Python数据分析pandas入门练习题
Posted Geek_bao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数据分析pandas入门练习题相关的知识,希望对你有一定的参考价值。
Python数据分析基础
- Preparation
- Exercise 1-Student Alcohol Consumption
- Introduction:
- Step 1. Import the necessary libraries
- Step 2. Import the dataset from this [address](https://raw.githubusercontent.com/guipsamora/pandas_exercises/master/04_Apply/Students_Alcohol_Consumption/student-mat.csv).
- Step 3. Assign it to a variable called df.
- Step 4. For the purpose of this exercise slice the dataframe from 'school' until the 'guardian' column
- Step 5. Create a lambda function that capitalize strings.
- Step 6. Capitalize both Mjob and Fjob
- Step 7. Print the last elements of the data set.
- Step 8. Did you notice the original dataframe is still lowercase? Why is that? Fix it and capitalize Mjob and Fjob.
- Step 9. Create a function called majority that return a boolean value to a new column called legal_drinker (Consider majority as older than 17 years old)
- Step 10. Multiply every number of the dataset by 10.
- Exercise 2-United States - Crime Rates - 1960 - 2014
- Introduction:
- Step 1. Import the necessary libraries
- Step 2. Import the dataset from this [address](https://raw.githubusercontent.com/guipsamora/pandas_exercises/master/04_Apply/US_Crime_Rates/US_Crime_Rates_1960_2014.csv).
- Step 3. Assign it to a variable called crime.
- Step 4. What is the type of the columns?
- Step 5. Convert the type of the column Year to datetime64
- Step 6. Set the Year column as the index of the dataframe
- Step 7. Delete the Total column
- Step 8. Group the year by decades and sum the values
- Step 9. What is the most dangerous decade to live in the US?
- Conclusion
Preparation
下面是练习题的数据集,尽量下载下来使用。下面习题的连接不一定能打开。
需要数据集可以私聊博主或者自行网上寻找,传到csdn,你们下载要会员,就不传了。
Exercise 1-Student Alcohol Consumption
Introduction:
This time you will download a dataset from the UCI.
Step 1. Import the necessary libraries
import pandas as pd
Step 2. Import the dataset from this address.
Step 3. Assign it to a variable called df.
代码如下:
df = pd.read_csv("student-mat.csv", sep=',')
df.head()
输出结果如下:
| school | sex | age | address | famsize | Pstatus | Medu | Fedu | Mjob | Fjob | ... | famrel | freetime | goout | Dalc | Walc | health | absences | G1 | G2 | G3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | GP | F | 18 | U | GT3 | A | 4 | 4 | at_home | teacher | ... | 4 | 3 | 4 | 1 | 1 | 3 | 6 | 5 | 6 | 6 |
| 1 | GP | F | 17 | U | GT3 | T | 1 | 1 | at_home | other | ... | 5 | 3 | 3 | 1 | 1 | 3 | 4 | 5 | 5 | 6 |
| 2 | GP | F | 15 | U | LE3 | T | 1 | 1 | at_home | other | ... | 4 | 3 | 2 | 2 | 3 | 3 | 10 | 7 | 8 | 10 |
| 3 | GP | F | 15 | U | GT3 | T | 4 | 2 | health | services | ... | 3 | 2 | 2 | 1 | 1 | 5 | 2 | 15 | 14 | 15 |
| 4 | GP | F | 16 | U | GT3 | T | 3 | 3 | other | other | ... | 4 | 3 | 2 | 1 | 2 | 5 | 4 | 6 | 10 | 10 |
5 rows × 33 columns
Step 4. For the purpose of this exercise slice the dataframe from ‘school’ until the ‘guardian’ column
代码如下:
stud_alcoh = df.loc[:, 'school':'guardian'] # loc切片一般用行列名,iloc一般用行列号
stud_alcoh.head()
输出结果如下:
| school | sex | age | address | famsize | Pstatus | Medu | Fedu | Mjob | Fjob | reason | guardian | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | GP | F | 18 | U | GT3 | A | 4 | 4 | at_home | teacher | course | mother |
| 1 | GP | F | 17 | U | GT3 | T | 1 | 1 | at_home | other | course | father |
| 2 | GP | F | 15 | U | LE3 | T | 1 | 1 | at_home | other | other | mother |
| 3 | GP | F | 15 | U | GT3 | T | 4 | 2 | health | services | home | mother |
| 4 | GP | F | 16 | U | GT3 | T | 3 | 3 | other | other | home | father |
Step 5. Create a lambda function that capitalize strings.
