推荐系统论文之序列推荐:KERL
Posted Ethan_CW
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统论文之序列推荐:KERL相关的知识,希望对你有一定的参考价值。
KERL: A Knowledge-Guided Reinforcement Learning Modelfor Sequential Recommendation
摘要
时序推荐是基于用户的顺序行为,对未来的行为进行预测的任务。目前的工作利用深度学习技术的优势,取得了很好的效果。但是这些工作仅专注于所推荐商品的局部收益,并未考虑该商品对于序列长期的影响。
强化学习(RL)通过最大化长期回报为这一问题提供了一个可能的解决方案。但是,在时推荐场景中,用户与商品交互的稀疏性,动态性增加了强化学习的随机探索的难度,使得模型不能很好地收敛。
Specifically, we formalize the sequential recommendation task as a Markov Decision Process (MDP), and make three major technical extensions in this framework, includingstate representation, reward function and learning algorithm.
- 首先,从开发 exploitation 和探索 exploration 两个方面考虑,提出用KG信息增强状态表示。
- 其次,我们精心设计了一个复合奖励函数,该函数能够计算序列级和知识级奖励。
- 第三,我们提出了一种新的算法来更有效地学习所提出的模型。
- 据我们所知,这是第一次在基于RL的序列推荐中明确讨论和利用知识信息,特别是在探索过程中。
1 INTRODUCTION
Sequential recommendation 有许多方法:classic matrix factorization、popular recurrent neural network approaches [5,9,14],通常,这些方法都是用极大似然估计(MLE)来训练,以便逐步拟合观测到的相互作用序列。
强化学习(RL)的最新进展[24]通过考虑最大化长期性能为这一问题提供了一个有希望的解决方案。
- [24] Mastering the game of Go with deep neuralnetworks and tree search. Nature 529, 7587 (2016), 484–489
首先,用户-项目交互数据可能是稀疏的或有限的。 直接学习更困难的优化目标并不容易。
其次,RL模型的核心概念或机制是探索过程。采用单一或随机的探索策略来捕捉用户兴趣的演变可能是不可靠的。从本质上讲,用户行为是复杂多变的,将RL算法应用于顺序推荐,需要一个更可控的学习过程。所以我们以KG数据为指导,采用基于RL的学习方法进行顺序推荐。
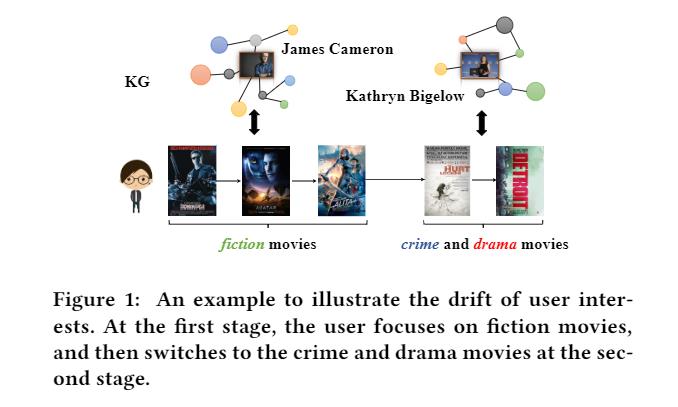
Indeed, KG data has been widely utilized in recommendationtasks [12,26,28]. 但只用在了开发 exploitation 过程,并没有运用到探索 exploration 过程中。如 Figure 1,电影可以被分为两个阶段,直觉上,利用 KG 可以在每个阶段很好地推荐电影,但是这两个阶段的电影在类型,风格和故事等许多方面都本质上是不同的。 现有的了解知识的顺序推荐者很可能会在第一阶段被“困住”,并且无法有效地捕获这两个阶段之间的偏好漂移。
- 【12】2018. Improving Sequential Recommendation with Knowledge-Enhanced Mem-ory Networks. In SIGIR. 505–514.
- 【26】2018. RippleNet: Propagating User Preferences on the KnowledgeGraph for Recommender Systems.
