go进阶 -深入理解goroutine并发运行机制
Posted hguisu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了go进阶 -深入理解goroutine并发运行机制相关的知识,希望对你有一定的参考价值。
并发指的是同时进行多个任务的程序,Web处理请求,读写处理操作,I/O操作都可以充分利用并发增长处理速度,随着网络的普及,并发操作逐渐不可或缺
一、goroutine简述
在Golang中一个goroutines就是一个执行单元,而每个程序都应该有一个主函数main也就是主Goroutines。
协程也叫轻量级线程,为什么说是一个轻量级的线程呢?协程可以轻松创建上百万个而不会导致系统资源衰竭,而线程和进程通常不能超过1万个。在Go语言提供所有系统调用操作,都会出让CPU给其他goroutine,让轻量级线程的切换管理不依赖于系统的线程和进程,也不依赖CPU的核心数量。
线程和协程的概念
线程(Thread):有时被称为轻量级进程(Lightweight Process,LWP),是程序执行流的最小单元。一个标准的线程由线程ID,当前指令指针(PC),寄存器集合和堆栈组成。另外,线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。
线程拥有自己独立的栈和共享的堆,共享堆,不共享栈,线程的切换一般也由操作系统调度。
协程(coroutine):又称微线程与子例程(或者称为函数)一样,协程(coroutine)也是一种程序组件。相对子例程而言,协程更为一般和灵活,但在实践中使用没有子例程那样广泛。
和线程类似,共享堆,不共享栈,协程的切换一般由程序员在代码中显式控制。它避免了上下文切换的额外耗费,兼顾了多线程的优点,简化了高并发程序的复杂。
两者的区别:
相同点:
1、一个程序可以包含多个协程,可以对比于一个进程包含多个线程。
2、和线程类似,共享堆,不共享栈
不同点:线程切换受系统控制,协程切换由自己控制:
我们知道多个线程相对独立,有自己的上下文,切换受系统控制;而协程也相对独立,有自己的上下文,但是其切换由自己控制,由当前协程切换到其他协程,由当前协程来控制。
Goroutine和其他语言的协程(coroutine)在使用方式上类似,但从字面意义上来看不同(一个是Goroutine,一个是coroutine),再就是协程是一种协作任务控制机制,在最简单的意义上,协程不是并发的,而Goroutine支持并发的。因此Goroutine可以理解为一种Go语言的协程。同时它可以运行在一个或多个线程上。
goroutine是Go语言轻量级线程实现,由Go运行时(runtime)管理的:goroutine 是Go语言中并发的执行单位。有点抽象,其实就是和传统概念上的”线程“类似,可以理解为”线程“。
Go语言中使用 goroutine 非常简单,只需要在函数或方法调用前加上go关键字就可以创建一个 goroutine,从而让该函数或方法在新创建的 goroutine 中执行。go func
func sum(x, y int)
z := x + y
fmt.Println(z)
让这个函数并发执行非常简单:
go sum(1,1)在一个函数调哦那个前面加上go关键字,这次调用就会在一个新的goroutine中并发执行。如果调用返回时,那么goroutine也自动结束了。(如该函数有返回值,那么这个返回值会被丢弃)
2、goroutine协程执行机制
goroutine协程执行机制:在主Goroutine结束之后其他的所有Goroutine都会直接退出。
Go程序从初始化main package并执行main()函数开始,当main()函数返回时,程序退出, 且程序并不等待其他goroutine(非主goroutine)结束。
func sum(x, y int)
z := x + y
fmt.Println(z)
func main()
for i := 0; i < 10; i++
go sum(i,i)
,我们使用for循环中调用10次sum()函数,它们是并发执行,但是发现运行后,控制台啥也没有输出。
让主goroutine等待其它 goroutine:
for i := 0; i < 10; i++
go sum(i,i)
time.Sleep(time.Millisecond * 1000)
//goroutine 完成的时间极可能小于设置的等待时间,那么这就会形成多余的等待时间主要特点:
- 是一种轻量级“线程”
- 最重要的是非抢占式多任务处理,有协程主动交出控制权。(非抢占就是正在执行的不允许中断)
- 编译器/解析器/虚拟机层面的多任务
- 多个协程肯在一个多个线程上运行
goroutine可能的切换点
