论文阅读Chinese Relation Extraction with Multi-Grained Information and External Linguistic Knowledge[A
Posted Harukaze
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读Chinese Relation Extraction with Multi-Grained Information and External Linguistic Knowledge[A相关的知识,希望对你有一定的参考价值。
论文地址:https://www.aclweb.org/anthology/P19-1430.pdf
代码地址:https://github.com/ thunlp/Chinese_NRE
Abstract
中文关系抽取是利用基于字符或基于单词输入的神经网络进行的,现有的方法大多存在切分错误和多义歧义。针对这一问题,本文提出了一种基于多粒度multi-grained语言信息和外部语言知识的中文关系抽取框架(MG-lattice)。在这个框架中,(1)我们将word-level信息整合到字符序列character sequence输入中,以避免分割错误(2) 我们还利用外部语言知识对多义词的多种意义进行建模,以减轻多义词的歧义。在三个不同领域的真实数据集上的实验表明,与其他基线相比,该模型具有一致性和显著的优越性以及鲁棒性。
1 Introduction
虽然NRE没有必要进行特征工程,但是他们忽略了输入的不同语言粒度对模型的影响,特别是对中文RE。传统上,根据粒度的不同,现有的中文检索方法可分为基于字符的检索和基于单词的检索。
对于基于字符的RE,它将每个输入句子看作一个字符序列。这种方法的缺点是不能充分利用词级信息,比基于词的方法获取的特征少。对于基于词的RE,首先要进行分词。然后,导出一个单词序列,并将其输入到神经网络模型中。然而,基于词的模型的性能会受到切分质量的显著影响。
For example, as shown in Fig 1, the Chinese sentence “达尔文研究所有杜鹃 (Darwin studies all the cuckoos)” has two entities, which are “达 尔文 (Darwin)” and “杜鹃 (cuckoos)”, and the relation between them is Study. In this case, the correct segmentation is “达尔文 (Darwin) / 研究 (studies) / 所有 (all the) / 杜鹃 (cuckoos)” . Nevertheless, semantics of the sentence could become entirely different as the segmentation changes. If the segmentation is “达尔文 (In Darwin) / 研究所 (institute) / 有 (there are) / 杜鹃 (cuckoos)”, the meaning of the sentence becomes ’there are cuckoos in Darwin institute’ and the relation between “达尔文 (Darwin)” and “杜鹃 (cuckoos)” turns into Ownership, which is wrong. Hence, neither character-based methods nor word-based methods can sufficiently exploit the semantic information in data. Worse still, this problem becomes severer when datasets is finely annotated, which are scarce in number. Obviously, to discover highlevel entity relationships from plain texts, we need the assistance of comprehensive information with various granularity.
此外,数据集中存在大量多义词这一事实也是现有RE模型所忽视的一个问题,限制了模型挖掘深层语义特征的能力。例如,这个词"杜鹃” 有两种不同的感觉,杜鹃花和杜鹃花’cuckoos’ and ’azaleas’。但是,如果没有外部知识的帮助,很难从纯文本中学习两种感官的信息。因此,外部语言知识的引入将对NRE模型有很大的帮助。
本文提出了一种综合利用内部信息和外部知识的统一模型&多粒度格框架(MG-lattice)(1) 该模型采用基于格的结构,将词级特征动态集成到基于字符的方法中。因此,它可以利用输入的多粒度信息而不受分割错误的影响(2) 此外,为了缓解多义词的歧义问题,该模型利用了HowNet(Dong和Dong,2003)这一外部知识库对多义词进行人工标注。然后,在训练阶段自动选择词义,从而充分利用数据中的语义信息,提高训练效果。
实验在三个人工标记的RE数据集上进行。结果表明,我们的模型明显优于现有的多种方法,在不同的数据集上实现了最新的结果。
本文借助于Dong和Dong(2003)提出的HowNet(知网)概念知识库,利用语义层次的信息对具有相关词义的汉语进行标注。此外,我们的工作中还使用了开源的知网API(Qi et al.,2019)。
3 Methodology
给定一个汉语句子和其中的两个标记实体,汉语关系抽取的任务就是提取两个实体之间的语义关系。在本节中,我们将详细介绍用于中文关系抽取的MG格模型。如图2所示,模型可以从三个方面进行介绍:
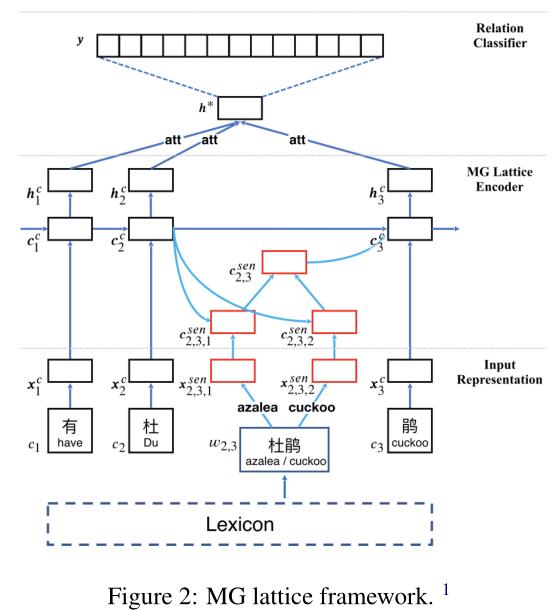
Input Representation.
