实验4
Posted --艾合
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实验4相关的知识,希望对你有一定的参考价值。
with open(\'data1_1.txt\', \'r\', encoding = \'utf-8\') as f: data=f.readlines() n = 0 for line in data: if line.strip(\'\\n\') == \'\': continue n+=1 print(f\'共{n}行\')
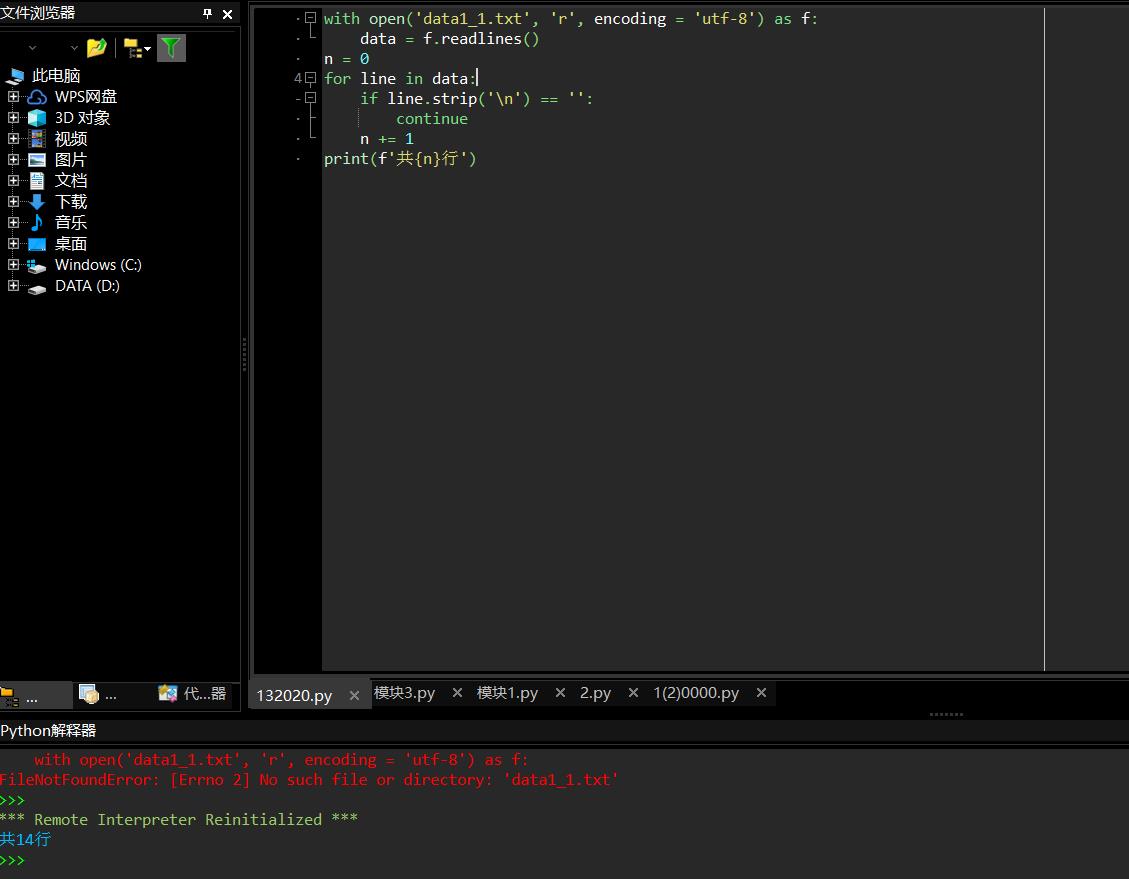
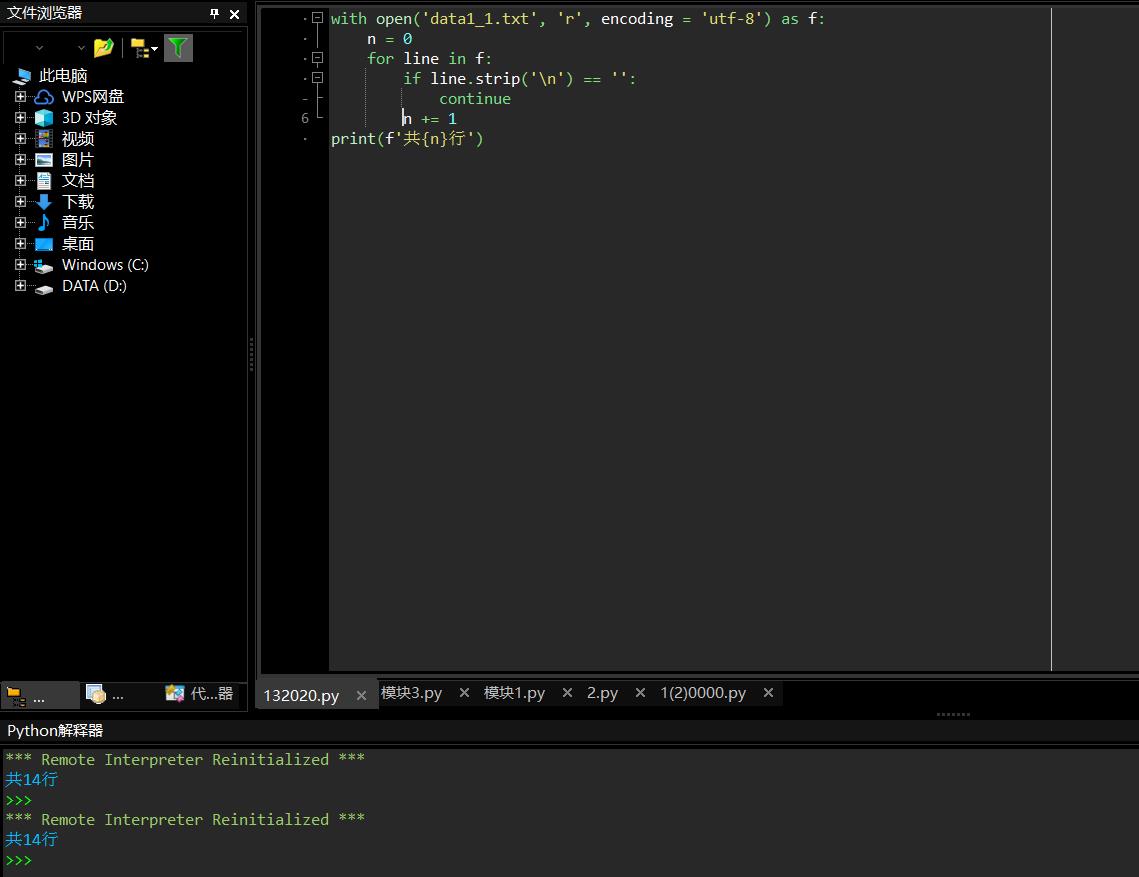
with open(\'data1_1.txt\', \'r\', encoding = \'utf-8\') as f: n = 