背景
Read the fucking source code!--By 鲁迅A picture is worth a thousand words.--By 高尔基
说明:
- Kernel版本:4.14
- ARM64处理器,Contex-A53,双核
- 使用工具:Source Insight 3.5, Visio
1. 概述
本文将分析Buddy System。
Buddy System伙伴系统,是通过将物理内存划分为页面来进行管理的系统,支持连续的物理页面分配和释放。此外,使用与碎片相关的算法来确保最大的连续页面。
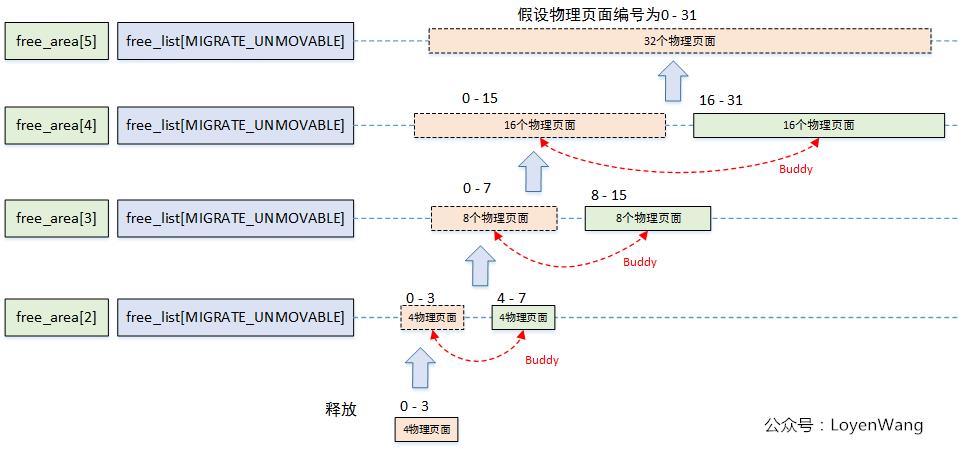
先通过一个例子大体介绍一下原理吧:
空闲的物理页框按大小分组成0~MAX_ORDER个链表,每个链表存放页框的大小为2的n次幂,其中n在0 ~ MAX_ORDER-1中取值。
假设请求分配2^8 = 256个页框块:
- 检查
n = 8的链表,检查是否有空闲块,找到了则直接返回; - 没有找到满足需求的,则查找
n = 9的链表,找到512大小空闲块,拆分成两个256大小块,将其中一个256大小块返回,另一个256大小块添加到n = 8的链表中; - 在
n = 9的链表中没有找到合适的块,则查找n = 10的链表,找到1024大小空闲块,将其拆分成512 + 256 + 256大小的块,返回需要获取的256大小的块,将剩下的512大小块插入n = 9链表中,剩下的256大小块插入n = 8的链表中;
合并过程是上述流程的逆过程,试图将大小相等的Buddy块进行合并成单独的块,并且会迭代合并下去,尝试合并成更大的块。合并需要满足要求:
- 两个
Buddy块大小一致; - 它们的物理地址连续;
- 第一个
Buddy块的起始地址为(2 x N x 4K)的整数倍,其中4K为页面大小,N为Buddy块的大小;

struct page结构中,与Buddy System相关的字段有:
_mapcount: 用于标记page是否处在Buddy System中,设置成-1或PAGE_BUDDY_MAPCOUNT_VALUE(-128);private: 一个2^k次幂的空闲块的第一个页描述符中,private字段存放了块的order值,也就是k值;index: 存放MIGRATE类型;_refcount: 用户使用计数值,没有用户使用为0,有使用的话则增加;
合并时如下图所示:

