基于python的pixiv爬虫
Posted 灰咕咕
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于python的pixiv爬虫相关的知识,希望对你有一定的参考价值。
基于python的pixiv爬虫
1、目标
在和朋友吹逼过程中,突发奇想想做一个p站每日推荐色图的色图机,遂学习爬虫。
目标:
- 批量下载首页色图。
- 由于对qq机器人不熟,先利用flask搭键一个网页色图机。
2、流程
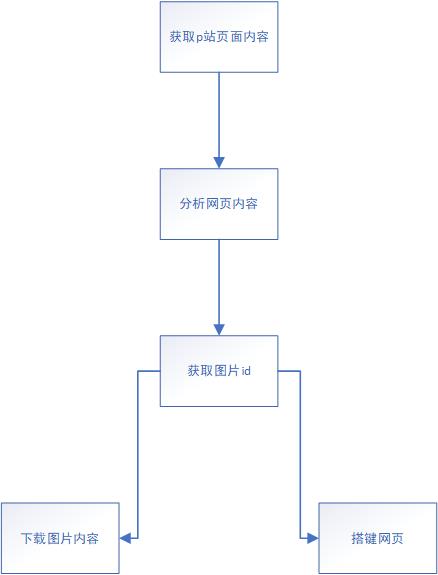
3、批量下载
1、分析网页
虽然直接进入pixiv的主页是需要登录的,但是进入排行榜却不需要这个过程。
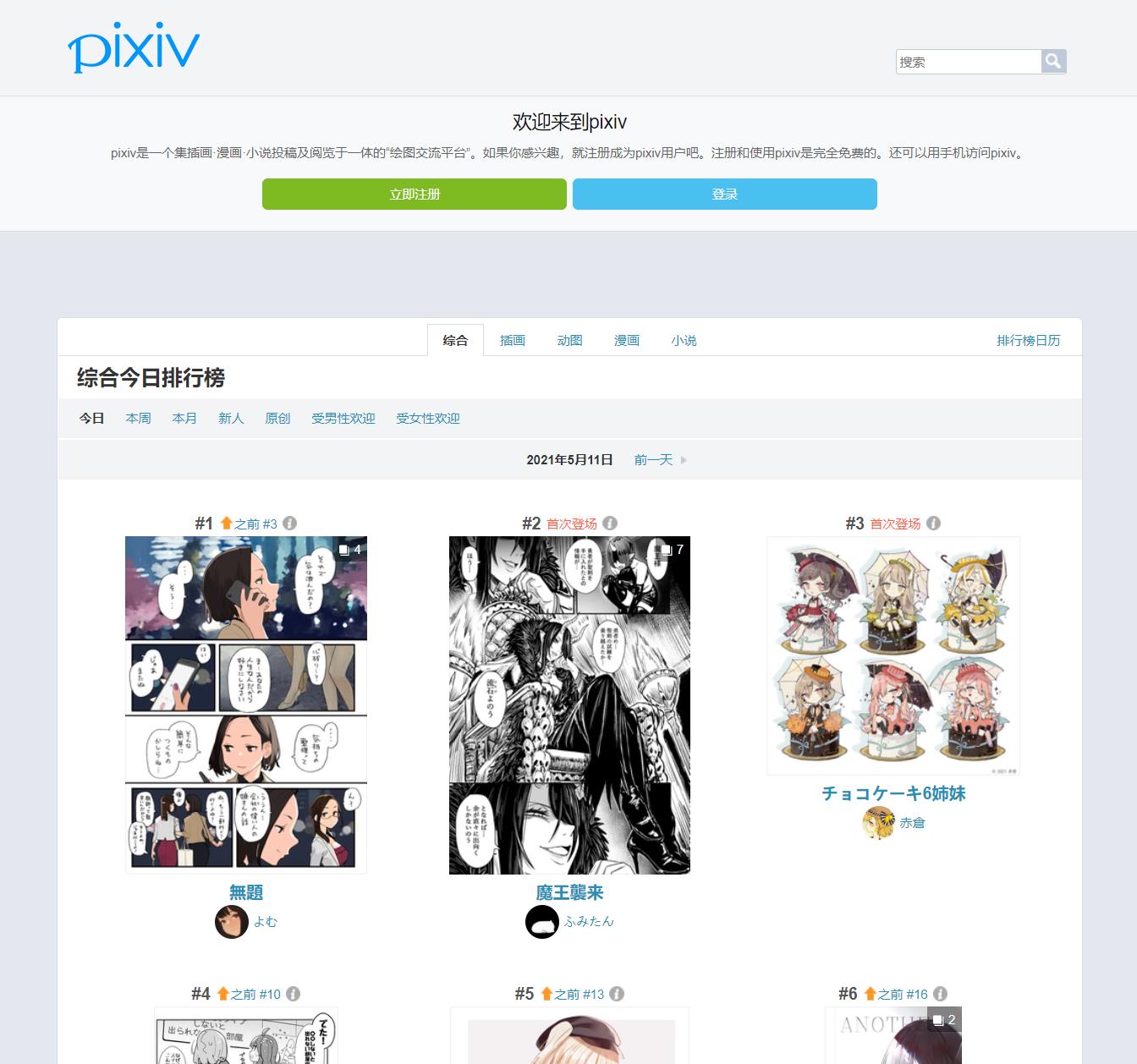
我们通过网页源代码定位到图片id
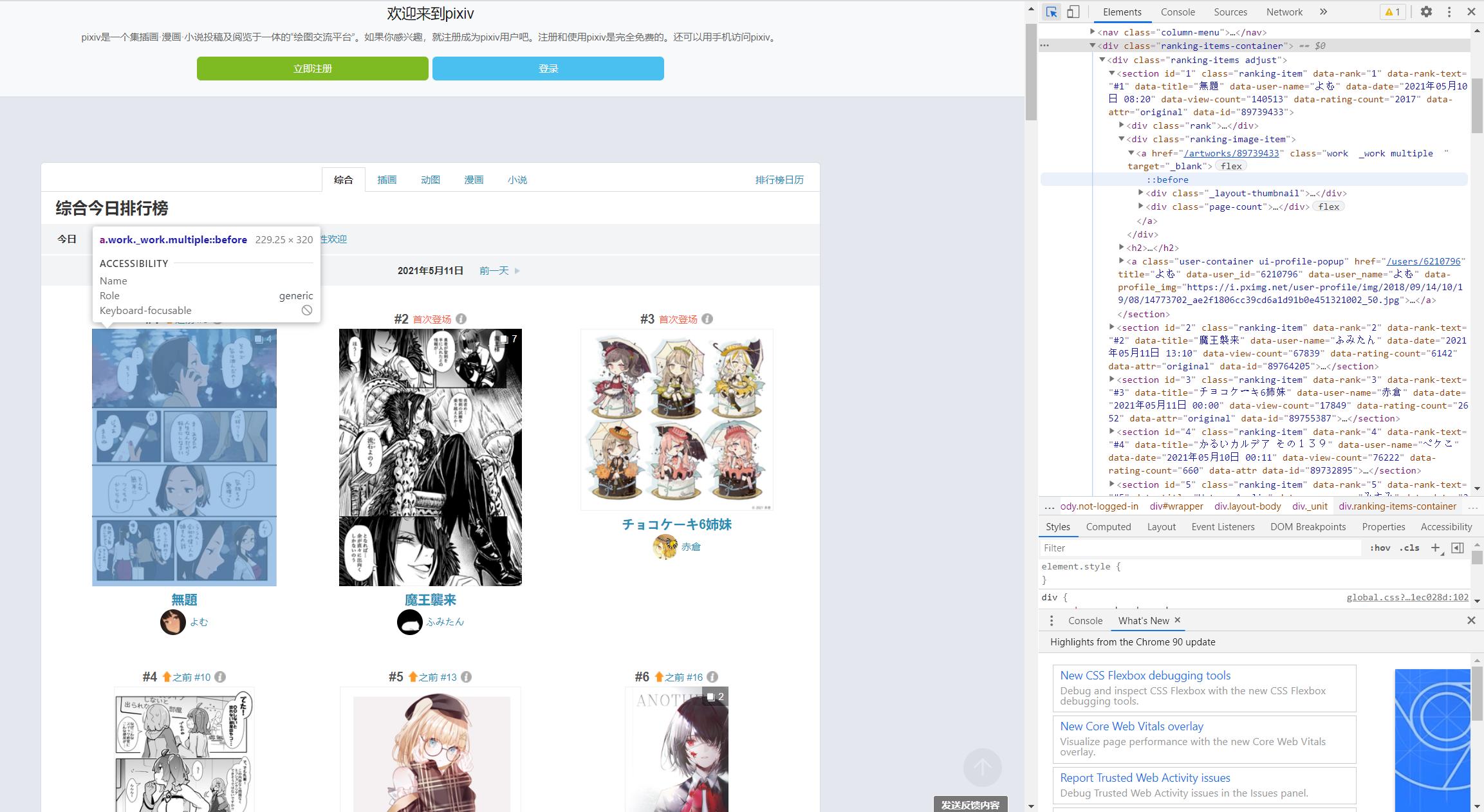
<section id="1" class="ranking-item" data-rank="1" data-rank-text="#1" data-title="無題" data-user-name="よむ" data-date="2021年05月10日 08:20" data-view-count="140513" data-rating-count="2017" data-attr="original" data-id="89739433"><div class="rank"><h1><a href="#1" class="label ui-scroll" data-hash-link="true">#1</a><i class="up sprites-up"></i></h1><p><a href="ranking.php?mode=daily&date=20210510&p=1&ref=rn-b-1-yesterday-3#3" target="_blank">之前 #3</a></p><i class="_icon sprites-info open-info ui-modal-trigger"></i></div><div class="ranking-image-item"><a href="/artworks/89739433" class="work _work multiple " target="_blank"><div class="_layout-thumbnail"><img