jieba分词的功能和性能分析
Posted linkcxt
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了jieba分词的功能和性能分析相关的知识,希望对你有一定的参考价值。
-
用户词典大小最大可以有多大
-
用户词典大小对速度的影响
-
有相同前缀和后缀的词汇如何区分
-
对比百度分词的API
问题一:词典大小
从源码大小分析,整个jieba分词的源码总容量为81MB,其中系统词典dict.txt的大小为5.16MB,所以用户词典至少可以大于5.16MB,在从词典中的词语数量来看,系统词典的总的词语数共349047
import pandas as pd
import numpy as np
import os
path = os.getcwd()
print(path)
dict_path = os.path.join(path, \'medical_dict\')
#调用pandas的read_csv()方法时,默认使用C engine作为parser engine,而当文件名中含有中文的时候,用C engine在部分情况下就会出错。所以在调用read_csv()方法时指定engine为Python就可以解决问题了。
res = pd.read_csv(dict_path+\'\\\\部位.txt\',sep=\' \',header=None,encoding=\'utf-8\',engine=\'python\')
res = res.append( pd.read_csv(dict_path+\'\\\\疾病.txt\',sep=\' \',header=None,encoding=\'utf-8\',engine=\'python\') )
res = res.append( pd.read_csv(dict_path+\'\\\\检查.txt\',sep=\' \',header=None,encoding=\'utf-8\',engine=\'python\') )
res = res.append( pd.read_csv(dict_path+\'\\\\手术.txt\',sep=\' \',header=None,encoding=\'utf-8\',engine=\'python\') )
res = res.append( pd.read_csv(dict_path+\'\\\\药品.txt\',sep=\' \',header=None,encoding=\'utf-8\',engine=\'python\') )
res = res.append( pd.read_csv(dict_path+\'\\\\症状.txt\',sep=\' \',header=None,encoding=\'utf-8\',engine=\'python\') )
res = res.append( pd.read_csv(dict_path+\'\\\\中药.txt\',sep=\' \',header=None,encoding=\'utf-8\',engine=\'python\') )
print(res.count())
0 35885
1 35880
2 35880
将35885个医疗词典放入,远比系统词典小。之后导出为一个用户词典,代码如下:
res[2] = res[1]
res[1] = 883635
print(res.head())
res.to_csv(dict_path+\'\\\\medicaldict.txt\',sep=\' \',header=False,index=False)
测试语句
#encoding=utf-8
import jieba
import jieba.posseg as pseg
import os
path = os.getcwd()
# 添加用户词典
jieba.load_userdict(path + "\\\\medical_dict\\\\medicaldict.txt")
print( path + "\\\\medical_dict\\\\medicaldict.txt" )
test_sent = (
"患者1月前无明显诱因及前驱症状下出现腹泻,起初稀便,后为水样便,无恶心呕吐,每日2-3次,无呕血,无腹痛,无畏寒寒战,无低热盗汗,无心悸心慌,无大汗淋漓,否认里急后重感,否认蛋花样大便,当时未重视,未就诊。")
words = jieba.cut(test_sent)
print(\'/\'.join(words))
Building prefix dict from the default dictionary ...
Loading model from cache C:\\Users\\Public\\Documents\\Wondershare\\CreatorTemp\\jieba.cache
Loading model cost 0.921 seconds.
Prefix dict has been built succesfully.
D:\\code\\jiebafenci\\jieba\\medical_dict\\medicaldict.txt
患者/1/月前/无/明显/诱因/及/前驱/症状/下/出现/腹泻/,/起初/稀便/,/后/为/水样便/,/无/恶心/呕吐/,/每日/2/-/3/次/,/无/呕血/,/无/腹痛/,/无/畏寒/
寒战/,/无/低热/盗汗/,/无/心悸/心慌/,/无/大汗淋漓/,/否认/里急后重/感/,/否认/蛋/花样/大便/,/当时/未/重视/,/未/就诊/。