代码如下:
capitalizer = lambda str: str.capitalize() #capitalize()将字符串首字母转换为大写字母,upper()将整个字符串转化为大写
print(capitalizer('www'))
输出结果如下:
Www
Step 6. Capitalize both Mjob and Fjob
代码如下:
# for i in df['Mjob']:
# print(capitalizer(i))
stud_alcoh.Mjob.apply(capitalizer)
stud_alcoh.Fjob.apply(capitalizer)
输出结果如下:
0 Teacher
1 Other
2 Other
3 Services
4 Other
5 Other
6 Other
7 Teacher
8 Other
9 Other
10 Health
11 Other
12 Services
13 Other
14 Other
15 Other
16 Services
17 Other
18 Services
19 Other
20 Other
21 Health
22 Other
23 Other
24 Health
25 Services
26 Other
27 Services
28 Other
29 Teacher
...
365 Other
366 Services
367 Services
368 Services
369 Teacher
370 Services
371 Services
372 At_home
373 Other
374 Other
375 Other
376 Other
377 Services
378 Other
379 Other
380 Teacher
381 Other
382 Services
383 Services
384 Other
385 Other
386 At_home
387 Other
388 Services
389 Other
390 Services
391 Services
392 Other
393 Other
394 At_home
Name: Fjob, Length: 395, dtype: object
Step 7. Print the last elements of the data set.
代码如下:
# df.iloc[394, 32]
stud_alcoh.tail()
输出结果如下:
| school | sex | age | address | famsize | Pstatus | Medu | Fedu | Mjob | Fjob | reason | guardian | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 390 | MS | M | 20 | U | LE3 | A | 2 | 2 | services | services | course | other |
| 391 | MS | M | 17 | U | LE3 | T | 3 | 1 | services | services | course | mother |
| 392 | MS | M | 21 | R | GT3 | T | 1 | 1 | other | other | course | other |
| 393 | MS | M | 18 | R | LE3 | T | 3 | 2 | services | other | course | mother |
| 394 | MS | M | 19 | U | LE3 | T | 1 | 1 | other | at_home | course | father |
Step 8. Did you notice the original dataframe is still lowercase? Why is that? Fix it and capitalize Mjob and Fjob.
代码如下:
stud_alcoh.Mjob = stud_alcoh.Mjob.apply(capitalizer)
stud_alcoh.Fjob = stud_alcoh.Fjob.apply(capitalizer)
stud_alcoh
输出结果如下:
| school | sex | age | address | famsize | Pstatus | Medu | Fedu | Mjob | Fjob | reason | guardian | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | GP | F | 18 | U | GT3 | A | 4 | 4 | At_home | Teacher | course | mother |
| 1 | GP | F | 17 | U | GT3 | T | 1 | 1 | At_home | Other | course | father |
| 2 | GP | F | 15 | U | LE3 | T | 1 | 1 | At_home | Other | other | mother |
| 3 | GP | F | 15 | U | GT3 | T | 4 | 2 | Health | Services | home | mother |
| 4 | GP | F | 16 | U | GT3 | T | 3 | 3 | Other | Other | home | father |
| 5 | GP | M | 16 | U | LE3 | T | 4 | 3 | Services | Other | reputation | mother |
| 6 | GP | M | 16 | U | LE3 | T | 2 | 2 | Other | Other | home | mother |
| 7 | GP | F | 17 | U | GT3 | A | 4 | 4 | Other | Teacher | home | mother |
| 8 | GP | M | 15 | U | LE3 | A | 3 | 2 | Services | Other | home | mother |
| 9 | GP | M | 15 | U | GT3 | T | 3 | 4 | Other | Other | home | mother |
| 10 | GP | F | 15 | U | GT3 | T | 4 | 4 | Teacher | Health | reputation | mother |
| 11 | GP | F | 15 | U | GT3 | T | 2 | 1 | Services | Other | reputation | father |