给定一个以两个目标实体为输入的汉语句子,这部分代表句子中的每个单词和字符。然后该模型可以同时利用字级和字级信息。
MG Lattice Encoder.
将外部知识融入词义消歧中,利用格结构LSTM网络为每个输入实例构造分布式表示。
Relation Classifier.
在学习了隐藏状态后,采用字符级机制进行特征融合。然后将最后的句子表示形式输入到softmax分类器中进行关系预测。
3.1 Input Representation
该模型的输入是一个带有两个标记实体的汉语句子$s$。为了利用多粒度信息,我们在句子中同时表示字符和单词。
3.1.1 Character-level Representation
我们的模型将基于字符的句子作为直接输入,即将每个输入句子看作一个字符序列。给定一个由$M$个字符组成的句子$s={c_1,…,c_M}$,我们首先将每个字符$c_i$映射到一个$d^c$维向量,表示为$x_i^{ce}\\in \\cal{R}^{d^c}$,通过Skip-gram模型(Mikolov et al,2013)。
此外,我们利用位置嵌入来指定实体对,实体对定义为当前角色到头部和尾部实体的相对距离(Zeng等人,2014)。具体地,从第$i$个字符$ci_$到两个标记实体的相对距离分别表示为$p^1_i$和$p^2_i$。我们计算$p^1_i$as如下:
$p_i^1 = \\left \\{ \\begin{array}{lr} i-b^1 & i<b^1,\\\\ 0& b^1\\leq i \\leq e^1 ,\\\\ i-e^1 & i>e^1,\\end{array} \\right$
where $b^1$ and $e^1$ are the start and end indices of the head entity. The computation of $p^2_i$ is similar to Eq. 1. Then, $p^1_i$ and $p^2_i$ are transformed into two corresponding vectors, denoted as $x^{p_1}_i \\in R^{d^p}$ and $x^{p_2}_i \\in R^{d^p}$ , by looking up a position embedding table.
Finally, the input representation for character $c_i$, denoted as $x^c_i∈ R^d(d = d^c+ 2×d^p)$, is concatenated by character embedding $x^{ce}_i$, position embeddings $x^{p_1}_i$ and $x^{p_2}_i$:
$x_i^c=[x_i^{ce};x_i^{p_1};x_i^{p_2}]$
Then, the representation of characters $xc= {x^c_1, ...,x^c_M}$ will be directly fed into our model.