- 【28】2019. KGAT:Knowledge Graph Attention Network for Recommendation. In KDD. 950–958
我们将顺序推荐任务正式化为马尔可夫决策过程(MDP),并在此框架中进行了三项主要的技术扩展。具体包括知识增强的状态表示方法、引入知识的奖励机制,以及基于截断策略的学习机制。
- 首先,提出用KG信息增强状态表示。通过学习序列级和知识级的状态表示,我们的模型能够更准确地捕捉用户偏好。为了实现这一目标,我们构建了一个预测未来用户偏好知识特征的归纳网络。
- 其次,我们精心设计了一个能够同时计算序列级和知识级奖励信号的复合奖励函数。For sequence-level reward,the BLEU metric [21] from machine translation, and measure the overall quality of the recommendation sequence. For knowledge-level reward, we force theknowledge characteristics of the actual and the recommended se-quences to be similar.
- Third, we propose a truncated policy gradientstrategy to train our model. Concerning the sparsity and instabilityin training induction network, we further incorporate a pairwiselearning mechanism with simulated subsequences to improve the learning of the induction network.(没理解)
2 RELATED WORK
Sequential Recommendation.顺序推荐旨在根据用户的历史互动数据来预测他们的未来行为。 早期工作通常利用马尔可夫链来捕获顺序行为的单步依赖性。
- 【22】2010. Factor-izing Personalized Markov Chains for Next-basket Recommendation. In WWW.811–820 设计了个性化的马尔可夫链以提供建议.
- 【27】2015. Learning Hierarchical Representation Model for NextBasket Recommendation.利用表征学习方法对用户和项目之间的复杂交互进行建模。
- 【19】
- 2018. Translation-based factorization ma-chines for sequential recommendation. InRecSys. 63–71. 结合 translation and metric-based approaches for sequential recommendation.
另一条线是对多步顺序行为进行建模,这被证明是顺序推荐的一种更有效的方法,并且基于递归神经网络(RNN)的模型在该领域得到了广泛的应用[5,20,29]。基于RNN的模型可以很好地捕获较长的序列行为进行推荐。
- 【5】2017. Sequential User-basedRecurrent Neural Network Recommendations. InRecSys. 152–160.
- 【20】2017. Personalizing Session-based Recommendations with Hierarchical RecurrentNeural Networks. InRecSys. 130–137
- 【9】2016. Session-based Recommendations with Recurrent Neural Networks. In ICLR
- [14] Wang-Cheng Kang and Julian J. McAuley. 2018. Self-Attentive Sequential Rec-ommendation. In ICDM. 197–206