| 12 | GP | M | 15 | U | LE3 | T | 4 | 4 | Health | Services | course | father |
| 13 | GP | M | 15 | U | GT3 | T | 4 | 3 | Teacher | Other | course | mother |
| 14 | GP | M | 15 | U | GT3 | A | 2 | 2 | Other | Other | home | other |
| 15 | GP | F | 16 | U | GT3 | T | 4 | 4 | Health | Other | home | mother |
| 16 | GP | F | 16 | U | GT3 | T | 4 | 4 | Services | Services | reputation | mother |
| 17 | GP | F | 16 | U | GT3 | T | 3 | 3 | Other | Other | reputation | mother |
| 18 | GP | M | 17 | U | GT3 | T | 3 | 2 | Services | Services | course | mother |
| 19 | GP | M | 16 | U | LE3 | T | 4 | 3 | Health | Other | home | father |
| 20 | GP | M | 15 | U | GT3 | T | 4 | 3 | Teacher | Other | reputation | mother |
| 21 | GP | M | 15 | U | GT3 | T | 4 | 4 | Health | Health | other | father |
| 22 | GP | M | 16 | U | LE3 | T | 4 | 2 | Teacher | Other | course | mother |
| 23 | GP | M | 16 | U | LE3 | T | 2 | 2 | Other | Other | reputation | mother |
| 24 | GP | F | 15 | R | GT3 | T | 2 | 4 | Services | Health | course | mother |
| 25 | GP | F | 16 | U | GT3 | T | 2 | 2 | Services | Services | home | mother |
| 26 | GP | M | 15 | U | GT3 | T | 2 | 2 | Other | Other | home | mother |
| 27 | GP | M | 15 | U | GT3 | T | 4 | 2 | Health | Services | other | mother |
| 28 | GP | M | 16 | U | LE3 | A | 3 | 4 | Services | Other | home | mother |
| 29 | GP | M | 16 | U | GT3 | T | 4 | 4 | Teacher | Teacher | home | mother |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 365 | MS | M | 18 | R | GT3 | T | 1 | 3 | At_home | Other | course | mother |
| 366 | MS | M | 18 | U | LE3 | T | 4 | 4 | Teacher | Services | other | mother |
| 367 | MS | F | 17 | R | GT3 | T | 1 | 1 | Other | Services | reputation | mother |
| 368 | MS | F | 18 | U | GT3 | T | 2 | 3 | At_home | Services | course | father |
| 369 | MS | F | 18 | R | GT3 | T | 4 | 4 | Other | Teacher | other | father |
| 370 | MS | F | 19 | U | LE3 | T | 3 | 2 | Services | Services | home | other |
| 371 | MS | M | 18 | R | LE3 | T | 1 | 2 | At_home | Services | other | father |
| 372 | MS | F | 17 | U | GT3 | T | 2 | 2 | Other | At_home | home | mother |
| 373 | MS | F | 17 | R | GT3 | T | 1 | 2 | Other | Other | course | mother |
| 374 | MS | F | 18 | R | LE3 | T | 4 | 4 | Other | Other | reputation | mother |
| 375 | MS | F | 18 | R | GT3 | T | 1 | 1 | Other | Other | home | mother |
| 376 | MS | F | 20 | U | GT3 | T | 4 | 2 | Health | Other | course | other |
| 377 | MS | F | 18 | R | LE3 | T | 4 | 4 | Teacher | Services | course | mother |
| 378 | MS | F | 18 | U | GT3 | T | 3 | 3 | Other | Other | home | mother |
| 379 | MS | F | 17 | R | GT3 | T | 3 | 1 | At_home | Other | reputation | mother |
| 380 | MS | M | 18 | U | GT3 | T | 4 | 4 | Teacher | Teacher | home | father |
| 381 | MS | M | 18 | R | GT3 | T | 2 | 1 | Other | Other | other | mother |
| 382 | MS | M | 17 | U | GT3 | T | 2 | 3 | Other | Services | home | father |
