理解go中goroutine的GPM
Posted ArthurXL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了理解go中goroutine的GPM相关的知识,希望对你有一定的参考价值。
01
介绍
Golang 语言与其他编程语言之间比较,最大的亮点就是 goroutine,使 Golang 语言天生支持并发,可以高效使用 CPU 的多个核心,而并发执行需要一个调度器来协调。
Golang 语言的调度器是基于协程调度模型 GMP,即 goroutine(协程)、processor(处理器)、thread(线程),通过三者的相互协作,实现在用户空间管理和调度并发任务。
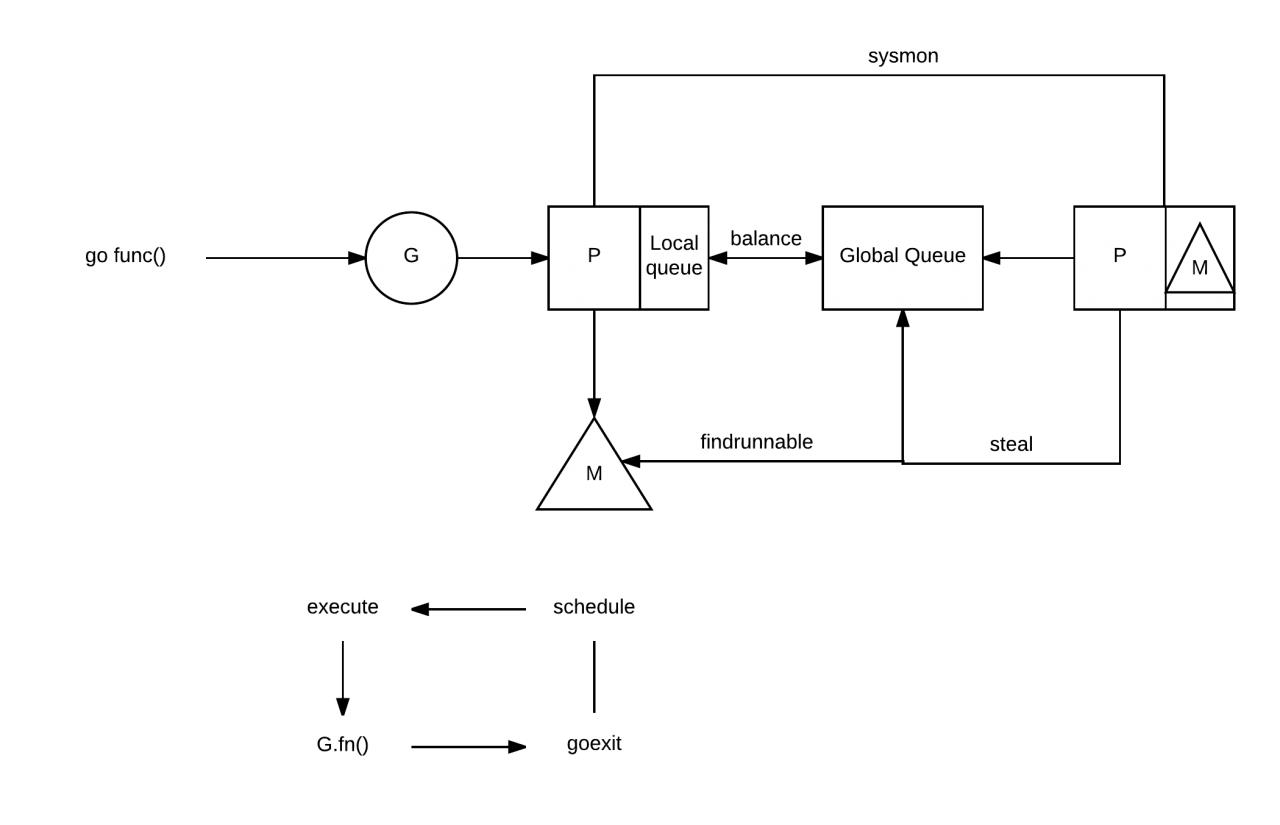
其中 thread(M) 是由操作系统分配的执行 Go 程序的线程,一个 thread(M) 和一个 processor(P) 绑定,M 是实际执行体,以调度循环的方式执行 G 并发任务。M 通过修改寄存器,将执行栈指向 G 自带的栈内存,并在此空间内分配堆栈帧,执行任务函数。M 只负责执行,不再持有状态,这时并发任务跨线程调度,实现多路复用的根本所在。每个 processor(P) 维护一个本地 goroutine(G) 队列,此外还有一个全局 goroutine(G) 队列。
其中,M 的数量由操作系统分配,并且如果有 M 阻塞,操作系统会创建新的 M,如果有 M 空闲,操作系统会回收 M 或将空闲 M 睡眠,此外,Golang 语言还可以限定 M 的最大数量为 10000, runtime/debug 包中的 SetMaxThread 函数也可以设置 M 的数量。
Go 程序启动时,会创建 P 列表,P 的数量由环境变量 GOMAXPROCS 的值设置,也可以在 Go 程序中通过调用 runtime 包的 GOMAXPROCS 函数来设置。自 Go1.5 开始,GOMAXPROCS 的默认值为 CPU 的核心数,但是 GOMAXPROCS 的默认值在某些情况下也不是最优值。
P 的作用类似 CPU 的核心,用来控制可同时并发执行的任务数量,每个内核的线程 M 必须绑定到一个 P 上,M 才可以被允许执行任务,否则被操作系统将其睡眠或回收。M 独享所绑定的 P 的资源(对象分配内存、本地任务队列等),可以在无锁状态下执行高效操作。
虽然一个 P 绑定一个 M,但是 P 和 M 的数量并不一致。原因是当 M 因陷入系统调用而长时间阻塞时,P 就会被监控线程抢占,去唤醒睡眠的 M 或新建 M 去执行 P 的本地任务队列,这样 M 的数量就会增长。
每个 P 维护一个本地 G 队列,此外,还有一个全局 G 队列,那么新创建的 G 会放在哪里?新创建的 G 优先放在有空闲空间的 P 中(每个 P 的最大存储数量是 256个),如果所有 P 的存储空间都满了,则存放在全局 G 队列中。
02
调度器的发展历史
单进程的操作系统
多进程之间按照先后顺序执行,同一时间只能执行其中一个进程。如果在执行过程中,正在执行的进程如果发生阻塞,CPU 需要等待进程执行完成后,再执行下一个进程,会造成对 CPU 执行时间的浪费。
多线程/多进程的操作系统
CPU 调度器轮询调度多个进程,固定时间内轮询执行其中一个进程,不关心进程在固定时间内是否执行完毕。视觉效果是并发执行,实际上是 CPU 调度器的轮询调度。避免了因为正在执行的进程阻塞,浪费 CPU 的执行时间。
但是带来了另外一些问题,CPU 切换执行多个线程/进程也需要一定成本,并且随着任务的增加,线程/进程的数量也会增加,同时就会增加 CPU 切换成本。即 CPU 使用率一部分被切换成本消耗。另外,多线程/进程之间,还会有数据竞争。