3 PRELIMINARY
除了用户的历史交互数据,还有一个 KG,其中假设每个item可以与KG对齐。【33】2019. KB4Rec: A Data Set for Linking Knowledge Bases withRecommender Systems. Data Intell.1, 2 (2019), 121–136。
任务定义:主要围绕着 predict the next item 与【12】2018. Improving Sequential Recommendation with Knowledge-Enhanced Mem-ory Networks. InSIGIR. 505–514 设置相似。
4 OUR APPROACH
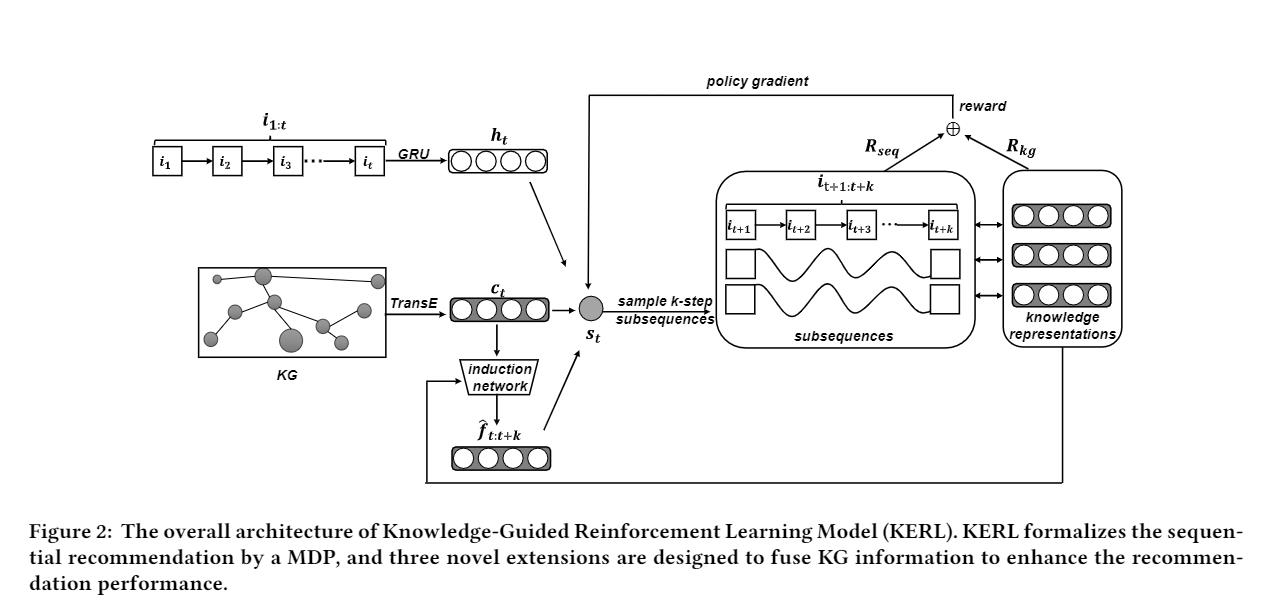
4.1 A MDP Formulation for Our Task
环境状态包含用于顺序推荐的所有有用信息,包括交互历史和KG。st = [ i1:t , G ],其中 G 代表 KG 信息,s0 = [0, G]。Vst 代表状态 st 。
根据状态,the agent 选择一个 action at 属于A,即从课程集合 I 选择中一个课程 it+1 进行推荐。
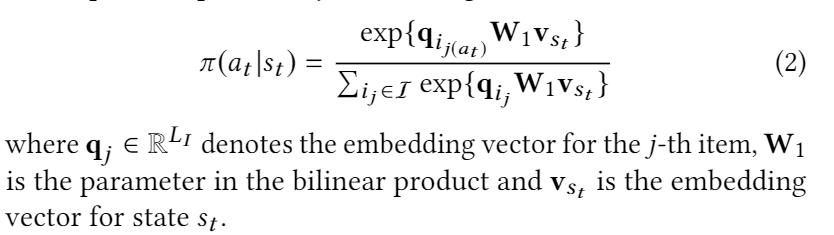
在 action 后,agent 收到一个 reward,例如 rt+1 = R(st, at) , 奖励函数可以反应出推荐的质量。并且状态根据状态转移函数进行更新
T(T:S×T→S):st+1=T(st,at)=T([u, i1:t, G],ij(at))。
4.2 Learning Knowledge-Enhanced State Representation
尽管已经在基于序列的任务中提出了许多RL方法[21,35],但它们主要集中在学习算法上,并且缺乏对外部知识信息的利用
- 【21】2016.Sequence Level Training with Recurrent Neural Networks. InICLR.
- 【35】2019. Reinforcement Learning to Optimize Long-term User Engagement inRecommender Systems. InKDD. 2810–2818.
本文为了 enhance the state representations 分为两部分:sequence-level and knowledge-level state representations.
4.2.1 Sequence-level State Representation.
采用标准的 GRU for encoding previous interaction sequence。这样主要捕获用户偏好的顺序特征,并且不利用知识信息来推导状态表示。

4.2.2 Knowledge-level State Representation.
如【12】,KG 可以用来提高序列推荐的表现。However, previous methods mainly consider enhancing item or user representations with KG data for fitting short-term behaviors with MLE [35]. 所以为了平衡 exploitation and exploration,提出两个 knowledge-based preference for a user,当前知识偏好(简称当前偏好)和未来知识偏好(简称未来偏好)。
- 【12】2018. Improving Sequential Recommendation with Knowledge-Enhanced Mem-ory Networks. InSIGIR. 505–514.
- 【35】2019. Reinforcement Learning to Optimize Long-term User Engagement inRecommender Systems. InKDD. 2810–2818.
