码农吧干货谈一谈数据库的那些事Ⅱ
Posted 毛奇志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了码农吧干货谈一谈数据库的那些事Ⅱ相关的知识,希望对你有一定的参考价值。

/ 介绍一下数据库并发策略? /
并发控制一般采用三种方法,分别是乐观锁和悲观锁以及时间戳。
乐观锁:持有一种乐观的态度,觉得自己读数据库的时候,别人不会刚好在写自己刚读的数据,所以每次读写数据库都要不加锁;
悲观锁:持有一种悲观的态度,觉得自己读数据库的时候,别人可能刚好在写自己刚读的数据,所以每次读写数据库都要加锁;
时间戳:不加锁,通过时间戳来控制并发出现的问题。
1、乐观锁
乐观锁认为一个用户读数据的时候,别人不会去写自己所读的数据,所以不加锁,操作成功则无事,操作失败则回退。
2、悲观锁
悲观锁就是在读取数据的时候,为了不让别人修改自己读取的数据,就会先对自己读取的数据加锁,只有自己把数据读完了,才允许别人修改那部分数据,或者反过来说,就是自己修改某条数据的时候,不允许别人读取该数据,只有等自己的整个事务提交了,才释放自己加上的锁,才允许其他用户访问那部分数据。以上悲观锁所说的加“锁”,其实包括两种锁:排它锁(写锁)和共享锁(读锁)。
3、时间戳
时间戳就是在数据库表中单独加一列时间戳,比如“TimeStamp”,每次读出来的时候,把该字段也读出来,当写回去的时候,把该字段加1,提交之前 ,跟数据库的该字段比较一次,如果比数据库的值大的话,就允许保存,否则不允许保存,这种处理方法虽然不使用数据库系统提供的锁机制,但是这种方法可以大大提高数据库处理的并发量。

/ 介绍一下数据库锁? /
行级锁
行级锁是一种排他锁,防止其他事务修改此行。
锁定:INSERT、UPDATE、DELETE、SELECT … FOR UPDATE [OF columns] [WAIT n | NOWAIT]; 该语句允许用户一次锁定多条记录进行更新;
解锁:使用 COMMIT 或 ROLLBACK 语句释放锁。
表级锁
表级锁定包括表共享读锁(共享锁)与表独占写锁(排他锁),表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分 mysql 引擎支持,最常使用的 MYISAM 与 INNODB 都支持表级锁定。
页级锁
页级锁是 MySQL 中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录,BDB 支持页级锁。
/ 介绍一下数据库基于Redis的分布式锁? /
获取锁
获取锁的时候,使用 setnx 加锁,锁的 value 值为一个随机生成的 UUID,该 UUID 用于释放锁的时候进行判断。
SETNX key val:
若 key 不存在时,set 一个 key为 val 的字符串,返回 1 ,表示成功获取该锁;
若 key 存在,则什么都不做,返回 0 ,表示该锁正在被别人使用。
此外,设置一个获取的超时时间,若超过这个时间则放弃获取锁;还可以使用 expire 命令为这个锁添加一个超时时间,超过该时间则自动释放锁。
释放锁
