机器学习项目实战识别mnist数据集识别图片数字
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习项目实战识别mnist数据集识别图片数字相关的知识,希望对你有一定的参考价值。
目录
1 机器学习分析步骤
机器学习项目的实际过程大致分为以下5个环节。
(1)问题定义。
(2)数据的收集和预处理。
(3)模型(算法)的选择。
(4)选择机器学习模型。
(5)超参数调试和性能优化。
2 问题定义
这里要向大家介绍MNIST数据集。这个数据集相当于是机器学习领域的HelloWorld,非常的经典,里面包含60000张训练图像和10000张测试图像,都是28px×28px的手写数字灰度图像,如下图所示。
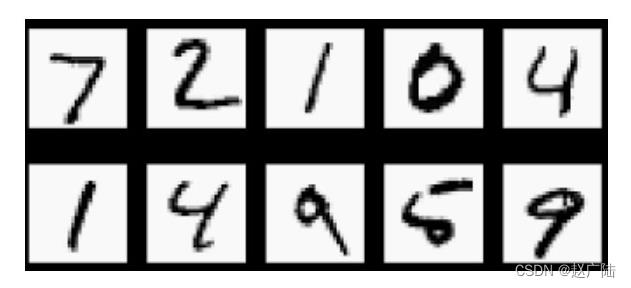
此处要解决的问题是:将手写数字灰度图像分类为0,1,2,3,4,5,6,7,8,9,共10个类别。
注:灰度图像与黑白图像不同哦,黑白图像只有黑、白两种颜色,对应的像素的值是0和1;而灰度图像在黑色与白色之间还有许多灰度级别,取值为0~255。
2 数据的收集和预处理
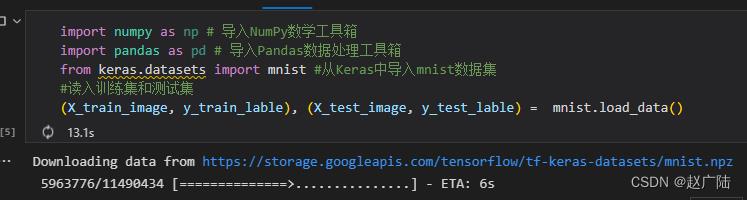
这里直接载入Keras自带的MNIST数据集,如下段代码所示
import numpy as np # 导入NumPy数学工具箱
import pandas as pd # 导入Pandas数据处理工具箱
from keras.datasets import mnist #从Keras中导入mnist数据集
#读入训练集和测试集
(X_train_image, y_train_lable), (X_test_image, y_test_lable) = mnist.load_data()
解析:
X_train_image:训练集特征—图片
y_train_lable:训练集标签—数字
X_test_image:测试集特征—图片
y_test_lable:测试集标签—数字
print ("特征集张量形状:", X_train_image.shape) #用shape方法显示张量的形状
print ("第一个数据样本:\\n", X_train_image[0]) #注意Python的索引是从0开始的
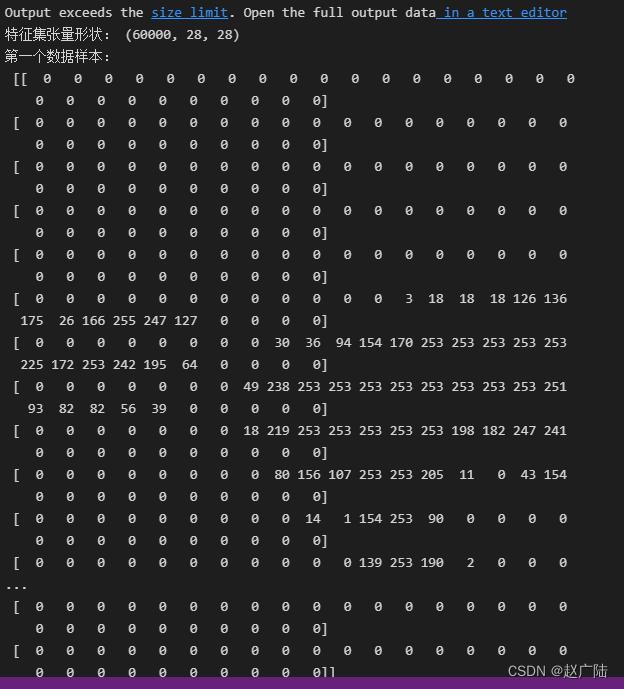
整理了一下这个数据集还是比较像5的

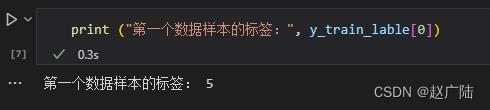
print ("第一个数据样本的标签:", y_train_lable[0])
第一个数据样本对应的标签
上面的数据集在输入机器学习模型之前还要做一些数据格式转换的工作:
from tensorflow.keras.utils import to_categorical # 导入keras.utils工具箱的类别转换工具
X_train = X_train_image.reshape(60000,28,28,1) # 给标签增加一个维度
X_test = X_test_image.reshape(10000,28,28,1) # 给标签增加一个维度
y_train = to_categorical(y_train_lable, 10) # 特征转换为one-hot编码
y_test = to_categorical(y_test_lable, 10) # 特征转换为one-hot编码
print ("数据集张量形状:", X_train.shape) # 特征集张量的形状
print ("第一个数据标签:",y_train[0]) # 显示标签集的第一个数据
训练集张量形状:(60000, 28, 28, 1)
第一个数据标签:[0.0.0.0.0.0.0.0.1.0.]
