谈一谈凑单页的那些优雅设计
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了谈一谈凑单页的那些优雅设计相关的知识,希望对你有一定的参考价值。

本文将详细介绍作者如何在业务增长的情况下重构与优化系统设计。
写在前面
凑单页存在的历史也算是比较悠久了,我从去年接手到现在也经历不少的版本变更,最开始只是简单feeds流,为提升用户体验,更好的帮助用户去凑到满意的商品,我们在重构整个凑单页的同时,还新增了榜单、限时秒杀模块,在双十一期间,加购率和转化率得到明显提升。今年618还新增了凑单进度购物栏模块,支持了实时凑单进度展示以及结算下单的能力,提升用户凑单体验。并且在凑单页完成业务迭代的同时,也一路沉淀了些通用的能力支撑其他业务快速迭代,本文我将详细介绍我是如何在业务增长的情况下重构与优化系统设计的。
针对一些段时间内不会变化的,数量比较有限的数据,为了减少下游的压力,并提高自身系统的性能,我们常常会使用多级缓存来达到该目的。最常见的就是本地缓存 + redis缓存来承接,如果本地缓存不存在,则取redis缓存的数据,并本地缓存起来,如果redis也不存在,则再从数据源获取,基本代码(获取榜单数据)如下:
return LOCAL_CACHE.get(key, () ->
String cache = rdbCommonTairCluster.get(key);
if (StringUtils.isNotBlank(cache))
return JSON.parseObject(cache, new TypeReference<List<ItemShow>>());
List<ItemShow> itemShows = getRankingItemOriginal(context, rankingRequest);
rdbCommonTairCluster.set(key, JSON.toJSONString(itemShows), new SetParams().ex(CommonSwitch.rankingExpireSecond));
return itemShows;
);逐渐的就出现了问题,线上偶现某些用户一段时间看不到榜单模块。榜单模块示意图如下:

这种问题排查起来最是棘手,需要一定的项目经验,我第一次遇到这类问题也是费了老大劲。总结一下,如果某次缓存过期,下游服务刚好返回了空结果,就会导致本次请求被缓存了空结果。那该缓存的生命周期内,榜单模块都会消失,但由于某些机器本地缓存还有旧数据,就会导致部分用户能看到,部分用户看不到的场景。
下面来看看我是如何优化的。核心主要关注:区分下游返回的结果是真的空还是假的空,本身就为空的情况下,就该缓存空集合(非大促期间或者某些榜没有数据,数据本身就为空)
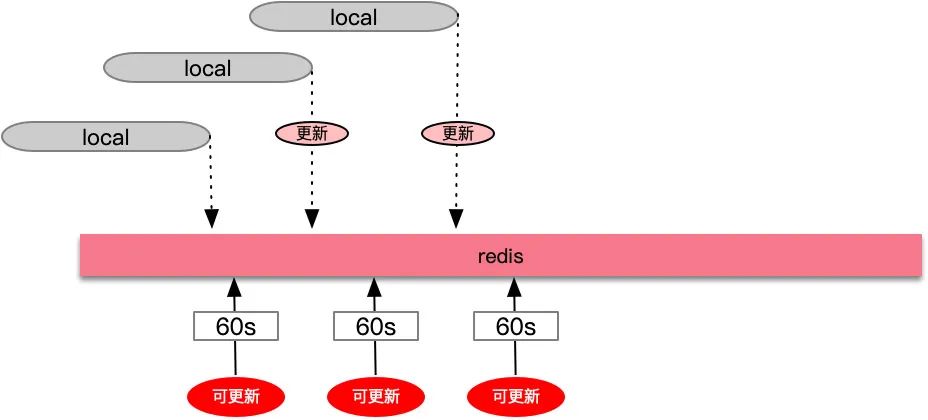
在redis中拉长value缓存的时间,同时新增一个可更新时间的缓存(比如60s过期),当判断更新时间缓存过期了,就重新读取数据源,将value值重新赋值,这里需要注意,我会对比新老数据,如果新数据为空,老数据不为空,则只是更新时间,不置换value。value随着自己的过期时间结束,改造后的代码如下:
return LOCAL_CACHE.get(key, () ->
String updateKey = getUpdateKey(key);
String value = rdbCommonTairCluster.get(key);
List<ItemShow> cache = StringUtils.isBlank(cache) ? Collections.emptyList()
: JSON.parseObject(value, new TypeReference<List<ItemShow>>());
if (rdbCommonTairCluster.exists(updateKey))
return cache;
rdbCommonTairCluster.set(updateKey, currentTime, cacheUpdateSecond);
List<ItemShow> itemShows = getRankingItemOriginal(context, rankingRequest);
if (CollectionUtils.isNotEmpty(itemShows))
rdbCommonTairCluster.set(key, JSON.toJSONString(itemShows), new SetParams().ex(CommonSwitch.rankingExpireSecond));
return itemShows;
);为了使这段代码能够复用,我将该多级缓存抽象出来一个独立对象,代码如下:
public class GatherCache<V>
@Setter
private Cache<String, List<V>> localCache;
@Setter
private CenterCache centerCache;
public List<V> get(boolean needCache, String key, @NonNull Callable<List<V>> loader, Function<String, List<V>> parse)
try
// 是否需要是否缓存
return needCache ? localCache.get(key, () -> getCenter(key, loader, parse)) : loader.call();
catch (Throwable e)
GatherContext.error(this.getClass().getSimpleName() + " get catch exception", e);
return Collections.emptyList();
private List<V> getCenter(String key, Callable<List<V>> loader, Function<String, List<V>> parse) throws Exception
String updateKey = getUpdateKey(key);
String value = centerCache.get(key);
boolean blankValue = StringUtils.isBlank(value);
List<V> cache = blankValue ? Collections.emptyList() : parse.apply(value);
if (centerCache.exists(updateKey))
return cache;
centerCache.set(updateKey, currentTime, cacheUpdateSecond);
List<V> newCache = loader.call();
if (CollectionUtils.isNotEmpty(newCache))
centerCache.set(key, JSON.toJSONString(newCache), cacheExpireSecond);
return newCache;
将从数据源获取数据的代码交与外部实现,使用Callable的形式,同时通过泛型约束数据源类型,这里还有一点瑕疵还没得到解决,就是通过fastJson转换String到对象时,没法使用泛型直接转,我这里就采用了外部化的处理,就是跟获取数据源方式一样,由外部来决定如何解析从redis中获取到的字符串value。调用方式如下:
List<ItemShow> itemShowList = gatherCache.get(true, rankingRequest.getKey(),
() -> getRankingItemOriginal(rankingRequest, context.getRequestContext()),
v -> JSON.parseObject(v, new TypeReference<List<ItemShow>>() ));同时我还采用的建造者模式,方便gatherCache类快速生成,代码如下:
@PostConstruct
public void init()
this.gatherCache = GatherCacheBuilder.newBuilder()
.localMaximumSize(500)
.localExpireAfterWriteSeconds(30)
.build(rdbCenterCache);
以上的代码相对比较完美了,却忽略了一个细节点,如果多台机器的本地缓存同时失效,恰好redis的可更新时间失效了,这时就会有多个请求并发打到下游(由于凑单有本地缓存兜底,并发打到下游的个数非常有限,基本可以忽略)。但遇到问题就需要去解决,追求完美代码。我做了如下的改造:
private List<V> getCenter(String key, Callable<List<V>> loader, Function<String, List<V>> parse) throws Exception
String updateKey = getUpdateKey(key);
String value = centerCache.get(key);
boolean blankValue = StringUtils.isBlank(value);
List<V> cache = blankValue ? Collections.emptyList() : parse.apply(value);
// 如果抢不到锁,并且value没有过期
if (!centerCache.setNx(updateKey, currentTime) && !blankValue)
return cache;
centerCache.set(updateKey, currentTime, cacheUpdateSecond);
// 使用异步线程去更新value
CompletableFuture.runAsync(() -> updateCache(key, loader));
return cache;
private void updateCache(String key, Callable<List<V>> loader)
List<V> newCache = loader.call();
if (CollectionUtils.isNotEmpty(newCache))
centerCache.set(key, JSON.toJSONString(newCache), cacheExpireSecond);
本方案使用分布式锁 + 异步线程的方式来处理更新。只会有一个请求抢到更新锁,并发情况下,其他请求在可更新时间段内还是返回老数据。由于redis封装的方法中并没有抢锁后同时设置过期时间的原子性操作,我这里用了先抢锁,再赋值过期时间的方式,在极端场景下可能会出现死锁的情况,就是刚好抢到了锁,然后机器出现异常宕机,导致过期时间没有赋值上去,就会出现永远无法更新的情况。这种情况虽然极端,但还是要解,以下是我能想到的两个方案,我选择了第二种方式:
通过使用lua脚本将两步操作合成一个原子性操作
利用value的过期时间来解该死锁问题

P.S. 一些从ThreadLocal中拿的通用信息,在使用异步线程处理的时候是拿不到的,得重新赋值
▐ 凑单核心处理流程设计
凑单本身是没有自己的数据源的,都是从其他服务读取,做各种加工后展示。这样的代码是最好写的,也是最难写的。就好比最简单的组装商品信息,一般的代码都会这么写:
// 获取推荐商品
List<Map<String, String>> summaryItemList = recommend();
List<ItemShow> itemShowList = summaryItemList.stream().map(v ->
ItemShow itemShow = new ItemShow();
// 设置商品基本信息
itemShow.setItemId(NumberUtils.createLong(v.get("itemId")));
itemShow.setItemImg(v.get("pic"));
// 获取利益点
GuideInfoDTO guideInfoDTO = new GuideInfoDTO();
AtmosphereResult<Map<Long, List<AtmosphereFullDTO>>> atmosphereResult = guideAtmosphereClient
.extract(guideInfoDTO, "gather", "item");
List<IconText> iconTexts = parseAtmosphere(atmosphereResult);
itemShow.setItemBenefits(iconTexts);
// 预售处理
String preSalePrice = getPreSale(v);
if (Objects.nonNull(preSalePrice))
itemShow.setItemPrice(preSalePrice);
// ......
return itemShow;
).collect(Collectors.toList());能快速写好代码并投入使用,但代码有点杂乱无章,对代码要求比较高的开发者可能会做如下的改进
// 获取推荐商品
List<Map<String, String>> summaryItemList = recommend();
List<ItemShow> itemShowList = summaryItemList.stream().map(v ->
ItemShow itemShow = new ItemShow();
// 设置商品基本信息
buildCommon(itemShow, v);
// 获取利益点
buildAtmosphere(itemShow, v);
// 预售处理
buildPreSale(itemShow, v);
// ......
return itemShow;
).collect(Collectors.toList());一般这样的代码算是比较优质的处理了,但这仅仅是针对单个业务,如果遇到多个业务需要使用该组装后,最简单但就是需要判断是来自feeds流模块的请求商品组装不需要利益点,来自前N秒杀模块的不需要处理预售价格。
// 获取推荐商品
List<Map<String, String>> summaryItemList = recommend();
List<ItemShow> itemShowList = summaryItemList.stream().map(v ->
ItemShow itemShow = new ItemShow();
// 设置商品基本信息
buildCommon(itemShow, v);
// 获取利益点
if (!Objects.equals(soluction, FiltrateFeedsSolution.class))
buildAtmosphere(itemShow, v);
// 预售处理
if (!Objects.equals(source, "seckill"))
buildPreSale(itemShow, v);
// ......