释放锁的时候,通过 UUID 判断是不是该锁,若是该锁,则执行 delete 进行锁释放。
/ 介绍一下数据库分区、分表技术? /
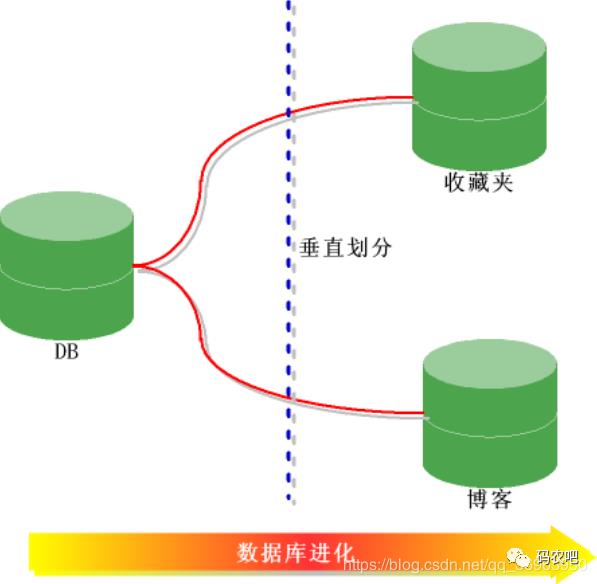
分库分表有垂直切分和水平切分两种。
垂直切分 ( 按照功能模块 )
将表按照功能模块、关系密切程度划分出来,部署到不同的库上。例如,我们会建立定义数据库 workDB、商品数据库 payDB、用户数据库 userDB、日志数据库 logDB 等,分别用于存储项目数据定义表、商品定义表、用户数据表、日志数据表等。
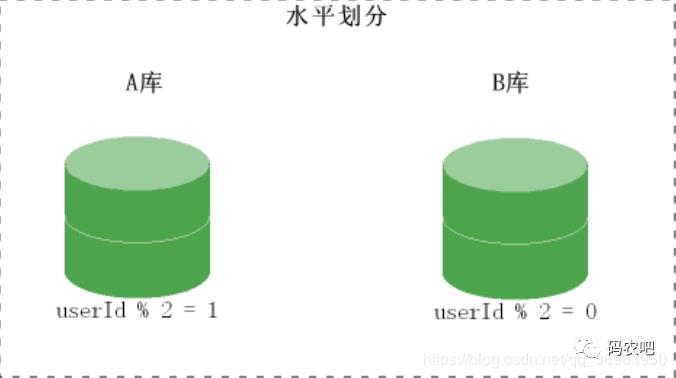
水平切分 ( 按照规则划分存储 )
当一个表中的数据量过大时,我们可以把该表的数据按照某种规则,例如 userID 散列,进行划分,然后存储到多个结构相同的表,和不同的库上。
/ 谈一谈数据库两阶段提交协议? /
分布式事务是指会涉及到操作多个数据库的事务,在分布式系统中,各个节点之间在物理上相互独立,通过网络进行沟通和协调。
XA 就是 X/Open DTP 定义的交易中间件与数据库之间的接口规范(即接口函数),交易中间件用它来通知数据库事务的开始、结束以及提交、回滚等。XA 接口函数由数据库厂商提供。
二阶段提交(Two-phaseCommit)是指,在计算机网络以及数据库领域内,为了使基于分布式系统架构下的所有节点在进行事务提交时保持一致性而设计的一种算法(Algorithm)。通常,二阶段提交也被称为是一种协议(Protocol))。在分布式系统中,每个节点虽然可以知晓自己的操作时成功或者失败,却无法知道其他节点的操作的成功或失败。当一个事务跨越多个节点时,为了保持事务的 ACID 特性,需要引入一个作为协调者的组件来统一掌控所有节点(称作参与者)的操作结果并最终指示这些节点是否要把操作结果进行真正的提交(比如将更新后的数据写入磁盘等等)。
因此,二阶段提交的算法思路可以概括为:参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是否要提交操作还是中止操作。
1、准备阶段
事务协调者(事务管理器)给每个参与者(资源管理器)发送 Prepare 消息,每个参与者要么直接返回失败(如权限验证失败),要么在本地执行事务,写本地的 redo 和 undo 日志,但不提交,到达一种“万事俱备,只欠东风”的状态。
2、提交阶段
如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源。(注意:必须在最后阶段释放锁资源)
3、两阶段提交存在的缺点
(1)参与者:同步阻塞问题
执行过程中,所有参与节点都是事务阻塞型的。
(2)协调者:单点故障
由于协调者的重要性,一旦协调者发生故障。参与者会一直阻塞下去。
(3)参与者:数据不一致 (脑裂问题)
在二阶段提交的阶段二中,当协调者向参与者发送 commit 请求之后,发生了局部网络异常或者在发送 commit 请求过程中协调者发生了故障,导致只有一部分参与者接受到了commit 请求。于是整个分布式系统便出现了数据部一致性的现象(脑裂现象)。