0 for line in f: if line.strip(\'\\n\') == \'\': continue n += 1 print(f\'共{n}行\')
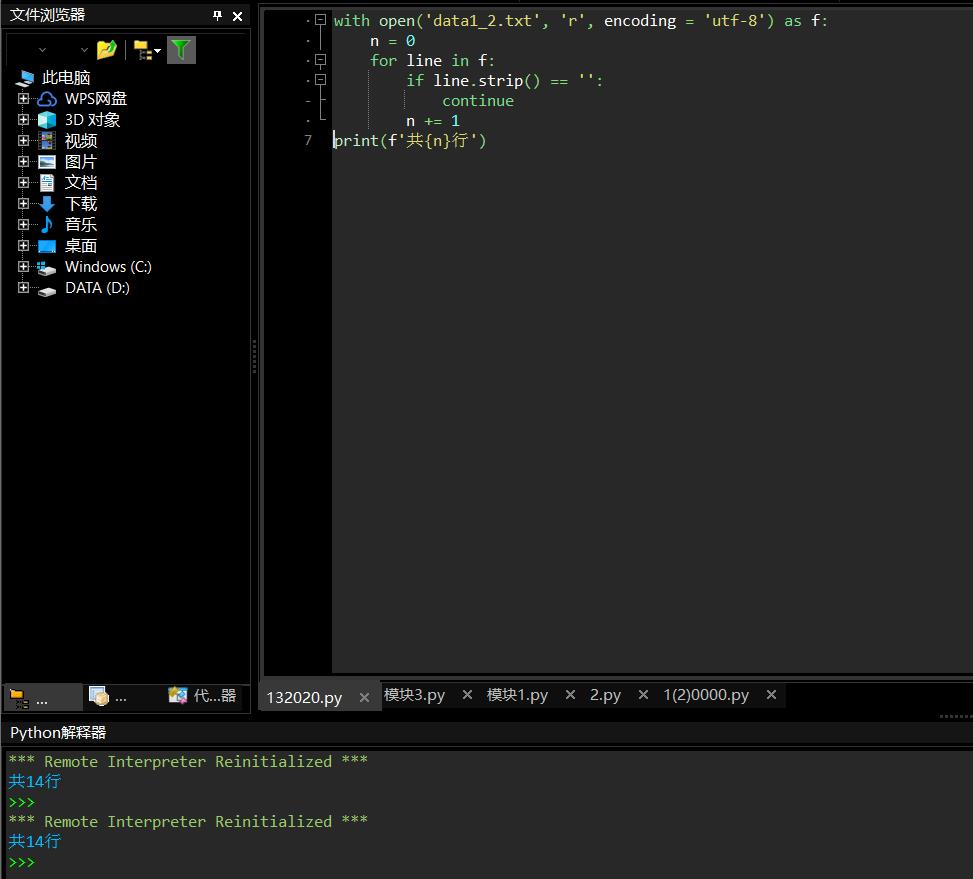
with open(\'data1_2.txt\', \'r\', encoding = \'utf-8\') as f: n = 0 for line in f: if line.strip() == \'\': continue n += 1 print(f\'共{n}行\')
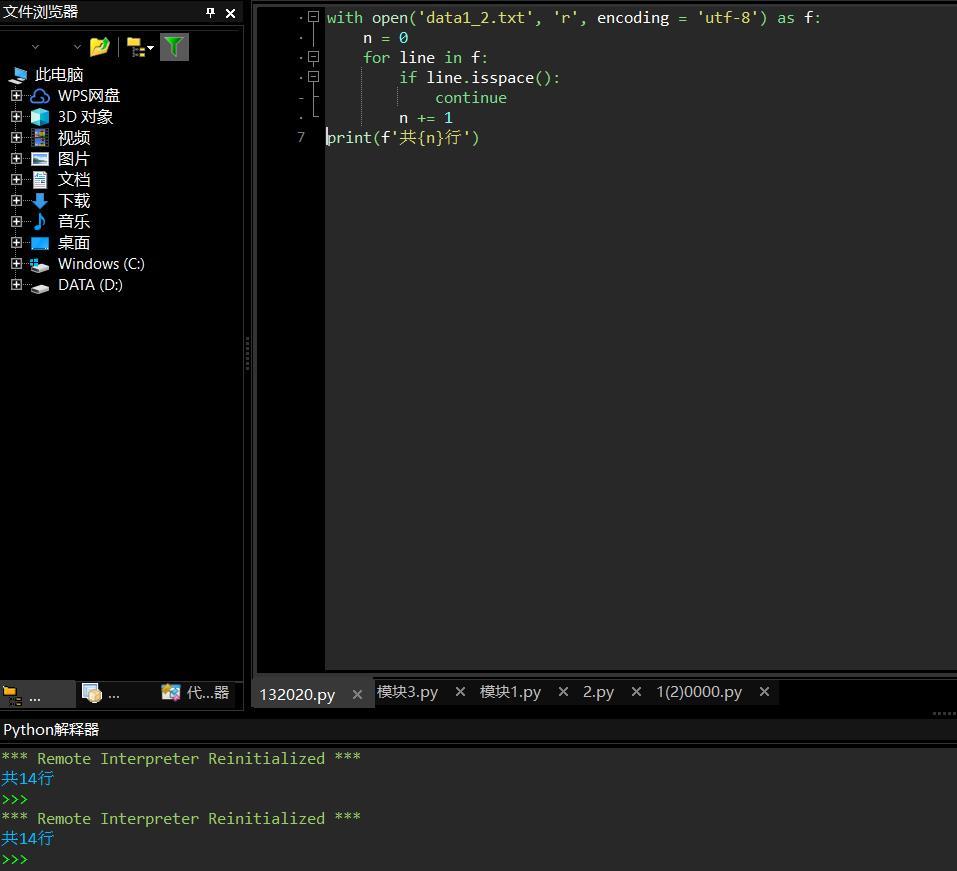
with open(\'data1_2.txt\', \'r\', encoding = \'utf-8\') as f: n = 0 for line in f: if line.isspace(): continue n += 1 print(f\'共{n}行\')