return itemShow;
).collect(Collectors.toList());该方案可以清晰看到整个主流程的分流结构,但会使得主流程不够整洁,降低可读性,很多人都习惯把该判断写到各自的方法里如下。(当然也有人每个模块都单独写一个主流程,以上只是为了文章易懂简化了代码,实际主流程较长,并且大部分都是需要处理的,如果每个模块都单独自己创建主流程,会带来很多重复代码,不推荐)
private void buildAtmosphere(ItemShow itemShow, Map<String, String> map)
if (Objects.equals(soluction, FiltrateFeedsSolution.class))
return;
GuideInfoDTO guideInfoDTO = new GuideInfoDTO();
AtmosphereResult<Map<Long, List<AtmosphereFullDTO>>> atmosphereResult = guideAtmosphereClient
.extract(guideInfoDTO, "gather", "item");
List<IconText> iconTexts = parseAtmosphere(atmosphereResult);
itemShow.setItemBenefits(iconTexts);
纵观整个凑单的业务逻辑,不管是参数组装,商品组装,购物车组装,榜单组装,都需要信息组装的能力,并且他们都有如下的特性:
每个或每几个字段的组装都不影响其他字段,就算出现异常也不应该影响其他字段的拼装
在消费者链路下,性能的要求会比较高,能不用访问的组装逻辑就不去访问,能不调用下游,就不去调用下游
如果在组装的过程中发现有写字段是必须要的,但没有补全,则提前终止流程
每个方法的处理需要记录耗时,开发能清楚的知道耗时在哪些地方,方便找到需要优化的代码
以上的点都很小,不做或者单独做都不影响整体,凑单页含有这么多组装逻辑的情况下,如果以上逻辑全部都写一遍,将产生大量的冗余代码。但对自己代码要求比较高的人来说,这些点不加上去,心里总感觉有根刺在。慢慢的就会因为自己之前设计考虑的不全,打各种补丁,就好比想知道某个方法的耗时,就会写如下代码:
long startTime = System.currentTimeMillis();
// 主要处理
buildAtmosphere(itemShow, summaryMap);
long endTime = System.currentTimeMillis();
return endTime - startTime;凑单各域都是做此类型的组装,有商品组装,参数组装,榜单组装,购物车组装。针对凑单业务的特性,寻遍各类设计模式,最终选择了责任链 + 命令模式。
在 GoF 的《设计模式》中,责任链模式是这么定义的:
将请求的发送和接收解耦,让多个接收对象都有机会处理这个请求。将这些接收对象串成一条链,并沿着这条链传递这个请求,直到链上的某个接收对象能够处理它为止。
首先,我们来看,职责链模式如何应对代码的复杂性。
将大块代码逻辑拆分成函数,将大类拆分成小类,是应对代码复杂性的常用方法。应用职责链模式,我们把各个商品组装继续拆分出来,设计成独立的类,进一步简化了商品组装类,让类的代码不会过多,过复杂。
其次,我们再来看,职责链模式如何让代码满足开闭原则,提高代码的扩展性。
当我们要扩展新的组装逻辑的时候,比如,我们还需要增加价格隐藏过滤,按照非职责链模式的代码实现方式,我们需要修改主类的代码,违反开闭原则。不过,这样的修改还算比较集中,也是可以接受的。而职责链模式的实现方式更加优雅,只需要新添加一个Command 类(实际处理类采用了命令模式做一些业务定制的扩展),并且通过 addCommand() 函数将它添加到 Chain 中即可,其他代码完全不需要修改。
接下来就是使用该模式,对凑单全域进行改造升级,核心架构图如下

各个域需要满足如下条件:
支持单个处理和批量处理
支持提前阻断
支持前置判断是否需要处理
处理类类图如下
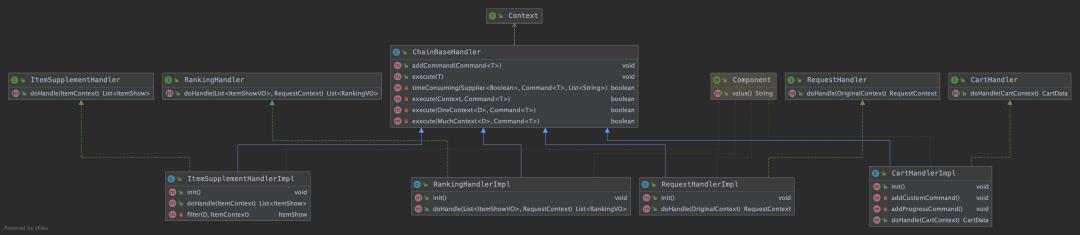
【ChainBaseHandler】:核心处理类
【CartHandler】:加购域处理类
【ItemSupplementHandler】:商品域处理类
【RankingHandler】:榜单域处理类
【RequestHanlder】:参数域处理类
我们首先来看核心处理层:
public class ChainBaseHandler<T extends Context>
/**
* 任务执行
* @param context
*/
public void execute(T context)
List<String> executeCommands = Lists.newArrayList();
for (Command<T> c : commands)
try
// 前置校验
if (!c.check(context))