(4)协调者:二阶段无法解决的问题 (数据状态不确定)
协调者再发出 commit 消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了。那么即使协调者通过选举协议产生了新的协调者,这条事务的状态也是不确定的,没人知道事务是否被已经提交。
/ 介绍一下数据库三阶段提交协议? /
三 阶 段 提 交 ( Three-phase commit ) , 也 叫 三 阶 段 提 交 协 议 ( Three-phase commit protocol),是二阶段提交(2PC)的改进版本。
与两阶段提交不同的是,三阶段提交有两个改动点。
1、引入超时机制。同时在协调者和参与者中都引入超时机制。
2、在第一阶段和第二阶段中插入一个准备阶段。保证了在最后提交阶段之前各参与节点的状态是一致的。也就是说,除了引入超时机制之外,3PC 把 2PC 的准备阶段再次一分为二,这样三阶段提交就有 CanCommit、PreCommit、DoCommit 三个阶段。
(1)CanCommit 阶段
协调者向参与者发送 commit 请求,参与者如果可以提交就返回 Yes 响应,否则返回 No 响应。
(2)PreCommit 阶段
协调者根据参与者的反应情况来决定是否可以继续进行,有以下两种可能。假如协调者从所有的参与者获得的反馈都是Yes响应,那么就会执行事务的预执行;假如有任何一个参与者向协调者发送了 No 响应,或者等待超时之后,协调者都没有接到参与者的响应,那么就执行事务的中断。
(3)doCommit 阶段
该阶段进行真正的事务提交,主要包含:
a.协调者发送提交请求
b.参与者提交事务
c.参与者响应反馈(事务提交完之后,向协调者发送 Ack 响应,告诉协调者自己提交完了)
d.协调者确定完成事务。
/ 介绍一下CAP原则? /
CAP 原则又称 CAP 定理,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。
一致性(C)
在分布式系统中的所有数据备份,在同一时刻是否同样的值(等同于所有节点访问同一份最新的数据副本)。
可用性(A)
在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求(对数据更新具备高可用性)。
分区容忍性(P)
以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在 C 和 A 之间做出选择。
/ 谈一谈对柔性事务的认识? /
BASE 理论是在 CAP 理论的基础之上的延伸,包括 基本可用(Basically Available)、柔性状态(Soft State)、最终一致性(Eventual Consistency)。
通常所说的柔性事务分为:两阶段型、补偿型、异步确保型、最大努力通知型几种。
两阶段型
就是分布式事务两阶段提交,对应技术上的 XA、JTA/JTS。这是分布式环境下事务处理的典型模式。
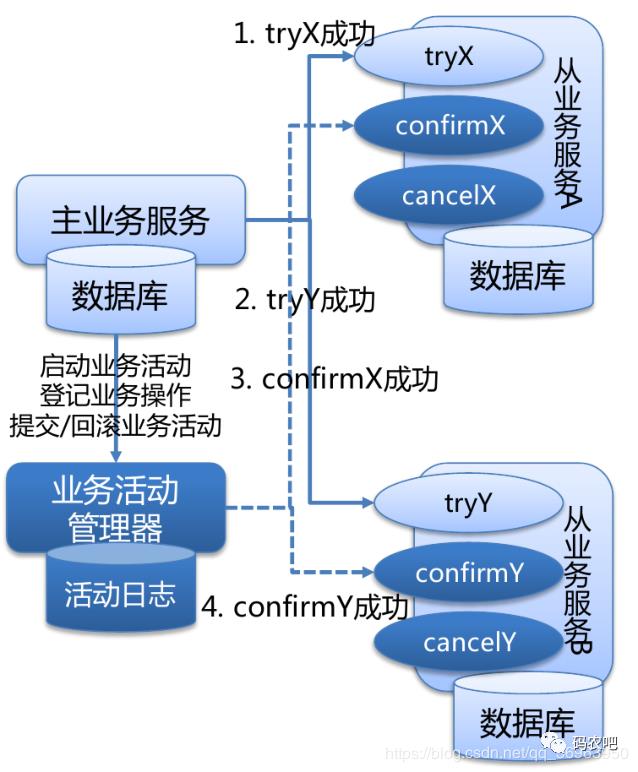
补偿型
