学习《从零开始学Python网络爬虫》PDF+源代码+《精通Scrapy网络爬虫》PDF
Posted unzp325
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习《从零开始学Python网络爬虫》PDF+源代码+《精通Scrapy网络爬虫》PDF相关的知识,希望对你有一定的参考价值。
学习网络爬虫,基于python3处理数据,推荐学习《从零开始学Python网络爬虫》和《精通Scrapy网络爬虫》。
《从零开始学Python网络爬虫》是基于Python 3的图书,代码挺多,如果是想快速实现功能,这本书是一个蛮好的选择。
《精通Scrapy网络爬虫》基于Python3,深入系统地介绍了Python流行框架Scrapy的相关技术及使用技巧。
学习参考:
《从零开始学Python网络爬虫》PDF,279页,带目录,文字可复制;
配套源代码,教学PPT。作者: 罗攀 / 蒋仟
《精通Scrapy网络爬虫》PDF,254页,带目录,文字可复制。作者: 刘硕
下载:https://pan.baidu.com/s/1NWd6w8pCHORBx4BFsw7cnQ
《从零开始学Python网络爬虫》是一本教初学者学习如何爬取网络数据和信息的入门读物。书中不仅有Python的相关内容,
而且还有数据处理和数据挖掘等方面的内容。内容非常实用,讲解时穿插了22个爬虫实战案例,可以大大提高读者的实际动
手能力。共分12章,核心主题包括Python零基础语法入门、爬虫原理和网页构造、第壹个爬虫程序、正则表达式、Lxml库与
Xpath语法、使用API、数据库存储、多进程爬虫、异步加载、表单交互与模拟登录、Selenium模拟浏览器、Scrapy爬虫框架。

此外,书中通过一些典型爬虫案例,讲解了有经纬信息的地图图表和词云的制作方法,让读者体验数据背后的乐趣。
全书共14章,从逻 辑上可分为基础篇和高级篇两部分,基础篇重点介绍Scrapy的核心元素,如spider、selector、item、link等;高级篇讲解爬虫 的高级话题,如登录认证、文件下载、执行JavaScript、动态网页爬取、使用HTTP代理、分布式爬虫的编写等,并配合项目案 例讲解,包括供练习使用的网站,以及知乎、豆瓣、360爬虫案例等。 案例丰富,注重实践,代码注释详尽,适合有一 定Python语言基础,想学习编写复杂网络爬虫的读者使用。
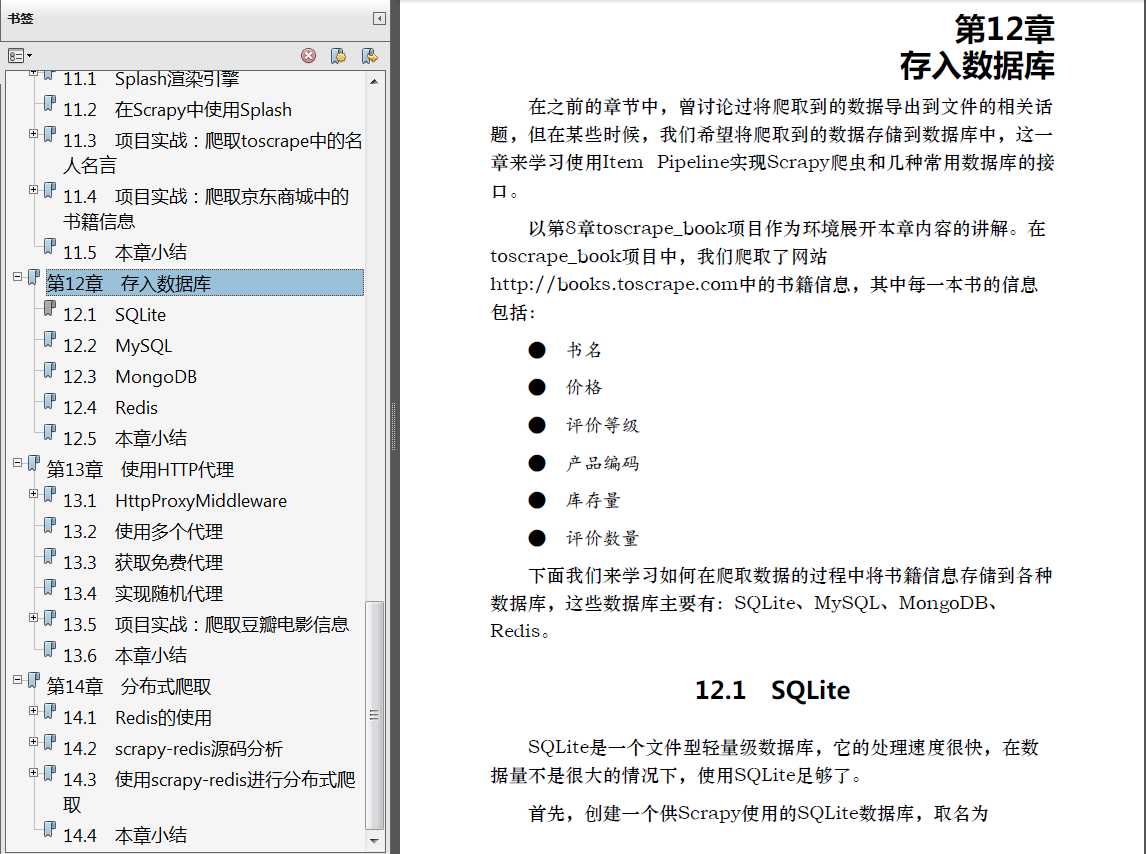
配合这本书学习,效果会更好。
《Python网络数据采集》高清中文PDF英文PDF源代码:https://pan.baidu.com/s/1DLOCZm8MnGALfXF7g_KtQw
以上是关于学习《从零开始学Python网络爬虫》PDF+源代码+《精通Scrapy网络爬虫》PDF的主要内容,如果未能解决你的问题,请参考以下文章
Python 3.5从零开始学 (刘宇宙 著) 完整pdf扫描版[41MB]