深度学习方法(十四):轻量级CNN网络设计——MobileNet,ShuffleNet,文末有思考
Posted 大饼博士X
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习方法(十四):轻量级CNN网络设计——MobileNet,ShuffleNet,文末有思考相关的知识,希望对你有一定的参考价值。
本系列前面介绍了非常多卷积网络结构设计,事实上,在inception和resnet网络提出并相对完善以后,网络结构的设计就不再爆发式出现了,这两大类网路涵盖了大部分应用的卷积网络结构。
在本文中,我们来一起看一些最近一年研究较多的轻量级卷积网络结构,这些网络主要的设计目标是——在保证一定的识别精度情况下,尽可能减少网络规模(参数量、计算量)。最直接的设计目标就是用于手机等移动终端中(CPU),让移动设备也具备AI计算的能力。
图1
Google MobileNet
MobileNet的新东西不多,主要是用到了depthwise separable convolutions,可以参考之前的Xception网络介绍,见下图,包括单通道卷积以及1*1卷积,这样做的好处是把参数大大降低,计算量也大大降低。
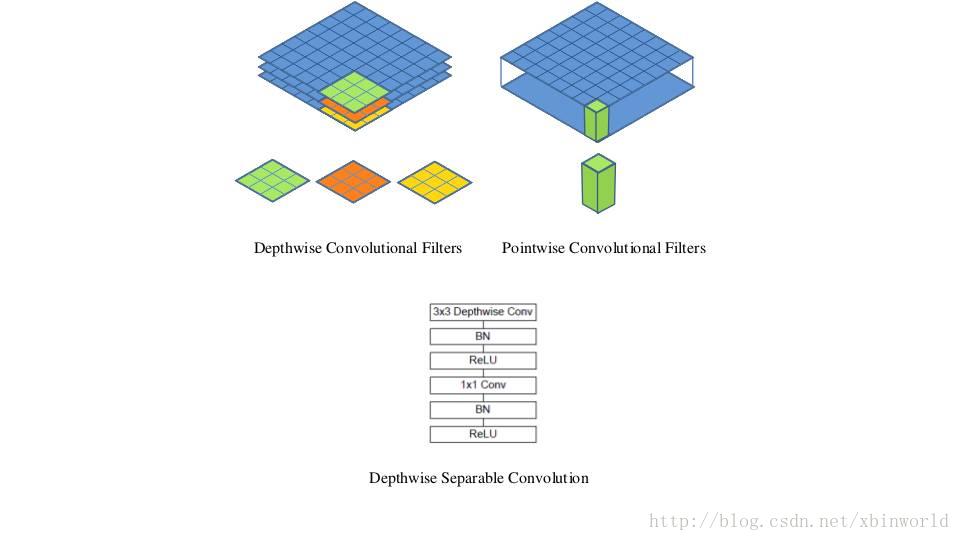
图2
简单复述一下思想:Depthwise Conv是指只有Spatial Weight的卷积,而没有Channel关系,因此每一个filter只对一个channel计算Conv,大大减少了计算量和参数量;而Channel之间的feature融合通过后面的1*1常规卷积来完成;在Relu之前都带上BN层。
旷世科技 ShuffleNet
本部分参考[1],因为作者写的很好。我自己的思考在本文的最后,大家可以直接跳过去看看。
ShuffleNet网络结构同样沿袭了稀疏连接的设计理念。作者通过分析Xception和ResNeXt模型,发现这两种结构通过卷积核拆分虽然计算复杂度均较原始卷积运算有所下降,然而拆分所产生的逐点卷积(即1*1的普通Conv)计算量却相当可观,成为了新的瓶颈。例如对于ResNeXt模型逐点卷积占据了93.4%的运算复杂度。可见,为了进一步提升模型的速度,就必须寻求更为高效的结构来取代逐点卷积。
受ResNeXt的启发,作者提出使用分组逐点卷积(group pointwise convolution)来代替原来的结构。通过将卷积运算的输入限制在每个组内,模型的计算量取得了显著的下降。然而这样做也带来了明显的问题:在多层逐点卷积堆叠时,模型的信息流被分割在各个组内,组与组之间没有信息交换(如图 3(a)所示)。这将可能影响到模型的表示能力和识别精度。
因此,在使用分组逐点卷积的同时,需要引入组间信息交换的机制。也就是说,对于第二层卷积而言,每个卷积核需要同时接收各组的特征作为输入,如图 3(b)所示。作者指出,通过引入“通道重排”(channel shuffle,见图 3(c))可以很方便地实现这一机制;并且由于通道重排操作是可导的,因此可以嵌在网络结构中实现端到端的学习。
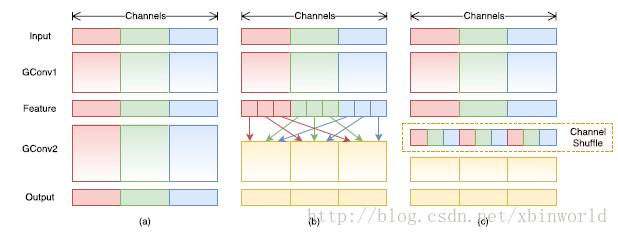
图3