结果正常,判别一条症状的响应速度快,jieba分词是足以将所有的医疗词汇放入,对于性能的影响可以在进一步分析。
问题二:词典大小对效率的影响
-
35885个词语,1条测试语句
load time: 1.0382411479949951s
cut time: 0.0s
-
71770个词语,1条测试语句
load time: 1.4251623153686523s
cut time: 0.0s
-
1148160个词语
load time: 7.892921209335327s
cut time: 0.0s
逐渐变慢了
-
2296320个词语
load time: 15.106632471084595s
cut time: 0.0s
在本机已经开始变得很慢了
-
4592640个词语
load time: 30.660043001174927s
cut time: 0.0s
-
9185280个词语
load time: 56.30760192871094s
-
18370560个词语
load time: 116.30s
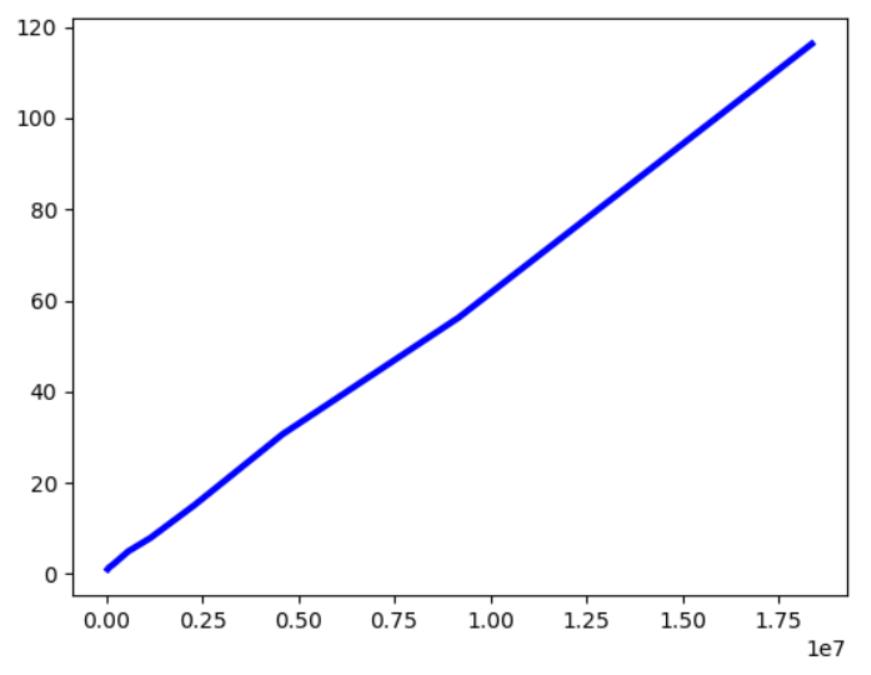
制作为折线图如上,基本上词语大小和加载速度呈正比。但是加载的词典一般保留在内存中,对内存和I/O负担较大。
之后将2220条病史数据导入后,对分词处理时间依然没有什么影响,在0.1s以内,分词时间可以忽略。
问题三:有相同前缀和后缀的词汇如何区分
-
关于无尿急、尿频、尿痛,在jieba分词导入用户词典后是能正确区分的,相关病例如下
/患者/3/小时/前/无/明显/诱因/出现/上/腹部/疼痛/,/左/上腹/为主/,/持续性/隐痛/,/无/放射/,/无/恶心/及/呕吐/,/无/泛酸/及/嗳气/,/无/腹胀/及/腹泻/,/无/咳嗽/及/咳痰/,/无/胸闷/及/气急/,/无/腰酸/及/腰疼/,/无/尿急/、/尿频/及/尿痛/,/无/头晕/,/无/黒/曚/,/无/畏寒/及/发热/,/无尿/黄/,/无/口苦/,/来/我院/求治/。
但是无尿黄划分成了无尿/黄,在查找用户词典后,发现是词典中没有尿黄的症状,为词典问题,便跳过处理。但是在症状中确实同时存在无尿和尿频,初步分析可能是词语在词典中的顺序,或者是jieba分词系统内部的分词策列导致,现在分析第一种可能,在词典中无尿在14221行,尿频在13561行,现在将无尿放在第一行,看分词结果。结果仍然为无/尿频,所以结果为是jieba分词内部的算法策略,当两个词语的词频相同是,后匹配的词语优先,比如在词语匹配中尿频比无尿后匹配,所以最后区分尿频,这与正确的分法也相匹配。
-
再比如腰部酸痛,在部位中有腰部这个词语,在症状中也有腰部酸痛这个词语,测试jieba分词会如何区分
测试词典:
腰部 883635
酸痛 883635
腰部酸痛 883635
测试结果:
腰部酸痛
将词典顺序交换后,并将腰部和疼痛的词频都设置成大于883635的值后,结果仍然是腰部酸痛,所以可以得出jieba分词更倾向于分长度更长的词语,即使短的词语的词频较大也会优先分长度更长的。而我去向自己学医的同学了解后,他也认为分成长词更合理,所以也不用处理。
-
在查看病例中,发现很多病例中存在方位名 + 部位名的词语,并且应该分成一个词语,如下代码实现添加方位名+部位名的词典,如词典中已经存在,便跳过。
res = pd.read_csv(dict_path+\'\\\\部位.txt\',sep=\' \',header=None,encoding=\'utf-8\',engine=\'python\')
direct = [\'上\',\'下\',\'左\',\'右\',\'前\',\'后\']
print(res[0].head())
resum = res[0].count()
print(resum)
result = res[0]
# 在部位名前加上方位名
for item in res[0].tolist():
if(item[0] in direct):
continue
else:
temp = Series([\'左\' + item, \'右\' + item], index = [resum+1,resum+2])
resum = resum + 2
result = result.append(temp)
print(result.tail())
df = pd.DataFrame(result)
print(df.describe())
百度分词
github地址 : https://github.com/baidu/lac/
实现代码
from LAC import LAC
# 装载分词模型
lac = LAC(mode=\'seg\')
# 单个样本输入,输入为Unicode编码的字符串
text = u"LAC是个优秀的分词工具"
seg_result = lac.run(text)
# 批量样本输入, 输入为多个句子组成的list,平均速率会更快
texts = [u"腰部酸痛"]
lac.load_customization(\'userdict.txt\', sep=None)
seg_result = lac.run(texts)
print(seg_result)
用户词典只需要添加词语和词性即可。经过测试得到结论:
1.百度分词无词频的概念,但是也更倾向于分长度更长的词语。
以上是关于jieba分词的功能和性能分析的主要内容,如果未能解决你的问题,请参考以下文章