continue;
// 执行
boolean isContinue = timeConsuming(() -> execute(context, c), c, executeCommands);
if (!isContinue)
break;
catch (Throwable e)
// 打印异常信息
GatherContext.debug("exception", c.getClass().getSimpleName());
GatherContext.error(c.getClass().getSimpleName() + " catch exception", e);
// 打印个命令任务耗时
GatherContext.debug(this.getClass().getSimpleName() + "-execute", executeCommands);
中间的timeConsuming方法用来计算耗时,耗时需要前后包裹执行方法
private boolean timeConsuming(Supplier<Boolean> supplier, Command<T> c, List<String> executeCommands)
long startTime = System.currentTimeMillis();
boolean isContinue = supplier.get();
long endTime = System.currentTimeMillis();
long timeConsuming = endTime - startTime;
executeCommands.add(c.getClass().getSimpleName() + ":" + timeConsuming);
return isContinue;
具体执行如下:
/**
* 执行每个命令
* @return 是否继续执行
*/
private <D extends ContextData> boolean execute(Context context, Command<T> c)
if (context instanceof MuchContext)
return execute((MuchContext<D>) context, c);
if (context instanceof OneContext)
return execute((OneContext<D>) context, c);
return true;
/**
* 单数据执行
* @return 是否继续执行
*/
private <D extends ContextData> boolean execute(OneContext<D> oneContext, Command<T> c)
if (Objects.isNull(oneContext.getData()))
return false;
if (c instanceof CommonCommand)
return ((CommonCommand<OneContext<D>>) c).execute(oneContext);
return true;
/**
* 批量数据执行
* @return 是否继续执行
*/
private <D extends ContextData> boolean execute(MuchContext<D> muchContext, Command<T> c)
if (CollectionUtils.isEmpty(muchContext.getData()))
return false;
if (c instanceof SingleCommand)
muchContext.getData().forEach(data -> ((SingleCommand<MuchContext<D>, D>) c).execute(data, muchContext));
return true;
if (c instanceof CommonCommand)
return ((CommonCommand<MuchContext<D>>) c).execute(muchContext);
return true;入参都是统一的context,其中的data为需要拼装的数据。类图如下
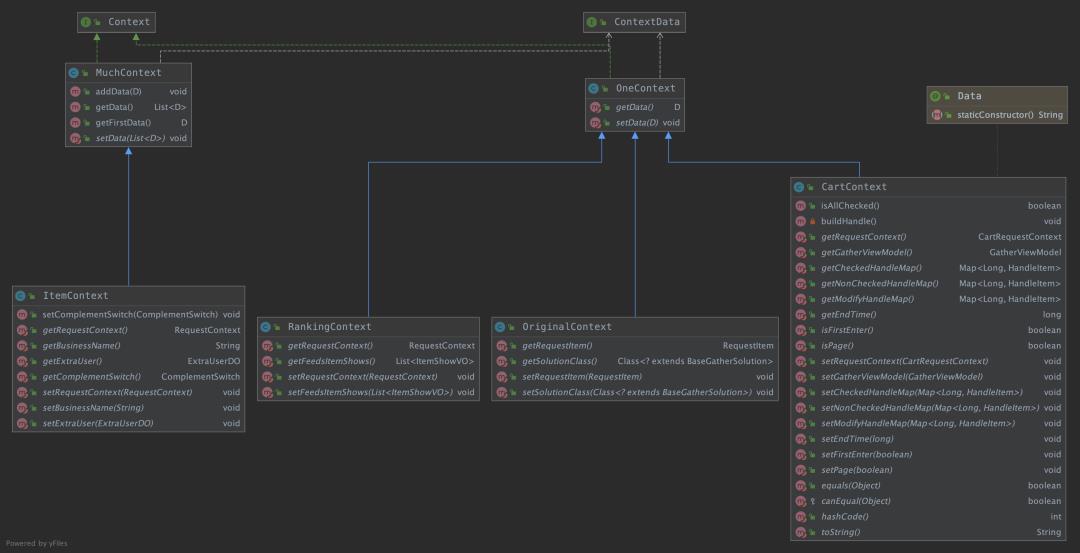
MuchContext(多值的数据拼装上下文),data是个集合
public class MuchContext<D extends ContextData> implements Context
protected List<D> data;
public void addData(D d)
if (CollectionUtils.isEmpty(this.data))
this.data = Lists.newArrayList();
this.data.add(d);
public List<D> getData()
if (Objects.isNull(this.data))