解释:
(1)Keras要求图像数据集导入卷积网络模型时为4阶张量,最后一阶代表颜色深度,灰度图像只有一个颜色通道,可以设置其值为1。
(2)在机器学习的分类问题中,标签 [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]就代表着类别值5。这是等会儿还要提到的one-hot编码。
3 选择机器学习模型
这里使用卷积神经网络

from keras import models # 导入Keras模型, 和各种神经网络的层
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
model = models.Sequential() # 用序贯方式建立模型
model.add(Conv2D(32, (3, 3), activation='relu', # 添加Conv2D层
input_shape=(28,28,1))) # 指定输入数据样本张量的类型
model.add(MaxPooling2D(pool_size=(2, 2))) # 添加MaxPooling2D层
model.add(Conv2D(64, (3, 3), activation='relu')) # 添加Conv2D层
model.add(MaxPooling2D(pool_size=(2, 2))) # 添加MaxPooling2D层
model.add(Dropout(0.25)) # 添加Dropout层
model.add(Flatten()) # 展平
model.add(Dense(128, activation='relu')) # 添加全连接层
model.add(Dropout(0.5)) # 添加Dropout层
model.add(Dense(10, activation='softmax')) # Softmax分类激活,输出10维分类码
# 编译模型
model.compile(optimizer='rmsprop', # 指定优化器
loss='categorical_crossentropy', # 指定损失函数
metrics=['accuracy']) # 指定验证过程中的评估指标
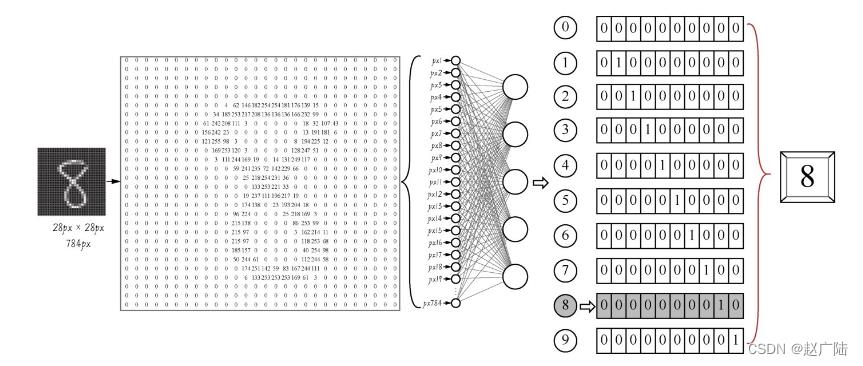
这里先简单地解释一下代码中都做了些什么。这段代码把数据集放入卷积神经网络进行处理。这个网络中包括两个Conv2D(二维卷积)层,两个MaxPooling2D(最大池化)层,两个Dropout层用于防止过拟合,还有Dense(全连接)层,最后通过Softmax分类器输出预测标签y’值,也就是所预测的分类值。这个y’值,是一个one-hot(即“一位有效编码”)格式的10维向量。我们可以将y’与标签真值y进行比较,以计算预测的准确率。整个过程如下图所示。
4 训练机器,确定参数
确定机器学习模型的算法类型之后,就进行机器的学习,训练机器以确定最佳的模型内部参数,并使用模型对新数据集进行预测。之所以说在这一环节中确定的是模型内部参数,是因为机器学习中还有超参数的概念。
