数栈技术分享:如何使用数栈进行数据采集?
Posted 数栈DTinsight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数栈技术分享:如何使用数栈进行数据采集?相关的知识,希望对你有一定的参考价值。
数栈是云原生—站式数据中台PaaS,我们在github和gitee上有一个有趣的开源项目:FlinkX,FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,也可以采集实时变化的数据,是全域、异构、批流一体的数据同步引擎。大家喜欢的话请给我们点个star!star!star!
github开源项目:https://github.com/DTStack/flinkx
gitee开源项目:https://gitee.com/dtstack_dev_0/flinkx
一、从哪里采集数据
我们谈大数据、用大数据、让数据产生价值的前提是,我们首先要有数据。
我们讲数据中台“存”、“通”、“用”,首先就是“存”,我们要将数据放到中台里,以前是放在数据仓库里,在“存”的基础上,我们会将不同来源不同格式的数据进行梳理、把一个个数据孤岛打通,数据资源形成数据资产,然后根据用户的具体场景,进行数据应用。
数据的产生不是凭空而来的,袋鼠云数栈提供离线数据同步采集和实时数据同步采集两种方式,帮助用户高效地将散落在各处的数据资源采集,存放在一起,用工具化的方式,进行“全域”数据采集,为构建数据中台奠定基础。
二、怎么采集数据
1、离线数据同步采集
可视化配置的数据同步任务如下图所示:

![]()
数栈的数据同步工具FlinkX,在不同存储系统中起到“桥梁”的作用,是数据中台的基础核心功能,支持多种不同的异构存储系统数据(mysql,Server,Oracle等),插件化架构可随时支持更多的新数据源需求,底层基于Flink分布式架构,支持大容量、高并发同步,相比单点同步性能更好,稳定性更高。
