[论文阅读] StrokeGAN+: Few-Shot Semi-Supervised Chinese Font Generation with Stroke Encoding
Posted 心有所向,日复一日,必有精进
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[论文阅读] StrokeGAN+: Few-Shot Semi-Supervised Chinese Font Generation with Stroke Encoding相关的知识,希望对你有一定的参考价值。
pre
title: StrokeGAN+: Few-Shot Semi-Supervised Chinese Font Generation with Stroke Encoding
accepted: arxiv 2022
paper: https://arxiv.org/abs/2211.06198
code: none
关键词:中文字体生成、笔画编码、few-shot(400+samples)、半监督
阅读理由:一看标题+号,再看实验部分对比的模型,还没投出去,确认下作者,首先就觉得会比较水,但竟然能写到14页,学习下怎么水的,也锻炼下阅读速度。
针对问题
当前方法大多基于GAN,而GAN又常会有模式坍塌的问题,因而提出这个one-bit的笔画编码跟半监督体系,即使用少数成对数据作为半监督信息,来分别探索汉字的局部跟全局结构信息,这是受笔画跟字符能直接体现汉字局部或全局模式的启发。
写作动机跟StrokeGAN简直一样,又是用笔画编码减少模式坍塌,只是多了个 few-shot 半监督损失,称为 \\(FS^3\\; loss\\)
核心思想
在StokeGAN基础上增加了 few-shot 半监督体系。
相关研究
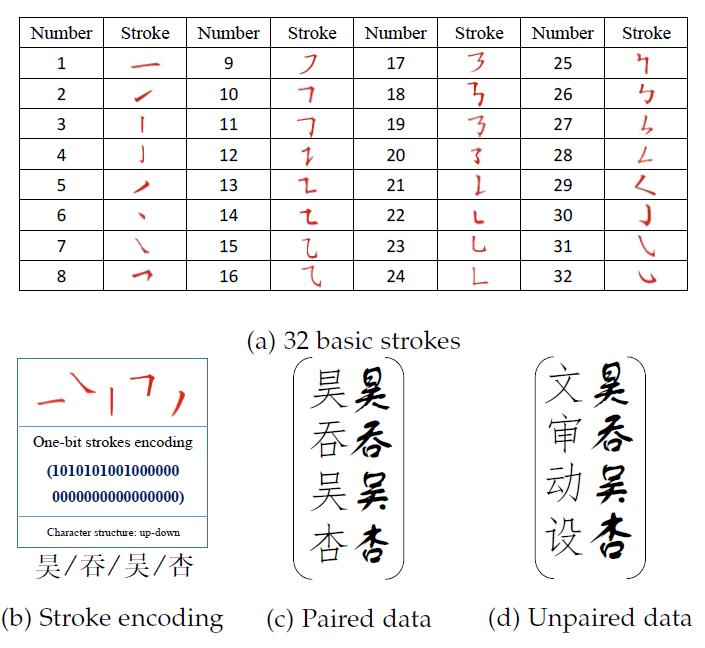
图2 a组成汉字的32个基本笔画 b具有相同one-bit编码跟结构的汉字 c配对数据例子 d非配对数据例子

图1 模型生成结果对比,CycleGAN跟SQ-GAN都有模式坍塌。

图3 本文的模型对3种字体的生成效果,框起来的是真实字符,其他是模型生成的
把模型分成需要配对数据跟不需要两类,看图2c,d。也是从图像翻译的pix2pix开始讲,从CalliGAN到其他没标名字的,这些要配对数据的不好。然后是SCFont,DG-Font,不用配对数据,但会有模式坍塌,看图1,效果不好。
有意思的是文章中先提到图2,再出现的图1,那为什么不互换编号呢。此外图2b那个应该是长度为32的01串,表示汉字是否包含对应序号的笔画,对笔画位置、数量大小形状等都没有约束。
图1的题注超级长,里面那个SQ-GAN基于一种田字格变换的自监督方法,想起来之前在知网上翻到一篇《基于生成对抗网络的汉字自动生成方法研究 陈琪》也是一样,仔细一看作者是一样的,也是这个陈琪,连学校都一样,这不是跟自己之前的工作对比吗?而StrokeGAN是本文第一作者曾锦山20年的工作,甚至中了AAAI2021,思想都差不多,打算先看看。
为了解决模式坍塌,提到那基于田字格(square-block)变换的SQ-GAN,同样基于CycleGAN改的,说这样还不够,因为很多字都有相同的空间结构,图2b。
又讲了一遍早期不用DNN,将字拆开,学到每个笔画/组件再拼成新字的方法,跟后来有了DNN对笔画信息的使用,提了一堆发在不知名地方的论文,其中那个SE-GAN也是之前看过的一篇,侧重毛笔手写体生成,虽然效果跟比较对象都不好,但毕竟做毛笔的少啊,但这篇嘛...