src="https://i.pximg.net/c/240x480/img-master/img/2021/05/10/08/20/13/89739433_p0_master1200.jpg" alt="" class="_thumbnail ui-scroll-view" data-filter="thumbnail-filter lazy-image" data-src="https://i.pximg.net/c/240x480/img-master/img/2021/05/10/08/20/13/89739433_p0_master1200.jpg" data-type="illust" data-id="89739433" data-tags="がんばれ同期ちゃん 予定調和 マニキュア オリジナル7500users入り 知ってる" data-user-id="6210796" style="opacity: 1;"></div><div class="page-count"><div class="icon"></div><span>4</span></div></a></div><h2><a href="/artworks/89739433" class="title" target="_blank" rel="noopener">無題</a></h2><a class="user-container ui-profile-popup" href="/users/6210796" title="よむ" data-user_id="6210796" data-user_name="よむ" data-profile_img="https://i.pximg.net/user-profile/img/2018/09/14/10/19/08/14773702_ae2f1806cc39cd6a1d91b0e451321002_50.jpg"><div class="_user-icon size-32 cover-texture ui-scroll-view" data-filter="lazy-image" data-src="https://i.pximg.net/user-profile/img/2018/09/14/10/19/08/14773702_ae2f1806cc39cd6a1d91b0e451321002_50.jpg" style="background-image: url("https://i.pximg.net/user-profile/img/2018/09/14/10/19/08/14773702_ae2f1806cc39cd6a1d91b0e451321002_50.jpg");"></div><span class="user-name">よむ</span></a></section>