this.data = Lists.newArrayList();
return this.data;
OneContext(单值的数据拼装上下文),data是个对象
public class OneContext <D extends ContextData> implements Context
protected D data;
各域可根据自己需要实现,各个实现的context也使用了领域模型的思想,将对入参的一些操作封装在此,简化各个命令处理器的获取成本。举个例子,比如入参是一系列操作集合 List<HandleItem> handle。但实际使用是需要区分各个操作,那我们就需要在context中做好初始化,方便获取:
private void buildHandle()
// 勾选操作集合
this.checkedHandleMap = Maps.newHashMap();
// 去勾选操作集合
this.nonCheckedHandleMap = Maps.newHashMap();
// 修改操作集合
this.modifyHandleMap = Maps.newHashMap();
Optional.ofNullable(requestContext.getExtParam())
.map(CartExtParam::getHandle)
.ifPresent(o -> o.forEach(v ->
if (Objects.equals(v.getType(), CartHandleType.checked))
checkedHandleMap.put(v.getCartId(), v);
if (Objects.equals(v.getType(), CartHandleType.nonChecked))
nonCheckedHandleMap.put(v.getCartId(), v);
if (Objects.equals(v.getType(), CartHandleType.modify))
modifyHandleMap.put(v.getCartId(), v);
));
下面来看各个命令处理器,类图如下:
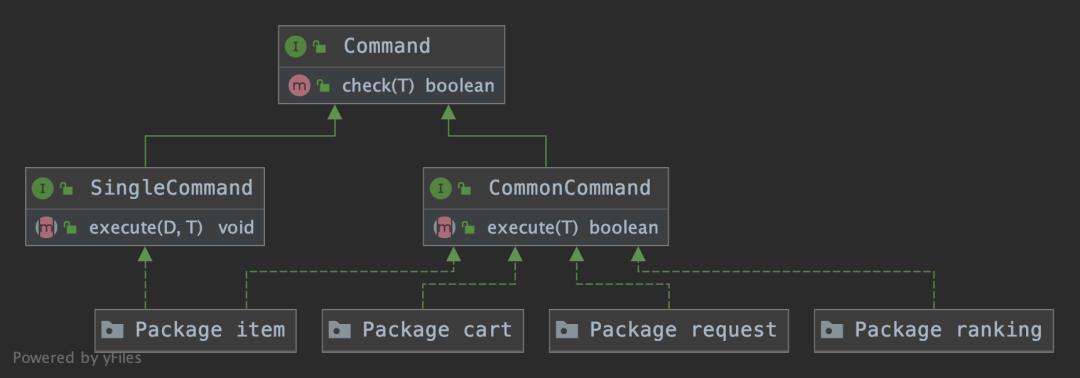
命令处理器主要分为SingleCommand和CommonCommand,CommonCommand为普通类型,即将data交与各个命令自行处理,而SingleCommand则是针对批量处理的情况下,将data集合提前拆好。两个核心区别就在于一个在框架层执行data的循环,一个是在各个命令层处理循环。主要作用在于:
SingleCommand减少重复循环代码
CommonCommand针对下游需要批量处理的可提高性能
下方是一个使用例子:
public class CouponCustomCommand implements CommonCommand<CartContext>
@Override
public boolean check(CartContext context)
// 如果不是跨店满减或者品类券,不进行该命令处理
return Objects.equals(BenefitEnum.kdmj, context.getRequestContext().getCouponData().getBenefitEnum())
|| Objects.equals(BenefitEnum.plCoupon, context.getRequestContext().getCouponData().getBenefitEnum());
@Override
public boolean execute(CartContext context)
CartData cartData = context.getData();
// 命令处理
return true;
最终的成品如下,各个命令执行顺序一目了然
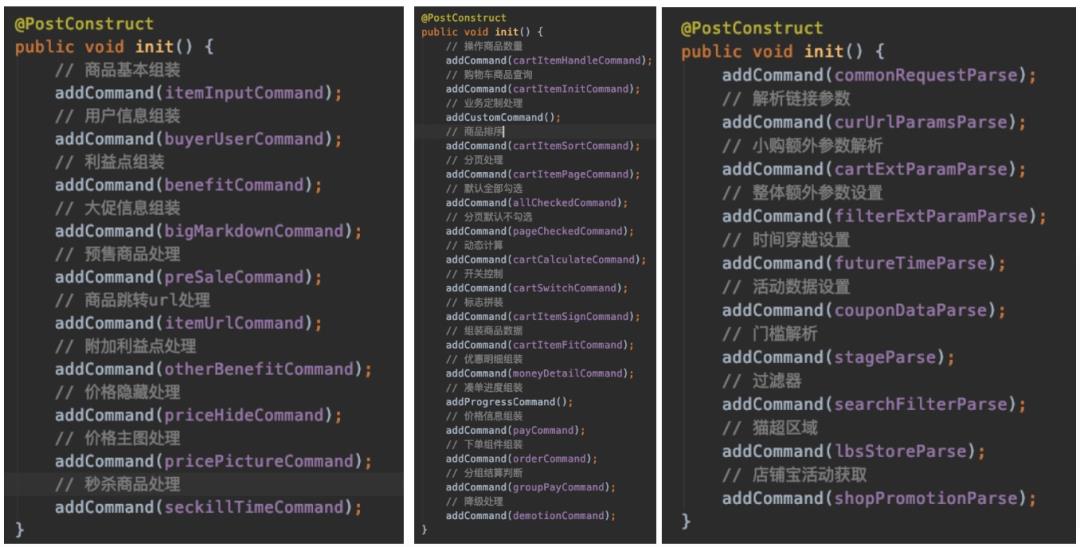
▐ 多算法分流设计
上面讲完了底层的一些代码结构设计,接下来讲一讲针对业务层的代码设计。凑单分为很多个模块,推荐feeds流、榜单模块、秒杀模块、搜索模块。整体效果图如下:
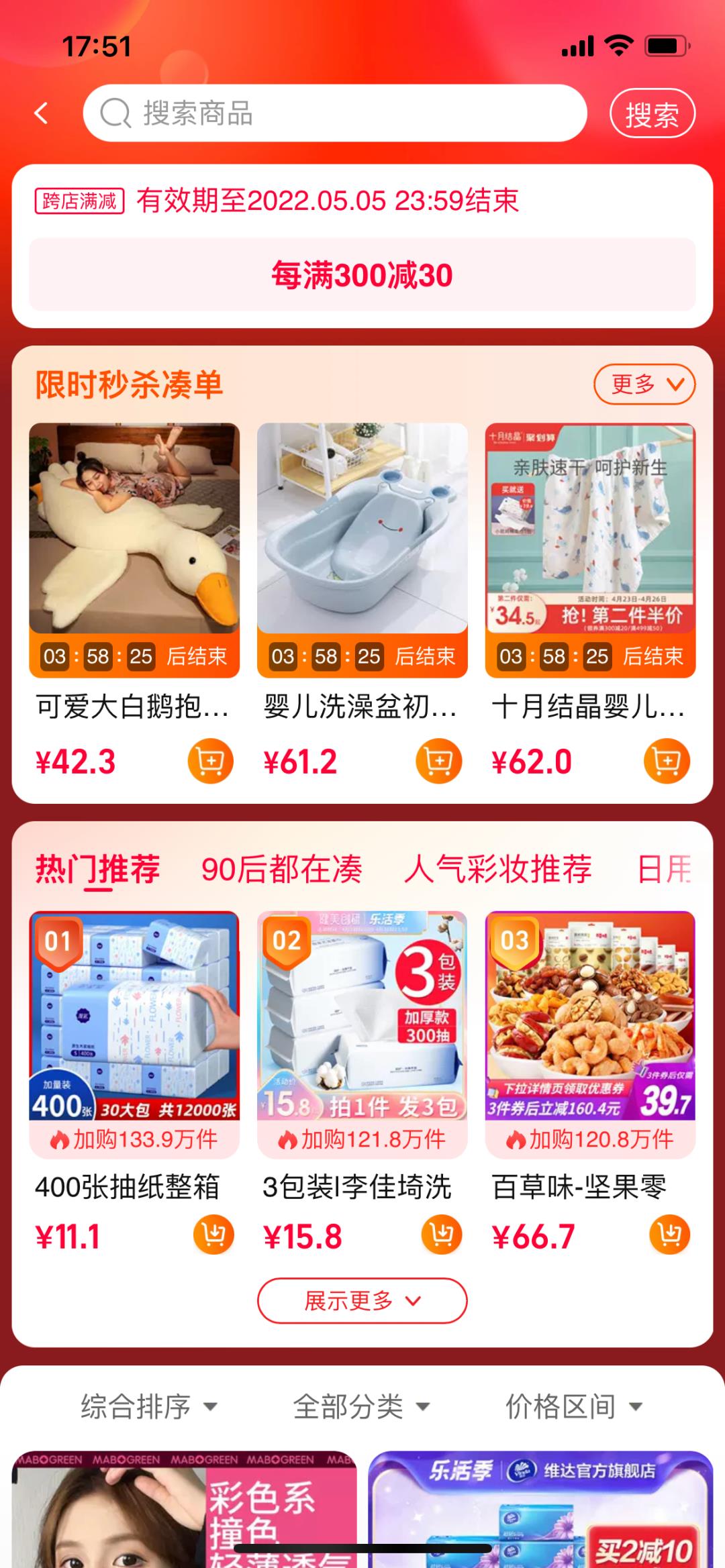
针对这种不同模块使用不同的算法,我们最先能想到的设计就是每个模块都是一个单独的接口。各自组装各自的逻辑。但在实现过程中会发现,这其中有很多通用的逻辑,比如推荐feeds流和限时秒杀模块,使用的都是凑单引擎的,算法逻辑完全相同,只是多了获取秒杀key的逻辑,所以我会选择使用同一个接口,让该接口能够尽量的通用。这里我选用了策略工厂模式,核心类图如下:
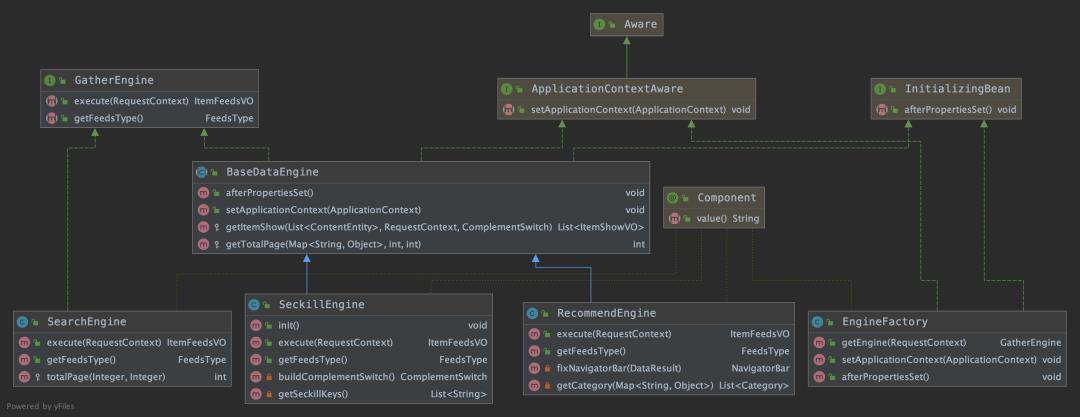
【SeckillEngine】:秒杀引擎,用于秒杀模块业务逻辑封装
【RecommendEngine】:推荐引擎,用于推荐feeds流业务逻辑封装