3.1.2 Word-level Representation
虽然我们的模型以字符序列作为直接输入,但是为了充分捕捉单词级的特征,它还需要输入句子中所有潜在单词的信息。在这里,一个潜在的单词是任何字符的子序列,它与在分段的大原始文本上构建的词典$\\cal{D}$中的单词相匹配。设$w_{b,e}$为从第$b$个字符到第$e$个字符的子序列。为了表示$w_{b,e}$,我们使用word2vec(Mikolov等人,2013)将其转换为实值向量$x_{b,e}^w\\in \\cal{R}^{d^w}$。
然而,word2vec方法将每个单词映射到一个单独的嵌入,忽略了许多单词具有多种意义的事实。为了解决这个问题,我们将知网作为一个外部知识库加入到我们的模型中来表示词义而不是单词。
因此,给定一个单词$w_{b,e}$,我们首先通过检索知网获得它的所有$K$个词义。用$Sense(w_{b,e})$表示$w_{b,e}$的意义集,然后通过SAT模型(Niu等人,2017年)将每个$sen_k^{(w_{b,e})}\\in Sense(w_{b,e})$转换为实值向量$x_{b,e,k}^{sen}\\in \\cal{R}^{d^{sen}}$。SAT模型是在Skip-gram的基础上建立的,它可以联合学习单词和意义的表示。最后,$w_{b,e}$的表示是一个向量集,表示为$x_{b,e}=\\{x_{b,e,1}^{sen},...,x_{b,e,K}^{sen}\\}$。
3.2 Encoder
编码器的直接输入是一个字符序列,以及字典D中的所有潜在单词。经过训练,编码器的输出是一个输入语句的隐藏状态向量。我们介绍了两种编码策略,包括基本点阵LSTM和多颗粒点阵(MG点阵)LSTM。the basic lattice LSTM and the multi-graind lattice (MG lattice) LSTM。
3.2.1 Basic Lattice LSTM Encoder
LSTM公式略,LSTM的输入以字符为单位$x_j^c->c_j^c$
给定一个单词$w_{b,e}$,在与外部词典$\\cal{D}$匹配的输入句子中,可以得到如下表示:
$x_{b,e}=e^w(w_{b,e})$
where $b$ and $e$ denotes the start and the end of the word, and $e^w$ is the lookup table . Under this circumstance, the computation of $c^c_j$ incorporates word-level representation $x_{b,e}^w$ to construct the basic lattice LSTM encoder. Further, a word cell $c_{b,e}^w$ is used to represent the memory cell state of $x_{b,e}^w$. The computation of $c_{b,e}^w$ is:
$i_{b,e}^w=\\sigma (W_ix_{b,e}^w+U_ih_b^c+b_i)$
$f_{b,e}^w=\\sigma (W_fx_{b,e}^w+U_fh_b^c+b_f)$
$\\tilde{c}_{b,e}^w=tanh(W_cx_{b,e}^w+U_ch_b^c+b_c)$
$c_{b,e}^w=f_{b,e}\\odots c_b^c+i_{b,e}^w\\odots \\tilde{c}_{b,e}^w$
where $i^w_{b,e}$ and $f_{b,e}^w$ serve as a set of word-level input and forget gates.
The cell state of the $e$-th character will be calculated by incorporating the information of all the words that end in index $e$, which is $w^{b,e}$ with $b\\in \\{ b^{\'}|w_{b^{\'},e}\\in \\cal{D}\\}$. To control the contribution of each word, an extra gate $i_{b,e}^c$ is used:
$i_{b,e}^c=\\sigma (Wx_e^c+Uc_{b,e}^w+b^l)$ (9)
Then the cell value of the $e$-th character is computed by:
$c_e^c=\\sum_{b\\in \\{b^{\'}|w_{b^{\'},e}\\in \\cal{D} \\}}\\alpga_{b,e}^c\\odots c_{b,e}^w+\\alpha_e^c\\odots \\tilde{c}_e^c$
where $\\alpha_{b,e}^c$ and $\\alpha_e^c$ are normalization factors, setting the sum to 1:
$\\alpha_{b,e}^c=\\frac{exp(i_{b,e}^c)}{exp(i_e^c)+\\sum_{b^{\'}\\in \\{ b^{\'\'}|w_{b^{\'\'},e}\\in \\cal{D}\\}}exp(i_{b^{\'},e}^c) }$
$\\alpha_{e}^c=\\frac{exp(i_{e}^c)}{exp(i_e^c)+\\sum_{b^{\'}\\in \\{ b^{\'\'}|w_{b^{\'\'},e}\\in \\cal{D}\\}}exp(i_{b^{\'},e}^c) }$ (12)
Finally, we use Eq. 5(LSTM输出) to compute the final hidden state vectors $h^c_j$ for each character of the sequence. This structure is also used in Zhang and Yang (2018).