关于内存占用方面,在 32 位操作系统中,进程大概占用 4G,线程大概占用 4M。
因为多线程/进程在 CPU 调度上和内存占用上消耗较大,并且优化难度较大,所以出现了协程,也叫做用户线程。
一个线程分为内核空间和用户空间两个部分,其中内核态负责线程创建和销毁,分配物理内存空间和磁盘空间;用户态负责承担应用开销。
协程(用户线程)
协程,也叫做用户线程,位于用户态。用户线程和内核态的线程之间是绑定关系。用户线程负责应用开销,内核线程负责系统调用的开销。CPU 只需负责系统调用,无需关心应用开销,提升了 CPU 使用率。
为了进一步提升内核态线程的使用率,所以出现了协程调度器,协程调度器与内核态的线程绑定,负责轮询调度多个协程。CPU 无需关心多个协程之间的调度,降低了 CPU 切换成本。通过协程调度器,线程和任务之间的关系由1 比 1,变为 1 比 N,但是仍然存在协程阻塞和无法利用 CPU 的多个核心的问题。
协程调度器又做了改进,由一个内核的线程对一个协程调度器,改为多个内核的线程对一个协程调度器,即线程和任务之间由 1 比 M,变为 N 比 M。这样的好处是可以有效利用多核 CPU,每个 CPU 的核心处理一个内核的线程。
将 CPU 切换消耗成本转换到协程调度器的切换消耗成本,可以通过进一步优化协程调度器,提升操作系统的性能。相比优化操作系统,优化协程调度器更加容易。
Golang 语言的协程调度
关于内存占用方面,创建一个 Golang 的协程(goroutine)初始栈仅有 2K,并且创建操作只在用户空间简单地分配对象,比在内核态分配线程要简单的多,所以可以创建成千上万的 goroutine,并且可以通过协程调度器循环调度 goroutine。
关于协程调度方面,Golang 语言早期是通过多个线程去轮询调度一个全局的 goroutine 队列,存在锁竞争和 CPU 切换线程的成本。
03
Golang 语言的 goroutine 调度器模型 GMP 的设计思想
复用线程:
我们已经知道,一个 M 和一个 P 绑定,M 和 P 的关系是 1 比 1,如果 M 阻塞,操作系统会唤醒睡眠的 M,如果没有睡眠的 M,操作系统会创建新的 M,并把阻塞的 M 上的 P 绑定到唤醒的睡眠的 M 或新创建的 M,该操作被称为 hand off 机制。阻塞的 M 达到操作系统最大时间就会被操作系统销毁或将其睡眠,未被执行的 G 会加入到其他 P 的队列中。
如果一个 P 的 G 被 M 处理完,会怎么样的?M 会等待 P 去获取新的 G,P 优先去其他 P 上获取(偷)它们的待处理的 G,该操作被称为 work stealing 机制。
使用 CPU 的多个核心:
我们已经知道,P 的数量由环境变量 GOMAXPROCS 的值设置, Go1.5 之前,GOMAXPROCS 的默认值为 1,自 Go1.5 开始,GOMAXPROCS 的默认值为 CPU 的核心数,可以有效使用 CPU 的多个核心,并行执行。
抢占调度:
co-routine 时代,CPU 轮询执行每个协程,每个协程执行完,主动释放 CPU 资源。
goroutine 时代,CPU 规定每个协程的最大执行时间为 10ms,超过最大执行时间,即便该协程未执行完,其它协程也会抢占 CPU 资源。
全局 G 队列:
如果一个 P 的 G 被 M 处理完,并且其他所有的 P 都没有待处理的 G,那么 P 会去全局 G 队列获取 G,此时会触发锁机制。
也许有的读者会说,那如果全局 G 队列也没有待处理的 G 呢?如果这样,该 M 达到最大空闲时间,就会被操作系统回收或将其睡眠。
04
m0 和 g0
什么是 m0?