【SearchEngine】:搜索引擎,用于搜索模块业务逻辑封装
【BaseDataEngine】:通用数据引擎,将引擎的通用层抽离出来,简化通用代码
【EngineFactory】:引擎工厂,用于模块路由到合适的引擎
该模式下,针对可能不断累加的模块,能完成快速的开发并投入使用,该模式也是比较通用,大家都会选择的模式,我这里就不再过多的业务阐述了,就讲讲我对策略模式的理解吧,一提到策略模式,有人就觉得,它的作用是避免 if-else 分支判断逻辑。实际上,这种认识是很片面的。策略模式主要的作用还是解耦,控制代码的复杂度,让每个部分都不至于过于复杂、代码量过多。除此之外,对于复杂代码来说,策略模式还能让其满足开闭原则,添加新策略的时候,最小化、集中化代码改动,减少引入 bug 的风险。
P.S. 实际上,设计原则和思想比设计模式更加普适和重要。掌握了代码的设计原则和思想,我们能更清楚的了解,为什么要用某种设计模式,就能更恰到好处地应用设计模式。
取巧的功能设计
▐ 凑单购物车部分
设计的背景
凑单是跨店优惠工具使用链路上的核心环节,用户对凑单有很高的诉求,但目前由于凑单页不支持实时凑单进度提示等问题,导致用户凑单体验较差,亟需优化凑单体验进而提升流量转化效率。但由于某些原因,我们不得不独立开发一套凑单购物车,同时加上凑单进度,其中商品数据源以及动态计算能力还是使用的淘宝购物车。
基本框架结构设计
凑单页购物车是需要展示满足某个跨店满减活动的商品(套购同理),我不能直接使用购物车的接口直接返回所有商品数据以及优惠明细。所以我这里将购物车的访问拆成了两个部分,第一步先通过购物车的data.query接口查询出该用户所有加购的商品(该商品数据只有id,数量,时间相关的信息)。在凑单页先进行一次活动商品过滤后,再将剩余的商品调用购物车的动态计算接口,完成整个凑单购物车内所有数据的展示。流程如下:
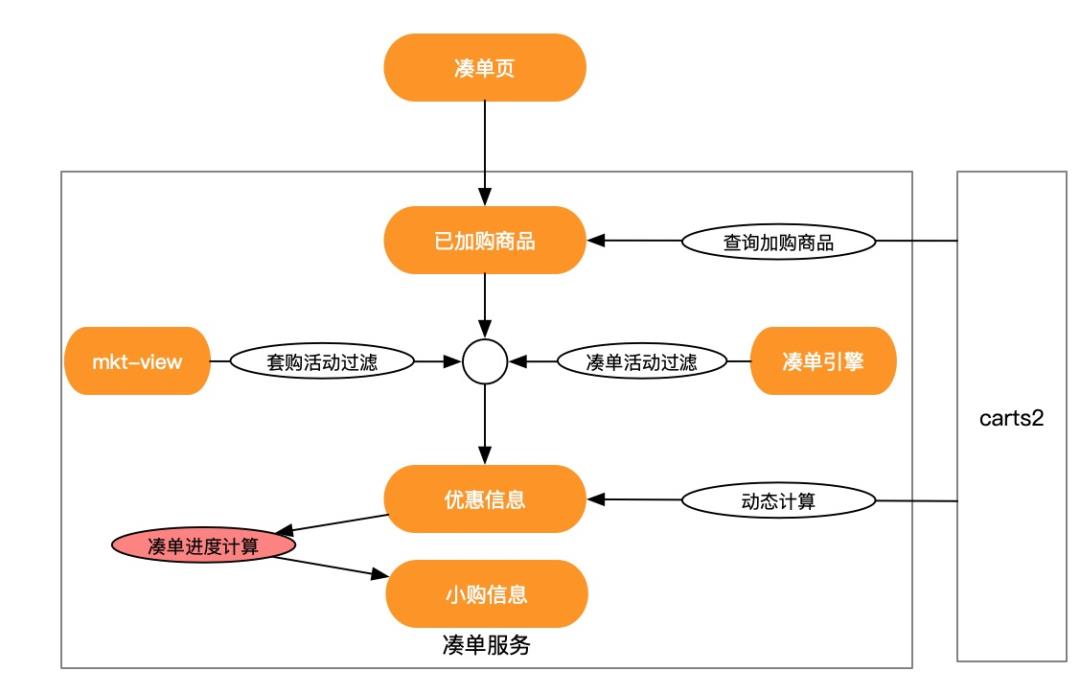
分页排序设计
大促期间,购物车大部分加购的品都是满足跨店满减活动的,如果每次都所有的商品参与动态计算并一次返回,性能会非常的差,所以这里就需要做到分页,页面展示如果涉及到了分页,难度系数将成倍的上升。首先我们来看凑单购物车的排序需求:
首次进入凑单页商品的顺序需要和购物车保持一致
同一个店铺的需要放在一起,按加购时间倒序排
店铺间按最新加购的某个商品的加购时间倒序排
如果是从某个店铺点进来的,该店铺需要在凑单页置顶,并主动勾选
如果过程中发现有新加入的品,该品需要置顶(不用将该店铺的其他品置顶)
如果过程中发现有失效的商品需要沉底(放到最后一页并沉底)
如果过程中发现有失效的品转成生效,需移上来
难点分析
排序并不是简单的按照时间维度排,增加的店铺维度,以及店铺置顶的能力
我们没有自己的数据源,每次查出来都得重新排序
第一次进入的排序和后续新加购的商品排序不同
支持分页
技术方案
首先能想到的就是找个地方存一下排序好的顺序,第一选择肯定是使用redis,但根据评估如果按用户维度去存储商品顺序,亿级的用户量 * 活动量需要耗费几百G的缓存容量,同时还需要维护该缓存的生命周期,相对还是比较麻烦。这种用户维度的缓存最好是通过客户端来进行缓存,我该如何利用前端来做该缓存,并让前端无感知呢?以下是我的接口设计:
itemList | [ "cartId": 11111, "quantity":50, "checked": 是否勾选 ] | 当前所有前端的品 |
sign | 标志,前端不需要关注里面的东西,后端返回直接传,如果没有就不传 | |
next | true | 是否继续加载 |
allChecked | true | 是否全选 |
handle | [ "cartId":1111, "quantity": 5, "checked":true, "type": modify ] | type=modify更新,checked勾选,nonChecked去掉勾选 |
其中sign对象服务端返回给前端,下一次请求需要将sign对象原封不动的传给服务端,sign中存储了分页信息,以及需要商品的排序,sign对象如下:
public class Sign
/**
* 已加载到到权重
*/
private Integer weight;
/**
* 本次查询购物车商品最晚加购时间
*/
private Long endTime;
/**
* 上一次查询购物车所有排序好的商品
*/
private List<CartItemData> activityItemList;
具体方案
首次进入按商品加购时间以及店铺维度做好初始排序,并标记weight(第一个200,第二个199,依次类推),并保存在sign对象的activityItemList中,取第一页数据,并将该页最小weight和所有商品的最晚加购时间endTime同步记录到sign中。并将sign返回给前端
前端在加载下一页时将上次请求后端返回的sign字段重新传给后端,后端根据sign中的weight大小判断,依次取下一页数据,同时将最新的最小weight写入sign,返回给前端。