with open(\'data2.txt\', \'r\', encoding = \'utf-8\') as f: data = f.read().split(\'\\n\') unique_line = [] for line in data: if data.count(line) == 1: unique_line.append(line) print(f\'共{ len(unique_line) }独特行\') for i in unique_line: print(i)
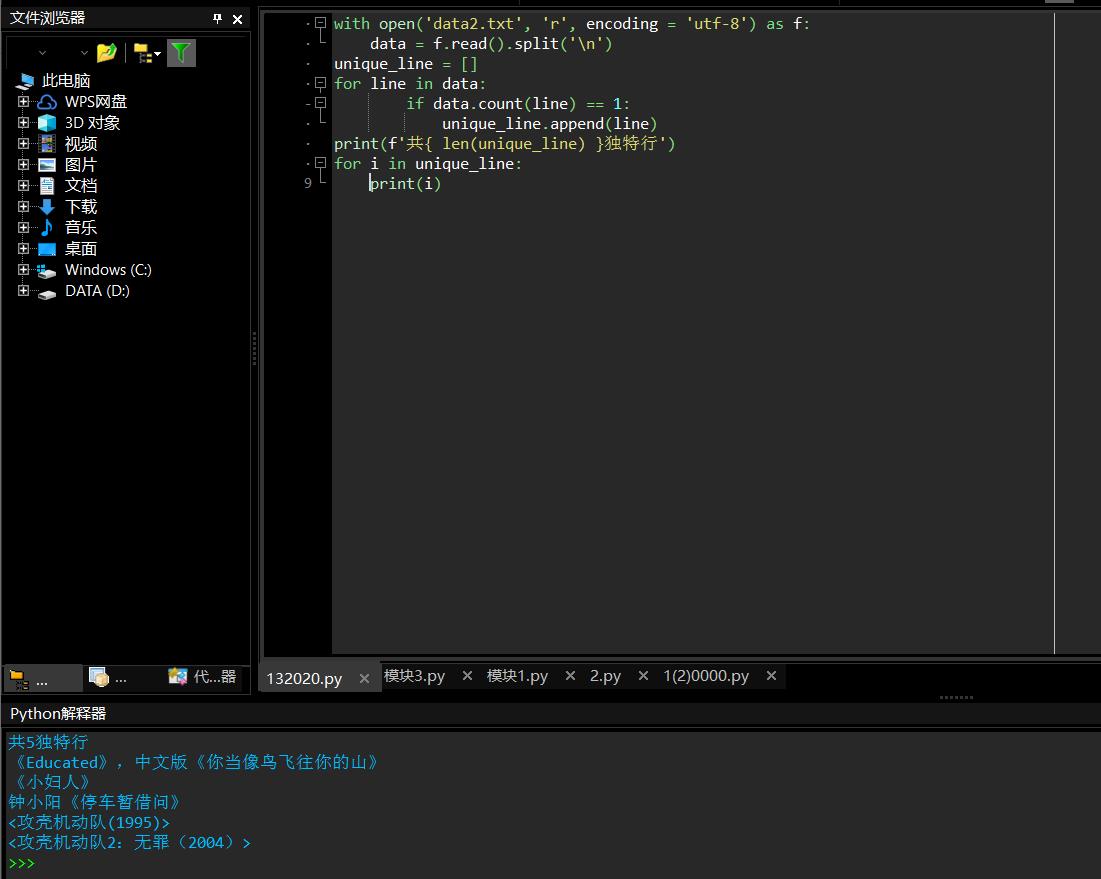
ls = [ [\'城市\', \'大致人口\'], [\'南京\', \'850万\'], [\'纽约\', \'2300万\'], [\'东京\', \'3800万\'], [\'巴黎\', \'1000万\'] ] with