| 383 | MS | M | 19 | R | GT3 | T | 1 | 1 | Other | Services | other | mother |
| 384 | MS | M | 18 | R | GT3 | T | 4 | 2 | Other | Other | home | father |
| 385 | MS | F | 18 | R | GT3 | T | 2 | 2 | At_home | Other | other | mother |
| 386 | MS | F | 18 | R | GT3 | T | 4 | 4 | Teacher | At_home | reputation | mother |
| 387 | MS | F | 19 | R | GT3 | T | 2 | 3 | Services | Other | course | mother |
| 388 | MS | F | 18 | U | LE3 | T | 3 | 1 | Teacher | Services | course | mother |
| 389 | MS | F | 18 | U | GT3 | T | 1 | 1 | Other | Other | course | mother |
| 390 | MS | M | 20 | U | LE3 | A | 2 | 2 | Services | Services | course | other |
| 391 | MS | M | 17 | U | LE3 | T | 3 | 1 | Services | Services | course | mother |
| 392 | MS | M | 21 | R | GT3 | T | 1 | 1 | Other | Other | course | other |
| 393 | MS | M | 18 | R | LE3 | T | 3 | 2 | Services | Other | course | mother |
| 394 | MS | M | 19 | U | LE3 | T | 1 | 1 | Other | At_home | course | father |
395 rows × 12 columns
Step 9. Create a function called majority that return a boolean value to a new column called legal_drinker (Consider majority as older than 17 years old)
代码如下:
def majority(age):
if age > 17:
return True
else:
return False
stud_alcoh['legal_drinker'] = stud_alcoh.age.apply(majority)
stud_alcoh
输出结果如下:
| school | sex | age | address | famsize | Pstatus | Medu | Fedu | Mjob | Fjob | reason | guardian | legal_drinker | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | GP | F | 18 | U | GT3 | A | 4 | 4 | At_home | Teacher | course | mother | True |
| 1 | GP | F | 17 | U | GT3 | T | 1 | 1 | At_home | Other | course | father | False |
| 2 | GP | F | 15 | U | LE3 | T | 1 | 1 | At_home | Other | other | mother | False |
| 3 | GP | F | 15 | U | GT3 | T | 4 | 2 | Health | Services | home | mother | False |
| 4 | GP | F | 16 | U | GT3 | T | 3 | 3 | Other | Other | home | father | False |
| 5 | GP | M | 16 | U | LE3 | T | 4 | 3 | Services | Other | reputation | mother | False |
| 6 | GP | M | 16 | U | LE3 | T | 2 | 2 | Other | Other | home | mother | False |
| 7 | GP | F | 17 | U | GT3 | A | 4 | 4 | Other | Teacher | home | mother | False |
| 8 | GP | M | 15 | U | LE3 | A | 3 | 2 | Services | Other | home | mother | False |
| 9 | GP | M | 15 | U | GT3 | T | 3 | 4 | Other | Other | home | mother | False |
| 10 | GP | F | 15 | U | GT3 | T | 4 | 4 | Teacher | Health | reputation | mother | False |
| 11 | GP | F | 15 | U | GT3 | T | 2 | 1 | Services | Other | reputation | father | False |
| 12 | GP | M | 15 | U | LE3 | T | 4 | 4 | Health | Services | course | father | False |
| 13 | GP | M | 15 | U | GT3 | T | 4 | 3 | Teacher | Other | course | mother | False |
| 14 | GP | M | 15 | U | GT3 | A | 2 | 2 | Other | Other | home | other | False |
| 15 | GP | F | 16 | U | GT3 | T | 4 | 4 | Health | Other | home | mother | False |
| 16 | GP | F | 16 | U | GT3 | T | 4 | 4 | Services | Services | reputation | mother | False |
| 17 | GP | F | 16 | U | GT3 | T | 3 | 3 | Other | Other | reputation | mother | False |