可以看到这张图片的详细信息
data-rank="1" #排名为第一
data-user-name="よむ" #作者名为よむ
data-id="89739433" #图片id为89739433
还有一个重要信息,是我在后期进行下载和引用时才发现的
class="page-count"><div class="icon"></div><span>4</span></div>
因为排行榜上的并非都是单张插画,也有此类多张的漫画,给我们的爬虫工作增加了许多困难。
2、分析动态页面
我们在分析了这个页面所有的内容后,发现在主页面,只显示了至多50张图片的信息,但其实每日排行的图片远远不止这个数量,但是pixiv并非像豆瓣或者bangumi拥有静态的目录,而且采取动态加载的方法,一直往下滑,则页面一直加载。
滑了半天,得知每日图片推荐一共有500张图片
对于动态页面,我们采取抓包查看每次动态加载的具体内容。
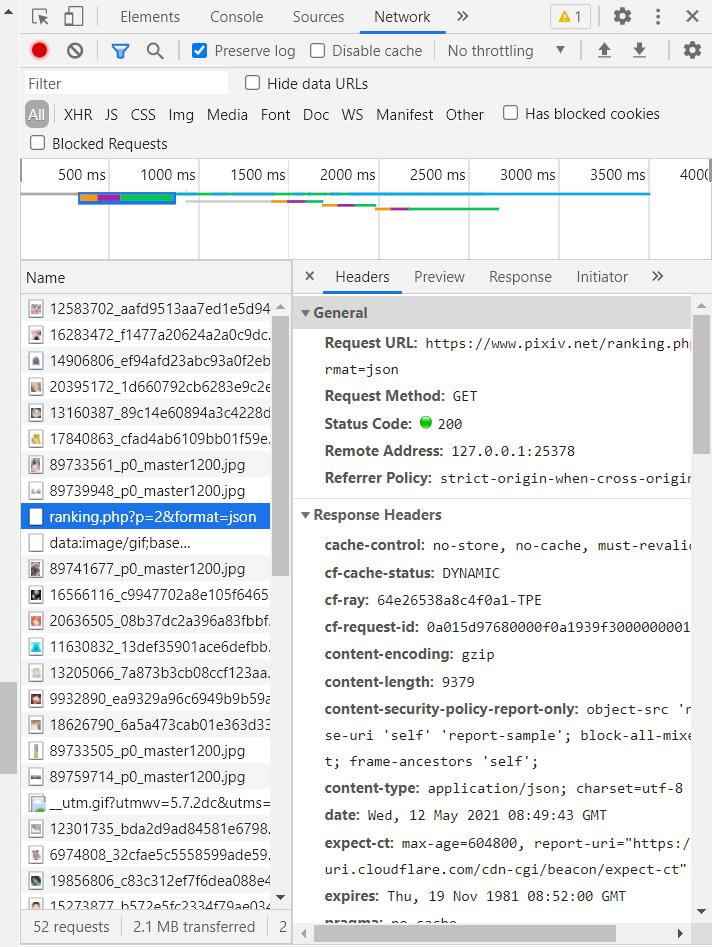
除了不停加载的图片信息,我们抓到一条请求
https://www.pixiv.net/ranking.php?p=2&format=json
我们查看这个页面

显然,这是排行榜第二页的内容,我们将p=2改为p=1,同样显示了第一页的内容,也就是说,每次发送请求,则返回50张图片的信息,发送十次请求,则可以获得500张照片的信息,那么接下来的工作就简单了。
3、热门图片信息获取
抓取的网页并非html标准格式的,我们不能也没必要用bs4进行内容分析,直接用正则表达式即可。
我们先用request请求获取十个页面,并且打印出来看下是否正确。
import requests
headers = {
\'user-agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36\',
\'referer\': \'https://www.pixiv.net/ranking.php?mode=daily&content=illust\',
}
for i in range(1, 11):
url = \'https://www.pixiv.net/ranking.php?p=%d&format=json\' % i
res = requests.get(url, headers=headers)