期间如果发现有商品的加购时间大于sign中的endTime,则主动将其置顶,weight使用默认最大数字200。
由于在排序时无法知道商品是否失效以及能够勾选,所以需要在商品补全后(调用购物车的动态计算接口)重新对失效商品排序。
如果本页没有失效的品,不做处理
如果本页全是失效的品,不做处理(为了处理最后几页都是失效品的情况)
如果有下一页,将失效的品放到后面页沉底
如果当前页是最后一页,则直接沉底
方案时序图如下:

商品勾选设计
购物车的商品勾选后就会出现勾选商品的下单价格以及能享受的各类优惠,勾选情况主要分为:
勾选、反勾选、全选
全选情况下加载下一页
勾选的商品数量变化
效果图如下:

难点
勾选的品越多,动态计算的rt越长,当50个品一起勾选,页面接口返回时间将近1.5s
全选的情况下,下拉加载需要将新加载出来的品主动勾选上
尽可能的减少调用动态计算(比如加载非勾选的品,修改非勾选的商品数量)
设计方案
由于可能需要计算所有勾选的商品,所以前端需要将当前所有已加载的商品数据的勾选状态告知服务端
超过50个勾选商品时,不再调用动态计算接口,直接用本地价格计算总价,同时降级优惠明细和凑单进度
前端根据后端返回结果进行合并操作,减少不必要的计算开销
整体逻辑如下:
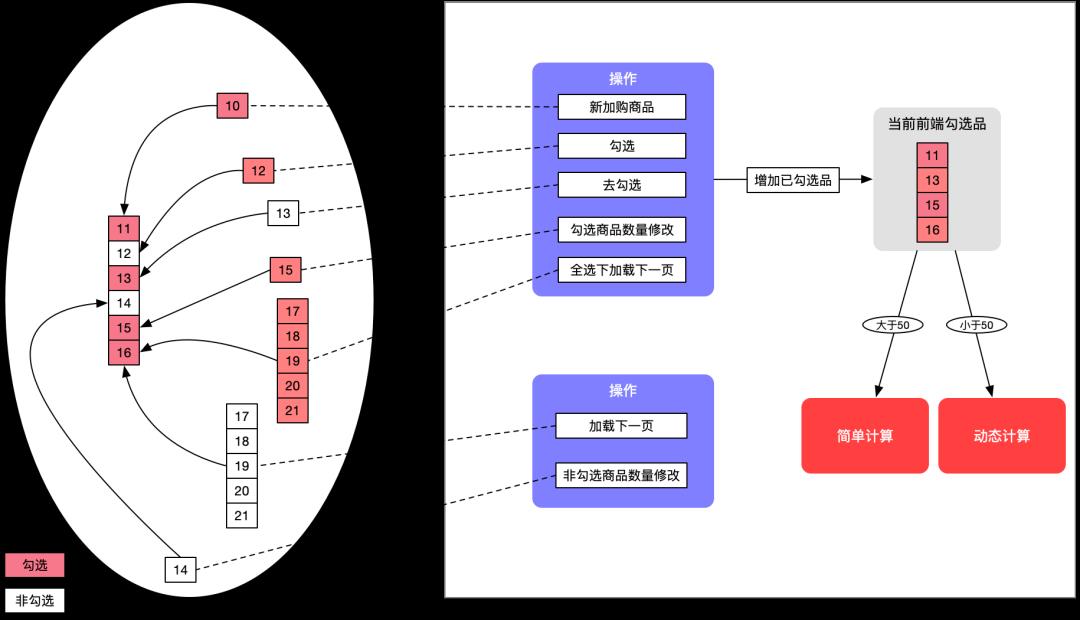
同时针对勾选处理,我将各类获取商品信息的动作封装进领域模型中(比如已勾选品,全部品,下一页品,操作的品,方便复用,⬆️代码设计已经讲过),获取各类商品的逻辑代码如下:
List<CartItemData> activityItemList = cartData.getActivityItemList();
Map<Long, CartItem> alreadyMap = requestContext.getAlreadyMap();
Map<Long, CartItem> checkedItemMap = requestContext.getCheckedItemMap();
Map<Long, CartItemData> addNextItemMap = Optional.ofNullable(cartData.getAddNextItemList())
.map(o -> o.stream().collect(Collectors.toMap(CartItemData::getCartId, Function.identity())))
.orElse(Collections.emptyMap());
Map<Long, HandleItem> checkedHandleMap = context.getCheckedHandleMap();
Map<Long, HandleItem> nonCheckedHandleMap = context.getNonCheckedHandleMap();
Map<Long, HandleItem> modifyHandleMap = context.getModifyHandleMap();勾选处理的逻辑代码如下:
boolean calculateAllChecked = isCalculateAllChecked(context, activityItemList);
activityItemList.forEach(v ->
CartItemDetail cartItemDetail = CartItemDetail.build(v);
// 新加入的品,加入动态计算列表,并勾选
if (v.getLastAddTime() > context.getEndTime())
cartItemDetail.setChecked(true);
cartData.addCalculateItem(cartItemDetail);
// 勾选操作的品,加入动态计算列表,并勾选
else if (checkedHandleMap.containsKey(v.getCartId()))
cartItemDetail.setChecked(true);
cartData.addCalculateItem(cartItemDetail);
// 取消勾选的品,加入动态计算列表,并去勾选
else if (nonCheckedHandleMap.containsKey(v.getCartId()))
cartItemDetail.setChecked(false);
cartData.addCalculateItem(cartItemDetail);
// 勾选商品的数量修改,加入动态计算
else if (modifyHandleMap.containsKey(v.getCartId()))
cartItemDetail.setChecked(modifyHandleMap.get(v.getCartId()).getChecked());
cartData.addCalculateItem(cartItemDetail);
// 加载下一页,加入动态计算,如果是全选动作下,则将该页商品勾选