| 18 | GP | M | 17 | U | GT3 | T | 3 | 2 | Services | Services | course | mother | False |
| 19 | GP | M | 16 | U | LE3 | T | 4 | 3 | Health | Other | home | father | False |
| 20 | GP | M | 15 | U | GT3 | T | 4 | 3 | Teacher | Other | reputation | mother | False |
| 21 | GP | M | 15 | U | GT3 | T | 4 | 4 | Health | Health | other | father | False |
| 22 | GP | M | 16 | U | LE3 | T | 4 | 2 | Teacher | Other | course | mother | False |
| 23 | GP | M | 16 | U | LE3 | T | 2 | 2 | Other | Other | reputation | mother | False |
| 24 | GP | F | 15 | R | GT3 | T | 2 | 4 | Services | Health | course | mother | False |
| 25 | GP | F | 16 | U | GT3 | T | 2 | 2 | Services | Services | home | mother | False |
| 26 | GP | M | 15 | U | GT3 | T | 2 | 2 | Other | Other | home | mother | False |
| 27 | GP | M | 15 | U | GT3 | T | 4 | 2 | Health | Services | other | mother | False |
| 28 | GP | M | 16 | U | LE3 | A | 3 | 4 | Services | Other | home | mother | False |
| 29 | GP | M | 16 | U | GT3 | T | 4 | 4 | Teacher | Teacher | home | mother | False |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 365 | MS | M | 18 | R | GT3 | T | 1 | 3 | At_home | Other | course | mother | True |
| 366 | MS | M | 18 | U | LE3 | T | 4 | 4 | Teacher | Services | other | mother | True |
| 367 | MS | F | 17 | R | GT3 | T | 1 | 1 | Other | Services | reputation | mother | False |
| 368 | MS | F | 18 | U | GT3 | T | 2 | 3 | At_home | Services | course | father | True |
| 369 | MS | F | 18 | R | GT3 | T | 4 | 4 | Other | Teacher | other | father | True |
| 370 | MS | F | 19 | U | LE3 | T | 3 | 2 | Services | Services | home | other | True |
| 371 | MS | M | 18 | R | LE3 | T | 1 | 2 | At_home | Services | other | father | True |
| 372 | MS | F | 17 | U | GT3 | T | 2 | 2 | Other | At_home | home | mother | False |
| 373 | MS | F | 17 | R | GT3 | T | 1 | 2 | Other | Other | course | mother | False |
| 374 | MS | F | 18 | R | LE3 | T | 4 | 4 | Other | Other | reputation | mother | True |
| 375 | MS | F | 18 | R | GT3 | T | 1 | 1 | Other | Other | home | mother | True |
| 376 | MS | F | 20 | U | GT3 | T | 4 | 2 | Health | Other | course | other | True |
| 377 | MS | F | 18 | R | LE3 | T | 4 | 4 | Teacher | Services | course | mother | True |
| 378 | MS | F | 18 | U | GT3 | T | 3 | 3 | Other | Other | home | mother | True |
| 379 | MS | F | 17 | R | GT3 | T | 3 | 1 | At_home | Other | reputation | mother | False |
| 380 | MS | M | 18 | U | GT3 | T | 4 | 4 | Teacher | Teacher | home | father | True |
| 381 | MS | M | 18 | R | GT3 | T | 2 | 1 | Other | Other | other | mother | True |
| 382 | MS | M | 17 | U | GT3 | T | 2 | 3 | Other | Services | home | father | False |
| 383 | MS | M | 19 | R | GT3 | T | 1 | 1 | Other | Services | other | mother | True |
| 384 | MS | M | 18 | R | GT3 | T | 4 | 2 | Other | Other | home | father | True |
| 385 | MS | F | 18 | R | GT3 | T | 2 | 2 | At_home | Other | other | mother | True |