print(res.text)
打印结果太多了,和上图浏览器中结果相同,就不做展示,正确的打印了十次请求获取的数据。
下面我们通过正则表达式获取每次请求中我们需要的内容,并打印查看
import re
id = re.findall(\'"illust_id":(\\d+)\', res.text)
for i in id:
print(i)
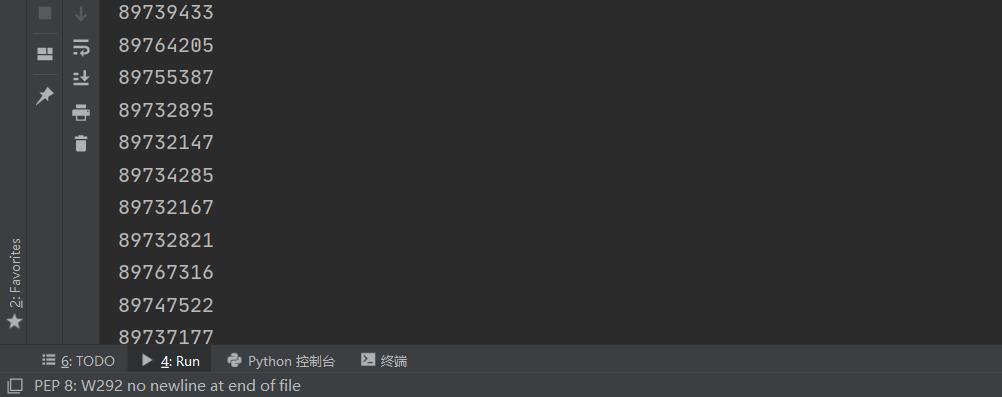
图片id就哗啦啦地出来了,检查打印下len(id)每组都为50个,一切无误。
同时,我们也将每一组图片的张数进行获取,方便之后的显示、下载。
count = re.findall(\'"illust_page_count":"(\\d+)"\', res.text)
4、图片下载
拿到了排行榜图片的id、张数,下一步是对其进行下载。
能否进行下载一直是我很担心的一个难点,因为有的图片尺度过大,在未登录时是无法直接进行访问的。

我们先进入一张普通图片的页面,寻找图片下载的地址
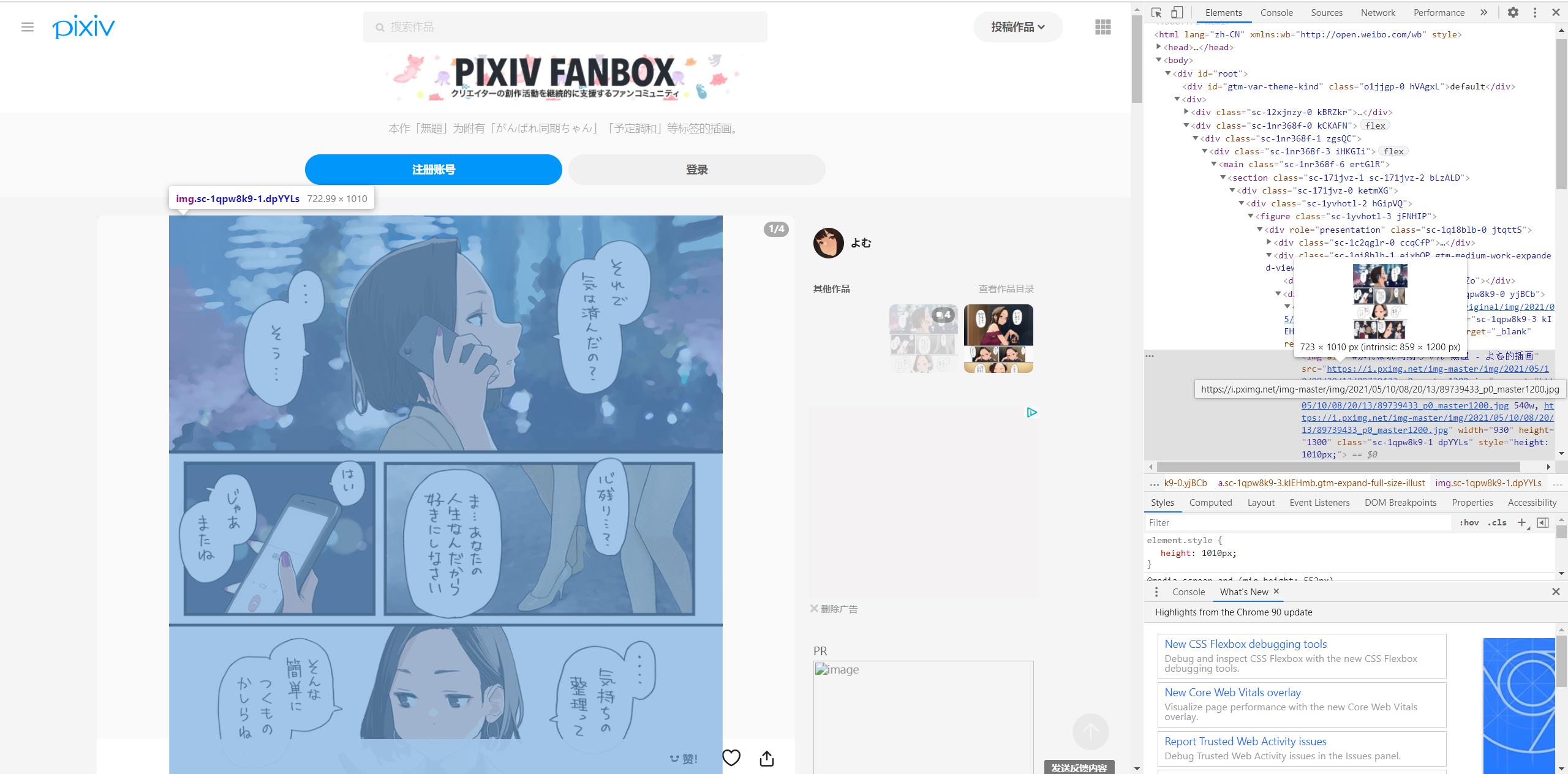
<div role="presentation" class="sc-1qpw8k9-0 yjBCb"><a href="https://i.pximg.net/img-original/img/2021/05/10/08/20/13/89739433_p0.png" class="sc-1qpw8k9-3 kIEHmb gtm-expand-full-size-illust" target="_blank" rel="noopener"><img alt="#がんばれ同期ちゃん 無題 - よむ的插画" src="https://i.pximg.net/img-master/img/2021/05/10/08/20/13/89739433_p0_master1200.jpg"
拿到图片下载的地址。
我注意到,这个标签的role的值为presentation,之后如果使用bs4进行查找,则可以轻松获得下载地址。
url = \'https://www.pixiv.net/artworks/89739433\'
res = requests.get(url, headers=headers)
with open(\'test.txt\',\'wb\') as f :
f.write(res.text.encode(\'utf8\'))
我们通过requests访问一下试试
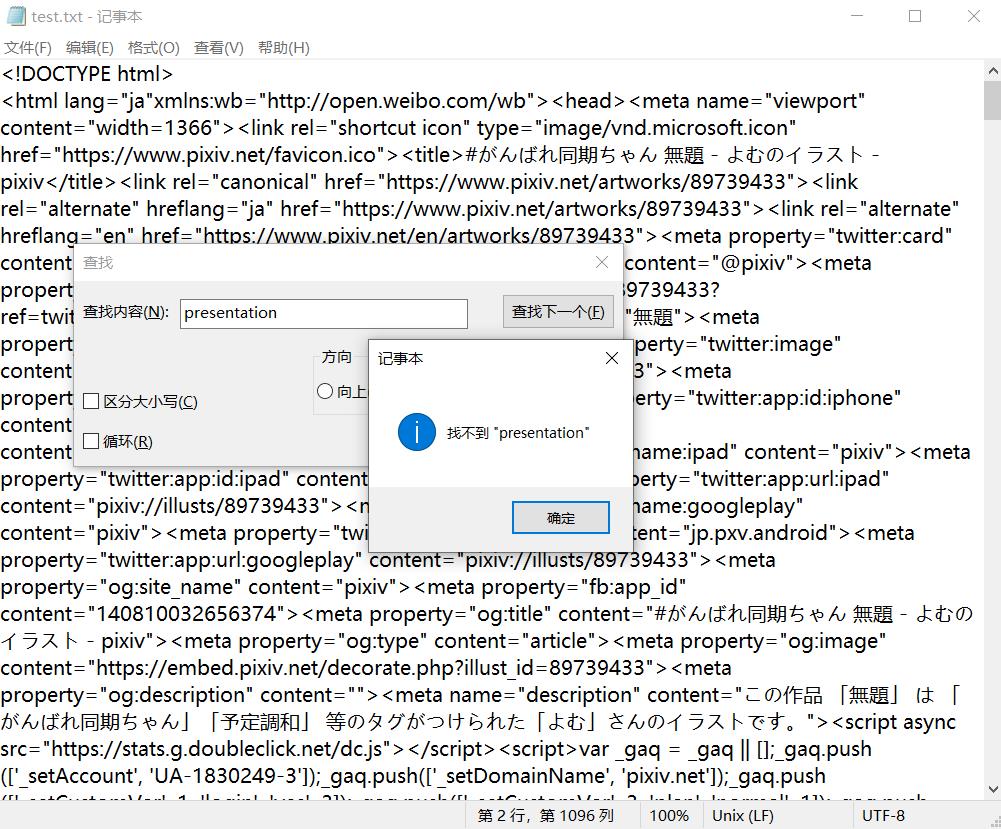
