缓存穿透缓存击穿缓存雪崩区别和解决方案
Posted xiaoniaox
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了缓存穿透缓存击穿缓存雪崩区别和解决方案相关的知识,希望对你有一定的参考价值。
转载自:https://blog.csdn.net/kongtiao5/article/details/82771694
转载自:https://blog.csdn.net/zzti_erlie/article/details/104655455?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-3.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-3.control
一、缓存处理流程
前台请求,后台先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,数据库取到更新缓存,并返回结果,数据库也没取到,那直接返回空结果。
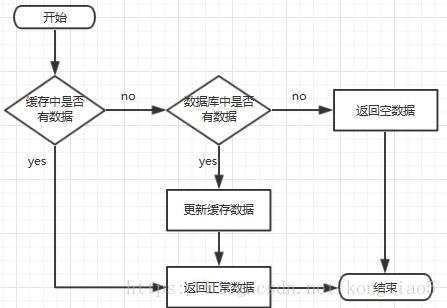
二、缓存穿透
描述:
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
出现过程
假如客户端每秒发送5000个请求,其中4000个为黑客的恶意攻击,即在数据库中也查不到。举个例子,用户id为正数,黑客构造的用户id为负数,如果黑客每秒一直发送这4000个请求,缓存就不起作用,数据库也很快被打死。

解决方案:
接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
解决方法
对请求参数进行校验,不合理直接返回
查询不到的数据也放到缓存,value为空,如 set -999 “”
使用布隆过滤器,快速判断key是否在数据库中存在,不存在直接返回
第一种是最基本的策略,第二种其实并不常用,第三种比较常用。
为什么第二种并不常用呢?
因为如果黑客构造的请求id是随机数,第二种并不能起作用,反而由于缓存的清空策略,(例如清除最近没有被访问的缓存)导致有用的缓存被清除了。
三、缓存击穿
描述:
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
出现过程
设置了过期时间的key,承载着高并发,是一种热点数据。从这个key过期到重新从mysql加载数据放到缓存的一段时间,大量的请求有可能把数据库打死。缓存雪崩是指大量缓存失效,缓存击穿是指热点数据的缓存失效
解决方法
- 设置key永远不过期,或者快过期时,通过另一个异步线程重新设置key
- 当从缓存拿到的数据为null,重新从数据库加载数据的过程上锁,下面写个分布式锁实现的demo
Redis实现分布式锁
我之前的文章写到了Redis实现分布式锁的原理,这里就不再详细概述了
Redis分布式锁为什么要这样写?
1.加锁执行命令
SET resource_name random_value NX PX 30000
1
2.解锁执行脚本
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
写一个分布式锁工具类
public class LockUtil {
private static final String OK = "OK";
private static final Long LONG_ONE = 1L;
private static final String script = "if redis.call(\'get\', KEYS[1]) == ARGV[1] then return redis.call(\'del\', KEYS[1]) else return 0 end";
public static boolean tryLock(String key, String value, long expire) {
Jedis jedis = RedisPool.getJedis();
SetParams setParams = new SetParams();
setParams.nx().px(expire);
return OK.equals(jedis.set(key, value, setParams));
}
public static boolean releaseLock(String key, String value) {
Jedis jedis = RedisPool.getJedis();
return LONG_ONE.equals(jedis.eval(script, 1, key, value));
}
}
工具类写起来还是挺简单的
示例代码
public String getData(String key) {
String lockKey = "key";
String lockValue = String.valueOf(System.currentTimeMillis());
long expireTime = 1000L;
String value = getFromRedis(key);
if (value == null) {
if (LockUtil.tryLock(lockKey, lockValue, expireTime)) {
// 从数据库取值并放到redis中
LockUtil.releaseLock(lockKey, lockValue);
} else {
// sleep一段时间再从缓存中拿
Thread.sleep(100);
getFromRedis(key);
}
}
return value;
}
解决方案:
设置热点数据永远不过期。
加互斥锁,互斥锁参考代码如下:

说明:
1)缓存中有数据,直接走上述代码13行后就返回结果了
2)缓存中没有数据,第1个进入的线程,获取锁并从数据库去取数据,没释放锁之前,其他并行进入的线程会等待100ms,再重新去缓存取数据。这样就防止都去数据库重复取数据,重复往缓存中更新数据情况出现。
3)当然这是简化处理,理论上如果能根据key值加锁就更好了,就是线程A从数据库取key1的数据并不妨碍线程B取key2的数据,上面代码明显做不到这点。
四、缓存雪崩
描述:
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
出现过程
假设有如下一个系统,高峰期请求为5000次/秒,4000次走了缓存,只有1000次落到了数据库上,数据库每秒1000的并发是一个正常的指标,完全可以正常工作,但如果缓存宕机了,或者缓存设置了相同的过期时间,导致缓存在同一时刻同时失效,每秒5000次的请求会全部落到数据库上,数据库立马就死掉了,因为数据库一秒最多抗2000个请求,如果DBA重启数据库,立马又会被新的请求打死了,这就是缓存雪崩。

解决方案:
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
设置热点数据永远不过期。
解决方法
- 事前:redis高可用,主从+哨兵,redis cluster,避免全盘崩溃
- 事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL被打死
- 事后:redis持久化RDB+AOF,快速恢复缓存数据
- 缓存的失效时间设置为随机值,避免同时失效
以上是关于缓存穿透缓存击穿缓存雪崩区别和解决方案的主要内容,如果未能解决你的问题,请参考以下文章