3.2.2 MG Lattice LSTM Encoder
Although the basic lattice encoder can explicitly显示地 leverages利用 character and word information, it could not fully consider the ambiguity歧义 of Chinese. For instance, as shown in Figure 2, the word $w_{2,3}$(杜 鹃) has two senses: $sen^{(w_{2,3})}_1$ represents ’azalea’ and $sen(w_{2,3})_2$ represents ’cuckoo’, but there is only one representation for $w_{2,3}$ in the basic lattice encoder, which is $x^w_{2,3}$.
针对这一不足,我们通过在模型中加入感知级sense-level路径作为外部知识来改进模型。因此,一个更全面的词汇comprehensive lexicon将被构建。如3.1所述,the representation of the $k$-th sense of the word $w_{b,e}$ is $x_{b,e,k}^{sen}$.
For each word $w_{b,e}$ which matches the lexicon $\\cal{D}$, we will take all its sense representations into the calculation. The computation of the $k$-th sense of word $w_{b,e}$ is:
$i_{b,e,k}^{sen}=\\sigma (W_ix_{b,e,k}^{sen}+U_ih_b^c+b_i)$
$f_{b,e,k}^{sen}=\\sigma (W_fx_{b,e,k}^{sen}+U_fh_b^c+b_f)$
$\\tilde{c}_{b,e,k}^{sen}=tanh(W_cx_{b,e,k}^{sen}+U_ch_b^c+b_c)$
$c_{b,e,k}^{sen}=f_{b,e,k}^{sen}\\odots c_b^c+i_{b,e,k}^{sen}\\odots \\tilde{c}_{b,e,k}^{sen}$
where $c_{b,e,k}^{sen}$ represents the memory cell of the $k$-th sense of the word $w_{b,e}$. Then all the senses are merged into a comprehensive representation to compute the memory cell of $w_{b,e}$, which is denoted as $c_{b,e}^{sen}$:
$c_{b,e}^{sen}=\\sum_k \\alpha_{b,e,k}^{sen}\\odots c_{b,e,k}^{sen}$
$\\alpha_{b,e,k}^{sen}=\\frac{exp(i_{b,e,k}^{sen})}{\\sum_{k^{\'}}^Kexp(i_{b,e,k^{\'}}^{sen})}$
where is $i_{b,e,k}^{sen}$ is an extra gate to control the contribution of the $k$-th sense, and is computed similar as Eq. 9.
在这种情况下,所有意义层的细胞状态都将被纳入词的表示$c_{b,e}^{sen}$中,从而更好地表示多义词。然后,类似于等式9-12,以索引e结尾的单词的所有循环路径将流入当前单元格$c_e^c$:
$c_e^c=\\sum_{b\\in b^{\'}|w_{b^{\'},e}\\in \\cal{D}}\\alpha_{b,e}^{sen}\\odots c_{b,e}^{sen}+\\alpha_e^c\\odots \\tilde{c}_e^c$
Finally, the hidden state $h$ are still computed by Eq. 5 and then sent to the relation classifier.
3.3 Relation Classifier
After the hidden state of an instance $h ∈ R^{d^h×M}$ is learnt, we first adopt a character-level attention mechanism to merge $h$ into a sentence-level feature vector, denoted as $h^{∗}∈ R^{d^h}$. Here, $d^h$ indicates the dimension of the hidden state and $M$ is the sequence length. Then, the final sentence representation $h^{∗}$ is fed into a softmax classifier to compute the confidence of each relation.
The representation $h^{∗}$ of the sentence is computed as a weighted sum of all character feature vectors in $h$:
$H=tanh(h)$
$\\alpha =softmax(w^TH)$
$h^{*}=h\\alpha^T$
where $w ∈ R^{d^h}$ is a trained parameter and $\\alpha ∈ R^M$ is the weight vector of $h$.
To compute the conditional probability of each relation, the feature vector $h^{∗}$ of sentence $S$ is fed into a softmax classifier:
$o=Wh^{*}+b$
$p(y|S)=softmax(o)$
where $W ∈ R^{Y×d^h}$ is the transformation matrix and $b ∈ R^Y$ is a bias vector. $Y$ indicates the total number of relation types, and $y$ is the estimated probability for each type. This mechanism is also applied to (Zhou et al., 2016).