然而,离谱的事情就出现了,那就是我们通过浏览器直接访问的内容和爬虫访问的内容是不一样的。不过还好,就算不一样,仍然可以拿到链接。
在txt文件中搜索https://i.pximg.net/img-original,我们找到了
"original":"https://i.pximg.net/img-original/img/2021/05/10/08/20/13/89739433_p0.png"}
通过正则,便可获取到这个下载地址
result = re.findall(r\'"original":"(.+?)"\',res.text)
在下载图片时,我们需要给图片命名,分为文件名和后缀名,全部通过正则提取。
pic_name = re.findall(r\'"illustTitle":"(.+?)"\', res.text)[0]
extension = re.findall(r\'....$\', pic_url)[0]
下载图片时,我用最简单的方法,将原始的url的末尾删除,for循环改变p的值,拼接上文件后缀名,从而达到下载一组多张图片的功能
pic_url = re.sub(\'.....$\',\'\',pic_url)
# 下载图片
for i in range(0,int(count)):
url = pic_url+str(i)+extension
print(url)
pic = requests.get(url, headers=headers)
with open(\'%s%d%s\' % (pic_name, i, extension), \'wb\') as f:
f.write(pic.content)
最后,将之前所有的代码整合,构造一个函数,输入图片id和图片张数,自动下载。
def download(id, count):
headers = {
\'user-agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36\',
\'referer\': \'https://www.pixiv.net/ranking.php?mode=daily&content=illust\',
}
url = \'https://www.pixiv.net/artworks/%d\' % id
res = requests.get(url, headers=headers)
pic_url = re.findall(r\'"original":"(.+?)"\', res.text)[0]