2. Buddy页面分配
Buddy页面分配的流程如下图所示:
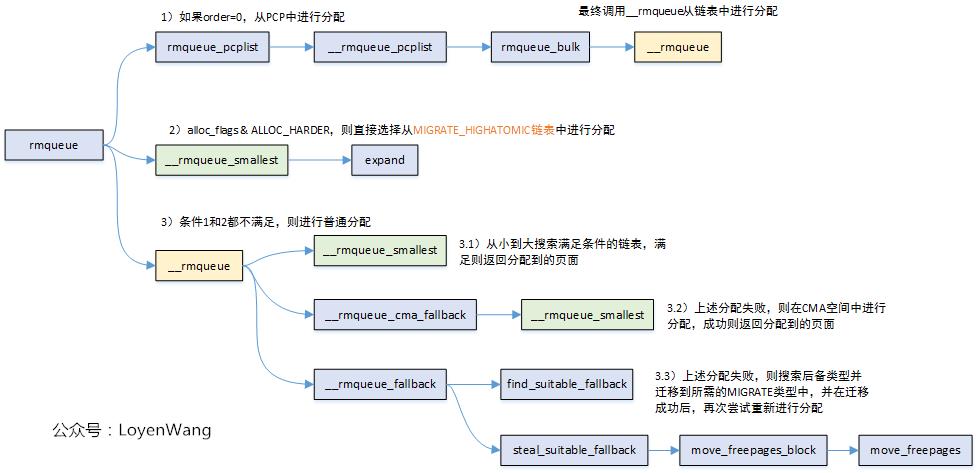
从上图中可以看出,在页面进行分配的时候,有以下四个步骤:
- 如果申请的是
order = 0的页面,直接选择从pcp中进行分配,并直接退出; order > 0时,如果分配标志中设置了ALLOC_HARDER,则从free_list[MIGRATE_HIGHATOMIC]的链表中进行页面分配,分配成功则返回;- 前两个条件都不满足,则在正常的
free_list[MIGRATE_*]中进行分配,分配成功则直接则返回; - 如果3中分配失败了,则查找
后备类型fallbacks[MIGRATE_TYPES][4],并将查找到的页面移动到所需的MIGRATE类型中,移动成功后,重新尝试分配;
如下图:

上述分配的过程,前3个步骤都会调用到__rmqueue_smallest,第4步调用__rmqueue_fallback,将从这两个函数来分析。
2.1 __rmqueue_smallest
__rmqueue_smallest的源代码比较简单,贴上来看看吧:
static inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
page = list_first_entry_or_null(&area->free_list[migratetype],
struct page, lru);
if (!page)
continue;
list_del(&page->lru);
rmv_page_order(page);
area->nr_free--;
expand(zone, page, order, current_order, area, migratetype);
set_pcppage_migratetype(page, migratetype);
return page;
}
return NULL;
}
从代码中可以看出:
- 从申请的
order大小开始查找目标MIGRATE类型链表中页表,如果没有找到,则从更大的order中查找,直到MAX_ORDER; - 查找到页表之后,从对应的链表中删除掉,并调用
expand函数进行处理;
expand函数的处理逻辑就跟本文概述中讲的例子一样,当在大的order链表中申请到了内存后,剩余部分会插入到其他的order链表中,来一张图就清晰了:

2.2 __rmqueue_fallback
当上述过程没有分配到内存时,便会开始从后备迁移类型中进行分配。
其中,定义了一个全局的二维fallbacks的数组,并根据该数组进行查找,代码如下:
/*
* This array describes the order lists are fallen back to when
* the free lists for the desirable migrate type are depleted
*/
static int fallbacks[MIGRATE_TYPES][4] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
#ifdef CONFIG_CMA
[MIGRATE_CMA] = { MIGRATE_TYPES }, /* Never used */
#endif
#ifdef CONFIG_MEMORY_ISOLATION
[MIGRATE_ISOLATE] = { MIGRATE_TYPES }, /* Never used */
#endif
};