| 386 | MS | F | 18 | R | GT3 | T | 4 | 4 | Teacher | At_home | reputation | mother | True |
| 387 | MS | F | 19 | R | GT3 | T | 2 | 3 | Services | Other | course | mother | True |
| 388 | MS | F | 18 | U | LE3 | T | 3 | 1 | Teacher | Services | course | mother | True |
| 389 | MS | F | 18 | U | GT3 | T | 1 | 1 | Other | Other | course | mother | True |
| 390 | MS | M | 20 | U | LE3 | A | 2 | 2 | Services | Services | course | other | True |
| 391 | MS | M | 17 | U | LE3 | T | 3 | 1 | Services | Services | course | mother | False |
| 392 | MS | M | 21 | R | GT3 | T | 1 | 1 | Other | Other | course | other | True |
| 393 | MS | M | 18 | R | LE3 | T | 3 | 2 | Services | Other | course | mother | True |
| 394 | MS | M | 19 | U | LE3 | T | 1 | 1 | Other | At_home | course | father | True |
395 rows × 13 columns
Step 10. Multiply every number of the dataset by 10.
I know this makes no sense, don’t forget it is just an exercise
代码如下:
def times10(x):
if type(x) is int:
return 10 * x
return x
# apply()将一个函数作用于DataFrame中的每个行或者列
# 将函数做用于DataFrame中的所有元素(elements)
stud_alcoh.applymap(times10).head()
输出结果如下:
| school | sex | age | address | famsize | Pstatus | Medu | Fedu | Mjob | Fjob | reason | guardian | legal_drinker | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | GP | F | 180 | U | GT3 | A | 40 | 40 | At_home | Teacher | course | mother | True |
| 1 | GP | F | 170 | U | GT3 | T | 10 | 10 | At_home | Other | course | father | False |
| 2 | GP | F | 150 | U | LE3 | T | 10 | 10 | At_home | Other | other | mother | False |
| 3 | GP | F | 150 | U | GT3 | T | 40 | 20 | Health | Services | home | mother | False |
| 4 | GP | F | 160 | U | GT3 | T | 30 | 30 | Other | Other | home | father | False |
Exercise 2-United States - Crime Rates - 1960 - 2014
Introduction:
This time you will create a data
Special thanks to: https://github.com/justmarkham for sharing the dataset and materials.
Step 1. Import the necessary libraries
import pandas as pd
Step 2. Import the dataset from this address.
Step 3. Assign it to a variable called crime.
代码如下:
crime = pd.read_csv('US_Crime_Rates_1960_2014.csv')
crime.head()
输出结果如下:
| Year | Population | Total | Violent | Property | Murder | Forcible_Rape | Robbery | Aggravated_assault | Burglary | Larceny_Theft | Vehicle_Theft | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1960 | 179323175 | 3384200 | 288460 | 3095700 | 9110 | 17190 | 107840 | 154320 | 912100 | 1855400 | 328200 |
| 1 | 1961 | 182992000 | 3488000 | 289390 | 3198600 | 8740 | 17220 | 106670 | 156760 | 949600 | 1913000 | 336000 |
| 2 | 1962 | 185771000 | 3752200 | 301510 | 3450700 | 8530 | 17550 | 110860 | 164570 | 994300 | 2089600 | 366800 |
| 3 | 1963 | 188483000 | 4109500 | 316970 | 3792500 | 8640 | 17650 | 116470 | 174210 | 1086400 | 2297800 | 408300 |
| 4 | 1964 | 191141000 | 4564600 | 364220 | 4200400 | 9360 | 21420 | 130390 | 203050 | 1213200 | 2514400 | 472800 |
Step 4. What is the type of the columns?