pic_name = re.findall(r\'"illustTitle":"(.+?)"\', res.text)[0]
# 获取后缀
extension = re.findall(r\'....$\', pic_url)[0]
pic_url = re.sub(\'.....$\',\'\',pic_url)
# 下载图片
for i in range(0,int(count)):
url = pic_url+str(i)+extension
print(url)
pic = requests.get(url, headers=headers)
with open(\'%s%d%s\'% (pic_name, i, extension), \'wb\') as f:
f.write(pic.content)
5、debug
获取到了图片的id和张数,并且构造了输入id和张数就能自动执行脚本的函数,将两者稍作整合,结果在运行时报错:
OSError: [Errno 22] Invalid argument: \'./ex/電車で寄りかかられたOLと寄りかかってきた居眠り(?)JK1.jpg\'
显然,文件命名不能包含\'?\',于是添加正则去除这些符号
if re.search(\'[\\\\\\ \\/ \\* \\? \\" \\: \\< \\> \\|]\', pic_name) != None:
pic_name = re.sub(\'[\\\\\\ \\/ \\* \\? \\" \\: \\< \\> \\|]\', \'\', pic_name)
之后运行正常
6、总代码
#-*— codeing = utf-8 -*-
import requests
import re
headers = {
\'user-agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36\',
\'referer\': \'https://www.pixiv.net/ranking.php?mode=daily&content=illust\',
}
def download(id, count):
url = \'https://www.pixiv.net/artworks/%d\' % id
res = requests.get(url, headers=headers)
pic_url = re.findall(r\'"original":"(.+?)"\', res.text)[0]
pic_name = re.findall(r\'"illustTitle":"(.+?)"\', res.text)[0]