该方案满足分钟(5分钟)、小时、天等多种级别的同步需求。
袋鼠云数栈数据同步界面如下图所示:
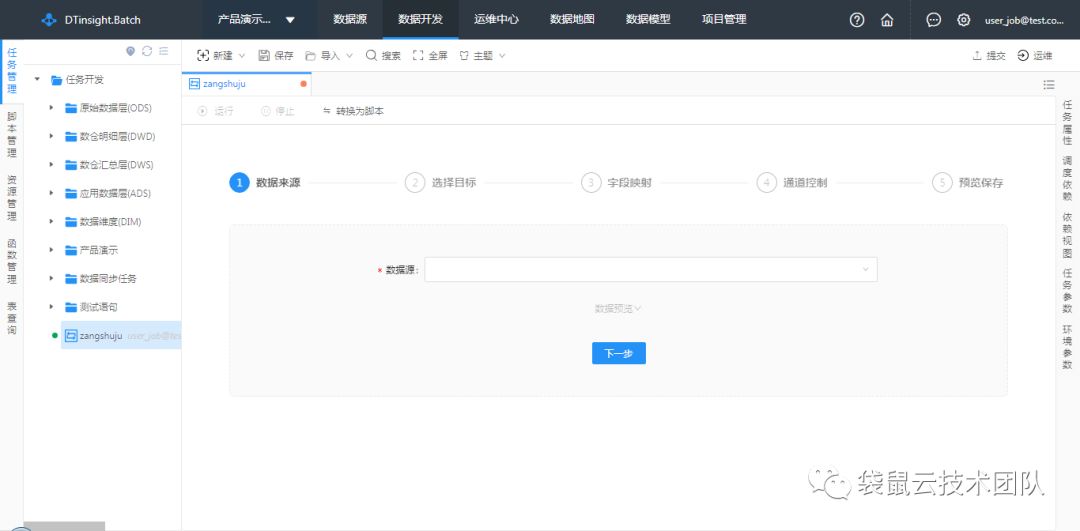
![]()
数据同步模块FlinkX是在各个存储单元之间执行数据交换的管道。为了在数据中台进行大规模数据集的挖掘与计算,通常的做法是在任务执行前将数据传输至数据中台,并在任务执行结束后将计算结果传输至外部存储单元(例如MySQL等应用数据库)。
数据集成的作用如下图所示:
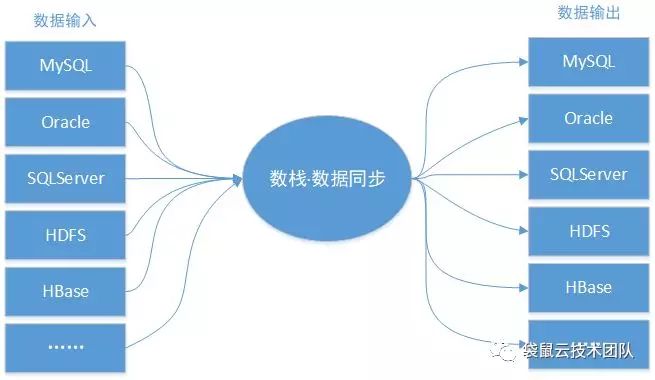
![]()
数据同步模块的特性包括以下几方面:
1)丰富的数据源支持
数据同步模块可对MySQL、Oracle、SQLServer、PostgreSQL、DB2、HDFS(Textfile/Parquet/ORC)、Hive、HBase、FTP、ElasticSearch、MaxCompute、ElasticSearch、Redis、MongoDB、CarbonData等数据源,支持对这些数据源进行读取或写入数据。使用时仅需配置数据源的连接信息(例如填写Oracle数据库的JDBC URL、用户名、密码等信息),再配置对应的数据同步任务即可。
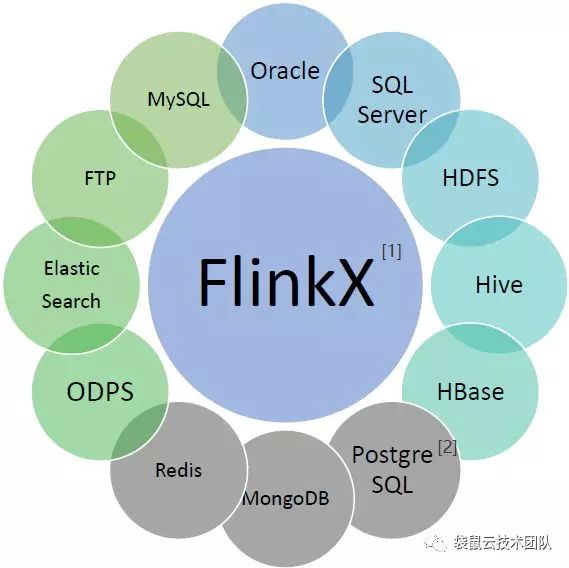
![]()
2)分布式系统架构
数据同步模块在系统架构上采用先进的分布式系统架构,可实现多个节点并发读取、写入数据,可极大的提升数据同步的吞吐量,相比Sqoop、Kettle等开源数据同步方案,数据吞吐能力更高、配套功能更完善。
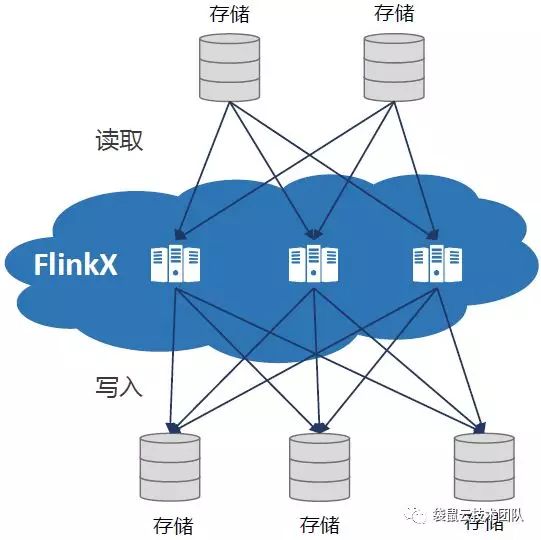
![]()
3)向导/自定义配置模式
向导模式:
特点是便捷、简单,可视化字段映射,快速完成同步任务配置。可通过向导模式完成同步任务的创建与配置,主要包括同步任务选择源库源表、目标库目标表、配置字段映射、配置同步速度等。

