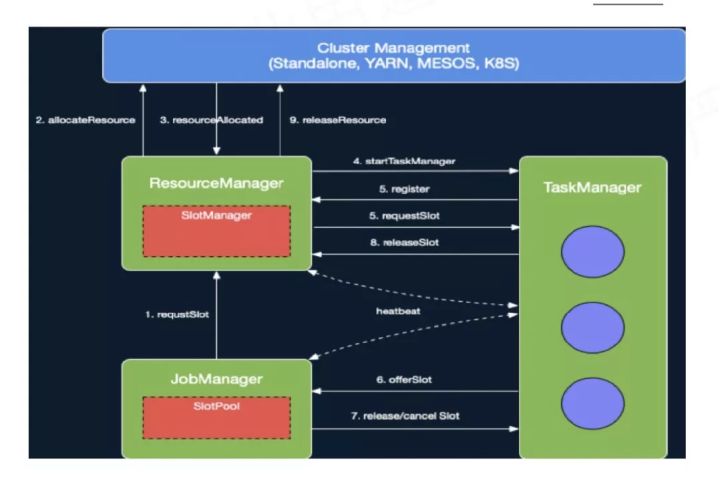
当submitTask收到请求后加载jobInformation和taskInformation文件,初始化jobInformation和taskInformation,然后构造Task,启动Task线程,最终调用AbstractInvokable.invoke方法。

![]()
- invokable.invoke( )将根据nameOfInvokableClass的不同调度不同的任务,包括批任务、Source任务、Sink任务、流任务
- DataSourceTask:Kafka Source
- StreamTask:中间算子
- DataSinkTask:Kafka Sink

这里以StreamTask例分析
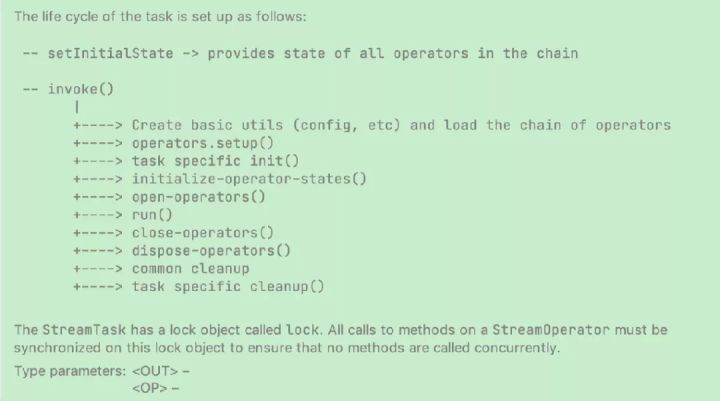
- 初始化、run、close
- 初始化:创建状态后端、operator配置、特殊task初始化、恢复算子的状态、richfunction open
- run:执行task,处理record并发往下游
- close:关闭和清理操作
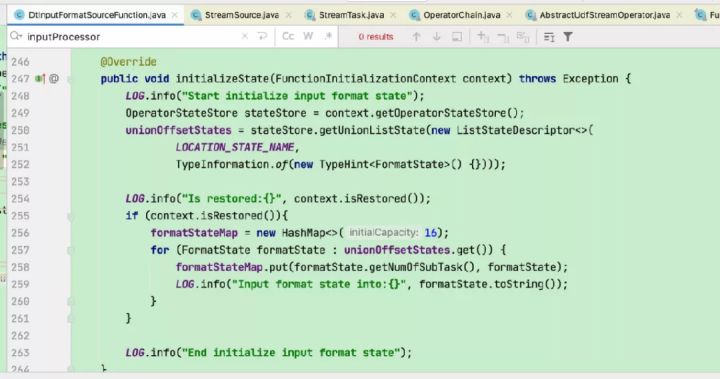
这里以flinkX中的代码为例:
会被invoke()中的initialize-operator-states()执行并调用到DtInputFormatSourceFunction的initializeState方法恢复状态。
这里以flinkX中的代码为例:
会被invoke()中的open-operators()执行并调用到DtInputFormatSourceFunction的open方法恢复状态做一些初始化工作。
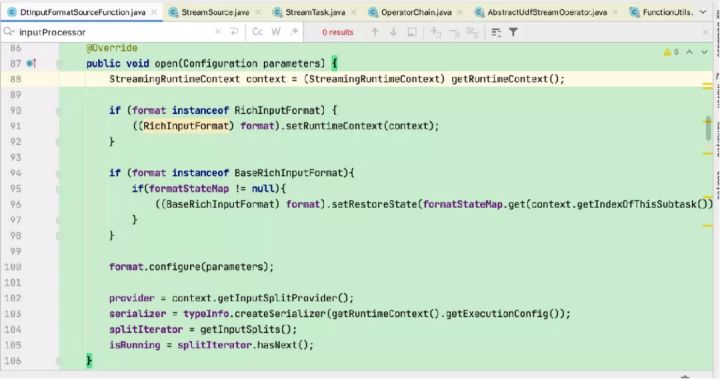
这里以flinkX中的代码为例:
会被invoke()中的run()执行并调用到DtInputFormatSourceFunction的run读取数据并往下游发送。
 经过上面分析,任务已经启动,并等待数据流动。
经过上面分析,任务已经启动,并等待数据流动。
相关参考:
https://zhuanlan.zhihu.com/p/87132673https://zhuanlan.zhihu.com/p/87132673
数栈是云原生—站式数据中台PaaS,我们在github和gitee上有一个有趣的开源项目:FlinkX,FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,也可以采集实时变化的数据,是全域、异构、批流一体的数据同步引擎。大家喜欢的话请给我们点个star!star!star!
github开源项目:https://github.com/DTStack/flinkx
gitee开源项目:https://gitee.com/dtstack_dev_0/flinkx
以上是关于数栈技术分享:一文带你了解Flink jmtm启动过程和资源分配的主要内容,如果未能解决你的问题,请参考以下文章