Finally, given all ($T$) training examples $(S^{(i)}, y^{(i)})$, we define the objective function using cross-entropy as follows:
$J(\\theta)=\\sum_{i=1}^Tlog p(y^{(i)}|S^{(i)},\\theta)$
where $θ$ indicates all parameters of our model.
为了避免隐藏单元的共同适应cp-adaptation,我们通过在前向传播过程中随机移除网络中的特征检测器feature detectors,在LSTM层上应用了dropout(Hinton et al.,2012)。
4 Experiments
在本节中,我们在三个手动标记的数据集上进行了一系列实验。与其他模型相比,我们的模型显示了优越性和有效性。此外,概括,泛化generalization 是我们模型的另一个优点,因为有五个语料库用于构建这三个数据集,它们在主题和写作方式上完全不同。实验安排如下:
(1) 首先,通过与基于字符和基于单词的模型的比较,研究了该模型结合字符级和单词级信息的能力;
(2) 然后重点研究了感知表征的影响,在三种不同的基于格的模型之间进行了实验;(2) Then we focus on the impact of sense representation, carrying out experiments among three different kinds of lattice-based models;
(3) 最后,我们在关系抽取任务上与其他模型进行了比较。
4.1 Datasets and Experimental Settings
Datasets.
We carry out our experiments on three different datasets, including Chinese SanWen (Xu et al., 2017), ACE 2005 Chinese corpus (LDC2006T06) and FinRE.
在837篇中文文献中,中文三文数据集包含9种关系类型,其中695篇用于训练,84篇用于测试,58篇用于验证。ACE2005数据集是从新闻专线、广播和网络日志中收集的,包含8023个关系事实和18个关系子类型。我们随机选取75%的样本进行训练,剩下的样本用于评估。
为了使测试域更加多样化,我们对新浪财经2647条财经新闻中的FinRE数据集进行了手工标注,分别用13486、3727和1489个关系实例进行训练、测试和验证。FinRE包含44个可分辨关系,包括一个特殊关系NA,表示标记的实体对之间没有关系。
Evaluation Metrics
实验中采用了多种标准的评价指标,包括查全率曲线、F1评分、前N预测精度(P@N)曲线下面积(AUC)。通过综合评价,可以从多个角度对模型进行评价。the precision-recall curve, F1-score, Precision at top N predictions (P@N) and area under the curve (AUC).
Parameter Settings.
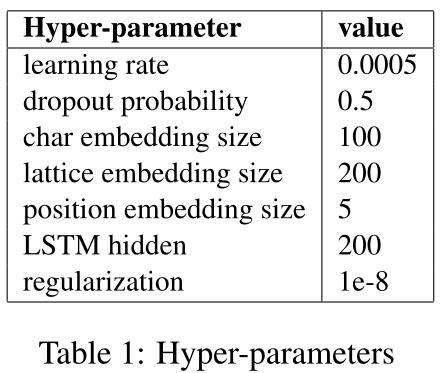
我们通过在验证数据集上进行网格搜索来调整模型的参数。利用网格搜索选择最优学习率$λ$ 对于Adam优化器(Kingma和Ba,2014),在$\\{0.0001,0.0005,0.001,0.005,\\}$和位置嵌入$d_p$ in ${5,10,15,20}$。表1显示了我们实验中最佳超参数的值。利用验证数据集上的评估结果,通过提前停止选择最佳模型。对于其他参数,我们遵循经验设置,因为它们对模型的整体性能影响很小。