# 获取后缀
extension = re.findall(r\'....$\', pic_url)[0]
pic_url = re.sub(\'.....$\',\'\',pic_url)
if re.search(\'[\\\\\\ \\/ \\* \\? \\" \\: \\< \\> \\|]\', pic_name) != None:
pic_name = re.sub(\'[\\\\\\ \\/ \\* \\? \\" \\: \\< \\> \\|]\', \'\', pic_name)
# 下载图片
for i in range(0,int(count)):
url = pic_url+str(i)+extension
print(\'正在下载id为:%d的第%d张图片\'%(id,i+1),end=\' \')
pic = requests.get(url, headers=headers)
with open(\'./ex/%s%d%s\' % (pic_name, i+1, extension), \'wb\') as f:
f.write(pic.content)
print(\'下载成功\', end=\'\\n\')
def bot():
id = []
count = []
for i in range(1, 2):
url = \'https://www.pixiv.net/ranking.php?p=%d&format=json\' % i
res = requests.get(url, headers=headers)
id = id + re.findall(\'"illust_id":(\\d+)\', res.text)
count = count + re.findall(\'"illust_page_count":"(\\d+)"\', res.text)
if len(id) == len(count):
for i in range(0,len(id)):
download(int(id[i]),int(count[i]))
bot()
参考资料:
- b站爬虫教学视频https://www.bilibili.com/video/BV12E411A7ZQ
- CSDN相似爬虫https://blog.csdn.net/weixin_45826022/article/details/109406389
以上是关于基于python的pixiv爬虫的主要内容,如果未能解决你的问题,请参考以下文章