后面还提到ScFont,以及一些比较早、不咋出名的。说其他方法增加了模型复杂度,而本文是为GAN添加更简单,更有效的监督
贡献
- 笔画编码跟那个少样本半监督损失,又是写了一大串,而且笔画编码似乎作为本文创新点又重新拉出来讲
- 做了实验,跟SOTA在14个任务上(14种字体)进行比较balabala,结果看图1跟图3。这次全文才6个very
- 把提出的思想用在其他baseline上,也测试了zero-shot的繁体字体生成任务
提及本文是他们上一篇StrokeGAN AAAI 2021 会议版本的扩展,难怪无论是思路还是行文、甚至图片的排布,跟StrokeGAN几乎一样,"+"诚不我欺。主要扩展点如下所示:
- 多了个少样本半监督,就是用少许配对样本作为半监督信息,进一步提供汉字的全局空间结构信息
- 做了更多实验来完全探索本文模型性能,显著优于StrokeGAN
作者认为这样比起那个会议版本做出了大量的扩展。
方法(模型)流程
又介绍了一遍笔画编码,略。说图1里StrokeGAN生成的样本有多余笔画,只用笔画编码不足以解决模式坍塌(strokegan的用词是sufficient),它只有局部信息,总之就需要那个少样本半监督损失来捕捉全局信息。
我看半监督好像都是先用标注样本训练,然后再给无标注样本打上伪标签再次训练,但这里作者好像把训练数据是否配对(同一个字不同风格)当做标注的有无。
首先所有数据同时使用,那些“未标注”的数据直接就能用于训练(StrokeGAN)。其次不可能先用标注数据训练模型后再匹配没配对的数据,因为每个图片实际上训练前就知道分别是什么字(才能给出笔画编码),能对应上早就可以先匹配好。
只是加了个损失,很难说是半监督,要说的话应该算监督模型,毕竟样本是字的图片,每个字都是有标签的(笔画编码)。但这个损失确实有用,毕竟原本要靠判别器给出生成的图片是否在目标域这种模糊的信息,现在直接用L1损失明确指出图片该如何变换,肯定是要好不少的。
Overview
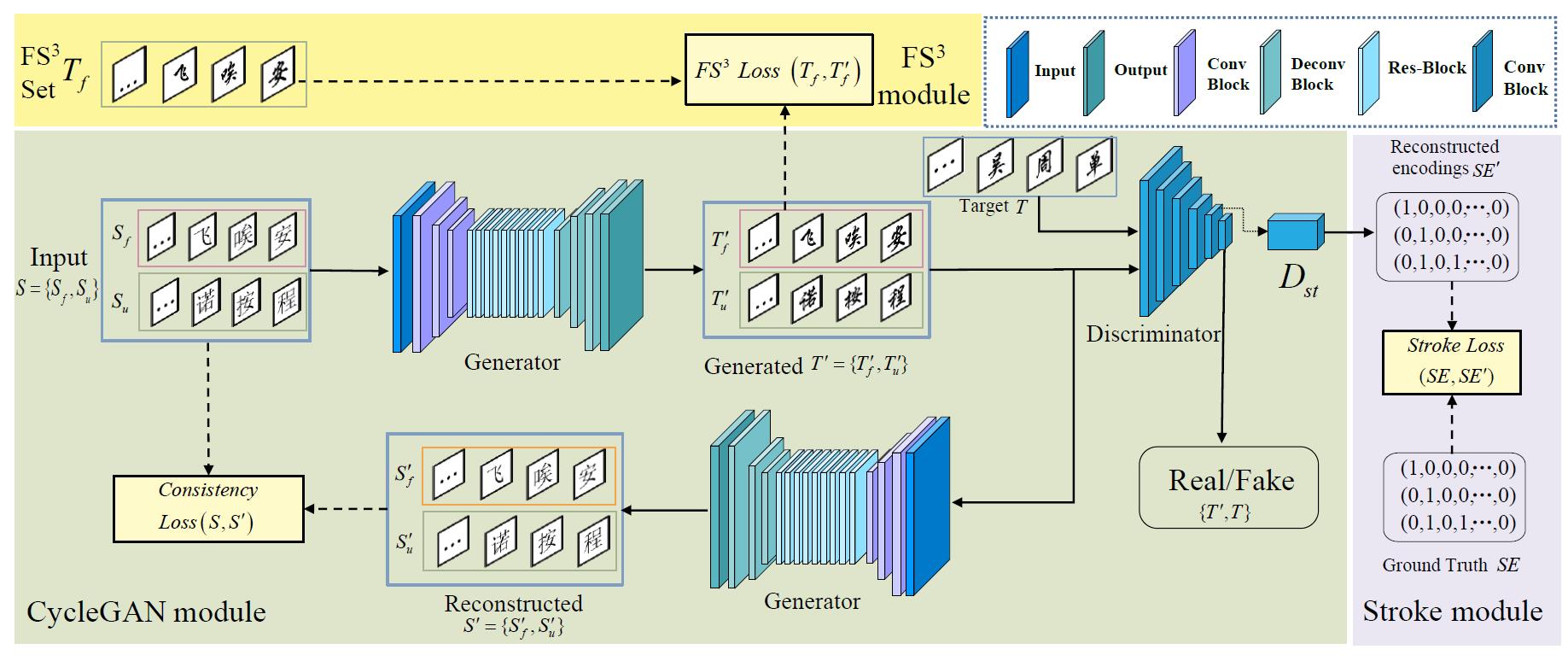
图4 StrokeGAN+总体架构
架构看图4,就比StrokeGAN多了个 \\(FS^3\\) 模块,其实就是一部分样本使用对应的groundtruth去计算L1损失,监督信息自然是比原来靠判别器判断是否为目标域来得强。
像图4里下标为f的是半监督用的配对样本,u下标的是非配对样本,SE是笔画编码集合。他甚至认真讲了模型输入输出的流程,好详细,这是其他论文所没有的。