基于分组逐点卷积和通道重排操作,作者提出了全新的ShuffleNet结构单元,如图4所示。该结构继承了“残差网络”(ResNet)的设计思想,在此基础上做出了一系列改进来提升模型的效率:首先,使用逐通道卷积替换原有的3x3卷积,降低卷积操作抽取空间特征的复杂度,如图2(a)所示;接着,将原先结构中前后两个1x1逐点卷积分组化,并在两层之间添加通道重排操作,进一步降低卷积运算的跨通道计算量。最终的结构单元如图4(b)所示。类似地,文中还提出了另一种结构单元(图4(c)),专门用于特征图的降采样。
借助ShuffleNet结构单元,作者构建了完整的ShuffeNet网络模型。它主要由16个ShuffleNet结构单元堆叠而成,分属网络的三个阶段,每经过一个阶段特征图的空间尺寸减半,而通道数翻倍。整个模型的总计算量约为140MFLOPs。通过简单地将各层通道数进行放缩,可以得到其他任意复杂度的模型。
另外可以发现,当卷积运算的分组数越多,模型的计算量就越低;这就意味着当总计算量一定时,较大的分组数可以允许较多的通道数,作者认为这将有利于网络编码更多的信息,提升模型的识别能力。
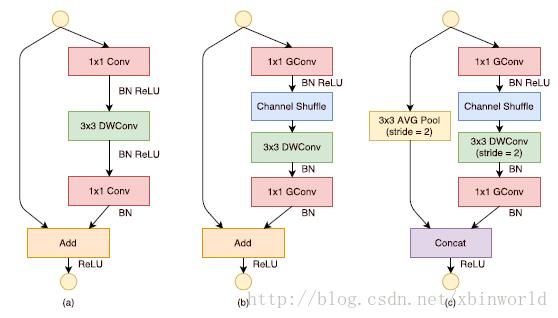
图4
实验结果
作者通过一系列在ImageNet 2016分类数据集上的控制实验说明了ShuffleNet结构单元每个部件存在的必要性、对于其他网络结构单元的优越性。接着作者通过在MS COCO目标检测上的结果说明模型的泛化能力。最后,作者给出了在ARM计算平台上ShuffleNet实际运行时的加速效果作者对于计算复杂度为140MFLOPs 、 40MFLOPs、13MFLOPs的ShuffleNet模型,在控制模型复杂度的同时对比了分组化逐点卷积的组数在1~8时分别对于性能的影响。从表1中可以看出,带有分组的(g>1)的网络的始终比不带分组(g=1)的网络的错误率低。作者观察到对于较小的网络(如ShuffleNet 0.25x),较大的分组会得到更好结果,认为更宽的通道对于小网络尤其重要。受这点启发,作者移除了网络第三阶段的两个结构单元,将节省下来的运算量用来增加网络宽度后,网络性能进一步提高。
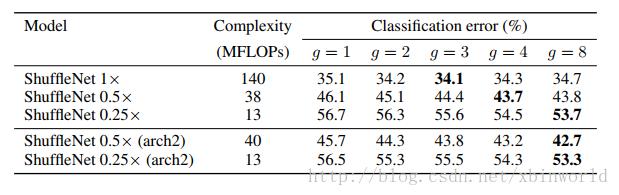
表1 组数对分类错误率的影响
道重排通
通道重排的目的是使得组间信息能够互相交流。在实验中,有通道重排的网络始终优于没有通道重排的网络,错误率降低0.9%~4.0%。尤其是在组数较大时(如g=8),前者远远优于后者。
结构对比
作者使用一样的整体网络布局,在保持计算复杂度的同时将ShuffleNet结构单元分别替换为VGG-like、ResNet、Xception-like和ResNeXt中的结构单元,使用完全一样训练方法。表2中的结果显示在不同的计算复杂度下,ShuffleNet始终大大优于其他网络。
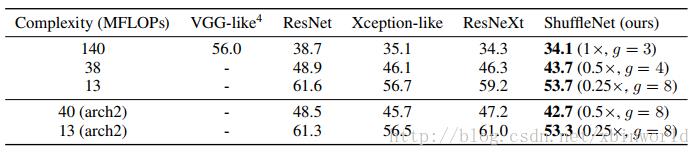
表2 和其他网络结构的分类错误(百分制)
对比MobileNets和其他的一些网络结构
最近Howard et al. 提出了MobileNets [8],利用ResNeXt里的逐通道卷积的设计移动设备上高效的网络结构。虽然ShuffleNet是为了小于150MFLOPs的模型设计的,在增大到MobileNet的500~600MFLOPs量级,依然优于MobileNet。而在40MFLOPs量级,ShuffleNet比MobileNet错误率低6.7%。详细结果可以从表3中得到。