open(\'data3.csv\', \'w\', encoding = \'utf-8\') as f: for line in ls: data = \',\'.join(line) + \'\\n\' f.write(data) # 从data3.csv中读出数据,把逗号替换成\\t, 分行打印输出到屏幕上 with open(\'data3.csv\', \'r\', encoding = \'utf-8\') as f: data = f.read() print(data.replace(\',\', \'\\t\'), end = \'\')
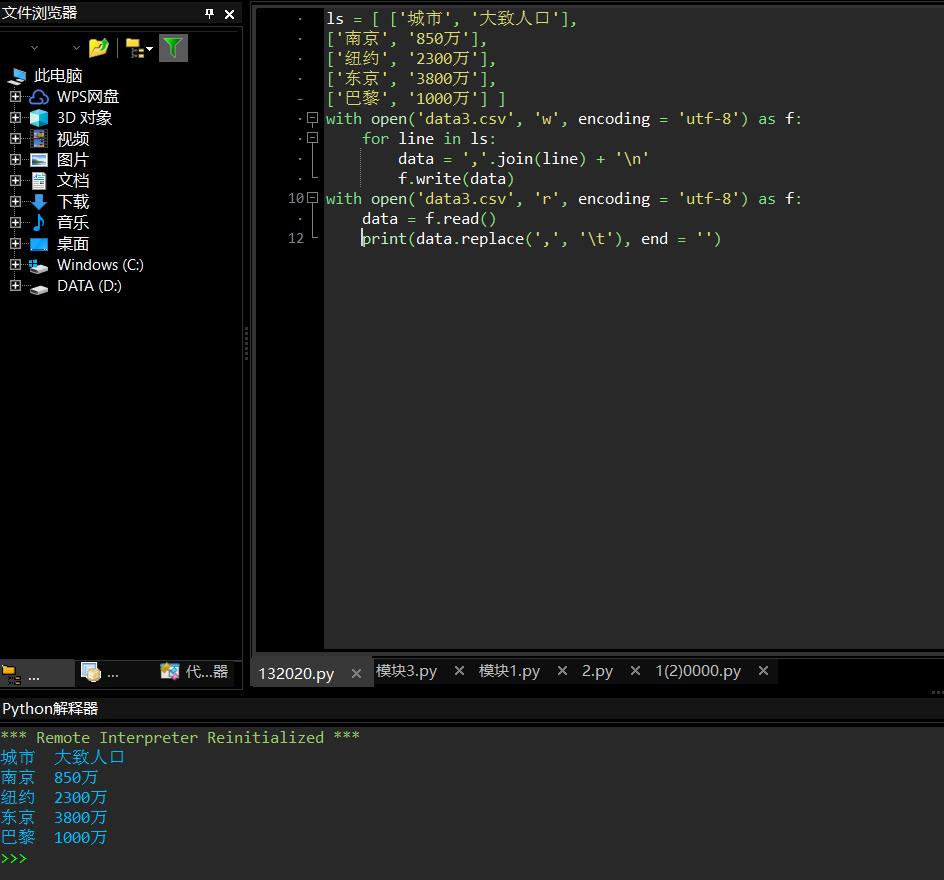