损失写得花里胡哨的,无非比StrokeGAN多了一个配对数据的L1损失:
总损失为:
不同的是模型这块就完了,公式不标序号,也没有分小节细讲每个模块,前面都水那么多字数了,咋不干脆多整点呢。
实验
实验环境Linux, AMD(R) Ryzen 7 3900x twelve-core processor ×24 CPU, GeForce RTX 2080ti GPU,不会因为中了AAAI升级了装备吧
选的baseline共6个,然而只有最后两个SQ-GAN跟StrokeGAN是字体生成的模型,其他都是图像翻译领域的,而且都挺早的了,跟pix2pix而不跟zi2zi比,他还是那么懂比较。
架构、优化器跟StrokeGAN大差不差,四项损失的\\(\\lambda\\)中,对抗损失的没提及,中间俩设为1,最后那个半监督的说是手动调优(hand-optimal),甚至没给个大概的范围。
根据所做的实验,每个生成任务,随机选20%的字符作为监督样本,按最小的数据集2000字算也需要400个监督样本,这能叫few-shot?跟那个fsFont有的一比了。
数据集

表1 不同汉字字体的数据集大小

图5 本文模型生成的一些样本
不出意外,找了14个字体称作14个子数据集,写出来就是跑了14个任务。数据集具体信息看表1,样本看图5左部。这图也是有点意思,分辨率低,而且没有放出groundtruth,该不会想让人故意看不清吧
手写汉字数据集来自CASIA-HWDB1.1,300人,每人3755个常用汉字,一共3755x300,而本文则是每个字随机选一种,只用到其中3755个样本。其他数据集根据网上搜集的ttf制作,其实就13个字体(相比StrokeGAN增加了62.5%)。训练、测试集划分为8:2。结合表1,这段跟StrokeGAN一样,直接copy之前的笔记。
指标
- FID (Frechet Inception Distance)
- LPIPS (Learned Perceptual Image Patch Similarity)
- PSNR (Peak Signal-to-Noise Ratio)
- SSIM (Structural Similarity)
指标方面倒是比StokeGAN丰富多了,其中FID、LPIPS越小越好,PSNR、SSIM越大越好,其中LPIPS跟SSIM取值范围[0, 1]
Superiority in Reducing Mode Collapse
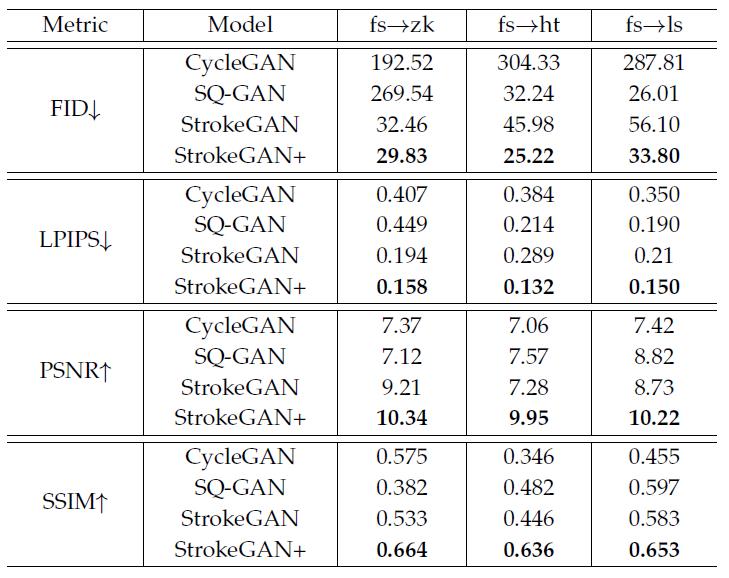