- I/O,select
- channel
- 等待锁
- 函数调用(有时)
- runtime.Gosched()
- 只是参考,不能保证切换,不能保证在其他地方不切换。
3、WaitGroup:多个goroutine并发执行
WaitGroup让goroutine执行完后马上执行下一个goroutine
WaitGroup翻译为等待组,其实就是计数器,只要计数器中有内容将一直阻塞。
Go语言标准库中WaitGroup只有三个方法
Add(delta int)表示向内部计数器添加增量(delta)其中参数delta可以是负数
Done()表示减少WaitGroup计数器的值,应当在程序最后执行,相当于Add(-1)
Wait()表示阻塞直到WaitGroup计数器为
// 声明全局等待组变量
var wg sync.WaitGroup
func demo(count int)
fmt.Println(count)
func main()
//wg.Add(5) 如果不在for里面写,可以直接添加5个。
for i := 0; i < 5; i++
wg.Add(1) // //每启动一个协程增长一个等待
go demo(i)
wg.Done() // 告知当前goroutine完成,释放资源
//time.Sleep(time.Millisecond)//不使用
wg.Wait() // 阻塞等待登记的goroutine完成,不然主Go结束了就都退出了
fmt.Println("ok")
WaitGroup类似java的CountDownLatch工具,保证线程1、线程2....执行完之后再接着执行。
二、GO并发的实现原理
Go实现了两种并发形式:多线程共享内存和CSP(communicating sequential processes)并发模型。
第一种是大家普遍认知的:多线程共享内存。其实就是Java或者C++等语言中的多线程开发。
另外一种是Go语言特有的,也是Go语言推荐的:CSP(communicating sequential processes)并发模型。
CSP并发模型是在1970年左右提出的概念,属于比较新的概念,不同于传统的多线程通过共享内存来通信,CSP讲究的是“以通信的方式来共享内存”。
请记住下面这句话: DO NOT COMMUNICATE BY SHARING MEMORY; INSTEAD, SHARE MEMORY BY COMMUNICATING. “不要以共享内存的方式来通信,相反,要通过通信来共享内存。”
普通的线程并发模型,就是像Java、C++、或者Python,他们线程间通信都是通过共享内存的方式来进行的。非常典型的方式就是,在访问共享数据(例如数组、Map、或者某个结构体或对象)的时候,通过锁来访问,因此,在很多时候,衍生出一种方便操作的数据结构,叫做“线程安全的数据结构”。例如Java提供的包”java.util.concurrent”中的数据结构。Go中也实现了传统的线程并发模型。
Go的CSP并发模型,是通过goroutine和channel来实现的。
1、传统的线程并发模型:多线程共享内存
共享内存:线程不安全
func TestCounter(t *testing.T)
counter := 0
for i := 0; i < 5000; i++
go func()
counter++
()
time.Sleep(1 * time.Second)
t.Logf("counter = %d", counter)
//执行结果会小于5000, 出现了线程安全的问题,因为在并发的过程有可能会出现多个go同时执行counter++,这样只会有一个是有效的。
当多个协程操作一个变量时可能会出现冲突问题,也许会导致程序出异常也许不会,我们可以使用go run -race查看是否有竞争。
和大多数语言同样go也支持加锁保证线程的安全。
使用sync.Mutex对内容加锁:
var tex sync.Mutex
tex.Lock()
tex.Unlock()当一个 goroutine 获取互斥锁之后,其他的 goroutine 将等待直至解锁。
1、互斥锁Mutex使用
var (
num = 100
wg sync.WaitGroup
m sync.Mutex
)
func demo1()
m.Lock()
for i := 0; i < 10; i++
num = num - i
m.Unlock()
wg.Done()
func main()
wg.Add(10)
for i := 0; i < 10; i++
go demo1()
wg.Wait()
fmt.Println(num)
fmt.Println("ok")
2、读写锁(RWMutex)
先看Go语言标准库中的API
type