内部参数:机器学习模型的具体参数值,例如线性函数y=2x+1,其中的2和1就是模型内参数。在机器学习里面这叫作权重(weight)和偏置(bias)。神经网络也类似,每一个节点都有自己的权重(或称kernel),网络的每一层也有偏置。模型内参数在机器的训练过程中被确定,机器学习的过程就是把这些参数的最佳值找出来。
超参数(hyperparameter):位于机器学习模型的外部,属于训练和调试过程中的参数。机器学习应该迭代(被训练)多少次?迭代时模型参数改变的速率(即学习率)是多大?正则化参数如何选择?这些都是超参数的例子,它们需要在反复调试的过程中被最终确定。这是机器学习第5个环节中所着重要做的工作。
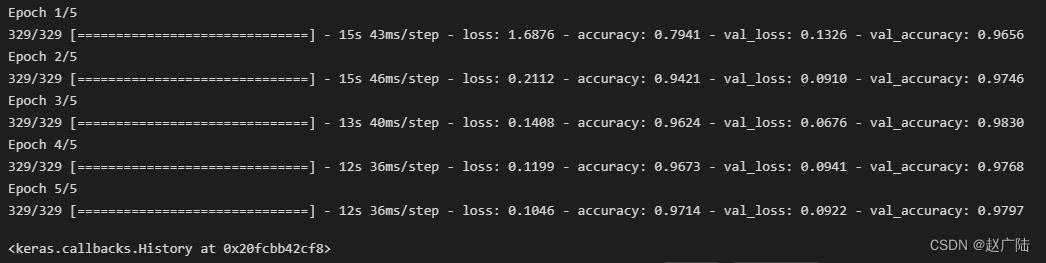
model.fit(X_train, y_train, # 指定训练特征集和训练标签集
validation_split = 0.3, # 部分训练集数据拆分成验证集
epochs=5, # 训练轮次为5轮
batch_size=128) # 以128为批量进行训练
5 超参数调试和性能优化
5.1 训练集、验证集和测试集
score = model.evaluate(X_test, y_test) # 在测试集上进行模型评估
print('测试集预测准确率:', score[1]) # 打印测试集上的预测准确率

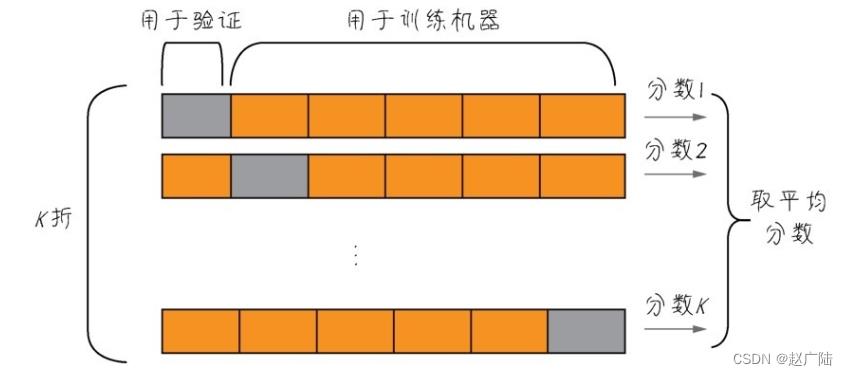
5.2 K折验证
数据,很多时候都是十分珍贵的。因此,如果有足够的数据可用,一般来说按照60%、20%、20%的比例划分为训练集、验证集和测试集。但是如果数据本身已经不大够用,还要拆分出3个甚至更多个集合,就更令人头疼。而且样本数量过少,学习出来的规律会失去代表性。因此,机器学习中有重用同一个数据集进行多次验证的方法,即K折验证,如下图所示。
5.3 模型的优化和泛化
优化(optimization)和泛化(generalization),这是机器学习的两个目标。它们之间的关系很微妙,是一种此消彼长的状态。
模型能否泛化,也许比模型在当前数据集上的性能优化更重要。经过训练之后100张猫图片都能被认出来了,但是也没什么了不起,因为这也许是通过死记硬背实现的,再给几张新的猫图片,就不认识了。这就有可能是出现了“过拟合”的问题—机器学习到的模型太过于关注训练数据本身。
5.4 验证预测结果
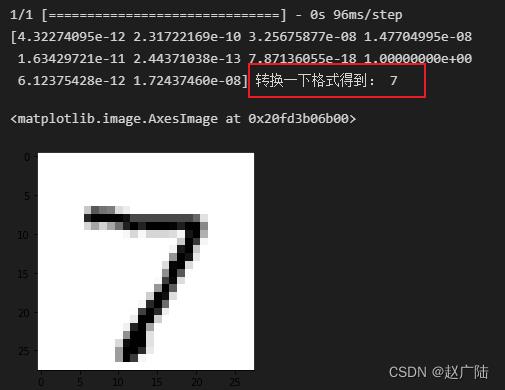
pred = model.predict(X_test[0].reshape(1, 28, 28, 1)) # 预测测试集第一个数据
print(pred[0],"转换一下格式得到:",pred.argmax()) # 把one-hot码转换为数字
import matplotlib.pyplot as plt # 导入绘图工具包
plt.imshow(X_test[0].reshape(28, 28),cmap='Greys') # 输出这个图片
以上是关于机器学习项目实战识别mnist数据集识别图片数字的主要内容,如果未能解决你的问题,请参考以下文章
PyTorch学习实战第四篇:MNIST数据集的读取显示以及全连接实现数字识别
联邦学习实战基于FATE框架的MNIST手写数字识别——全连接神经网络
TensorFlow入门实战|第1周:实现mnist手写数字识别