表2 3个任务、4个模型在4种指标上的结果,展示本文模型解决模式坍塌的优越性
比较结果看图1、表2。论文方面就几个事实不停重复:有模式坍塌,加田字格变换有效,笔画编码更有效,但再加个半监督更更有效
On Few-Shot Semi-Supervised Schemes
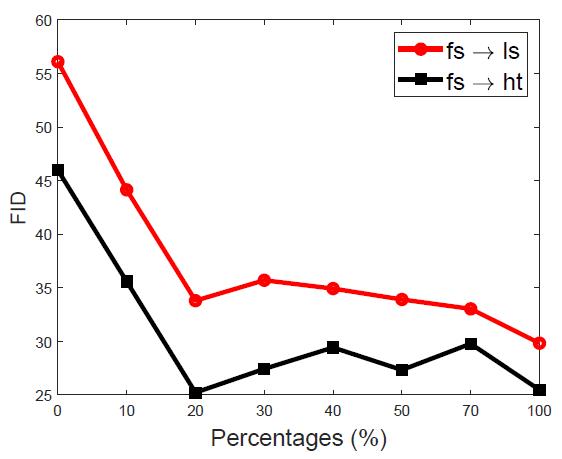
图6 不同概率下随机选择监督样本的FID值趋势
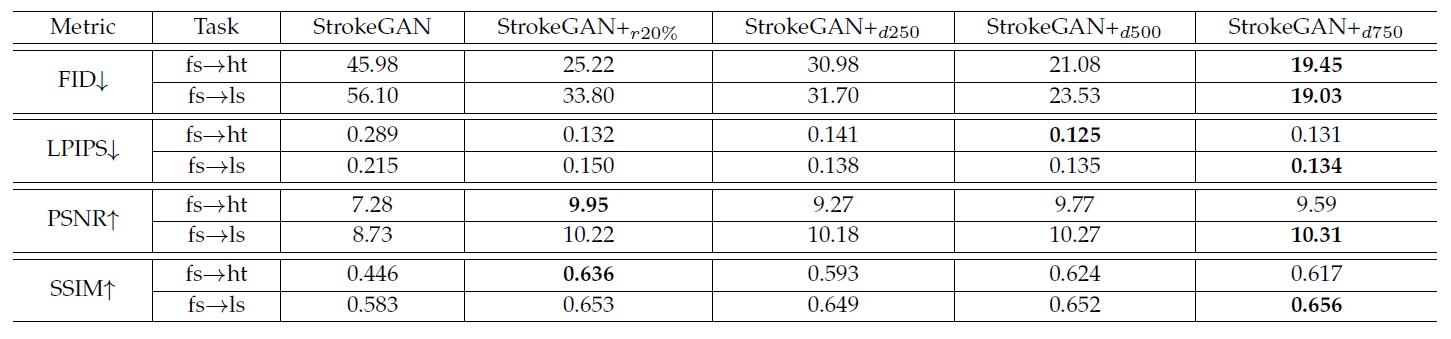
表3 两种半监督策略的性能比较

表4 在毛笔字体上两种半监督策略性能比较
实验没有测试1000、1500个字的效果,想必应该越大越好。其次这实验只用到3个字体,看表就知道了,不确定性很大。而且这几个字体都是比较“端正”的,至少多做几个字体的试验取平均?
两种选择few-shot半监督样本的策略:
- 随机,以确定概率从训练集选择
- 确定,有篇论文说450个独体字跟300个复合字可以覆盖所有汉字结构信息,因此选择750个样本做few-shot半监督
对第一种策略,分别用8种概率0%, 10%, 20%, 30%, 40%, 50%, 70%, 100%去抽样本,各自对应的FID值见图6,大于20%(600样本)的基本稳定,作者说这就足够了,由此选择20%。很奇怪的是介于20到100%的为什么会比20%的FID大呢,按理说用的监督样本越多效果应该越好。或者作者是把用于半监督损失的字单独划出来,不参与对抗损失、循环一致性等的计算?总觉得奇怪。(看后面Few-shot Semi-supervised Scheme Vs. Data Augmentation小节,应该是都参与的)
第二种策略也做了三个实验:选250、500、750个字,表3展示了跟上面随机选20%一起的比较结果,那肯定是精心选的750个字好啊,还需要做实验?
首先如果做实验,怎么不试试1000、1500个字的效果,想必应该越大越好。其次这实验只用到3个字体,看它那表就知道了,不确定性很大。而且这几个字体都是比较“端正”的,应该试试行楷、草书、艺术字等,再怎么也应该多几个再取平均吧?
然后说一些毛笔字体没有750个那么多的样本,找了两个不知道什么字体(只有拼音),分别490跟600个样本,样本总数记为N。就做三个实验:N个字全拿、随机选N、随机选20%,结果看表4。我是不知道他这前两个采样策略有什么不一样,还是说实际上都是ttf来的,要多少有多少,只是假装样本不足?