func (rw *RWMutex) Lock() //禁止其他协程读
func (rw *RWMutex) Unlock()
func (rw *RWMutex) RLock() //禁止其他协程写入,只能读取
func (rw *RWMutex) RUnlock()
func (rw *RWMutex) RLocker()
var tex sync.RWMutex
tex.Lock()
tex.Unlock()
读写锁分为两种:读锁和写锁。
当一个 goroutine 获取到读锁之后,其他的 goroutine如果是获取读锁会继续获得锁,如果是获取写锁就会等待;
互斥锁的锁事同一时间只能一个goroutine运行,而读写锁表示在锁范围内数据的读写操作
共享内存:线程安全:回到上面的例子,通过加锁方式实现共享内存线程安全:
func TestCounterWaitGroup(t *testing.T)
var mut sync.Mutex//建立锁对象
var wg sync.WaitGroup
counter := 0
for i := 0; i < 5000; i++
wg.Add(1)//每启动一个协程增长一个等待
go func()
defer func()
mut.Unlock()//释放锁
()
mut.Lock()//开启锁
counter++
wg.Done()//告诉协成等待的事务已经完成
()
wg.Wait()//等待协程
t.Logf("counter = %d", counter)
读写锁使用场景
如果并发过程中绝大部分都是读操作,那么使用读写锁将会优于互斥锁,如果读操作并不是特别多那将不会有太大差别
读写锁使用原因
多个 goroutine 同时操作一个资源(临界区)的情况,这种情况下就会发生竞态问题(数据竞态)
2、Go的CSP并发模型:channel
Go的CSP并发模型,是通过goroutine和channel来实现的。
上面已经提到,Go并发的核心哲学是不要通过共享内存进行通信; 相反,通过沟通分享记忆。
channel是Go提供goroutine间的通信方式,使用channel可以使多个goroutine之间通信。channel是进程内的通信方式,通过channel传递对象的过程和调用函数时的参数传递行为比较一致,比如也可以传递指针等。
如需跨进程通信,Go建议用分布式系统的方法来解决,如使用Socket或者HTTP等通信协议,Go语言在网络方面也有非常完善的支持。
channel是类型相关的,一个channel只能传递一种类型的值,这个类型需要在声 明channel时指定。
channel是Go语言中各个并发结构体(goroutine)之前的通信机制。 通俗的讲,就是各个goroutine之间通信的”管道“,有点类似于Linux中的管道。
1)、channel基本语法:
var channame chan ElementType
var channame chan <- ElementType //只写
var channame <- chan ElementType //只读
chanName := make(chan int) //无缓存channel
chanName := make(chan in,0) //无缓存channel
chanName := make(chan int,100) //有缓存channel
channel跟map类似的在使用之前都需要使用make进行初始化ch1 := make(chan int, 5)
未初始化的channel零值默认为nil
var ch chan int
fmt.Println(ch) // <nil>2)通信机制:
传数据用channel <- data,取数据用<-channel。例子:
channel <- 1 //向channel添加一个值为1
<- channel //从channel取出一个值
a := <- channel //从channel取出一个值并赋值给a
a,b := <- channel //从channel取出一个值赋值给a,如果channel已经关闭或channel没有值,b为false- 成对出现:在通信过程中,传数据
channel <- data和取数据<-channel必然会成对出现,因为这边传,那边取,两个goroutine之间才会实现通信。 - 阻塞:不管传还是取,必阻塞,直到另外的
goroutine传或者取为止。 - channel仅允许被一个goroutine读写。
3)同步,主协程和子协程之间通信:
func main()
ch := make(chan int)
go func()
ch <- 996 //向ch添加元素
()
a := <- ch
fmt.Println(a)
fmt.Println("程序结束!")