m0 表示进程启动的第一个线程,也叫主线程。它和其他的 m 没有什么区别,要说区别的话,它是进程启动通过汇编直接复制给 m0 的,m0 是个全局变量,而其他的 m 都是 runtime 内自己创建的。m0 的赋值过程,可以看前面 runtime/asm_amd64.s 的代码。一个 go 进程只有一个 m0。
什么是 g0?
首先要明确的是每个 m 都有一个 g0,因为每个线程有一个系统堆栈,g0 虽然也是 g 的结构,但和普通的 g 还是有差别的,最重要的差别就是栈的差别。g0 上的栈是系统分配的栈,在 linux 上栈大小默认固定 8M,不能扩展,也不能缩小。而普通 g 一开始只有 2K 大小,可扩展。在 g0 上也没有任何任务函数,也没有任何状态,并且它不能被调度程序抢占。因为调度就是在 g0 上跑的。
proc.go 中的全局变量 m0和g0
在 runtime/proc.go 的文件中声明了两个全局变量,m0 表示主线程,这里的 g0 表示和 m0 绑定的 g0,也可以理解为 m0 线程的堆栈,这两个变量的赋值是汇编实现的。
到这里我们应该知道了 g0 和 m0 是什么了?m0 代表主线程、g0 代表了线程的堆栈。调度都是在系统堆栈上跑的,也就是一定要跑在 g0 上,所以 mstart1 函数才检查是不是在 g0 上, 因为接下来就要执行调度程序了。
05
调度器跟踪调试
Go 允许跟踪运行时调度器。这是通过 GODEBUG 环境变量完成的:
GODEBUG=scheddetail=1,schedtrace=1000 ./program
输出示例:
SCHED 0ms: gomaxprocs=8 idleprocs=7 threads=2 spinningthreads=0 idlethreads=0 runqueue=0 gcwaiting=0 nmidlelocked=0 stopwait=0 sysmonwait=0 P0: status=1 schedtick=0 syscalltick=0 m=0 runqsize=0 gfreecnt=0 P1: status=0 schedtick=0 syscalltick=0 m=-1 runqsize=0 gfreecnt=0 P2: status=0 schedtick=0 syscalltick=0 m=-1 runqsize=0 gfreecnt=0 P3: status=0 schedtick=0 syscalltick=0 m=-1 runqsize=0 gfreecnt=0 P4: status=0 schedtick=0 syscalltick=0 m=-1 runqsize=0 gfreecnt=0 P5: status=0 schedtick=0 syscalltick=0 m=-1 runqsize=0 gfreecnt=0 P6: status=0 schedtick=0 syscalltick=0 m=-1 runqsize=0 gfreecnt=0 P7: status=0 schedtick=0 syscalltick=0 m=-1 runqsize=0 gfreecnt=0 M1: p=-1 curg=-1 mallocing=0 throwing=0 preemptoff= locks=1 dying=0 helpgc=0 spinning=false blocked=false lockedg=-1 M0: p=0 curg=1 mallocing=0 throwing=0 preemptoff= locks=1 dying=0 helpgc=0 spinning=false blocked=false lockedg=1 G1: status=8() m=0 lockedm=0
请注意,输出结果使用了 G、M 和 P 的概念及其状态,比如 P 的 queue 大小。通常,您不需要那么多细节,因此只需使用:
GODEBUG=schedtrace=1000 ./program
此外,Golang 还有一个高级工具,名为 go tool trace,它具有 UI,允许您浏览程序以及运行时正在做什么。
以上是关于理解go中goroutine的GPM的主要内容,如果未能解决你的问题,请参考以下文章