对着表4描述半天,然后说简单起见用20%随机策略,其他策略并不复杂为何不选更好的呢,而且 N个字全拿 跟 随机选N个字 结果在两个字体上几乎相反吧,到底是怎么得出这个结论的。
Few-shot Semi-supervised Scheme Vs. Data Augmentation
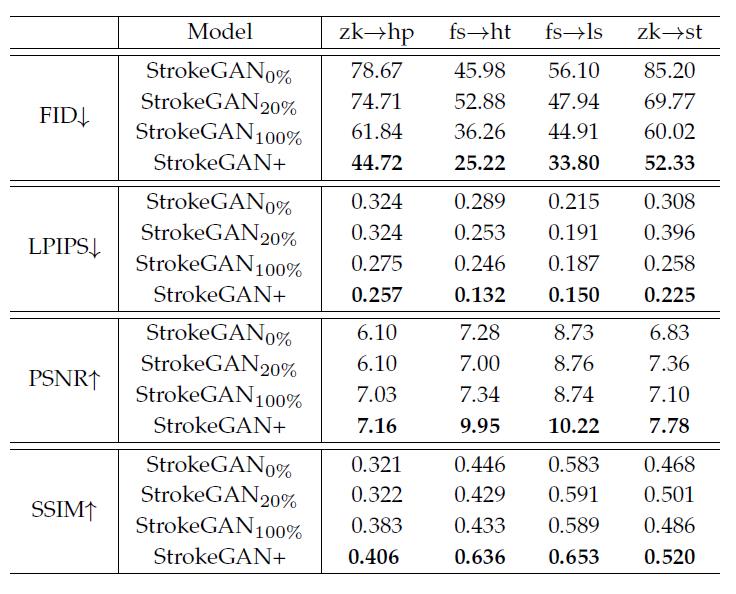
表5 半监督跟拷贝数据增强策略定量比较

图7 半监督跟拷贝数据增强策略可视化结果比较
想说few-shot半监督样本带来的损失是否只跟相关的拷贝数据增强(associated copy data augmentation)有关,于是比较20%随机策略的StokeGAN+ 跟 用了不同数据增强方法的StrokeGAN:用0%、20%、100%配对(paired)数据当做非配对数据。
属实是没看懂这表述,作者说100%的相当于将训练数据集加倍。不清楚是额外加的数据还是把已有数据重复一遍,感觉跟那个半监督划分也不同啊。按照copy data augmentation,应该是复制了对应百分比的数据。但是按照后文又是额外添加的,总之很jb傻逼,已经不想看了。