4)、两个子协程的通信
使用channel实现两个goroutine之间通信。
func two()
tc := make(chan string)
ch := make(chan int)
// 第一个协程
go func()
tc <- "协程A,我在添加数据"
ch <- 1
()
// 第二个协程
go func()
content := <- tc
fmt.Printf("协程B,我在读取数据:%s\\n",content)
ch <- 2
()
<- ch
<- ch
fmt.Println("程序结素!")
func main()
two()
5)、channel仅允许被一个goroutine读写。
package main
import (
"fmt"
"time"
)
func goRoutineA(a <-chan int)
val := <-a
fmt.Println("goRoutineA received the data", val)
func goRoutineB(b chan int)
val := <-b
fmt.Println("goRoutineB received the data", val)
func main()
ch := make(chan int, 3)
go goRoutineA(ch)
go goRoutineB(ch)
ch <- 3
time.Sleep(time.Second * 1)
结果为:goRoutineA received the data 3
上面只是个简单的例子,只输出goRoutineA ,没有执行goRoutineB,说明channel仅允许被一个goroutine读写。
三、GO并发模型的实现原理
1、线程模型的实现
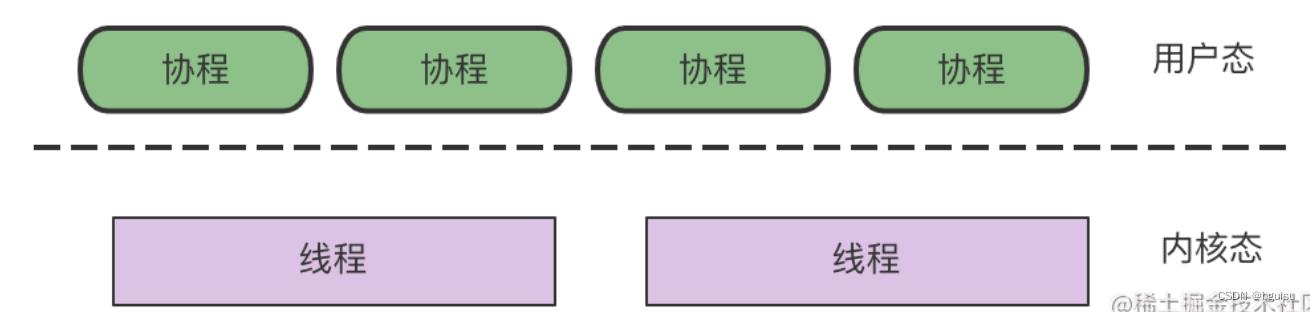
先从线程讲起,无论语言层面何种并发模型,到了操作系统层面,一定是以线程的形态存在的。而操作系统根据资源访问权限的不同,体系架构可分为用户空间和内核空间;内核空间主要操作访问CPU资源、I/O资源、内存资源等硬件资源,为上层应用程序提供最基本的基础资源,用户空间呢就是上层应用程序的固定活动空间,用户空间不可以直接访问资源,必须通过“系统调用”、“库函数”或“Shell脚本”来调用内核空间提供的资源。