![]()
脚本模式:
特点是全能、高效,可深度调优,支持全部数据源。需通过编写JSON脚本的方式完成配置过程。
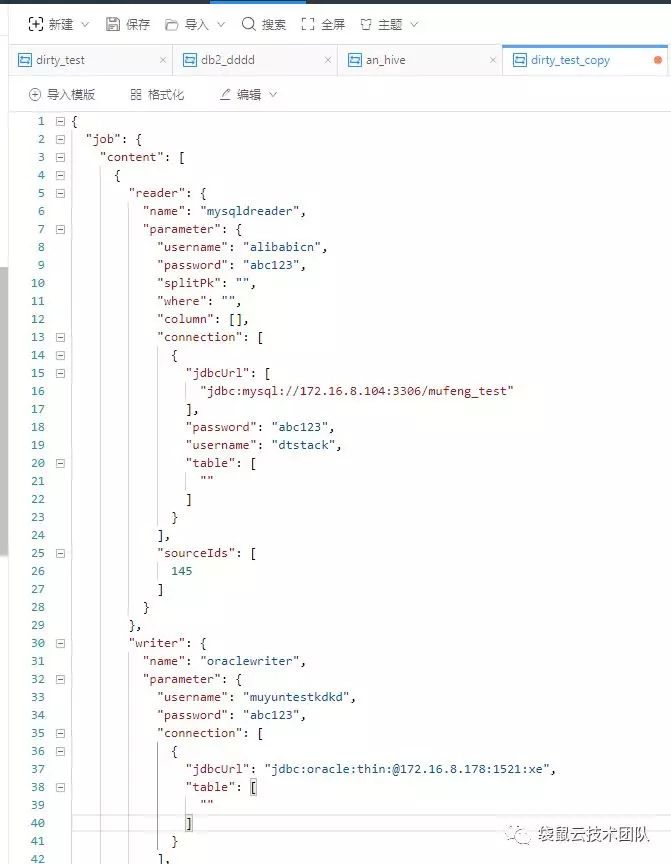
![]()
4)调度与依赖的配置
在实际的数据生产过程中,数据同步任务通常是数据处理链路的第一个任务和最后一个任务,分别承担“从业务系统抽取数据”和“将结果数据写出”的职责。【离线计算-开发套件】支持对同步任务配置依赖关系,约束同步任务与其他任务的执行先后顺序。
数据同步任务通常是周期执行的,每天、每周、每小时或分钟级(5分钟)执行一次,【离线计算-开发套件】支持对同步任务配置循环周期,实现同步任务的定期执行,详细的调度与依赖配置功能请参考数据开发:构建数据分析逻辑一节。
5)全量/增量同步
从业务系统读取数据的过程中,为了最小化对业务系统的影响,通常需要进行数据的增量同步。在源数据库表中具备数据变更时间字段的情况下,【离线计算-开发套件】支持对关系型数据库进行增量数据同步,用户仅需输入相应的数据过滤语句即可实现。
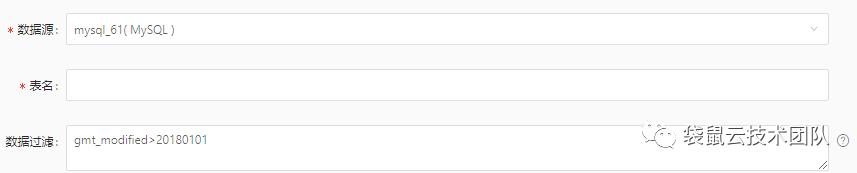
![]()
6)整库同步
整库同步是帮助提升用户效率、降低用户使用成本的一种快捷工具,它可以快速把一个MySQL数据库内所有表一并上传到数据平台中,节省大量初始化精力。假设数据库有100张表,您原本可能需要配置100次数据同步任务,但有了整库上传便可以一次性完成(要求数据库的表设计具备较高的规范性)。
在整库同步配置中,用户可批量选择待同步的表,并配置全量/增量,同步批次等信息。同时支持自定义表名、字段类型等配置,在方便快捷的基础上实现高度灵活性。

![]()
7)分库分表(MySQL)、FTP多路径同步
数据同步模块可以支持关系型数据库分库分表模式下的数据同步,用户仅需在页面上选择多张表、多个数据库即可(要求每张表的结构相同)。