结果看表5,这边又说\\(StrokeGAN_20\\%\\)是用20% 额外的 非配对的(unpaired) 的数据,图7是对应的一些样本。看这俩结果给StrokeGAN更多的数据确实有明显的提升,如果是额外的数据为什么不喂给StrokeGAN+呢,如果是复制的怎么不试试更多的,500%之类的效果
Comparison with State-of-the-art Models
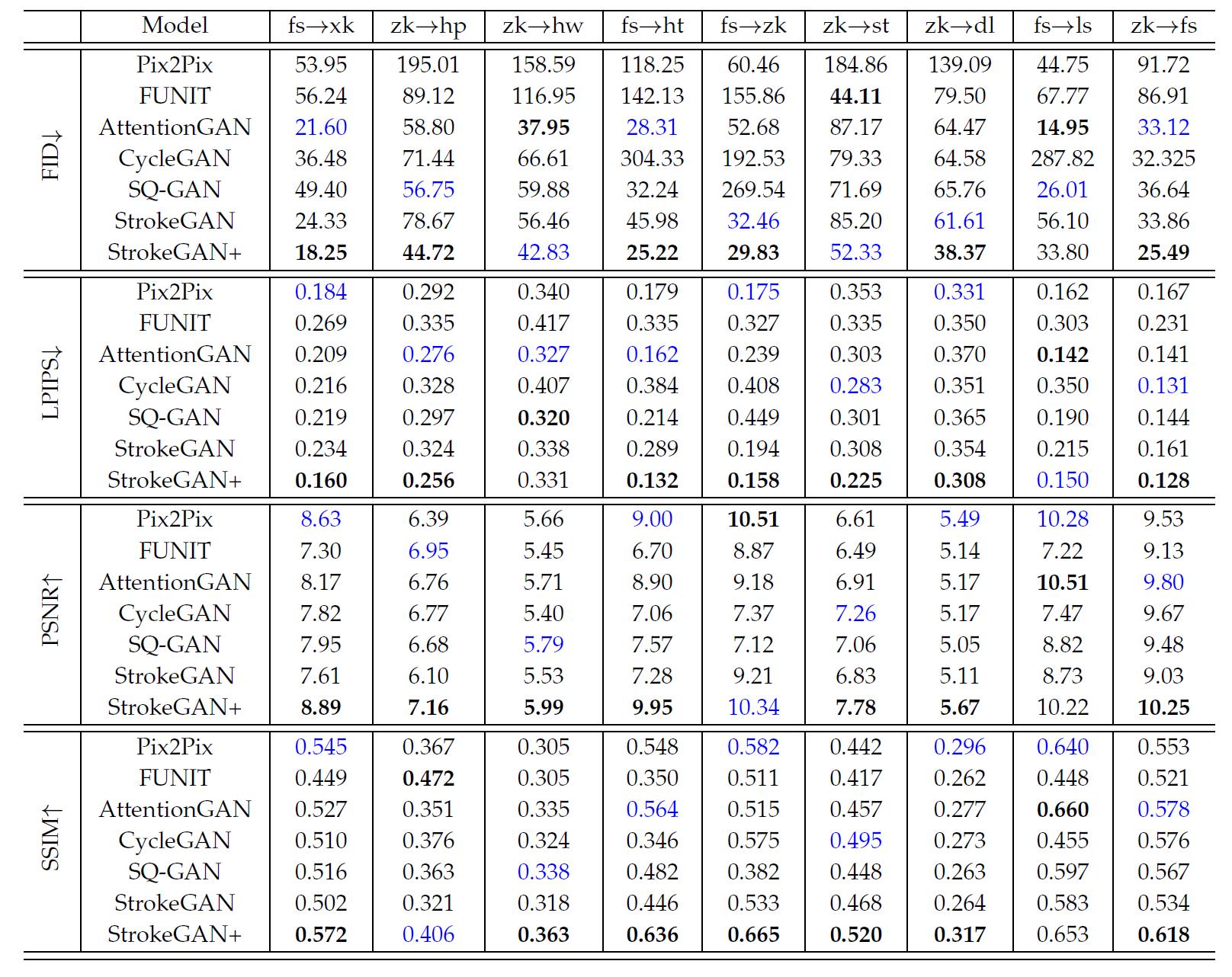
表6 9个印刷或手写体上SOTA方法的比较,粗体、蓝色分别表示最好跟次好结果
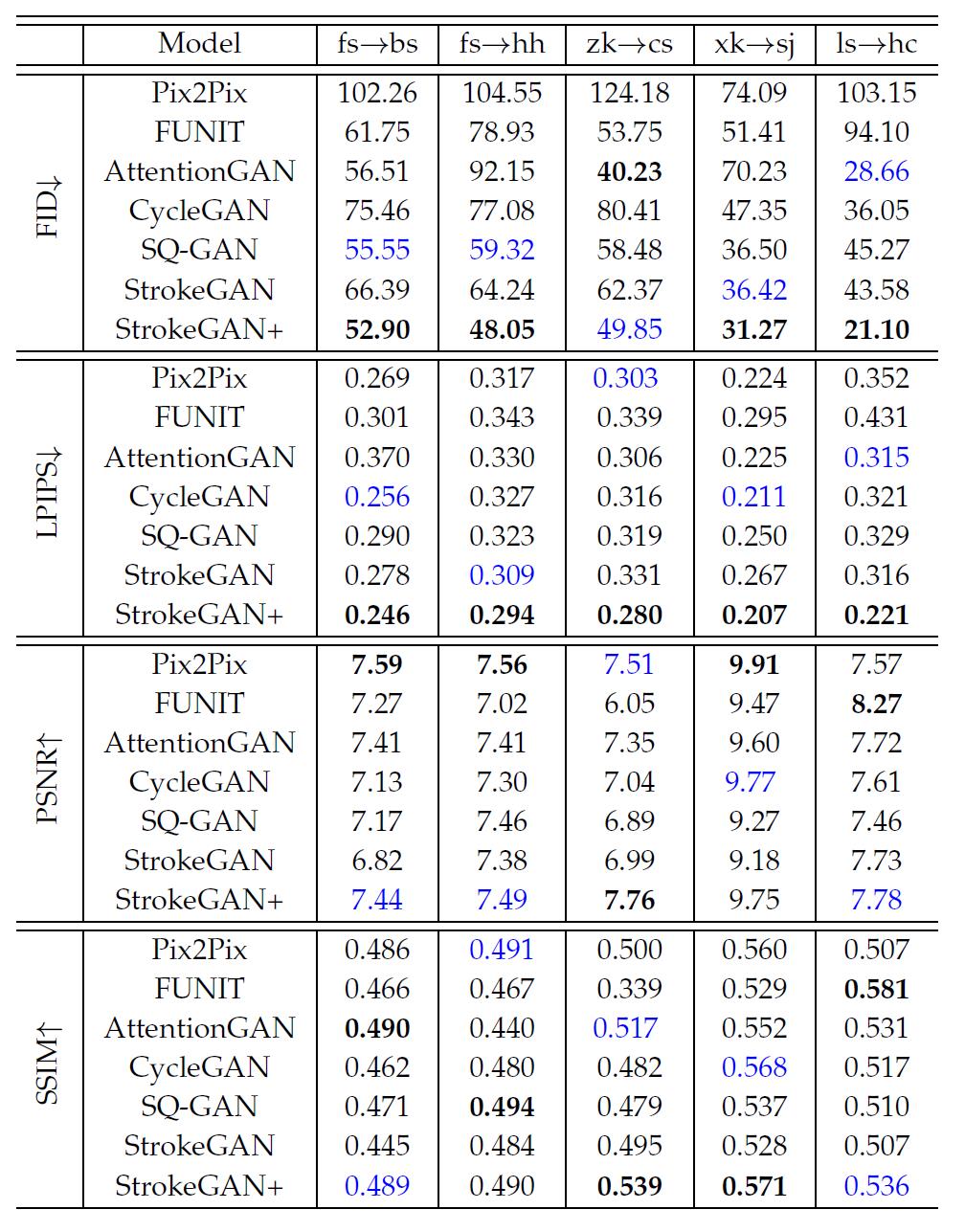
表7 5种毛笔字体上SOTA方法的比较,粗体、蓝色分别表示最好跟次好结果

图8 各模型的可视化结果

图9 各模型对于未知复杂字符生成结果的比较
跟其他模型比较,结果看表6表7,弱baseline小数据集却是相近的指标,还要靠一手标蓝安慰自己
看图8,本文的模型结果质量最好,图里的红框应该是效果不好的部分,感觉框少了,而且不客观。琥珀体看起来确实不容易,模型把握不好笔画什么时候该连接什么时候断开。总算有target的对比,这StrokeGAN+只能说矮子里拔高个。
图9是一些未知的复杂汉字生成结果,体现本文模型良好的泛化性能,合着前面都是训练集里面有的字?
