爬虫:多进程爬虫
Posted tree1000
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫:多进程爬虫相关的知识,希望对你有一定的参考价值。
本文测试代码要利用到上一篇文章爬取到的数据,上一章链接:爬虫:获取动态加载数据(selenium)(某站) ,本文要爬取的内容是某乎提问上面的话题关键字
1. 多进程语法
1.1 语法1
import multiprocessing import time def func(x): print(x*x) if __name__ == \'__main__\': start = time.time() jobs = [] for i in range(5): p = multiprocessing.Process(target=func, args=(i, )) jobs.append(p) p.start() end = time.time() print(end - start)
截图如下:先打印时间不知怎么解释?求大佬指点

1.2 语法2
from multiprocessing import Pool import time def func(x, y): print(x+y) if __name__ == \'__main__\': pool = Pool(5) start = time.time() for i in range(100): pool.apply_async(func=func, args=(i, 3)) pool.close() pool.join() end = time.time() print(end - start)
2. 实践测试代码
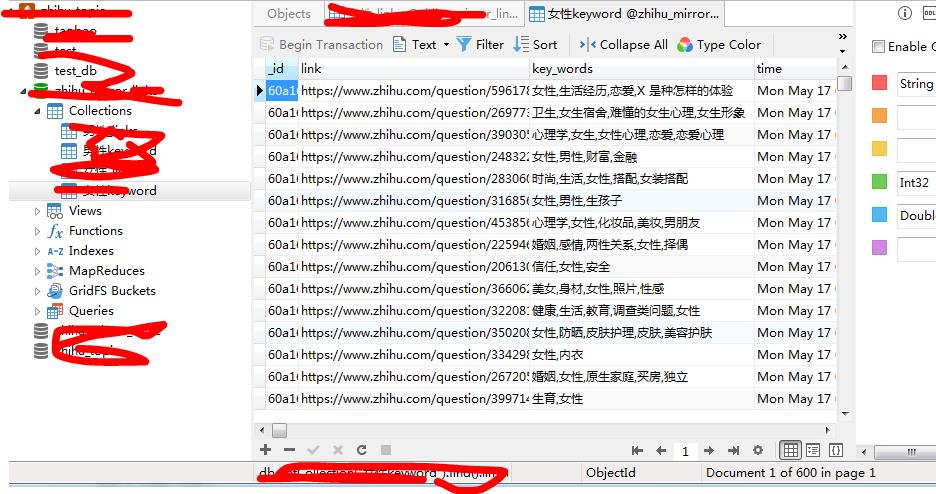
import requests from bs4 import BeautifulSoup import time from requests.exceptions import RequestException from pymongo import MongoClient from multiprocessing import Pool client = MongoClient(\'localhost\') db = client[\'test_db\'] def get_page_keyword(url, word): headers = { \'cookie\': \'\', \'user-agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/78.0.3904.108 Safari/537.36\' } # 替换为自己的cookie try: html = requests.get(url, headers=headers, timeout=5) html = BeautifulSoup(html.text, "html.parser") key_words = html.find("div", {\'class\': \'QuestionPage\'}).find("meta", {\'itemprop\': \'keywords\'}).attrs[\'content\'] print(key_words) with open(r\'女性话题链接.txt\', \'a\') as file: file.write(key_words + \'\\n\') db[u\'\' + word + \'keyword\'].insert_one({"link": url, "key_words": key_words, "time": time.ctime()}) except RequestException: print(\'请求失败\') if __name__ == \'__main__\': input_word = input(\'输入链接文件所属话题(比如:女性):\') f = open(r\'女性2021-5-16-3-8.txt\') # 自己爬取到链接的文件位置 lines = [] for i in f.readlines(): lines.append(i.strip()) # 因为上次爬取链接结尾加了行结束符 EOF f.close() # 多进程测试 pool = Pool(2) # 数字大会快点,但笔者电脑两核,而且数字太大网站一会就说你账号异常 start = time.time() for link in lines: pool.apply_async(func=get_page_keyword, args=(link, input_word)) pool.close() pool.join() end = time.time() print(end - start)
截图:不打算重新跑了,是以前的截图

以上是关于爬虫:多进程爬虫的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫编程思想(138):多线程和多进程爬虫--从Thread类继承