代码如下:
# crime.columns
crime.info()
输出结果如下:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 55 entries, 0 to 54
Data columns (total 12 columns):
Year 55 non-null int64
Population 55 non-null int64
Total 55 non-null int64
Violent 55 non-null int64
Property 55 non-null int64
Murder 55 non-null int64
Forcible_Rape 55 non-null int64
Robbery 55 non-null int64
Aggravated_assault 55 non-null int64
Burglary 55 non-null int64
Larceny_Theft 55 non-null int64
Vehicle_Theft 55 non-null int64
dtypes: int64(12)
memory usage: 5.2 KB
Have you noticed that the type of Year is int64. But pandas has a different type to work with Time Series. Let’s see it now.
Step 5. Convert the type of the column Year to datetime64
代码如下:
crime.Year = pd.to_datetime(crime.Year, format='%Y') # 转化为日期格式%Y%m%d %H%M%S
crime.info() # 输出列名以及列数据类型等相关信息
输出结果如下:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 55 entries, 0 to 54
Data columns (total 12 columns):
Year 55 non-null datetime64[ns]
Population 55 non-null int64
Total 55 non-null int64
Violent 55 non-null int64
Property 55 non-null int64
Murder 55 non-null int64
Forcible_Rape 55 non-null int64
Robbery 55 non-null int64
Aggravated_assault 55 non-null int64
Burglary 55 non-null int64
Larceny_Theft 55 non-null int64
Vehicle_Theft 55 non-null int64
dtypes: datetime64[ns](1), int64(11)
memory usage: 5.2 KB
Step 6. Set the Year column as the index of the dataframe
代码如下:
crime = crime.set_index('Year', drop = True)# drop参数默认为False,想要删除原先的索引列要置为True
crime.head()
输出结果如下:
| Population | Total | Violent | Property | Murder | Forcible_Rape | Robbery | Aggravated_assault | Burglary | Larceny_Theft | Vehicle_Theft | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Year | |||||||||||
| 1960-01-01 | 179323175 | 3384200 | 288460 | 3095700 | 9110 | 17190 | 107840 | 154320 | 912100 | 1855400 | 328200 |
| 1961-01-01 | 182992000 | 3488000 | 289390 | 3198600 | 8740 | 17220 | 106670 | 156760 | 949600 | 1913000 | 336000 |
| 1962-01-01 | 185771000 | 3752200 | 301510 | 3450700 | 8530 | 17550 | 110860 | 164570 | 994300 | 2089600 | 366800 |
| 1963-01-01 | 188483000 | 4109500 | 316970 | 3792500 | 8640 | 17650 | 116470 | 174210 | 1086400 | 2297800 | 408300 |
| 1964-01-01 | 191141000 | 4564600 | 364220 | 4200400 | 9360 | 21420 | 130390 | 203050 | 1213200 | 2514400 | 472800 |
Step 7. Delete the Total column
代码如下:
del crime['Total'] # del直接删除
crime.head()
输出结果如下:
| Population | Violent | Property | Murder | Forcible_Rape | Robbery | Aggravated_assault | Burglary | Larceny_Theft | Vehicle_Theft | |
|---|---|---|---|---|---|---|---|---|---|---|
| Year | ||||||||||