Generalizability of Proposed Idea

图10 两个baseline跟各自应用了本文思想的升级版本生成样本的比较
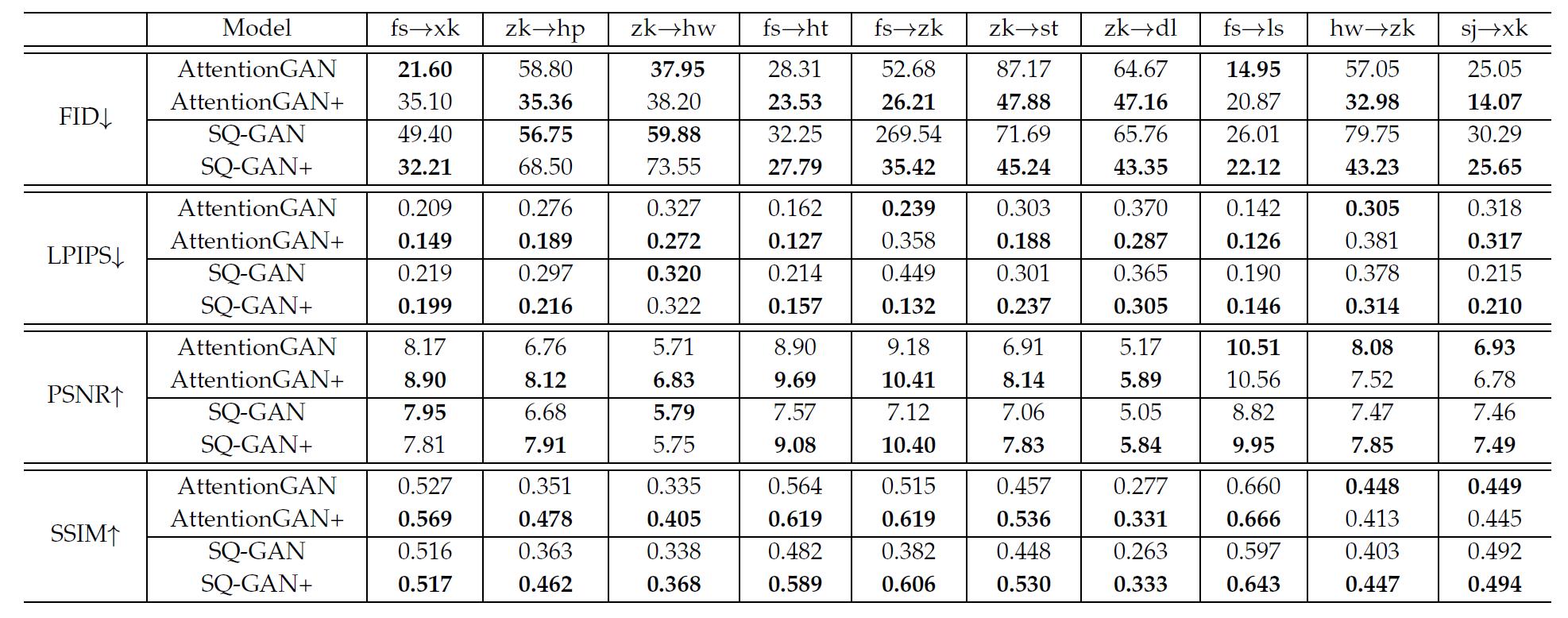
表8 在10种印刷或手写体上baseline跟各自应用了本文思想的升级版本性能比较
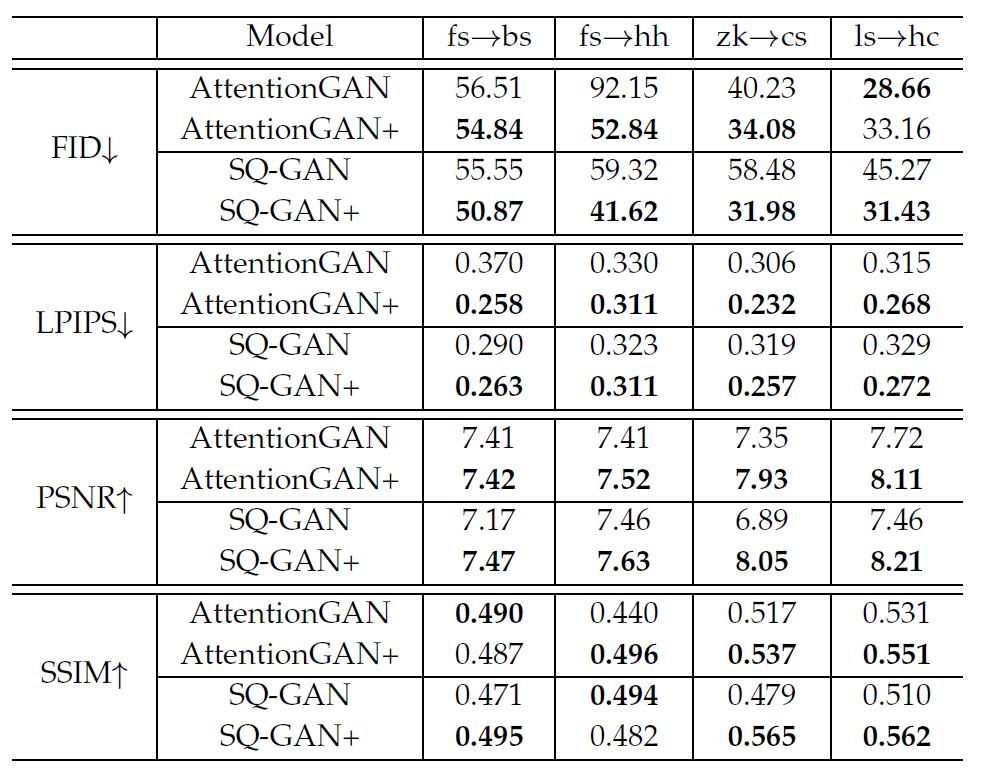
表9 在4种毛笔字体上baseline跟各自应用了本文思想的升级版本性能比较
把笔画编码跟那个半监督损失加到其他模型,如AttentionGAN 和 SQ-GAN上。找了14个字体去做实验,结果在表8表9,部分可视化结果看图10。总之就是提点很多,方法有效,然而看表8表9,在部分字体部分指标上升级版反倒不如原来的,有的提点实际上很有限,作者并未加以分析。
Effectiveness in Zero-shot Traditional Chinese Font Generation

图11 3个字体上简体训练的模型生成繁体字的结果
把用简体训好的模型拿去测试繁体字,称之zero-shot繁字汉字生成,结果看图11,效果特别好balabala...差别大概是部分笔画不包括在训练集里面?
总结
总算到tm的总结了,属实折磨。现存的 无监督 汉字生成模型存在模式坍塌问题,提出了两个点子提供监督信息...监督式的也会有模式坍塌吧。提的思想可以用于其他模型...但本身这StrokeGAN就属于用其他模型吧,毕竟又没改CycleGAN的结构。
鸣谢部分又是 国家自然科学基金 跟 江西省千人计划。
评价