我们现在的计算机语言,可以狭义的认为是一种“软件”,它们中所谓的“线程”,往往是用户态的线程,和操作系统本身内核态的线程(简称KSE),还是有区别的。
线程模型的实现,可以分为以下几种方式:
用户级线程模型:多线程程序在一个核的cpu上运行
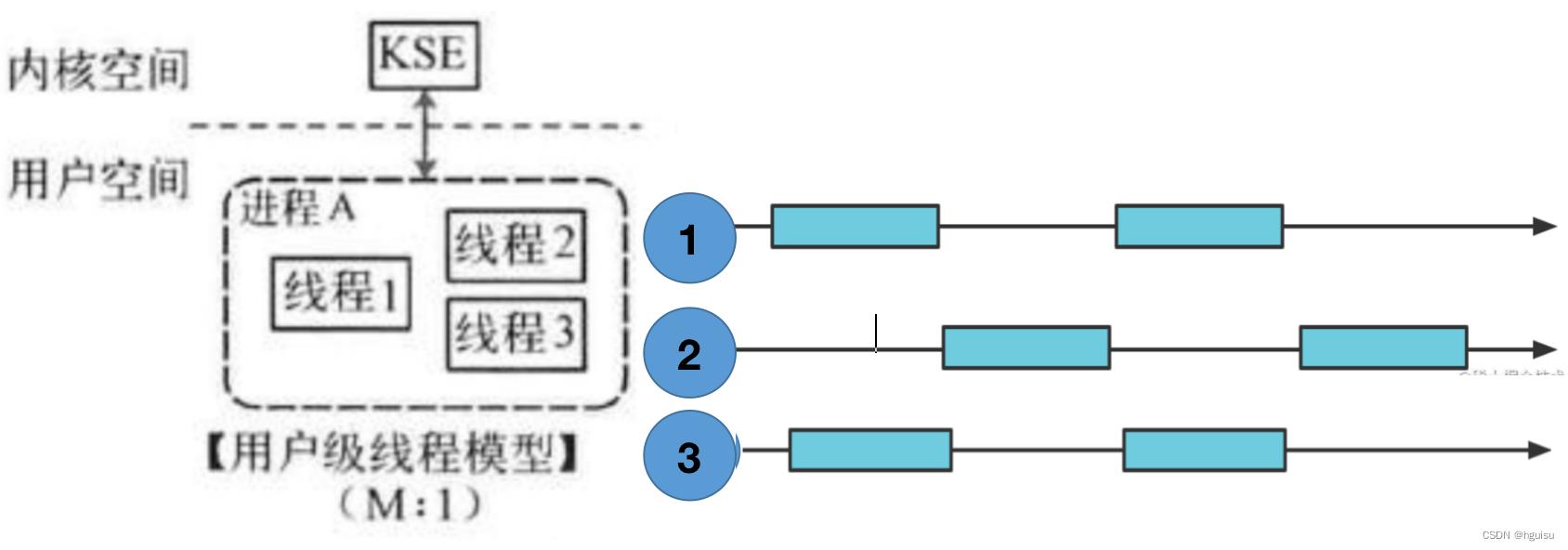
如图所示,多个用户态的线程对应着一个内核线程,程序线程的创建、终止、切换或者同步等线程工作必须自身来完成。它可以做快速的上下文切换。缺点是不能有效利用多核CPU。
内核级线程模型
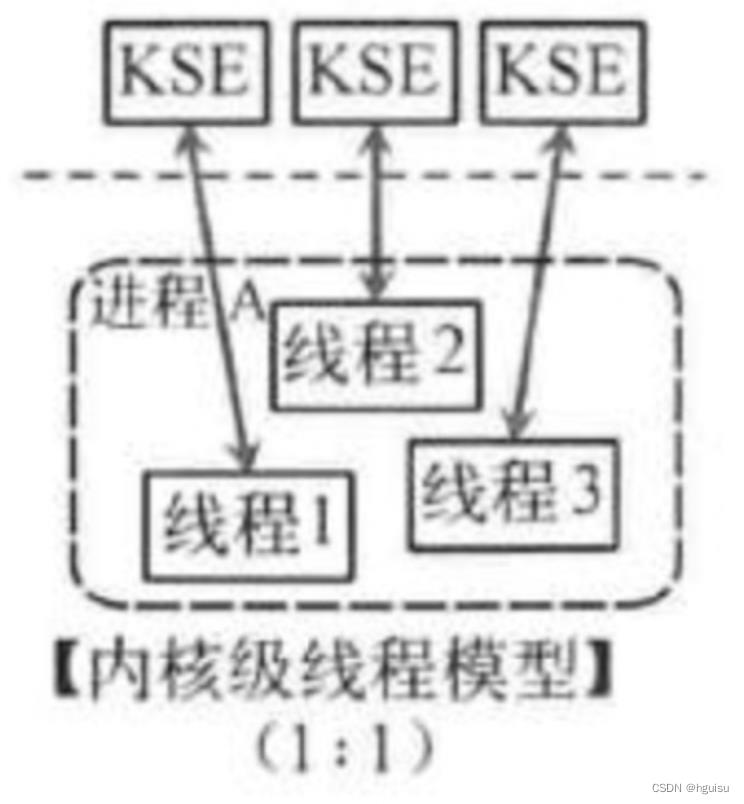
这种模型直接调用操作系统的内核线程,所有线程的创建、终止、切换、同步等操作,都由内核来完成。一个用户态的线程对应一个系统线程,它可以利用多核机制,但上下文切换需要消耗额外的资源。C++就是这种。
两级线程模型

这种模型是介于用户级线程模型和内核级线程模型之间的一种线程模型。这种模型的实现非常复杂,和内核级线程模型类似,一个进程中可以对应多个内核级线程,但是进程中的线程不和内核线程一一对应;这种线程模型会先创建多个内核级线程,然后用自身的用户级线程去对应创建的多个内核级线程,自身的用户级线程需要本身程序去调度,内核级的线程交给操作系统内核去调度。
M个用户线程对应N个系统线程,缺点增加了调度器的实现难度。
Go语言的线程模型就是一种特殊的两级线程模型(GPM调度模型)。
2、Go线程实现模型MPG
M指的是Machine,一个M直接关联了一个内核线程。由操作系统管理。 P指的是”processor”,代表了M所需的上下文环境,也是处理用户级代码逻辑的处理器。它负责衔接M和G的调度上下文,将等待执行的G与M对接。 G指的是Goroutine,其实本质上也是一种轻量级的线程。包括了调用栈,重要的调度信息,例如channel等。
P的数量由环境变量中的GOMAXPROCS决定,通常来说它是和核心数对应,例如在4Core的服务器上回启动4个线程。G会有很多个,每个P会将Goroutine从一个就绪的队列中做Pop操作,为了减小锁的竞争,通常情况下每个P会负责一个队列。