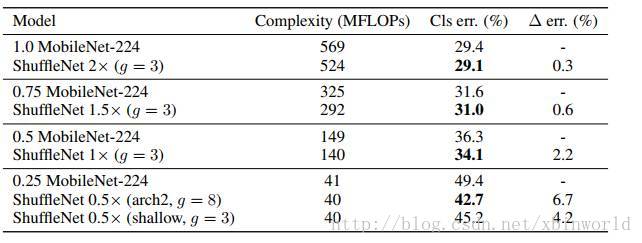
表3 ShuffleNet和MobileNet对比
和其他一些网络结构相比,ShuffleNet也体现出很大的优势。从表4中可以看出,ShuffleNet 0.5x仅用40MFLOPs就达到了AlexNet的性能,而AlexNet的计算复杂度达到了720MFLOPs,是ShuffleNet的18倍
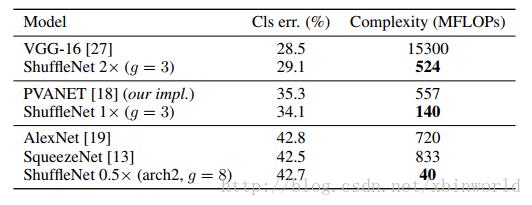
表4 ShuffleNet和其他网络结构计算复杂度的对比
MS COCO物体检测
在Faster-RCNN [5]框架下,和1.0 MobileNet-224网络复杂度可比的 ShuffleNet 2x,在600分辨率的图上的mAP达到24.5%,而MobileNet为19.8%,表明网络在检测任务上良好的泛化能力
实际运行速度
最后作者在一款ARM平台上测试了网络的实际运行速度。在作者的实现里40MFLOPs的ShuffleNet对比相似精度的AlexNet实际运行速度快约13x倍。224x224输入下只需15.2毫秒便可完成一次推理,在1280x720的输入下也只需要260.1毫秒。
应用展望
很多重要的需要语义信息的计算机视觉任务,如目标检测、物体识别等,都需要一个好的“基础模型”作为特征提取器。在移动设备越发重要的今天,在其之上运行的视觉算法模型会越多、准确率要求会越来越高。无论目标检测和识别、人脸检测和识别,还是图片风格化编辑、美颜,抑或是直播用户行为分析,都离不开基础模型的支持。好的基础模型可以让因为原始运算力需求过大而无法在手机上高效运行的模型能高效运行,将众多不可能变为可能。
此外,其他常用的模型压缩技术,如稀疏化、网络量化等技术也可以在ShuffleNet上应用,提高存储效率和运行速度,进一步降低视觉算法和应用的落地门槛。
以上Shufflenet的描述是参考的[1],下面是我自己的一些思考,希望对大家有启发:
(1)关于最作者说的最后一段,我觉得大家可以思考一下,不同模型简化的功效,是否本质上都是类似?不论是参数稀疏,矩阵分解,Depthwise卷积,分组卷积,都是基于一般的Conv内部有大量冗余,而去除这些冗余使得模型精度下降不多;但是如果已经用了一种方法简化了模型,比如10X,是否再加一种方法可以继续达到100X的简化呢,甚至只是20X有否可能?我虽然没有马上的结论,但是从我的一些经验来看,如果已经压缩较大,再叠加其他方法可能是没有简单叠加的效果。这引发了一个思考,虽然方法千奇百种,但是模型压缩的本质是什么?是否可以找到一种度量metric来直接衡量模型压缩后对模型本身的影响大小,而不用只看应用的精度比如Accuracy的变化。我觉得是存在的,并且我看到已经有一些工作在其他角度关注类似的问题。
(2)shufflenet中也采用了分组卷积的思想,(当然这个思想并不是其原创),效果非常显著,间接说明了,实际上一种高效的神经网络结构设计就是应该是分组的,而不是和一般的Conv或者InnerProduct那样全部连接在一起——类似信息应该被共享,不需要重复提取;不同的分组会承担不同的功能,并且这些功能是可以被训练的。最近Hinton教授的Capsule结构,虽然我还不知道是什么形式的,但是我猜想会有分组的概念在里面;——信息是需要浓缩的。