以后再找几个字体做下实验岂不是能再发一篇StrokeGAN++,然后是 max plus pro ultra...
说到底这种基于CycleGAN的都不具备泛化能力,一次训练一种字体转换,而且这个 few-shot 完全是欺诈,没什么意义啊。比较对象,包括引用的论文都是跟笔画信息的使用有关的,事实上完全可以跟其他不使用笔画信息的比较,除非...效果不如他人。
实验倒是做得挺多,图表整了一大堆,却缺少分析,有种做政治材料分析嗯蹭知识点的数量美,不知道的还以为内容很丰富呢。主要就是笔画编码,但用笔画、组件信息的也不在少数。半监督只能说很勉强,加上配对样本效果肯定好,很早之前的zi2zi就这样,但配对样本的获取相对不容易,怎么用非配对效果又能好才是需要研究的吧。
不过有一说一,能上AAAI还是有可取之处的,大概,至少看完收获了很多水实验的点子,秘诀可能是:重复强调的改进点、基础知识的介绍、各个角度的小实验、像是为了过查重一样的白话文、一篇拆两篇...至少我是想不到把简体到繁体拎出来讲,其他论文也都是扔一起去训练。说到底这些实验难道不该写在前面StrokeGAN那篇里面?特意拆成两部分水两篇是吧。
待解明
- few-shot
- 半监督
- 用于半监督损失的样本有没有再去用于其他损失的计算
- 为什么不更多样本去做半监督?
- copy data augmentation 含义,样本是额外添加的还是原有的进行复制?
- 太多了写在各小节中不想重复
以上是关于[论文阅读] StrokeGAN+: Few-Shot Semi-Supervised Chinese Font Generation with Stroke Encoding的主要内容,如果未能解决你的问题,请参考以下文章