除了关系型数据库分库分表模式之外,还支持一个任务从多个FTP路径,读取多个文件,减少同步任务配置的重复性工作。
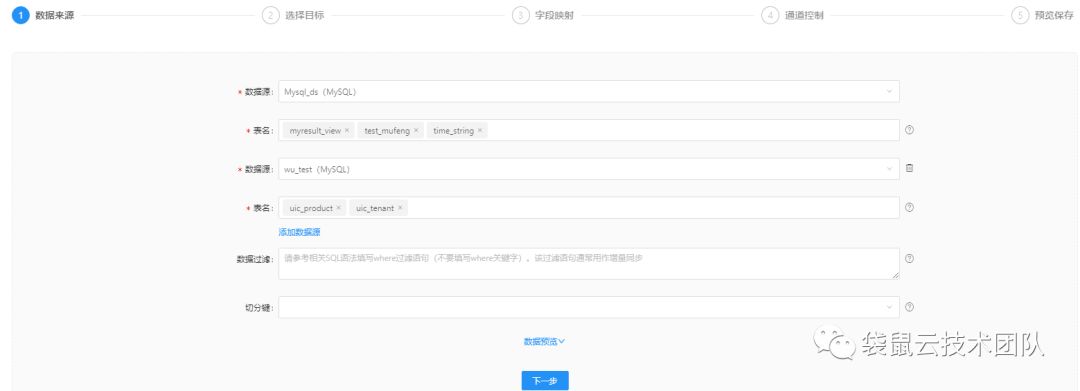
![]()
8)同步速度的控制
据进行初始化的同步时,往往有大量历史数据需要同步至中台,需要提高数据读取的速度,当业务数据库的运行压力较大时,为了减轻数据库的压力,需要降低数据读写的速度。
数据同步模块支持同步速度控制,通过设置同步速率上限来调整,此参数需根据硬件配置和数据量来调整,用户根据业务需求选择设定的值。

![]()
2、实时数据同步采集

![]()
上图是实时数据流同步架构,说明如下:
1)Oracle和SQLServer数据源:需要用户方自购并部署OGG实时采集工具,实时采集Oracle redo log数据,再通过数栈DTinsightStream产品可视化配置将数据打到Kafka,数据就被实时归档或实时消费。
2)MySQL数据源:数栈DTinsightStream产品已经集成Canal数据采集工具,实时采集MySQL binlog数据,直接通过可视化配置将数据打到Kafka,数据就被实时归档或实时消费。
3)日志类数据源:数栈DTinsightStream产品针对日志类实时采集模块底层基于jLogstash组件实现(相比开源的jLogstash进行了分布式改造),可基于YARN进行分布式资源调度,直接通过可视化配置将数据打到Kafka,数据就被实时归档或实时消费。

![]()
实时采集模块在WEB端的配置非常便捷且灵活,类似离线数据同步任务,可支持向导和脚本2种配置模式。以MySQL实时采集为例,用户仅需在页面配置数据源、表和部分过滤条件即可。
除了配置功能外,实时采集任务在运行时,系统也可对输入、输出的数据量进行实时监控并告警。
以上是关于数栈技术分享:如何使用数栈进行数据采集?的主要内容,如果未能解决你的问题,请参考以下文章
数栈技术分享:开源·数栈-扩展FlinkSQL实现流与维表的join