三者关系如下图所示:

以上这个图讲的是两个线程(内核线程)的情况。一个M会对应一个内核线程,一个M也会连接一个上下文P,一个上下文P相当于一个“处理器”,一个上下文连接一个或者多个Goroutine。为了运行goroutine,线程必须保存上下文。
上下文P(Processor)的数量在启动时设置为GOMAXPROCS环境变量的值或通过运行时函数GOMAXPROCS()。通常情况下,在程序执行期间不会更改。上下文数量固定意味着只有固定数量的线程在任何时候运行Go代码。我们可以使用它来调整Go进程到个人计算机的调用,例如4核PC在4个线程上运行Go代码。
图中P正在执行的Goroutine为蓝色的;处于待执行状态的Goroutine为灰色的,灰色的Goroutine形成了一个队列runqueues。
Go语言里,启动一个goroutine很容易:go function 就行,所以每有一个go语句被执行,runqueue队列就在其末尾加入一个goroutine,一旦上下文运行goroutine直到调度点,它会从其runqueue中弹出goroutine,设置堆栈和指令指针并开始运行goroutine。

抛弃P(Processor)
你可能会想,为什么一定需要一个上下文,我们能不能直接除去上下文,让Goroutine的runqueues挂到M上呢?答案是不行,需要上下文的目的,是让我们可以直接放开其他线程,当遇到内核线程阻塞的时候。
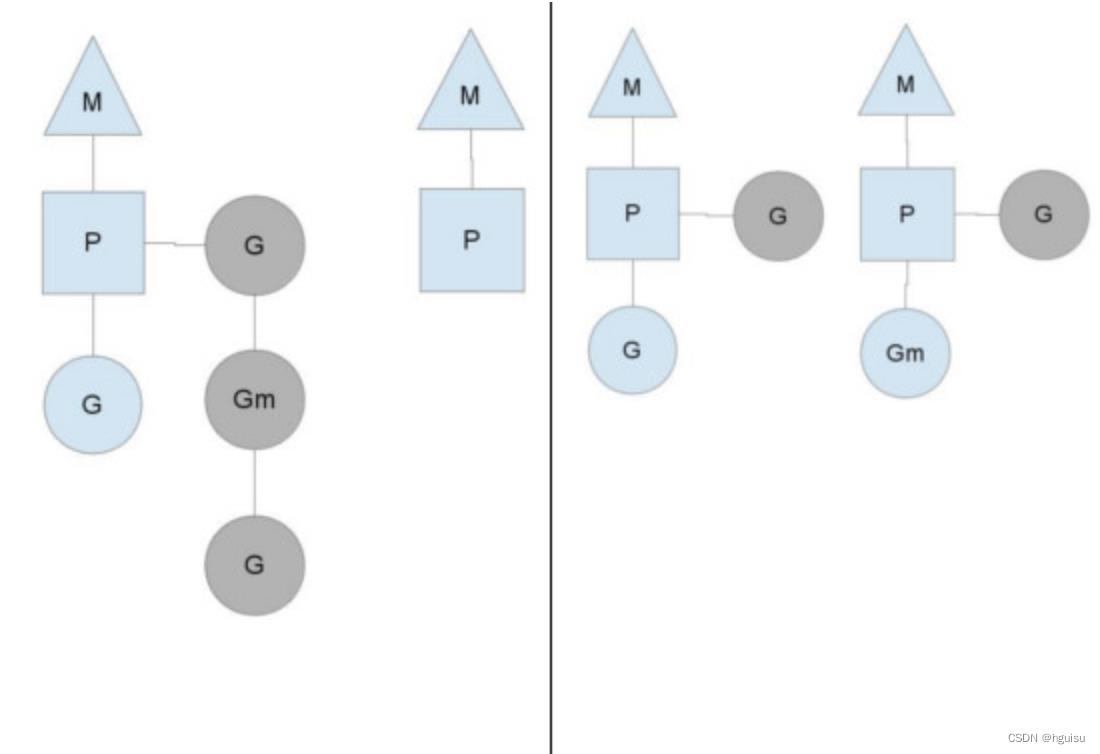
一个很简单的例子就是系统调用sysall,一个线程肯定不能同时执行代码和系统调用被阻塞,这个时候,此线程M需要放弃当前的上下文环境P,以便可以让其他的Goroutine被调度执行。

如上图左图所示,M0中的G0执行了syscall,然后就创建了一个M1(也有可能来自线程缓存),(转向右图)然后M0丢弃了P,等待syscall的返回值,M1接受了P,将·继续执行Goroutine队列中的其他Goroutine。