Learning Current Preference. 先用 TransE 得到每一个 item it 的 KG embedding Veit ,再使用 平均池方法(a simple average pooling method)来聚合用户与之交互的历史项的 embedding。
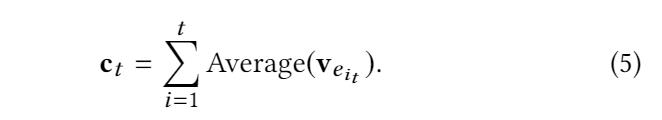
Predicting Future Preference. As the key point to achieve effective exploration,利用未来偏好来捕捉用户在未来时间的兴趣。我们构建了 an induction network 来预测未来偏好。通过使用 全连接网络结果, an induction network 可以更好地捕捉用户兴趣的演变,特别是偏好漂移。

4.2.3 Deriving the Final State Representation.
最后的状态表示为 vst ,where “⊕” is the vector concatenation operator
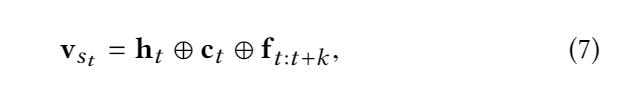
4.3 Setting the Reward with Knowledge Information
把 reward function 分为两部分
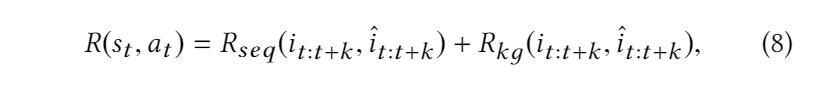
Sequence-level Reward. 在序列推荐中,一个好的奖励函数不仅要考虑单个步骤的表现,还需要衡量推荐序列的整体表现。用上了评估机器翻译的指标 BLEU。
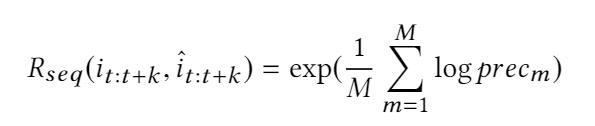
其中 precm 是修正后的精度,计算如下:
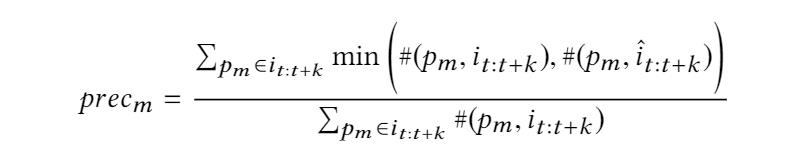
pm is an m-gram subsequence of it:t+k ,# 代表统计前者在后者中出现的次数。
Knowledge-level Reward. 推荐的 item 与一样利用 TransE 聚合,计算相似度,如下:
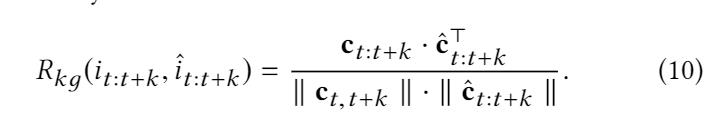
4.4 Learning and Discussion
Based on these subsequences, a pairwise ranking mechanism is then proposed to learn the induction network. 具体算法流程

接下来介绍细节。
4.4.1 Training with Truncated Policy Gradient.
目标是 learn a stochastic policy π that maximizes the expected cumulative reward J(Θ) for all uses. J(Θ) 的导数如下:
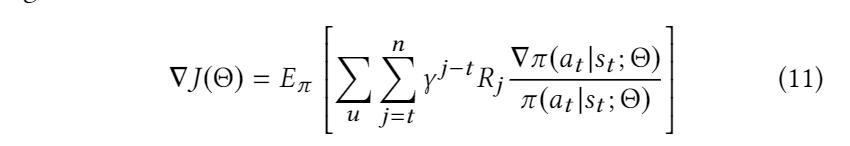
其中 γ is the discount factor to balance the importance of the current reward and future reward。
我们采用了一种截断式的 policy gradient 策略来对目标函数进行优化,对于用户的每个状态 , 随机采样L条长度为 k 的子序列,进行梯度更新:
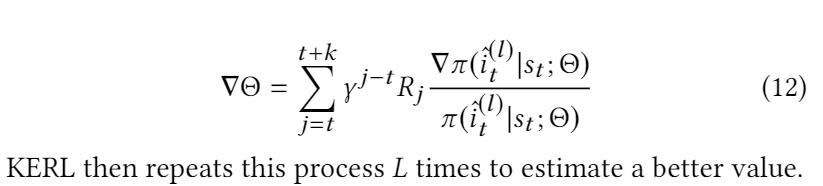
4.4.2 Training the Induction Network.
在 KERL 中我们通过设计一个推断网络来建模历史知识和未来知识的关联。但是训练数据的稀疏性使得该网络不能很好地收敛。考虑到 KERL 通过 policy gradient 策略采样了一系列子序列进行模型的学习,我们试图引入这些序列,通过构造一个排序模型学习推断网络。
具体的,我们先得到每一个序列的知识表达,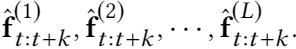 。给定两个子序列知识表达
。给定两个子序列知识表达 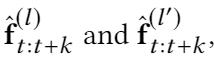 ,我们按照如下的规则构造键对
,我们按照如下的规则构造键对
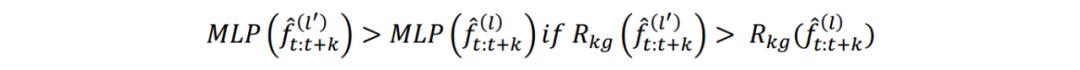
4.4.3 Discussion.
KERL 模型的主要创新之处在于它结合了未来基于知识的偏好,这个在【11】【12】和【28】被忽略了,导致很难捕捉用户兴趣偏移。
- 【11】2019. Taxonomy-Aware Multi-Hop Reasoning Networks for SequentialRecommendation. InWSDM. 573–581.
- 【12】2018. Improving Sequential Recommendation with Knowledge-Enhanced Mem-ory Networks. InSIGIR. 505–514
- 【28】2019. KGAT:Knowledge Graph Attention Network for Recommendation. InKDD. 950–958
尽管以前基于RL的推荐模型[30,35,37]迫使模型最大化长期奖励,但它们要么依赖奖励功能,要么采用随机探索策略。 因此,这些基于RL的模型尚未很好地研究(informative exploration strategy)信息探索策略。