__rmqueue_fallback完成的主要工作就是从后备fallbacks中找到一个迁移类型页面块,将其移动到目标类型中,并重新进行分配。
下图将示例整个流程:

3. Buddy页面释放
页面释放是申请的逆过程,相对来说要简单不少,先看一下函数调用图吧:

当order = 0时,会使用Per-CPU Page Frame来释放,其中:
MIGRATE_UNMOVABLE, MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE三个按原来的类型释放;MIGRATE_CMA, MIGRATE_HIGHATOMIC类型释放到MIGRATE_UNMOVABLE类型中;MIGRATE_ISOLATE类型释放到Buddy系统中;
此外,在PCP释放的过程中,发生溢出时,会调用free_pcppages_bulk()来返回给Buddy系统。来一张图就清晰了:
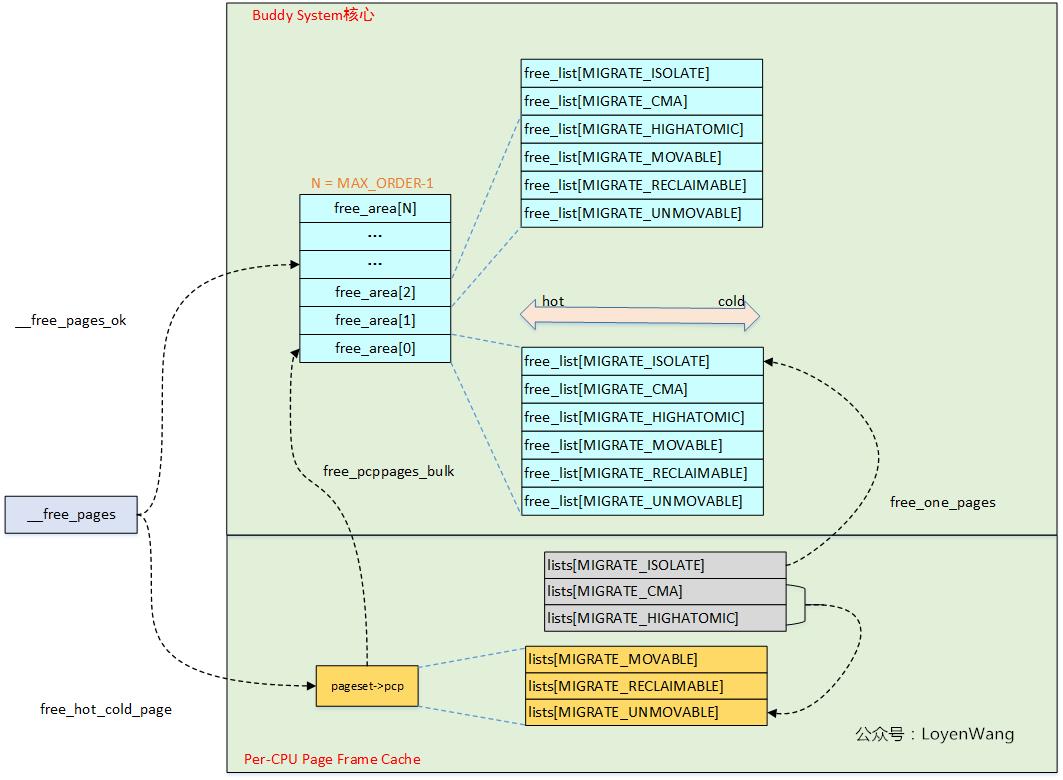
在整个释放过程中,核心函数为__free_one_page,该函数的核心逻辑部分如下所示:
continue_merging:
while (order < max_order - 1) {
buddy_pfn = __find_buddy_pfn(pfn, order);
buddy = page + (buddy_pfn - pfn);
if (!pfn_valid_within(buddy_pfn))
goto done_merging;
if (!page_is_buddy(page, buddy, order))
goto done_merging;
/*
* Our buddy is free or it is CONFIG_DEBUG_PAGEALLOC guard page,
* merge with it and move up one order.
*/
if (page_is_guard(buddy)) {
clear_page_guard(zone, buddy, order, migratetype);
} else {
list_del(&buddy->lru);
zone->free_area[order].nr_free--;
rmv_page_order(buddy);
}
combined_pfn = buddy_pfn & pfn;
page = page + (combined_pfn - pfn);
pfn = combined_pfn;
order++;
}
__find_buddy_pfn: 根据释放页面的pfn计算对应的buddy_pfn,比如pfn = 0x1000, order = 3,则buddy_pfn = 0x1008,pfn = 0x1008, order = 3,则buddy_pfn = 0x1000;page_is_buddy:将page和buddy进行配对处理,判断是否能配对;- 进行combine之后,再将pfn指向合并后的开始位置,继续往上一阶进行合并处理;
按照惯例,再来张图片吧:
不得不说,还有很多细节没有去扣,一旦沉沦,将难以自拔,待续吧。