4.2 Effect of Lattice Encoder.
在这一部分中,我们主要关注编码器层的效果。如表2所示,我们在所有数据集上对基于字符、基于单词和基于格的模型进行了实验。基于字和基于字符的基线是通过用双向LSTM替换晶格编码器来实现的The word-based and character-based baselines are implemented by replacing the lattice encoder with a bidirectional LSTM.。此外,字符和单词特征分别添加到这两个基线中,以便它们可以同时使用字符和单词信息。对于单词基线For word baseline,我们使用一个额外的CNN/LSTM来学习每个单词字符的隐藏状态(char-CNN/LSTM)。对于char基线For char baseline,bichar和softword(当前字符所在的单词word in which the current character is located)被用作word-level特征,以改进字符表示。
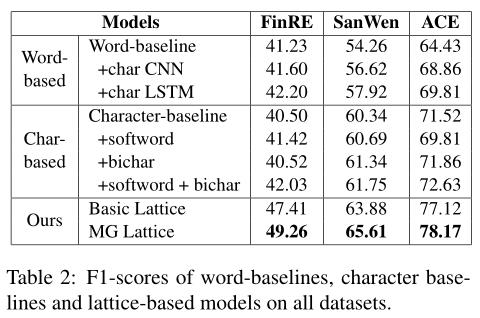
基于格的方法包括两种基于格的模型,它们都可以显式地利用字符和单词信息。基本格使用3.2.1中提到的编码器,它可以动态地将字级信息合并到字符序列中。对于MG格,每个意义嵌入sense embedding将被用来构造一条独立的意义路径。因此,不仅有单词信息,而且还有感觉信息流入细胞状态。Hence, there is not only word information, but also sense information flowing into cell states.
Results of word-based model.
在自动分词的情况下,基于词的模型在三个数据集上的基线得分分别为41.23%、54.26%和64.43%。在基线模型中加入字符CNN(character CNN),F1得分分别提高到41.6%、56.62%和68.86%。与字符CNN(character CNN)相比,字符LSTM表示的F1得分略高,分别为42.2%、57.92%和69.81%。结果表明,字符信息对基于单词模型的性能有促进作用,但F1分数的提高不显著。
Results of character-based model.
对于字符基线,与基于单词的方法相比,它给出了更高的F1分数。通过增加软词特征(soft word feature),在FinRE和SanWen数据集上F1得分略有提高。通过添加字符二元图character-bigram也可以得到类似的结果。此外,在基于字符character-based的模型中,两种单词特征的组合产生了最好的F1分数,分别为42.03%、61.75%和72.63%。
Results of lattice-based model.
虽然我们在基线中采用了多种策略来组合字符和单词信息,但是基于格的模型仍然显著优于它们。基本格点模型将三个数据集的F1得分分别从42.2%提高到47.35%,61.75%提高到63.88%,72.63%提高到77.12%。实验结果表明,该模型具有良好的字符和词序信息挖掘能力。下一小节将介绍基于格点模型的比较和分析。
4.3 Effect of Word Sense Representations
在这一部分中,我们将通过使用不同策略的意义层信息来研究词义表征的效果study the effect of word sense representations by utilizing sense-level information with different strategies.。因此,我们在实验中使用了三种基于晶格的模型。首先,基本格模型使用word2vec(Mikolov等人,2013)来训练单词嵌入,它不考虑词义信息no word sense【没有多义词这一理解】。然后,我们引入了基本格 the basic lattice ((SAT)模型作为比较,通过sense信息对预先训练的单词嵌入进行了改进(Niu等人,2017)。此外,MG晶格模型使用意义嵌入sense embeddings来建立独立的路径,并动态地选择合适的意义。