当系统调用syscall结束后,M0会“偷”一个上下文,如果不成功,M0就把它的Gouroutine G0放到一个全局的runqueue中,将自己置于线程缓存中并进入休眠状态。全局runqueue是各个P在运行完自己的本地的Goroutine runqueue后用来拉取新goroutine的地方。P也会周期性的检查这个全局runqueue上的goroutine,否则,全局runqueue上的goroutines可能得不到执行而饿死。
均衡的分配工作
按照以上的说法,上下文P会定期的检查全局的goroutine 队列中的goroutine,以便自己在消费掉自身Goroutine队列的时候有事可做。假如全局goroutine队列中的goroutine也没了呢?就从其他运行的中的P的runqueue里偷。
每个P中的Goroutine不同导致他们运行的效率和时间也不同,在一个有很多P和M的环境中,不能让一个P跑完自身的Goroutine就没事可做了,因为或许其他的P有很长的goroutine队列要跑,得需要均衡。 该如何解决呢?
Go的做法倒也直接,从其他P中偷一半!
四、Goroutine 小结
1、开销小
POSIX的thread API虽然能够提供丰富的API,例如配置自己的CPU亲和性,申请资源等等,线程在得到了很多与进程相同的控制权的同时,开销也非常的大,在Goroutine中则不需这些额外的开销,所以一个Golang的程序中可以支持10w级别的Goroutine。
每个 goroutine (协程) 默认占用内存远比 Java 、C 的线程少(*goroutine:*2KB ,线程:8MB)
2、调度性能好
在Golang的程序中,操作系统级别的线程调度,通常不会做出合适的调度决策。例如在GC时,内存必须要达到一个一致的状态。在Goroutine机制里,Golang可以控制Goroutine的调度,从而在一个合适的时间进行GC。
在应用层模拟的线程,它避免了上下文切换的额外耗费,兼顾了多线程的优点。简化了高并发程序的复杂度。
大部分参考:golang_development_notes/9.5.md at master · guyan0319/golang_development_notes · GitHub
以上是关于go进阶 -深入理解goroutine并发运行机制的主要内容,如果未能解决你的问题,请参考以下文章