| 1960-01-01 | 179323175 | 288460 | 3095700 | 9110 | 17190 | 107840 | 154320 | 912100 | 1855400 | 328200 |
| 1961-01-01 | 182992000 | 289390 | 3198600 | 8740 | 17220 | 106670 | 156760 | 949600 | 1913000 | 336000 |
| 1962-01-01 | 185771000 | 301510 | 3450700 | 8530 | 17550 | 110860 | 164570 | 994300 | 2089600 | 366800 |
| 1963-01-01 | 188483000 | 316970 | 3792500 | 8640 | 17650 | 116470 | 174210 | 1086400 | 2297800 | 408300 |
| 1964-01-01 | 191141000 | 364220 | 4200400 | 9360 | 21420 | 130390 | 203050 | 1213200 | 2514400 | 472800 |
Step 8. Group the year by decades and sum the values
Pay attention to the Population column number, summing this column is a mistake
代码如下:
# Uses resample to sum each decade
# resample聚合函数,将数据以W星期,M月,Q季度,QS季度的开始第一天开始,A年,10A十年,10AS十年聚合日期第一天开始.的形式进行聚合
crimes = crime.resample('10AS').sum()
# Uses resample to get the max value only for the "Population" column
population = crime['Population'].resample('10AS').max()
# Updating the "Population" column
crimes['Population'] = population
crimes
resample函数参数含义如下:
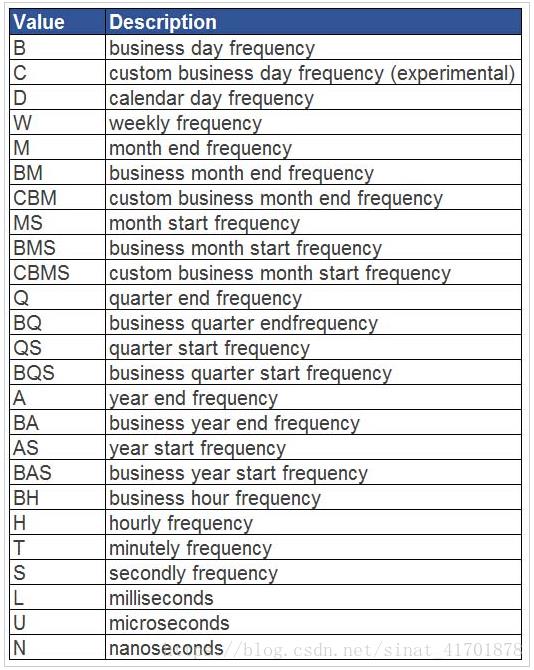
输出结果如下:
| Population | Violent | Property | Murder | Forcible_Rape | Robbery | Aggravated_assault | Burglary | Larceny_Theft | Vehicle_Theft | |
|---|---|---|---|---|---|---|---|---|---|---|
| Year | ||||||||||
| 1960-01-01 | 201385000.0 | 4134930 | 45160900 | 106180 | 236720 | 1633510 | 2158520 | 13321100 | 26547700 | 5292100 |
| 1970-01-01 | 220099000.0 | 9607930 | 91383800 | 192230 | 554570 | 4159020 | 4702120 | 28486000 | 53157800 | 9739900 |
| 1980-01-01 | 248239000.0 | 14074328 | 117048900 | 206439 | 865639 | 5383109 | 7619130 | 33073494 | 72040253 | 11935411 |
| 1990-01-01 | 272690813.0 | 17527048 | 119053499 | 211664 | 998827 | 5748930 | 10568963 | 26750015 | 77679366 | 14624418 |
| 2000-01-01 | 307006550.0 | 13968056 | 100944369 | 163068 | 922499 | 4230366 | 8652124 | 21565176 | 67970291 | 11412834 |
| 2010-01-01 | 318857056.0 | 6072017 | 44095950 | 72867 | 421059 | 1749809 | 3764142 | 10125170 | 30401698 | 3569080 |
| 2020-01-01 | NaN | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Step 9. What is the most dangerous decade to live in the US?
代码如下:
crime.idxmax(0) # 计算能够获得最大值的索引位置
# 从结果可以看出90s最危险,其实2020-2021更危险(滑稽+狗头保命)
输出结果如下:
Population 2014-01-01
Violent 1992-01-01
Property 1991-01-01
Murder 1991-01-01
Forcible_Rape 1992-01-01
Robbery 1991-01-01
Aggravated_assault 1993-01-01
Burglary 1980-01-01
Larceny_Theft 1991-01-01
Vehicle_Theft 1991-01-01
dtype: datetime64[ns]
Conclusion
今天主要练习了Apply()函数以及其他相关函数的使用。一定要理解每个参数含义,才能灵活运用函数得到你要的数。今天就到这里了,明天继续学习,各位加油!
以上是关于Python数据分析pandas入门练习题的主要内容,如果未能解决你的问题,请参考以下文章