结果P@N 表3展示了词义表征的有效性the effectiveness of word sense representations。由于在词嵌入中考虑了语义信息thanks to considering sense information into word embeddings,基本格(SAT)比原基本格模型具有更好的性能。虽然基本格(SAT)模型总体效果较好,但前100个实例的精度仍低于lattice basic模型。与其他两种模型相比,MG-lattice模型在各项性能指标上均显示出优越性P@N,平均成绩最好。
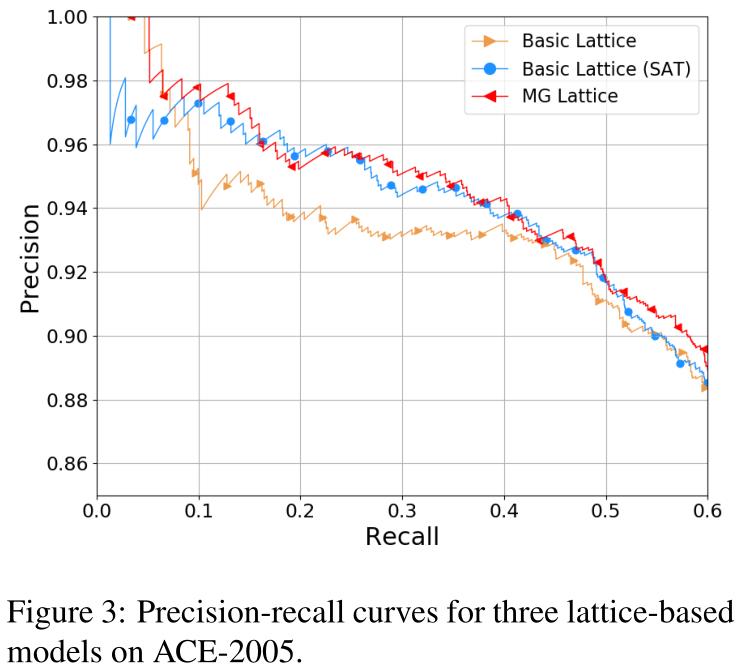
为了更直观地比较和分析所有基于格的模型lattice-based models 的有效性,我们以图3中的ACE-2005数据集的精确召回曲线为例进行了报告。虽然基本格(SAT)模型的整体性能优于原基本格模型,但在召回率较低的情况下,准确率仍然较低,这与表3中的结果相符。这种情况表明,仅在预训练阶段考虑多个感官会给词的表示增加噪声This situation indicates that considering multiple senses only in the pre-trained stage would add noise to the word representations.。换言之,词汇表征倾向于使用语料库中常用的词义,当当前词的正确词义不是常用词义时,会干扰模型In other words, the word representation tends to favor the commonly used senses in the corpora, which will disturb the model when the correct sense of the current word is not the common one.。然而,MG晶格模型成功地避免了这个问题,在曲线的所有部分都给出了最佳的性能。这一结果表明,MG晶格模型不受噪声信息的显著影响,因为它可以在不同的上下文中动态地选择感知路径。虽然MG-lattice模型在整体结果上显示出有效性和鲁棒性,但值得注意的是改进是有限的。这种情况表明,多粒度信息的利用率还有待提高。更详细的讨论见第5节。
4.4 Final Results
在本节中,我们将比较基于格点的模型与各种提出的方法的性能。我们选择的建议模型如下:
CNN(Zeng et al.,2014) proposes a CNN model for relation extraction.
PCNN (Zeng et al., 2015) puts forward a piecewise CNN model with multi-instance learning.
BLSTM (Zhang and Wang, 2015) proposes a bidrectional LSTM model for relation extraction.
Att-BLSTM (Zhou et al., 2016) is a bidrectional LSTM model with word-level attention mechanism.
PCNN+ATT (Lin et al., 2016) improves PCNN model with selective attention mechanism.
我们在上述五个模型的基于字符和基于单词的版本上进行了实验。结果表明,在所有的数据集上,基于字符的版本比基于单词的版本对所有模型都有更好的性能。因此,在下面的实验中,我们只使用五个选定模型的基于字符的版本。
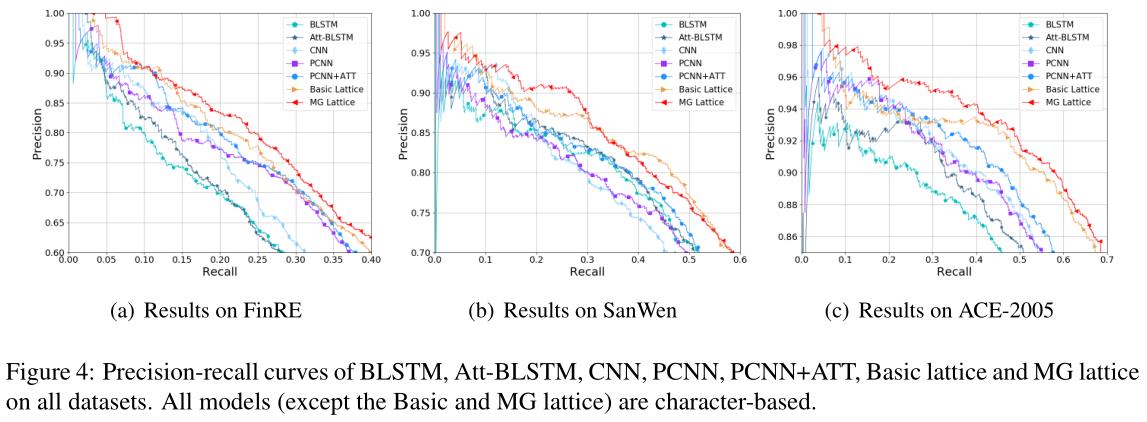
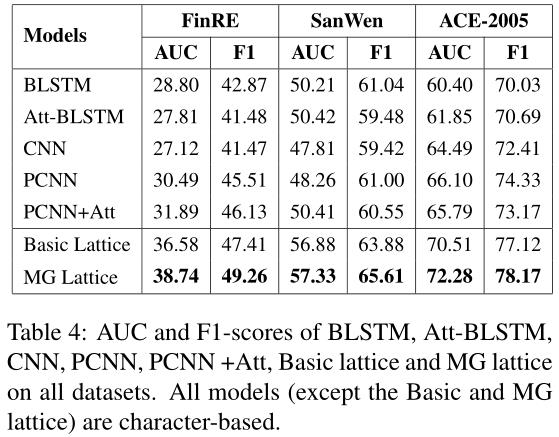