>>> import datetime >>> t = datetime.datetime.now() >>> t.strftime(\'%Y%m%d\') \'20210509\' >>> type( t.strftime(\'%Y%m%d\') ) <class \'str\'>
with open(\'data6_1.txt\', \'r\', encoding = \'utf-8\') as f: x = [] data = f.readlines() for i in data: x.append(i.strip().split()) f = lambda x:x[2] x.sort(key=f,reverse=True) with open(\'data6_2.txt\',\'w\',encoding=\'utf-8\') as fn: for j in x: data1 = \' \' .join(j) data2 = \' \'.join(j) + \'\\n\' print(data1) fn.write(data2)
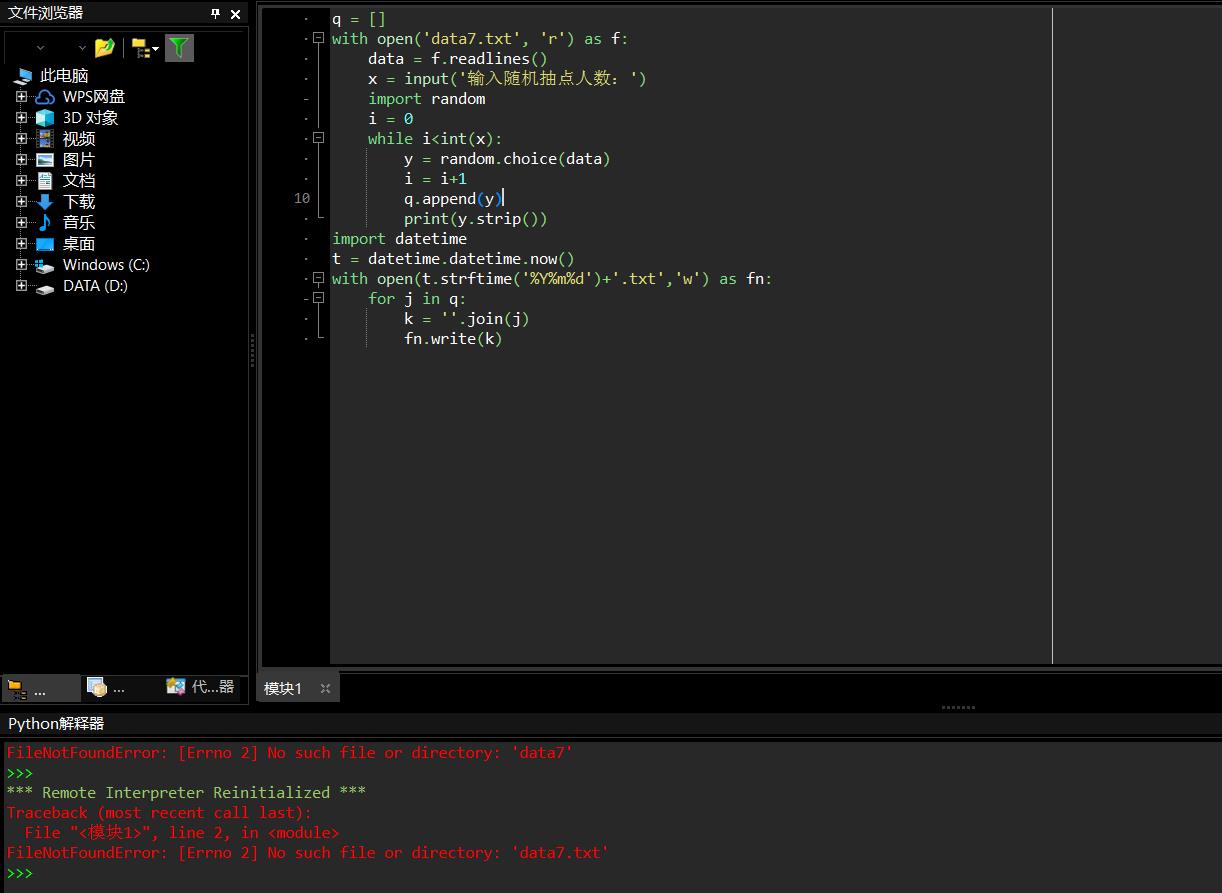
q = [] with open(\'data7.txt\', \'r\') as f: data = f.readlines() x = input(\'输入随机抽点人数:\') import random i = 0 while i<int(x): y = random.choice(data) i = i+1 q.append(y) print(y.strip()) with open(\'lucky.txt\',\'w\') as fn: for j in q: k = \'\'.join(j) fn.write(k)
以上是关于实验4的主要内容,如果未能解决你的问题,请参考以下文章
[NTUSTISC pwn LAB 7]Return to libc实验(puts泄露libc中gadget片段定位)