TCC 型事务(Try/Confirm/Cancel)可以归为补偿型。
WS-BusinessActivity 提供了一种基于补偿的 long-running 的事务处理模型。服务器 A 发起事务,服务器 B 参与事务,服务器 A 的事务如果执行顺利,那么事务 A 就先行提交,如果事务 B 也执行顺利,则事务 B 也提交,整个事务就算完成。但是如果事务 B 执行失败,事务 B 本身回滚,这时事务 A 已经被提交,所以需要执行一个补偿操作,将已经提交的事务 A 执行的操作作反操作,恢复到未执行前事务 A 的状态。这样的 SAGA 事务模型,是牺牲了一定的隔离性和一致性的,但是提高了 long-running 事务的可用性。
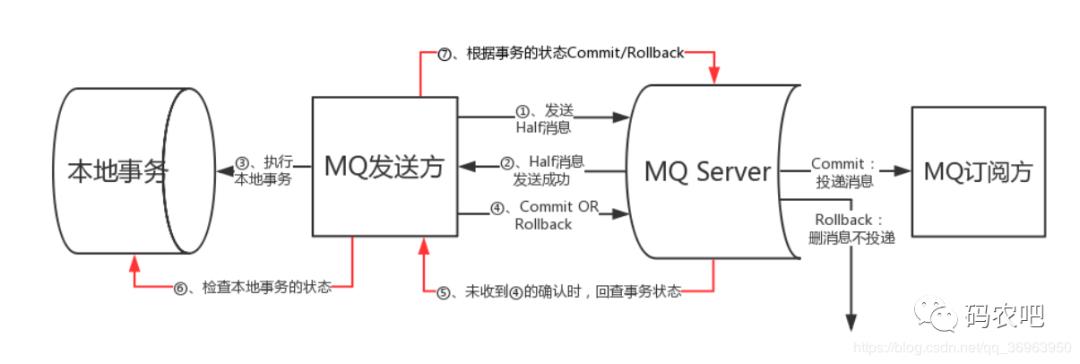
异步确保型
通过将一系列同步的事务操作变为基于消息执行的异步操作, 避免了分布式事务中的同步阻塞操作的影响。
最大努力通知型 (多次尝试)
这是分布式事务中要求最低的一种, 也可以通过消息中间件实现, 与前面异步确保型操作不同的一点是, 在消息由 MQ Server 投递到消费者之后, 允许在达到最大重试次数之后正常结束事务。
/ 介绍一下分布式缓存? /
1、常见问题:缓存雪崩
缓存雪崩我们可以简单的理解为:由于原有缓存失效,新缓存未到期间所有原本应该访问缓存的请求都去查询数据库了,而对数据库 CPU 和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。一般有三种处理办法:
(1)一般并发量不是特别多的时候,使用最多的解决方案是加锁排队。
(2)给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。
(3)为 key 设置不同的缓存失效时间。
2、 常见问题:缓存穿透
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
有很多种方法可以有效地解决缓存穿透问题,最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。通过这个直接设置的默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库。
3、常见技巧:缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
4、常见技巧:缓存更新
缓存更新除了缓存服务器自带的缓存失效策略之外(Redis 默认的有 6 中策略可供选择),我们还可以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:
(1)定时去清理过期的缓存;
(2)当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。
5、常见技巧:缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。
end
扫描二维码更精彩
以上是关于码农吧干货谈一谈数据库的那些事Ⅱ的主要内容,如果未能解决你的问题,请参考以下文章