为了综合比较和分析,我们在图4中给出了精确召回曲线,在表4中给出了F1得分和AUC。从结果中我们可以观察到:(1)基于格的模型在不同领域的数据集上显著优于其他提出的模型。由于多义信息的存在Thanks to the polysemy information,MG-lattice模型在所有模型中表现最好,在汉语关系抽取任务中显示出优越性和有效性。结果表明,语义层次的信息sense-level information能够增强从文本中获取深层语义信息deep semantic information的能力(2) 在数据集FinRE上,基本格模型和MG格模型之间的差距变小。造成这种现象的原因是财务报告语言是从财务报告语料库中构建的,财务报告语言往往严谨、明确(3) 相比之下,PCNN和PCNN+ATTmodels perform worse in theSanWen和ACE数据集。原因是这两个数据集中实体对之间存在位置重叠,使得PCNN无法充分利用分段机制。结果表明,基于PCNN的方法对数据集的形式有很高的依赖性。相比之下,我们的模型在所有三个数据集上都表现出健壮性。
5 Conclusion and Future Work
本文提出了用于中文关系抽取的MG格模型。该模型将词级信息word-level融入到字符序列character sequence中,探索深层语义特征,并通过引入外部语言知识避免了一词多义的歧义问题。我们在各种数据集上综合评估了我们的模型。结果表明,我们的模型显著优于其他提出的方法,在所有数据集上都达到了最新的结果。
在未来,我们将尝试改善MG晶格利用多粒度信息的能力we will attempt to improve the ability of the MG Lattice to utilize multi-grained information.。虽然我们在工作中使用了单词、意义sense和字符信息,但是更多的信息可以被整合到MG格中。从粗到细,义素层次的信息在直观上是有价值的。在这里,义素是词义的最小语义单位,它的信息可能有助于模型探索更深层次的语义特征sememe-level information can be intuitively valuable. Here, sememe is the minimum semantic unit of word sense, whose information may potentially assist the model to explore deeper semantic features. 从小到大From fine to coarse,,句子和段落应该被考虑在内,这样就可以捕捉到上下文信息的边界范围。
Tips:English has also ambiguity.
以上是关于论文阅读Chinese Relation Extraction with Multi-Grained Information and External Linguistic Knowledge[A的主要内容,如果未能解决你的问题,请参考以下文章
论文阅读笔记:Multi-Labeled Relation Extraction with Attentive Capsule Network(AAAI-2019)
论文阅读:Beyond Short-Term Snippet: Video Relation Detection with Spatio-Temporal Global Contex
[论文阅读] StrokeGAN+: Few-Shot Semi-Supervised Chinese Font Generation with Stroke Encoding
论文阅读 | Coherent Comments Generation for Chinese Articles with a Graph-to-Sequence Model
Person ReIDLearning Relation and Topology for Occluded Person Re-Identification 论文解读
Person ReIDLearning Relation and Topology for Occluded Person Re-Identification 论文解读