else if (addNextItemMap.containsKey(v.getCartId()))
if (context.isAllChecked())
cartItemDetail.setChecked(true);
cartData.addCalculateItem(cartItemDetail);
// 判断是否需要将之前所有勾选的商品加入动态计算
else if (calculateAllChecked && checkedItemMap.containsKey(v.getCartId()))
cartItemDetail.setChecked(true);
cartData.addCalculateItem(cartItemDetail);
);P.S. 这里可能有人会发现,这么多的if-else就觉得它是烂代码。如果 if-else 分支判断不复杂、代码不多,这并没有任何问题,毕竟 if-else 分支判断几乎是所有编程语言都会提供的语法,存在即有理由。遵循 KISS 原则,怎么简单怎么来,就是最好的设计。非得用策略模式,搞出 n 多类,反倒是一种过度设计。
▐ 营销商品引擎key设计
设计的背景
跨店满减和品类券从引擎中筛选是通过couponTagId + couponValue来召回的,couponTagId是ump的活动id,couponValue则是记录了满减信息。随着需求的迭代,我们需要展示满足跨店满减并同时满足其他营销玩法(比如限时秒杀)的商品,这里我们已经能筛选出满足跨店满减的品,但如果筛选出当前正在生效的限时秒杀的品呢?

详细索引设计
导购的召回主要依赖倒排索引,而我们秒杀商品召回的关键是正在生效,所以我的设想是将时间写入key中,就有了如下设计:
字段示例:mkt_fn_t_60_08200000_60
index | 例子 | 描述 |
0 | mkt | 营销工具平台 |
1 | fn | 前N |
2 | t | 前N分钟 |
3 | 60 | 开始前60分钟为预热时间 |
4 | 08200000 | 8月20号0点0分 |
5 | 60 | 开始后60分钟为结束时间 |
使用方可以遍历当前所有key,本地计算出当前正在生效的key再进行召回,具体细节这里就不做阐述了
最后的总结
▐ 设计的初衷是提高代码质量
我们经常会讲到一个词:初心。这词说的其实就是,你到底是为什么干这件事。不管走多远、产品经过多少迭代、转变多少次方向,“初心”一般都不会随便改。实际上,写代码也是如此。应用设计模式只是方法,最终的目的是提高代码的质量。具体点说就是,提高代码的可读性、可扩展性、可维护性等。所有的设计都是围绕着这个初心来做的。
所以,在做代码设计的时候,一定要先问下自己,为什么要这样设计,为什么要应用这种设计模式,这样做是否能真正地提高代码质量,能提高代码质量的哪些方面。如果自己很难讲清楚,或者给出的理由都比较牵强,那基本上就可以断定这是一种过度设计,是为了设计而设计。
▐ 设计的过程是先有问题后有方案
在设计的过程中,我们要先去分析代码存在的痛点,比如可读性不好、可扩展性不好等等,然后再针对性地利用设计模式去改善,而不是看到某个场景之后,觉得跟之前在某本书中看到的某个设计模式的应用场景很相似,就套用上去,也不考虑到底合不合适,最后如果有人问起了,就再找几个不痛不痒、很不具体的伪需求来搪塞,比如提高了代码的扩展性、满足了开闭原则等等。
▐ 设计的应用场景是复杂代码
设计模式的主要作用就是解耦,也就是利用更好的代码结构将一大坨代码拆分成职责更单一的小类,让其满足高内聚低耦合等特性。而解耦的主要目的是应对代码的复杂性。设计模式就是为了解决复杂代码问题而产生的。
因此,对于复杂代码,比如项目代码量多、开发周期长、参与开发的人员多,我们前期要多花点时间在设计上,越是复杂代码,花在设计上的时间就要越多。不仅如此,每次提交的代码,都要保证代码质量,都要经过足够的思考和精心的设计,这样才能避免烂代码。
相反,如果你参与的只是一个简单的项目,代码量不多,开发人员也不多,那简单的问题用简单的解决方案就好,不要引入过于复杂的设计模式,将简单问题复杂化。
▐ 持续重构能有效避免过度设计
应用设计模式会提高代码的可扩展性,但同时也会带来代码可读性的降低,复杂度的升高。一旦我们引入某个复杂的设计,之后即便在很长一段时间都没有扩展的需求,我们也不可能将这个复杂的设计删除,后面一直要背负着这个复杂的设计前行。
为了避免错误的预判导致过度设计,我比较喜欢持续重构的开发方法。持续重构不仅仅是保证代码质量的重要手段,也是避免过度设计的有效方法。我上面的核心流程处理的框架代码,也是在一次又一次的重构中才写出来的。
团队介绍
营销工具平台,向上支撑淘宝天猫 30+业务场景,向下跟交易全链路系统、营销中台、其他工具平台打通,作为业务的营销抓手,促转化,提客单,引导复购;平台除支撑淘宝天猫的日常营销活动,还有双十一,618,年货节等大促活动的核心工具。
✿ 拓展阅读


作者|鸣翰(郑健)
编辑|橙子君

以上是关于谈一谈凑单页的那些优雅设计的主要内容,如果未能解决你的问题,请参考以下文章