- 【30】2019. Reinforcement Knowledge Graph Reasoning for Explainable Recommenda-tion. InSIGIR.
- 【35】2019. Reinforcement Learning to Optimize Long-term User Engagement inRecommender Systems. InKDD. 2810–2818
- 【37】2019.MarlRank: Multi-agent Reinforced Learning to Rank. InCIKM. 2073–2076.
5. 模型试验效果
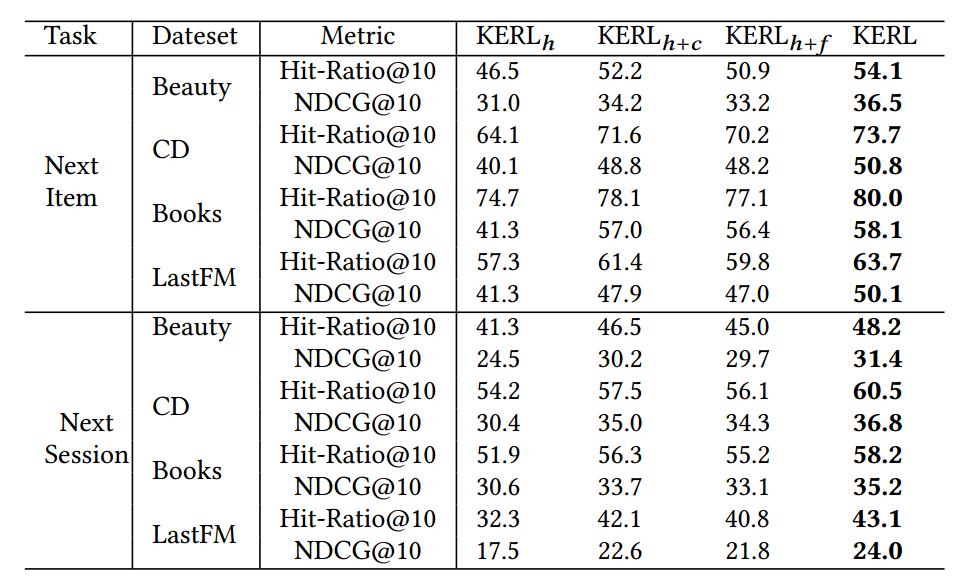
虑到我们的模型把 KG 的信息分别融合进了激励函数和状态表达之中,我们先通过剥离试验来具体的分析每一块的性能。
针对 RL 的状态表示,KERL 总共使用了三种不同的信息,分别是序列信息,历史知识,以及未来知识。我们首先分析一下不同的信息对于性能的影响,具体设计了三种基于不同状态表示 KERL 模型,包括 KERLh 仅用时序的信息;KERLh+c利用时序与历史知识信息; KERLh +f 利用时序与未来知识信息。我们将这三个模型同 KERL 进行比较,具体结果如图下所示:
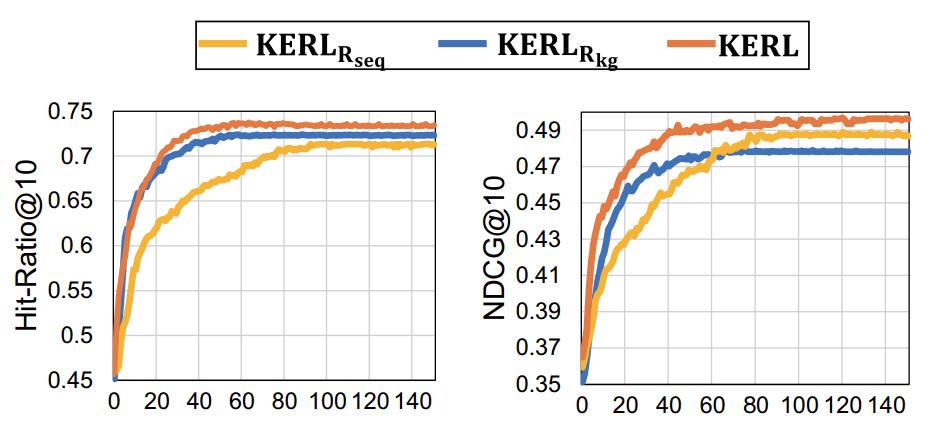
对于激励函数,我们分析了单独考虑时序相似性和知识相似性对于模型性能的影响。下图展现了在 CD 数据集上模型的性能:
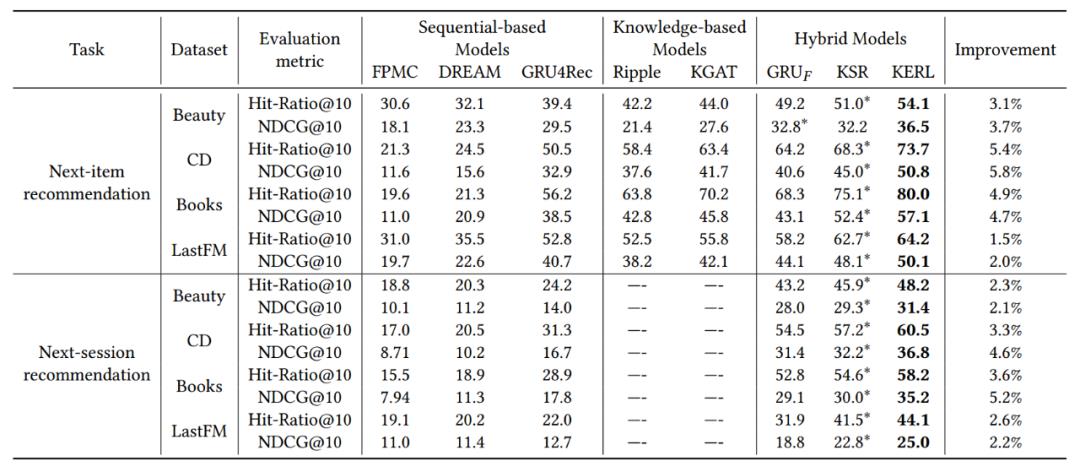
我们在 next-item 和 next-session 两个任务上验证了模型的有效性,KERL 一致超过了所有的基线方法。
6. 总结
该论文首次探讨了将强化学习应用于时序推荐任务的可行性,通过将该任务定义为 MDP 过程,赋予了时序预测模型捕获推荐商品长期收益的能力,并创造性地引入知识对强化学习的探索重复过程进行指导。文章在 next-item 和 next-session 两个推荐任务上验证了模型的有效性。
以上是关于推荐系统论文之序列推荐:KERL的主要内容,如果未能解决你的问题,请参考以下文章