(3)最后,手动设计网络结构的不断演进,以及最近看到Google提的用RL方法来自动设计神经网络结构,让我感到,也许在过2~3年,我们现在谈论的手工设计的神经网络结构都将淘汰,被可以不断进化,自动根据训练数据学习得到的“更适合”的网络结构所代替。当一些结构化的网络结构被发现并被固化下来,整个神经网络的拓扑结构可以被自动发现、设计,而不再是手动设计,并且这样的网络可以不断在场景中升级演化。
以上观点肯定尚有不成熟的地方,但是却值得思考;如果您有不同观点希望可以留言指点一二;而如果您已经在从事类似的研究工作,或者已经有一些初步成果,希望您一定不吝赐教,分享给我,十分感谢!!
Ok,本篇就到这里,这几天是中秋+国庆佳节,祝大家节日愉快!我写下此文以及文末的思考,也是有缘者读之,如果真有人可以指点,希望可以邮件联系我,在博客左边有留。
参考资料
[1] 孙剑团队提出移动端神经网络ShuffleNet,优于谷歌MobileNet,http://www.sohu.com/a/156480212_473283
[2] 专栏 | Momenta详解ImageNet 2017夺冠架构SENetm,http://www.sohu.com/a/161633191_465975
[3] DPN(Dual Path Network)算法详解, http://blog.csdn.net/u014380165/article/details/75676216
[4] 王井东详解ICCV 2017入选论文:通用卷积神经网络交错组卷积, http://www.sohu.com/a/161207875_13388
098
[5] François Chollet. Xception: Deep learning with depthwise separable convolutions. arXiv:1610.02357, 2016.
[6] Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, and Kaiming He. Aggregated residual transformations for deep neural networks. arXiv:1611.05431, 2016.
[7] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016.
[8] Howard, Andrew G., et al. “Mobilenets: Efficient convolutional neural networks for mobile vision applications.” arXiv preprint arXiv:1704.04861 (2017).
[9] Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal networks.” Advances in neural information processing systems. 2015.
以上是关于深度学习方法(十四):轻量级CNN网络设计——MobileNet,ShuffleNet,文末有思考的主要内容,如果未能解决你的问题,请参考以下文章